
Nos últimos anos, a ascensão global da inteligência artificial (IA) atraiu ampla atenção da sociedade. Um ponto comum de discussão em torno da IA é o conceito de clusters computacionais — um dos três pilares fundamentais da IA, juntamente com algoritmos e dados. Esses clusters computacionais servem como a principal fonte de poder computacional, semelhante a uma enorme usina de energia que alimenta continuamente a revolução da IA.

Mas o que exatamente constitui um cluster de computação de IA? Por que eles são capazes de oferecer um desempenho computacional tão imenso? Como é sua arquitetura interna e quais tecnologias-chave estão envolvidas?
O que são clusters de computação de IA?
Como o nome sugere, um cluster de computação de IA é um sistema que fornece os recursos computacionais necessários para executar tarefas de IA. Um "cluster" refere-se a um grupo de dispositivos independentes conectados por redes de alta velocidade para funcionar como um sistema unificado.
Por definição, um cluster de computação de IA é um sistema de computação distribuído formado pela interconexão de vários nós de computação de alto desempenho (como servidores GPU ou TPU) em redes de alta velocidade.
As cargas de trabalho de IA podem geralmente ser divididas em duas categorias principais: treinamento e inferência. Tarefas de treinamento são tipicamente mais complexas e exigem mais recursos computacionais, exigindo recursos computacionais significativos. Tarefas de inferência, por outro lado, são relativamente leves e menos exigentes.
Ambos os processos dependem fortemente de operações matriciais — incluindo convoluções e multiplicações de tensores — que naturalmente se prestam à paralelização. Assim, chips de computação paralela, como GPUs, NPUs e TPUs, tornaram-se essenciais para o processamento de IA. Coletivamente, eles são chamados de chips de IA.
Os chips de IA são as unidades fundamentais da computação de IA, mas um único chip não pode operar de forma independente; ele deve ser integrado a uma placa de circuito. Dependendo da aplicação:
Incorporados em placas-mãe de celulares ou integrados em SoCs, eles potencializam recursos de IA móvel.
Instalados em módulos para dispositivos IoT, eles permitem inteligência de ponta para equipamentos como veículos autônomos, braços robóticos e câmeras de vigilância.
Integrados em estações base, roteadores e gateways, eles fornecem computação de IA de ponta, normalmente limitada à inferência devido a restrições de tamanho e energia.
Para tarefas de treinamento mais exigentes, os sistemas precisam suportar múltiplos chips de IA. Isso é possível construindo placas de computação de IA e instalando várias delas em um único servidor, transformando efetivamente um servidor padrão em um servidor de IA.

Normalmente, um servidor de IA abriga oito placas de computação, embora alguns modelos suportem até vinte placas. No entanto, devido à dissipação de calor e às limitações de energia, uma expansão adicional torna-se impraticável.
Com essa configuração, a capacidade computacional aumenta significativamente, permitindo que o servidor lide facilmente com inferências e até mesmo execute tarefas de treinamento em menor escala. Um exemplo é o modelo DeepSeek, que otimizou sua arquitetura e algoritmos para reduzir significativamente as demandas computacionais. Consequentemente, muitos fornecedores agora oferecem racks integrados "tudo em um" — compostos por servidores de IA, armazenamento e fontes de alimentação — que suportam a implantação privada de modelos DeepSeek para clientes corporativos.
No entanto, o poder computacional dessas configurações permanece finito. Treinar modelos em escala extremamente grande — aqueles com dezenas ou centenas de bilhões de parâmetros — demanda recursos muito maiores. Isso leva ao desenvolvimento de clusters de computação de IA em larga escala, que incorporam um número ainda maior de chips de IA.
Termos como "escala 10K" ou "escala 100K" referem-se a clusters compostos por 10,000 ou 100,000 placas de computação de IA. Para atingir esse objetivo, são empregadas duas estratégias fundamentais: Scale Up (adicionando hardware mais potente) e Scale Out (expandindo o número de sistemas interconectados).
O que é Scale Up?
Na terminologia da computação, “escala” refere-se à expansão dos recursos do sistema. Este conceito é particularmente familiar para aqueles com experiência em computação em nuvem.
Scale Up, também conhecido como escalonamento vertical, envolve aumentar os recursos de um único nó, como adicionar mais poder de computação, memória ou placas aceleradoras de IA a um servidor.
Scale Out, ou escalonamento horizontal, significa expandir um sistema adicionando mais nós, conectando vários servidores ou dispositivos por meio de uma rede.
Na computação em nuvem, os conceitos também se estendem a Scale Down (redução de recursos de um nó) e Scale In (redução do número de nós).
Anteriormente, discutimos como a inserção de mais placas aceleradoras de IA em um servidor é uma forma de Scale Up, com cada servidor atuando como um único nó. Ao interconectar vários servidores por meio de redes de alta velocidade, alcançamos o Scale Out.

A principal distinção entre os dois está na largura de banda de comunicação entre os chips de IA:
O Scale Up envolve conexões de nós internos, oferecendo maior velocidade, menor latência e melhor desempenho.
Historicamente, as comunicações internas dos computadores dependiam do PCIe — um protocolo desenvolvido no final do século XX, durante a ascensão da computação pessoal. Embora o PCIe tenha passado por diversas atualizações, sua evolução tem sido lenta e insuficiente para as cargas de trabalho de IA modernas.
Para superar essas limitações, a NVIDIA lançou seu protocolo de barramento proprietário NVLINK em 2014, permitindo a comunicação ponto a ponto entre GPUs. O NVLINK oferece velocidade muito maior e latência substancialmente menor em comparação ao PCIe.
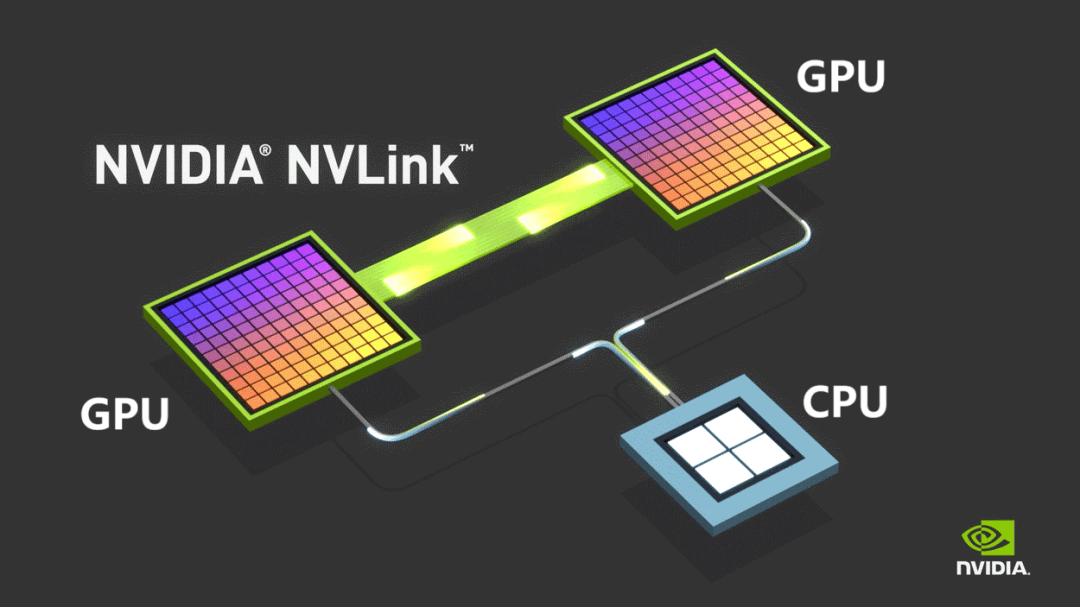
Inicialmente usado apenas para comunicação intramáquina, a NVIDIA lançou o NVSwitch em 2022 — um chip de comutação independente projetado para permitir conectividade de GPU de alta velocidade entre servidores. Essa inovação redefiniu o conceito de nó, permitindo que vários servidores e dispositivos de rede trabalhassem coletivamente dentro de um Domínio de Alta Largura de Banda (HBD).
A NVIDIA se refere a esses sistemas, onde mais de 16 GPUs são interconectadas com largura de banda ultra-alta, como supernós.
Com o tempo, o NVLINK evoluiu para sua quinta geração. Cada GPU agora suporta até 18 conexões NVLINK, e a largura de banda total da GPU Blackwell atingiu 1800 GB/s, superando em muito o PCIe Gen6.
Em março de 2024, a NVIDIA revelou o NVL72, um gabinete refrigerado a líquido que integra 36 CPUs Grace e 72 GPUs Blackwell. Ele oferece até 720 PFLOPS de desempenho de treinamento ou 1440 PFLOPS de desempenho de inferência, consolidando ainda mais a liderança da NVIDIA no ecossistema de computação de IA — impulsionada por seu popular hardware de GPU e pela pilha de software CUDA.

À medida que a adoção da IA se expandia, diversas outras empresas desenvolveram seus próprios chips de IA. Devido à natureza proprietária do NVLINK, essas empresas tiveram que desenvolver arquiteturas alternativas de clusters de computação.
A AMD, uma grande concorrente, lançou o UA LINK.
Participantes nacionais na China — como Tencent, Alibaba e China Mobile — lideraram iniciativas abertas como ETH-X, ALS e OISA.
Outro avanço notável é o protocolo UB (Unified Bus) da Huawei, uma tecnologia proprietária desenvolvida para dar suporte ao ecossistema de chips de IA Ascend. Os chips da Huawei, como o Ascend 910C, evoluíram consideravelmente nos últimos anos.
Em abril de 2025, a Huawei lançou o supernó CloudMatrix384, integrando 384 placas aceleradoras de IA Ascend 910C e alcançando até 300 PFLOPS de desempenho de computação BF16 denso — quase o dobro do sistema GB200 NVL72 da NVIDIA.
O CloudMatrix384 aproveita a tecnologia UB e consiste em três planos de rede distintos:
- Avião UB
- Plano RDMA (Acesso Direto à Memória Remoto)
- Plano VPC (Nuvem Privada Virtual)
Esses planos complementares permitem uma comunicação excepcional entre placas e melhoram significativamente o poder computacional geral dentro do supernó.
Devido a limitações de espaço, exploraremos os detalhes técnicos desses aviões separadamente em uma discussão futura.
Uma observação final: em resposta à crescente pressão dos padrões abertos, a NVIDIA anunciou recentemente sua iniciativa NVLink Fusion, oferecendo acesso à sua tecnologia NVLink a oito parceiros globais. Essa iniciativa visa ajudá-los a construir sistemas de IA personalizados por meio da interconectividade multichip. No entanto, de acordo com alguns relatos da mídia, os principais componentes do NVLink permanecem proprietários, sugerindo que a NVIDIA ainda é um tanto reservada em sua abertura.
O que é Scale Out?
Scale Out refere-se à expansão horizontal de sistemas de computação e se assemelha bastante às redes tradicionais de comunicação de dados. Tecnologias comumente usadas para conectar servidores convencionais — como arquitetura fat-tree, topologia de rede spine-leaf, protocolos TCP/IP e Ethernet — formam a base fundamental da infraestrutura Scale Out.
Evoluindo para as demandas da IA
Com as crescentes demandas das cargas de trabalho de IA, as tecnologias de rede tradicionais exigiram melhorias substanciais para atender aos critérios de desempenho. Atualmente, as duas tecnologias de rede dominantes para Scale Out são:
- Banda Infinita (IB)
- RoCEv2 (RDMA sobre Ethernet convergente versão 2)
Ambos são baseados no protocolo RDMA (Remote Direct Memory Access), fornecendo maiores taxas de transferência de dados, menor latência e recursos superiores de balanceamento de carga em comparação ao Ethernet tradicional.
InfiniBand vs RoCEv2
- O InfiniBand foi originalmente projetado para substituir o PCIe para fins de interconexão. Embora sua adoção tenha oscilado ao longo do tempo, foi finalmente adquirido pela NVIDIA por meio da compra da Mellanox. Hoje, o IB é propriedade da NVIDIA e desempenha um papel fundamental em sua infraestrutura computacional. Embora ofereça excelente desempenho, seu preço é alto.
- O RoCEv2, por outro lado, é um padrão aberto desenvolvido para contrabalançar o domínio de mercado da IB. Ele combina RDMA com Ethernet convencional, oferecendo eficiência de custos e reduzindo gradualmente a diferença de desempenho com o InfiniBand.
Diferentemente dos padrões fragmentados vistos em implementações de Scale Up, o Scale Out é amplamente unificado no RoCEv2, devido à sua ênfase na compatibilidade entre nós, em vez de acoplamento rígido com produtos em nível de chip.
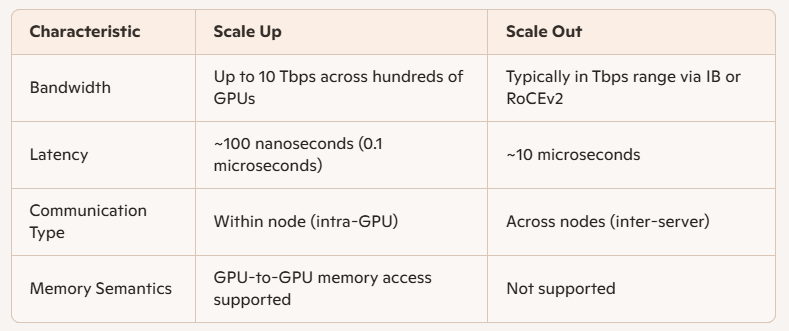
Diferenças de desempenho: escala vertical vs. escala horizontal
As principais diferenças técnicas entre Scale Up e Scale Out estão na largura de banda e na latência:

Aplicação em Treinamento de IA
O treinamento de IA envolve várias formas de computação paralela:
- TP (Paralelismo Tensor)
- EP (Paralelismo de Especialistas)
- PP (Paralelismo de Pipeline)
- DP (Paralelismo de Dados)
Geralmente:
- PP e DP envolvem cargas de comunicação menores e são manipuladas via Scale Out.
- TP e EP, que exigem troca de dados mais pesada, são melhor suportados pelo Scale Up dentro de supernós.
Vantagens do Scale Up no Design de Rede
Supernós — construídos na arquitetura Scale Up — são conectados por barramentos internos de alta velocidade e oferecem suporte eficiente para computação paralela, troca de parâmetros de GPU e sincronização de dados. Eles também permitem acesso direto à memória entre GPUs, um recurso que o Scale Out não possui.
Do ponto de vista de implantação e manutenção:
- Domínios maiores de alta largura de banda (HBDs) simplificam a rede de expansão.
- Os sistemas Scale Up pré-integrados reduzem a complexidade, encurtam o tempo de implantação e facilitam as operações de longo prazo.
No entanto, o Scale Up não pode se expandir infinitamente devido a restrições de custo. A escala ideal depende de cenários de uso específicos.

Um futuro unificado?
Em última análise, Scale Up e Scale Out representam um equilíbrio entre desempenho e custo. À medida que a tecnologia evolui, espera-se que a fronteira entre os dois se torne tênue. Padrões abertos de Scale Up emergentes, como o ETH-X, baseado em Ethernet, oferecem métricas de desempenho promissoras:
- Capacidade do chip de switch: até 51.2 Tbps
- Velocidade SerDes: Até 112 Gbps
- Latência: tão baixa quanto 200 nanossegundos
Como o Scale Out também utiliza Ethernet, essa convergência sugere uma arquitetura unificada, onde um único padrão pode sustentar ambos os modelos de expansão em futuros ecossistemas de computação.
Tendências no desenvolvimento de clusters de computação de IA
À medida que o campo da inteligência artificial (IA) continua a se expandir, os clusters de computação de IA estão evoluindo ao longo de várias trajetórias importantes:
Distribuição geográfica da infraestrutura física
Os clusters de IA estão evoluindo para configurações que contêm dezenas ou até centenas de milhares de cartões de IA. Por exemplo:
- O rack NVL72 da NVIDIA integra 72 chips.
- O CM384 da Huawei implementa 384 chips em 16 racks.
Para construir um cluster de 100,000 placas usando a arquitetura CM384 da Huawei, seriam necessárias 432 unidades CM384 — o equivalente a 165,888 chips e 6,912 racks. Essa escala excede em muito a capacidade física e elétrica de um único data center.
Como resultado, o setor está explorando ativamente implantações de data centers distribuídos que possam operar como um cluster unificado de computação de IA. Essas arquiteturas dependem fortemente de tecnologias avançadas de comunicação óptica de interconexão de data centers (DCI), que devem suportar transmissão de longa distância, alta largura de banda e baixa latência. Espera-se que inovações como a fibra óptica de núcleo oco acelerem sua adoção.
Personalização da Arquitetura do Nó
A abordagem tradicional para a construção de clusters de IA frequentemente se concentrava na maximização do número de chips de IA. No entanto, há uma ênfase crescente no design arquitetônico profundo, que vai além do volume.
As tendências emergentes incluem o agrupamento de recursos computacionais — como GPUs, NPUs, CPUs, memória e armazenamento — para criar clusters altamente adaptáveis, adaptados aos requisitos de modelos de IA em larga escala, incluindo arquiteturas como Mixture of Experts (MoE).
Em suma, entregar chips nus não é mais suficiente. Projetos personalizados e específicos para cada cenário são cada vez mais necessários para garantir desempenho e eficiência ideais.
Operações e Manutenção Inteligentes
O treinamento de modelos de IA em larga escala é notoriamente propenso a erros, com falhas potencialmente ocorrendo em poucas horas. Cada falha exige retreinamento, prolongando os cronogramas de desenvolvimento e aumentando os custos operacionais.
Para mitigar esses riscos, as organizações estão priorizando a confiabilidade e a estabilidade dos sistemas, incorporando ferramentas inteligentes de operação e manutenção. Esses sistemas podem:
- Prever falhas potenciais
- Identificar hardware abaixo do ideal ou deteriorado
- Habilitar a substituição proativa de componentes
Essas abordagens reduzem significativamente as taxas de falhas e o tempo de inatividade, reforçando assim a estabilidade do cluster e melhorando efetivamente a saída computacional geral.
Eficiência Energética e Sustentabilidade
A computação de IA exige um consumo massivo de energia, levando os principais fornecedores a explorar estratégias para reduzir o uso de energia e aumentar a dependência de fontes de energia renováveis.
Esse impulso para clusters de computação verde está alinhado com iniciativas de sustentabilidade mais amplas, como a estratégia “East Data, West Compute” da China, que visa otimizar a alocação de energia e promover o desenvolvimento ecológico de longo prazo da infraestrutura de IA.
Produtos relacionados:
-
 QSFP-DD-400G-SR8 400G QSFP-DD SR8 PAM4 850nm 100m MTP / MPO OM3 Módulo transceptor óptico FEC
$149.00
QSFP-DD-400G-SR8 400G QSFP-DD SR8 PAM4 850nm 100m MTP / MPO OM3 Módulo transceptor óptico FEC
$149.00
-
 QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310nm 500m MTP / MPO SMF FEC Módulo transceptor óptico
$400.00
QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310nm 500m MTP / MPO SMF FEC Módulo transceptor óptico
$400.00
-
 Módulo transceptor óptico QSFP-DD-400G-SR4 QSFP-DD 400G SR4 PAM4 850nm 100m MTP/MPO-12 OM4 FEC
$450.00
Módulo transceptor óptico QSFP-DD-400G-SR4 QSFP-DD 400G SR4 PAM4 850nm 100m MTP/MPO-12 OM4 FEC
$450.00
-
 QSFP-DD-400G-FR4 400G QSFP-DD FR4 PAM4 CWDM4 Módulo transceptor ótico 2km LC SMF FEC
$500.00
QSFP-DD-400G-FR4 400G QSFP-DD FR4 PAM4 CWDM4 Módulo transceptor ótico 2km LC SMF FEC
$500.00
-
 QSFP-DD-400G-XDR4 400G QSFP-DD XDR4 PAM4 1310nm 2km MTP / MPO-12 SMF FEC Módulo Transceptor Ótico
$580.00
QSFP-DD-400G-XDR4 400G QSFP-DD XDR4 PAM4 1310nm 2km MTP / MPO-12 SMF FEC Módulo Transceptor Ótico
$580.00
-
 QSFP-DD-400G-LR4 400G QSFP-DD LR4 PAM4 CWDM4 Módulo transceptor óptico SMF FEC LC 10km
$600.00
QSFP-DD-400G-LR4 400G QSFP-DD LR4 PAM4 CWDM4 Módulo transceptor óptico SMF FEC LC 10km
$600.00
-
 Módulo transceptor óptico de fotônica de silício QDD-4X100G-FR-Si QSFP-DD 4 x100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS3.0
$650.00
Módulo transceptor óptico de fotônica de silício QDD-4X100G-FR-Si QSFP-DD 4 x100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS3.0
$650.00
-
 Módulo transceptor óptico de fotônica de silício QDD-4X100G-FR-4Si QSFP-DD 4 x 100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS4.0
$750.00
Módulo transceptor óptico de fotônica de silício QDD-4X100G-FR-4Si QSFP-DD 4 x 100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS4.0
$750.00
-
 QSFP-DD-400G-SR4.2 400Gb/s QSFP-DD SR4 BiDi PAM4 850nm/910nm 100m/150m OM4/OM5 MMF MPO-12 FEC Módulo Transceptor Óptico
$900.00
QSFP-DD-400G-SR4.2 400Gb/s QSFP-DD SR4 BiDi PAM4 850nm/910nm 100m/150m OM4/OM5 MMF MPO-12 FEC Módulo Transceptor Óptico
$900.00
-
 Módulo transceptor óptico compatível com Arista Q112-400G-SR4 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC
$450.00
Módulo transceptor óptico compatível com Arista Q112-400G-SR4 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC
$450.00
-
 Cisco Q112-400G-DR4 compatível 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 com módulo transceptor óptico FEC
$650.00
Cisco Q112-400G-DR4 compatível 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 com módulo transceptor óptico FEC
$650.00
-
 OSFP-800G-DR8D-FLT 800G-DR8 OSFP Flat Top PAM4 1310nm 500m DOM Módulo transceptor óptico MTP/MPO-12 SMF duplo
$1199.00
OSFP-800G-DR8D-FLT 800G-DR8 OSFP Flat Top PAM4 1310nm 500m DOM Módulo transceptor óptico MTP/MPO-12 SMF duplo
$1199.00
-
 OSFP-800G-SR8D-FLT OSFP 8x100G SR8 Flat Top PAM4 850nm 100m DOM Módulo Transceptor Ótico MPO-12 MMF Duplo
$650.00
OSFP-800G-SR8D-FLT OSFP 8x100G SR8 Flat Top PAM4 850nm 100m DOM Módulo Transceptor Ótico MPO-12 MMF Duplo
$650.00
-
 OSFP-800G-SR8D OSFP 8x100G SR8 PAM4 850nm 100m DOM Módulo Transceptor Ótico MPO-12 MMF Duplo
$650.00
OSFP-800G-SR8D OSFP 8x100G SR8 PAM4 850nm 100m DOM Módulo Transceptor Ótico MPO-12 MMF Duplo
$650.00
-
 OSFP-800G-DR8D 800G-DR8 OSFP PAM4 1310nm 500m DOM Módulo Transceptor Ótico MTP/MPO-12 SMF Duplo
$850.00
OSFP-800G-DR8D 800G-DR8 OSFP PAM4 1310nm 500m DOM Módulo Transceptor Ótico MTP/MPO-12 SMF Duplo
$850.00
-
 OSFP-800G-2FR4L OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF Módulo Transceptor Óptico
$1200.00
OSFP-800G-2FR4L OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF Módulo Transceptor Óptico
$1200.00