
NVLink — это технология, разработанная NVIDIA для высокоскоростного соединения «точка-точка» между графическими процессорами. Он направлен на преодоление ограничения пропускной способности соединения PCIe и обеспечение передачи данных с малой задержкой и высокой пропускной способностью между чипами графического процессора, позволяя им работать вместе более эффективно. До появления технологии NVLink (до 2014 года) графические процессоры необходимо было соединять между собой через переключатель PCIe, как показано на рисунке ниже. Сигнал от графического процессора должен был сначала пройти через коммутатор PCIe, где обработка данных включала распределение и планирование ЦП, что добавляло дополнительную задержку в сети и ограничивало производительность системы. В то время протокол PCIe достиг третьего поколения с одноканальной скоростью 3 Гбит/с и общей пропускной способностью 8 ГБ/с (16 Гбит/с, 128 байт = 1 бит) для 8 каналов. Поскольку производительность чипа графического процессора постоянно улучшалась, пропускная способность его межсетевого соединения стала узким местом.
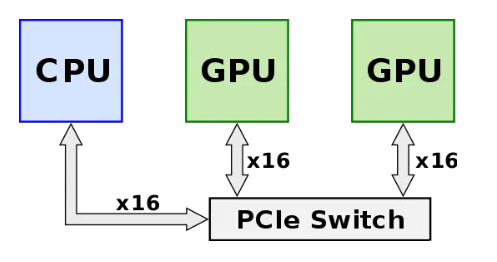
Источник: https://en.wikichip.org/wiki/nvidia/nvlink.
В 2014 году был выпущен NVLink 1.0, который был применен к чипу P100, как показано на следующем рисунке. Между двумя графическими процессорами имеется четыре канала NVlink, каждый из которых содержит восемь линий, каждая со скоростью 20 Гбит/с. Таким образом, двунаправленная пропускная способность всей системы составляет 160 ГБ/с, что в пять раз больше, чем у PCIe3 x16.
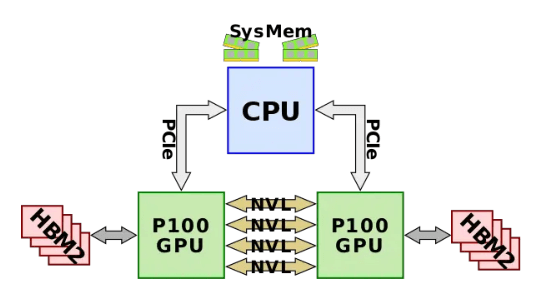
Источник: https://en.wikichip.org/wiki/nvidia/nvlink.
Каждый NVLink состоит из 16 пар дифференциальных линий, соответствующих восьми полосам каналов в обоих направлениях, как показано на следующем рисунке. Два конца дифференциальной пары — это PHY, которые содержат SerDes.
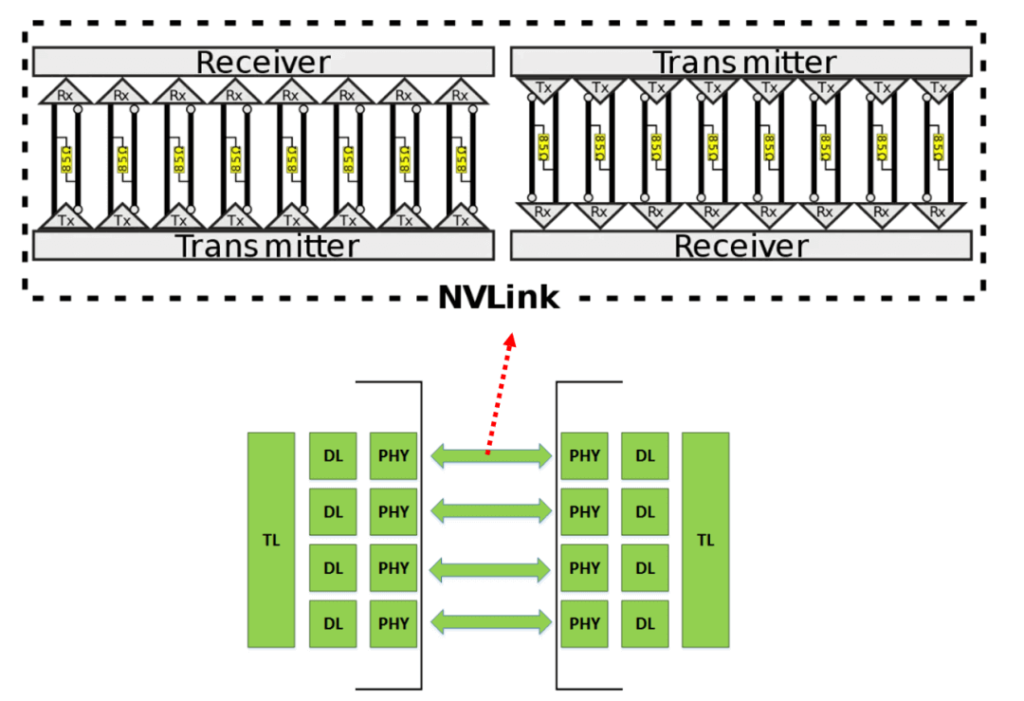
Источник: https://www.nextplatform.com/2016/05/04/nvlink-takes-gpu-acceleration-next-level/
На основе NVLink 1.0 можно сформировать плоскую ячеистую структуру из четырех графических процессоров с двухточечными соединениями между каждой парой. Восемь графических процессоров соответствуют кубической сетке, которая может образовывать сервер DGX-1. Это также соответствует обычной конфигурации из восьми карт, как показано на следующем рисунке. Следует отметить, что в настоящее время восемь графических процессоров не образуют комплексного соединения.
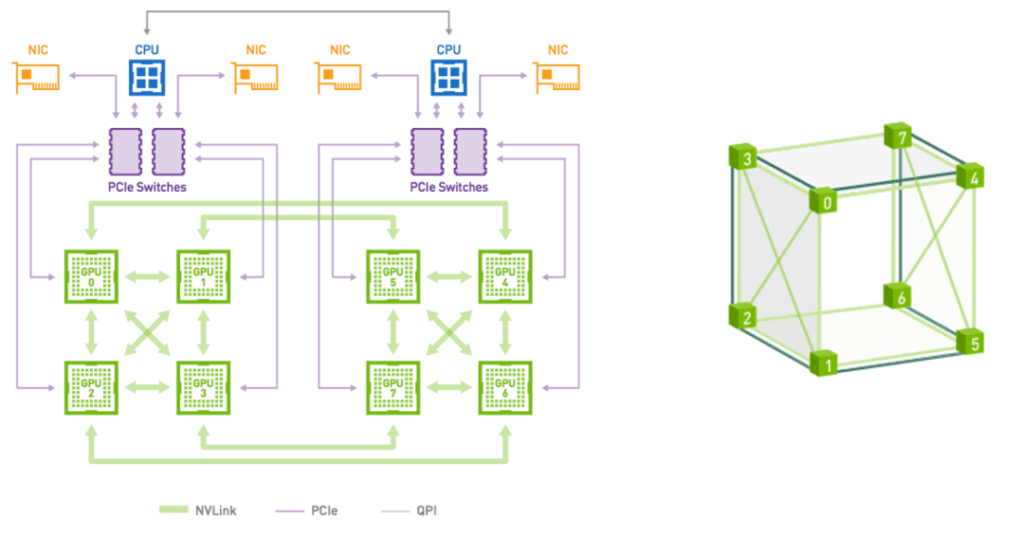
Источник: https://developer.nvidia.com/blog/dgx-1-fastest-deep-learning-system/
В 2017 году Nvidia запустила второе поколение технологии NVLink. Он соединяет два чипа GPU V100 с шестью каналами NVLink, каждый из которых состоит из восьми линий. Скорость каждой линии увеличена до 25 Гбит/с, а двунаправленная пропускная способность системы достигает 300 ГБ/с, что почти вдвое больше, чем у NVLink 1.0. Одновременно, чтобы обеспечить комплексное соединение между восемью графическими процессорами, Nvidia представила технологию NVSwitch. NVSwitch 1.0 имеет 18 портов, каждый с пропускной способностью 50 ГБ/с и общей пропускной способностью 900 ГБ/с. Каждый NVSwitch резервирует два порта для подключения к ЦП. Используя шесть NVSwitch, можно установить комплексное соединение восьми чипов GPU V100, как показано на рисунке ниже.
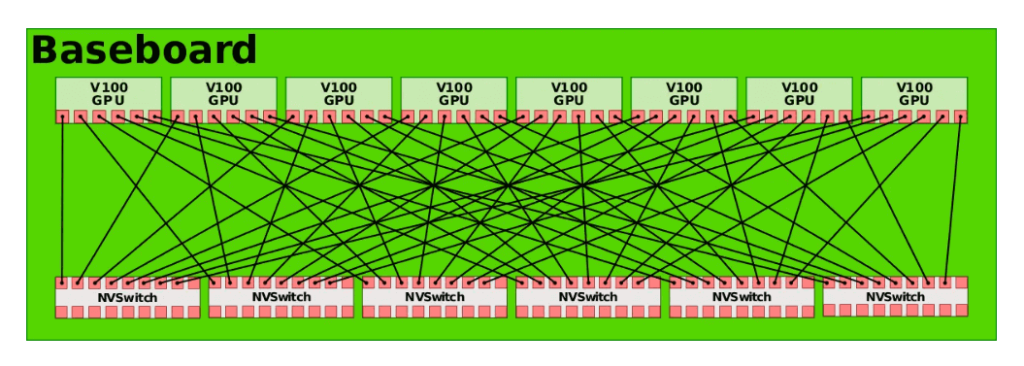
Источник: https://en.wikichip.org/wiki/nvidia/nvswitch.
Система DGX-2 состоит из двух плат, как показано на рисунке ниже, обеспечивая комплексное соединение 16 чипов графического процессора.
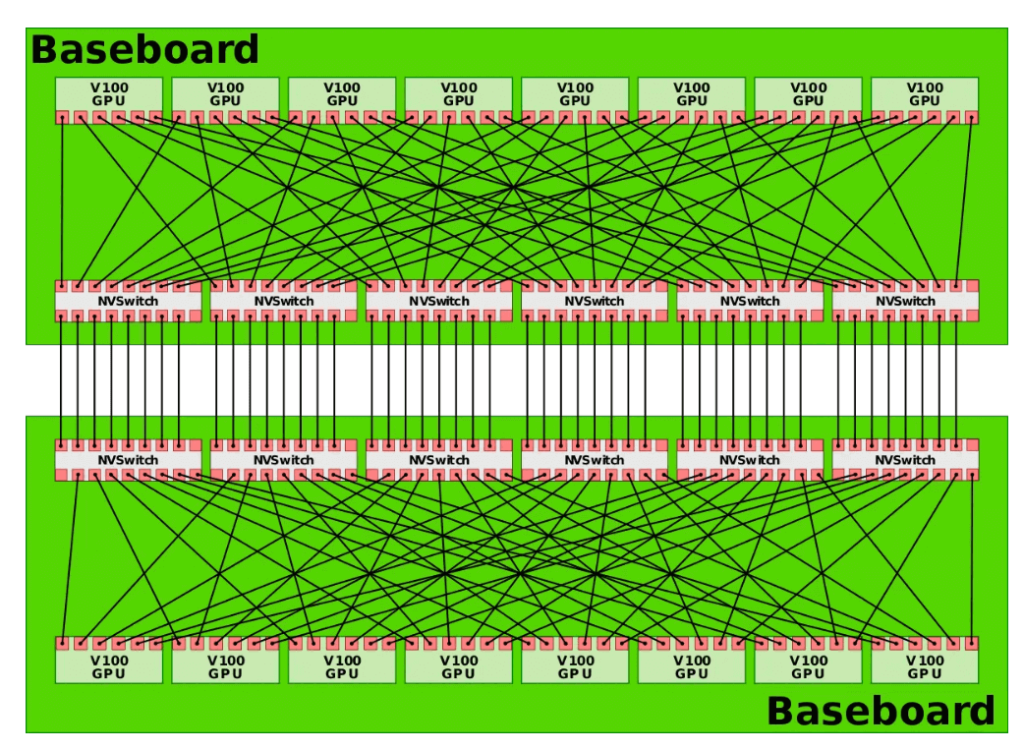
Источник: https://en.wikichip.org/wiki/nvidia/nvswitch.
В 2020 году появилась технология NVLink 3.0. Он связывает два чипа графического процессора A100 с 12 каналами NVLink, каждый из которых содержит четыре линии. Скорость каждой линии составляет 50 Гбит/с, а двунаправленная пропускная способность системы достигает 600 ГБ/с, что вдвое больше, чем у NVLink 2.0. По мере увеличения количества NVLinks количество портов NVSwitch также выросло до 36, каждый со скоростью 50 ГБ/с. DGX A100 состоит из восьми чипов графического процессора A100 и четырех NVSwitch, как показано на рисунке ниже.
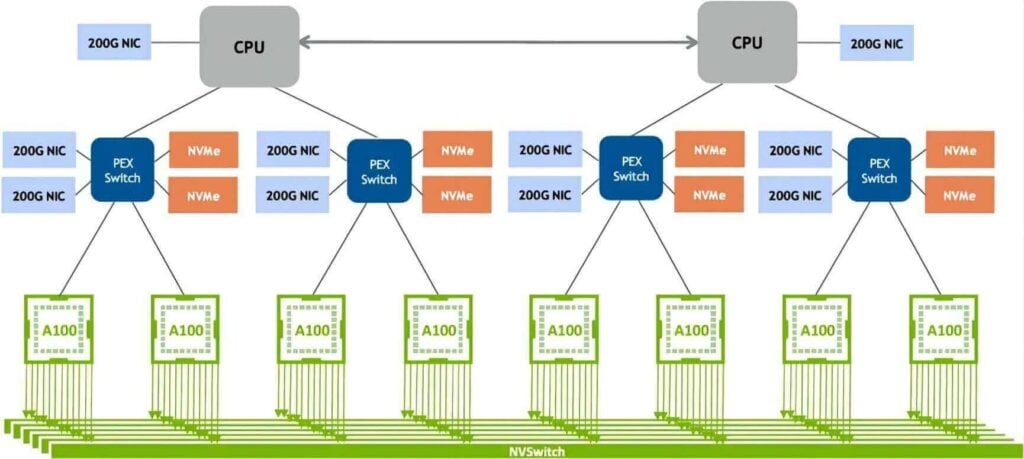
Источник: http://www.eventdrive.co.kr/2020/azwell/DGX_A100_Azwellplus.pdf.
В 2022 году технология NVLink была обновлена до четвертого поколения, что позволяет двум чипам графического процессора H100 соединяться между собой через 18 каналов NVLink, каждый канал содержит 2 линии, каждая линия поддерживает скорость PAM100 4 Гбит/с, таким образом общая двунаправленная пропускная способность увеличилась до 900 ГБ. /с. NVSwitch также был обновлен до третьего поколения: каждый NVSwitch поддерживает 64 порта, каждый порт имеет скорость 50 ГБ/с. DGX H100 состоит из 8 чипов H100 и 4 чипов NVSwitch, как показано на рисунке ниже. На другой стороне каждого NVSwitch имеется несколько Оптические модули 800G OSFP подключены. Если взять в качестве примера первый NVSwitch слева, его общая однонаправленная пропускная способность на стороне, подключенной к графическому процессору, составляет 4 Тбит/с (20NVLink200 Гбит/с), а общая пропускная способность на стороне, подключенной к оптическому модулю, также составляет 4 Тбит/с (5800 Гбит/с), оба из которых равны по размеру, образуя неблокирующую сеть. Следует отметить, что полоса пропускания в оптическом модуле является однонаправленной, тогда как в микросхемах AI обычно используется двунаправленная полоса пропускания.
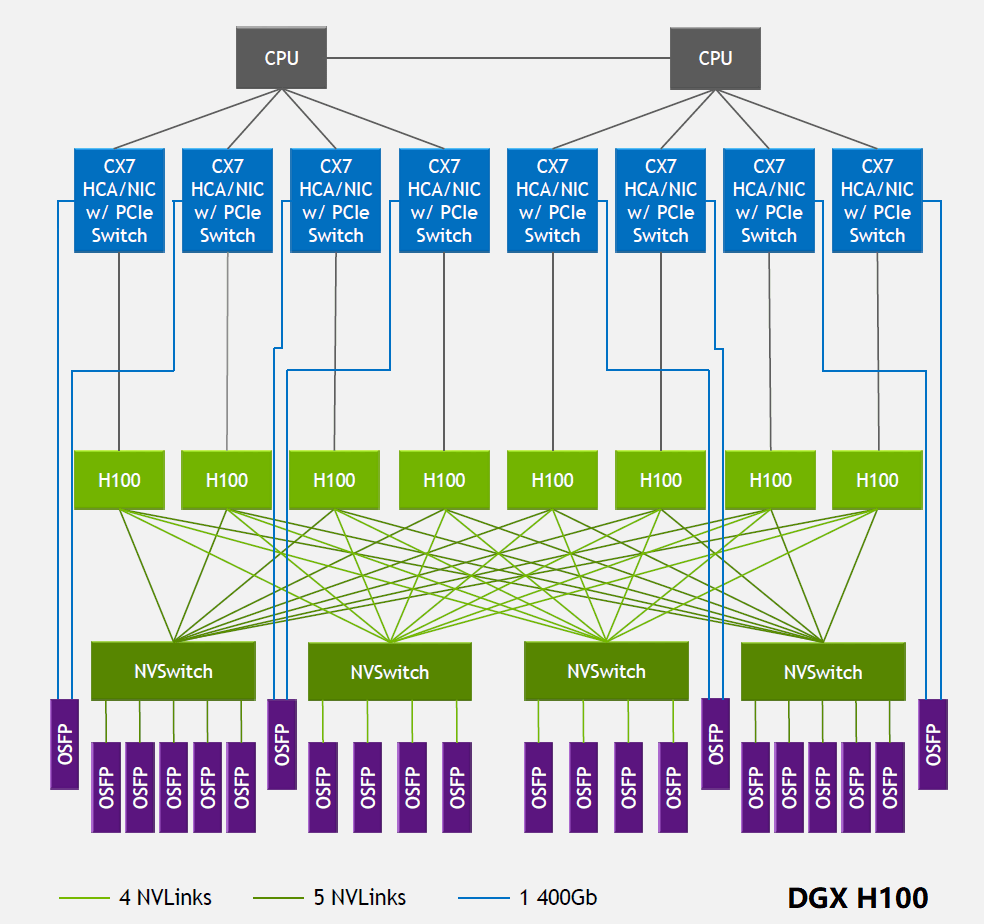
Источник: https://blog.apnic.net/2023/08/10/large-language-models-the-hardware-connection/
Модуль оптического приемопередатчика 800G OSFP SR8 предназначен для каналов 400G InfiniBand NDR по многомодовому оптоволокну с использованием длины волны 850 нм. Модуль имеет два порта 4-канальной оптической модуляции 100G-PAM4, каждый из которых использует разъем MTP/MPO-12. В видео ниже вы увидите, как подключить его к другому устройству с помощью оптоволоконных кабелей и как настроить протокол коммутатора на основе InfiniBand или Ethernet. Вы также узнаете о ключевых функциях и преимуществах модуля 800G OSFP SR8, таких как его высокая пропускная способность, низкое энергопотребление и возможность горячего подключения.
В следующей таблице приведены параметры производительности каждого поколения NVLink.
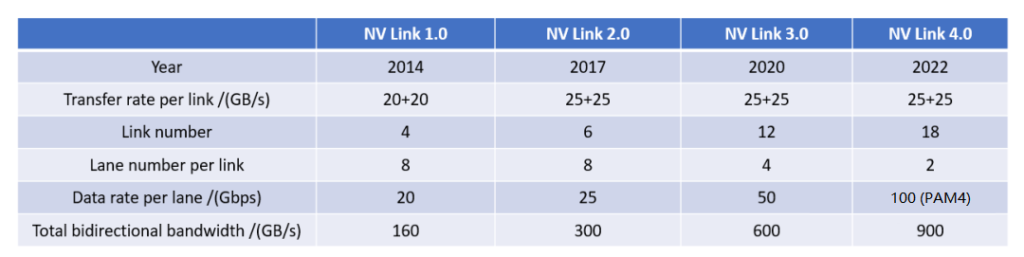
Параметры каждого поколения PCIe показаны в следующей таблице.

С точки зрения скорости одной линии NVLink обычно примерно в два раза выше, чем PCIe за тот же период, а преимущество общей пропускной способности еще более очевидно: NVLink примерно в пять раз превышает общую пропускную способность PCIe. Оно превосходило и никогда не прекращалось.
NVLink, после почти десяти лет разработки, стала основной технологией чипов графических процессоров Nvidia, важной частью ее экосистемы, эффективно решая проблему соединения данных с высокой пропускной способностью и малой задержкой между чипами графических процессоров и изменяя традиционную вычислительную архитектуру. Однако, поскольку эта технология уникальна для Nvidia, другие производители чипов AI могут использовать только PCIe или другие протоколы межсетевого взаимодействия. В то же время Nvidia изучает возможность использования оптического соединения для обеспечения соединения между графическими процессорами, как показано на рисунке ниже, где кремниевый чип фотоники и графический процессор упакованы вместе, а оптические волокна соединяют два чипа графического процессора.
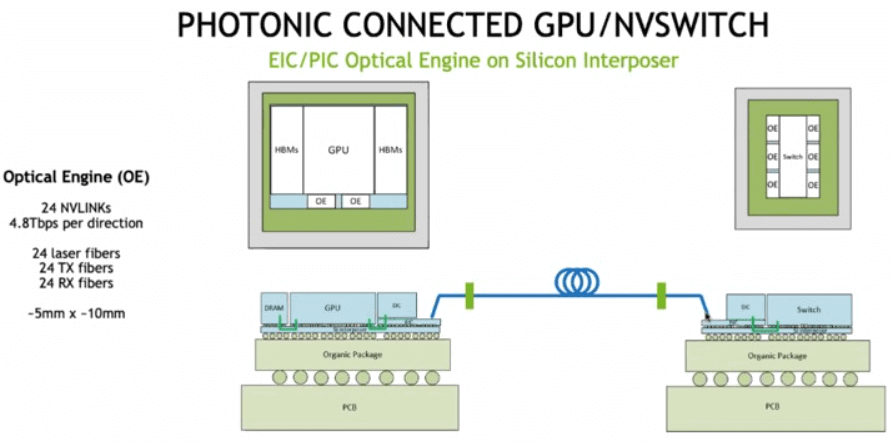
Источник: https://www.nextplatform.com/2022/08/17/nvidia-shows-what-optically-linked-gpu-systems-might-look-like/
Сопутствующие товары:
-
 Совместимый с NVIDIA MMA4Z00-NS400 400G OSFP SR4 Flat Top PAM4 850 нм 30 м на OM3/50 м на OM4 MTP/MPO-12 Многомодовый модуль оптического трансивера FEC
$550.00
Совместимый с NVIDIA MMA4Z00-NS400 400G OSFP SR4 Flat Top PAM4 850 нм 30 м на OM3/50 м на OM4 MTP/MPO-12 Многомодовый модуль оптического трансивера FEC
$550.00
-
 NVIDIA MMA4Z00-NS-FLT Совместимый двухпортовый OSFP 800 Гбит/с 2x400G SR8 PAM4 850 нм 100 м DOM Двойной модуль оптического трансивера MPO-12 MMF
$650.00
NVIDIA MMA4Z00-NS-FLT Совместимый двухпортовый OSFP 800 Гбит/с 2x400G SR8 PAM4 850 нм 100 м DOM Двойной модуль оптического трансивера MPO-12 MMF
$650.00
-
 NVIDIA MMA4Z00-NS Совместимый двухпортовый OSFP 800 Гбит/с 2x400G SR8 PAM4 850 нм 100 м DOM Двойной модуль оптического трансивера MPO-12 MMF
$650.00
NVIDIA MMA4Z00-NS Совместимый двухпортовый OSFP 800 Гбит/с 2x400G SR8 PAM4 850 нм 100 м DOM Двойной модуль оптического трансивера MPO-12 MMF
$650.00
-
 NVIDIA MMS4X00-NM Совместимый двухпортовый OSFP 800 Гбит/с 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Модуль оптического трансивера
$900.00
NVIDIA MMS4X00-NM Совместимый двухпортовый OSFP 800 Гбит/с 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Модуль оптического трансивера
$900.00
-
 Совместимый с NVIDIA MMS4X00-NM-FLT 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Модуль оптического трансивера
$1199.00
Совместимый с NVIDIA MMS4X00-NM-FLT 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Модуль оптического трансивера
$1199.00
-
 Совместимый с NVIDIA MMS4X00-NS400 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Модуль оптического трансивера
$700.00
Совместимый с NVIDIA MMS4X00-NS400 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Модуль оптического трансивера
$700.00
-
 NVIDIA (Mellanox) MMA1T00-HS совместимый 200G Infiniband HDR QSFP56 SR4 850 нм 100 м оптический приемопередающий модуль MPO-12 APC OM3/OM4 FEC PAM4
$139.00
NVIDIA (Mellanox) MMA1T00-HS совместимый 200G Infiniband HDR QSFP56 SR4 850 нм 100 м оптический приемопередающий модуль MPO-12 APC OM3/OM4 FEC PAM4
$139.00
-
 Совместимость с NVIDIA MFP7E10-N010, 10 волокон, длина 33 м (8 футов), низкие вносимые потери, гнездо-мама Магистральный кабель MPO, полярность B, APC-APC, LSZH, многомодовый OM3 50/125
$47.00
Совместимость с NVIDIA MFP7E10-N010, 10 волокон, длина 33 м (8 футов), низкие вносимые потери, гнездо-мама Магистральный кабель MPO, полярность B, APC-APC, LSZH, многомодовый OM3 50/125
$47.00
-
 Совместимый с NVIDIA MCP7Y00-N003-FLT 3 м (10 фута) 800G OSFP с двумя портами до 2x400G Flat Top OSFP InfiniBand NDR Breakout DAC
$260.00
Совместимый с NVIDIA MCP7Y00-N003-FLT 3 м (10 фута) 800G OSFP с двумя портами до 2x400G Flat Top OSFP InfiniBand NDR Breakout DAC
$260.00
-
 NVIDIA MCP7Y70-H002 Совместимость с двумя портами 2G, 7 м (400 фута), от 2x200G OSFP до 4x100G QSFP56, медный кабель прямого подключения с пассивной разводкой
$155.00
NVIDIA MCP7Y70-H002 Совместимость с двумя портами 2G, 7 м (400 фута), от 2x200G OSFP до 4x100G QSFP56, медный кабель прямого подключения с пассивной разводкой
$155.00
-
 NVIDIA MCA4J80-N003-FTF, совместимый с двумя портами 3G, 10 м (800 футов), 2x400G OSFP на 2x400G OSFP, активный медный кабель InfiniBand NDR, плоская верхняя часть на одном конце и ребристая верхняя часть на другом
$600.00
NVIDIA MCA4J80-N003-FTF, совместимый с двумя портами 3G, 10 м (800 футов), 2x400G OSFP на 2x400G OSFP, активный медный кабель InfiniBand NDR, плоская верхняя часть на одном конце и ребристая верхняя часть на другом
$600.00
-
 NVIDIA MCP7Y10-N002, совместимый с двухпортовым OSFP 2G InfiniBand NDR длиной 7 м (800 фута) с 2x400G QSFP112 Breakout ЦАП
$190.00
NVIDIA MCP7Y10-N002, совместимый с двухпортовым OSFP 2G InfiniBand NDR длиной 7 м (800 фута) с 2x400G QSFP112 Breakout ЦАП
$190.00