
O “Super Bowl” da indústria de IA começou, e a estrela de hoje é Jensen Huang.
Empreendedores de tecnologia, desenvolvedores, cientistas, investidores, clientes da NVIDIA, parceiros e a mídia do mundo todo se aglomeraram na pequena cidade de San Jose em busca do homem da jaqueta de couro preta.
A palestra de Huang no GTC 2025 começou às 10:00 da manhã, horário local, em 18 de março, mas às 6:00 da manhã, o fundador da Doges AI, Abraham Gomez, já havia garantido o segundo lugar na fila do SAP Center, na esperança de "conseguir um assento na primeira fila". Às 8:00 da manhã, a fila do lado de fora se estendia por mais de um quilômetro.
Bill, CEO da startup de geração musical Wondera, sentou-se na primeira fila vestindo sua própria jaqueta de couro preta “como uma homenagem a Jensen”. Enquanto a multidão estava entusiasmada, Huang adotou um tom mais comedido em comparação à energia de rockstar do ano passado. Desta vez, ele teve como objetivo reafirmar a estratégia da NVIDIA, enfatizando repetidamente “scale up” ao longo de seu discurso.
No ano passado, Huang declarou que “o futuro é generativo”; este ano, ele afirmou que “a IA está em um ponto de inflexão”. Sua palestra se concentrou em três anúncios principais:
1. Blackwell GPU entra em produção total
“A demanda é incrível, e por um bom motivo — a IA está em um ponto de inflexão”, afirmou Huang. Ele destacou a crescente necessidade de poder de computação impulsionado por sistemas de inferência de IA e cargas de trabalho de treinamento de agentes.
2. Blackwell NVLink 72 com software Dynamo AI
A nova plataforma oferece 40x o desempenho de fábrica de IA do NVIDIA Hopper. “À medida que escalamos a IA, a inferência dominará as cargas de trabalho na próxima década”, explicou Huang. Apresentando o Blackwell Ultra, ele reviveu uma frase clássica: “Quanto mais você compra, mais economiza. Na verdade, ainda melhor — quanto mais você compra, mais ganha.”
3. Roteiro anual da NVIDIA para infraestrutura de IA
A empresa delineou três pilares de infraestrutura de IA: nuvem, empresa e robótica.
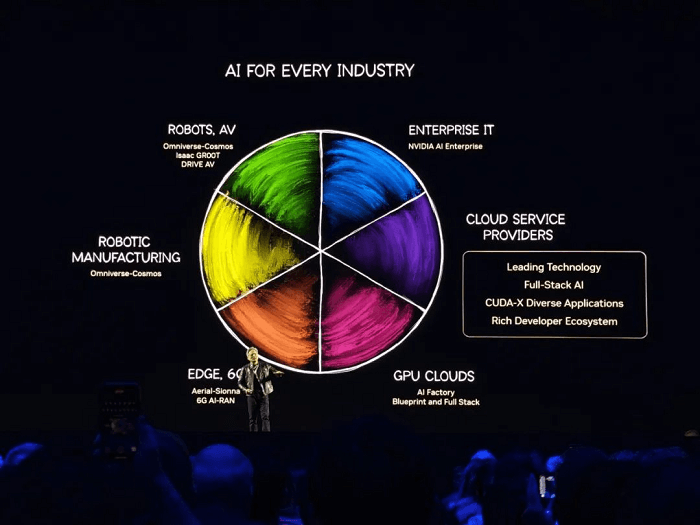
Huang também revelou duas novas GPUs: a Blackwell Ultra GB300 (uma Blackwell atualizada) e a arquitetura Vera Rubin de última geração com Rubin Ultra.
A NVIDIA revelou duas novas GPUs: a Blackwell Ultra GB300, uma versão atualizada da Blackwell do ano passado, e uma arquitetura de chip completamente nova chamada Vera Rubin, junto com o Rubin Ultra.
A crença inabalável de Jensen Huang na Lei de Escala está enraizada nos avanços alcançados por meio de várias gerações de arquiteturas de chips.
Seu discurso principal focou principalmente em “Computação Extrema para Inferência de IA em Grande Escala”.
Na inferência de IA, escalar de usuários individuais para implantações em larga escala requer encontrar o equilíbrio ideal entre desempenho e custo-eficiência. Os sistemas não devem apenas garantir respostas rápidas para os usuários, mas também maximizar o rendimento geral (tokens por segundo) aprimorando os recursos de hardware (por exemplo, FLOPS, largura de banda HBM) e otimizando o software (por exemplo, arquitetura, algoritmos), desbloqueando, em última análise, o valor econômico da inferência em larga escala.
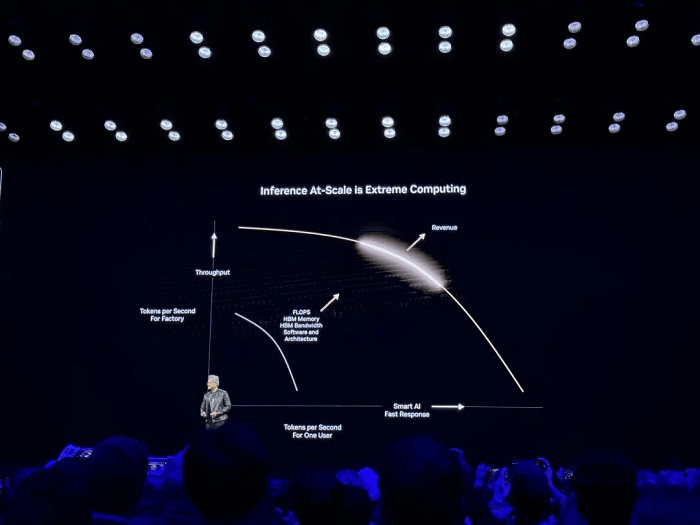
Abordando preocupações sobre a desaceleração da Lei de Escala, Jensen Huang expressou um ponto de vista contrastante, alegando que “os métodos e tecnologias de expansão emergentes estão acelerando a melhoria da IA em um ritmo sem precedentes”.
Enfrentando uma pressão considerável, Huang parecia visivelmente tenso durante a transmissão ao vivo, frequentemente bebendo água durante os intervalos e parecendo um pouco rouco no final de sua apresentação.
À medida que o mercado de IA faz a transição de “treinamento” para “inferência”, concorrentes como AMD, Intel, Google e Amazon estão introduzindo chips de inferência especializados para reduzir a dependência da NVIDIA. Enquanto isso, startups como Cerebras, Groq e Tenstorrent estão acelerando o desenvolvimento de aceleradores de IA, e empresas como a DeepSeek visam minimizar a dependência de GPUs caras otimizando seus modelos. Essas dinâmicas contribuem para os desafios que Huang enfrenta. Embora a NVIDIA domine mais de 90% do mercado de treinamento, Huang está determinado a não abrir mão do mercado de inferência em meio à competição cada vez mais intensa. O banner de inscrição do evento perguntava corajosamente: “O que vem por aí na IA começa aqui”.

Os principais destaques da palestra de Jensen Huang, conforme resumido no local pelo “FiberMall”, incluem:
O mundo entendeu mal a lei da escala
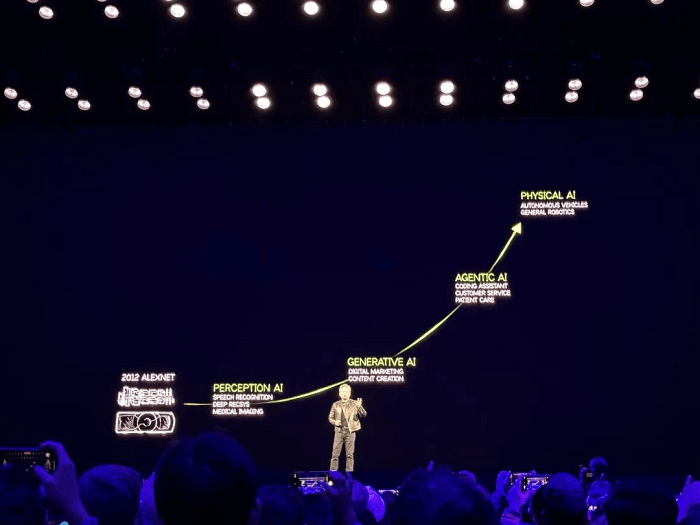
A IA representou uma oportunidade transformadora para a NVIDIA na última década, e Huang continua profundamente confiante em seu potencial. Neste GTC, ele revisitou dois slides de sua palestra de janeiro na CES:
O primeiro slide descreveu os estágios do desenvolvimento da IA: IA de percepção, IA generativa, IA de agente e IA física.
O segundo slide descreveu as três fases da Lei de Escala: Escala pré-treinamento, Escala pós-treinamento e Escala durante o teste (Pensamento Longo).
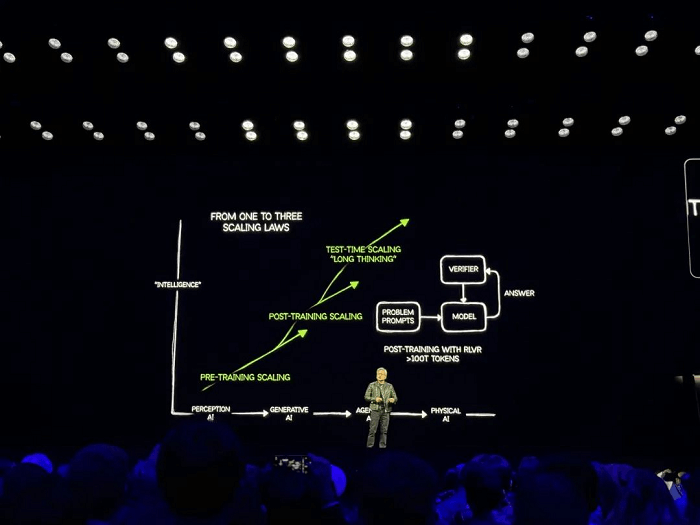
Huang ofereceu uma perspectiva que contrasta fortemente com as visões convencionais, afirmando que as preocupações sobre a desaceleração da Lei de Escala são equivocadas. Em sua visão, métodos e tecnologias de expansão emergentes estão impulsionando o progresso da IA em um ritmo sem precedentes.
Como um firme defensor da Lei de Escala, a convicção de Huang decorre do fato de que os avanços globais da IA estão intimamente ligados aos negócios de GPU da NVIDIA. Ele continuou descrevendo a evolução da IA que pode "raciocinar passo a passo", enfatizando o papel da inferência e do aprendizado por reforço na condução de demandas computacionais. À medida que a IA atinge um "ponto de inflexão", os provedores de serviços de nuvem estão cada vez mais exigindo GPUs, com Huang estimando que o valor da construção do data center chegará a US$ 1 trilhão.
Huang elaborou que as bibliotecas de aceleração de GPU NVIDIA CUDA-X e microsserviços agora atendem a quase todos os setores. Em sua visão, cada empresa operará duas fábricas no futuro: uma para produzir bens e outra para gerar IA.

A IA está se expandindo para vários campos no mundo todo, incluindo robótica, veículos autônomos, fábricas e redes sem fio. Jensen Huang destacou que uma das primeiras aplicações da IA foi em veículos autônomos, afirmando: “As tecnologias que desenvolvemos são usadas por quase todas as empresas de veículos autônomos”, tanto em data centers quanto na indústria automotiva.
Jensen anunciou um marco significativo na direção autônoma: a General Motors, a maior montadora dos Estados Unidos, está adotando a IA, simulação e computação acelerada da NVIDIA para desenvolver seus veículos, fábricas e robôs de próxima geração. Ele também apresentou o NVIDIA Halos, um sistema de segurança integrado que combina as soluções de segurança de hardware e software automotivo da NVIDIA com pesquisa de IA de ponta em segurança de veículos autônomos.

Passando para data centers e inferência, Huang compartilhou que a NVIDIA Blackwell entrou em produção em larga escala, apresentando sistemas de vários parceiros da indústria. Satisfeito com o potencial da Blackwell, ele elaborou sobre como ela suporta escalabilidade extrema, explicando: "Nosso objetivo é abordar um desafio crítico, e isso é o que chamamos de inferência".
Huang enfatizou que a inferência envolve a geração de tokens, um processo essencial para empresas. Essas fábricas de IA que geram tokens devem ser construídas com eficiência e desempenho excepcionais. Com os modelos de inferência mais recentes capazes de resolver problemas cada vez mais complexos, a demanda por tokens continuará a aumentar.
Para acelerar ainda mais a inferência em larga escala, Huang anunciou o NVIDIA Dynamo, uma plataforma de software de código aberto projetada para otimizar e dimensionar modelos de inferência em fábricas de IA. Descrevendo-o como “essencialmente o sistema operacional para fábricas de IA”, ele ressaltou seu potencial transformador.
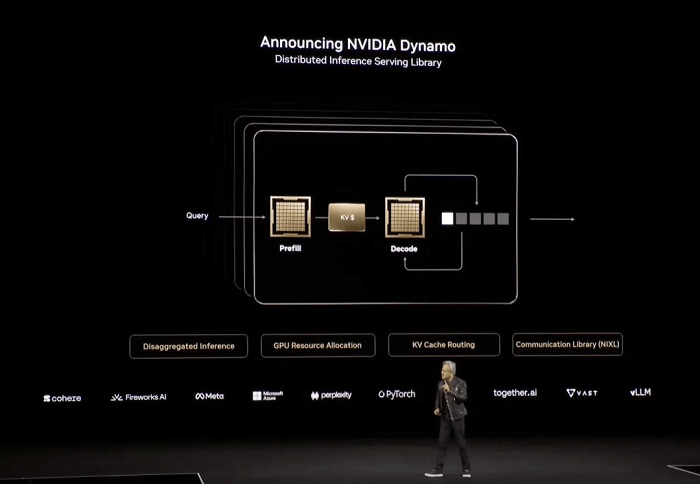
“Compre mais, economize mais, ganhe mais”
A NVIDIA também revelou duas novas GPUs: a Blackwell Ultra GB300, uma versão atualizada da Blackwell do ano passado, e as arquiteturas de chip Vera Rubin e Rubin Ultra de próxima geração.
O Blackwell Ultra GB300 estará disponível no segundo semestre deste ano.
Vera Rubin tem lançamento previsto para o segundo semestre do ano que vem.
O Rubin Ultra está previsto para o final de 2027.
Além disso, Huang revelou o roteiro para os próximos chips. A arquitetura para a geração além do Rubin foi chamada de Feynman, prevista para 2028. O nome provavelmente homenageia o renomado físico teórico Richard Feynman.
Dando continuidade à tradição da NVIDIA, cada arquitetura de GPU recebe o nome de cientistas proeminentes: Blackwell, em homenagem ao estatístico David Harold Blackwell, e Rubin, em homenagem a Vera Rubin, a astrofísica pioneira que confirmou a existência da matéria escura.
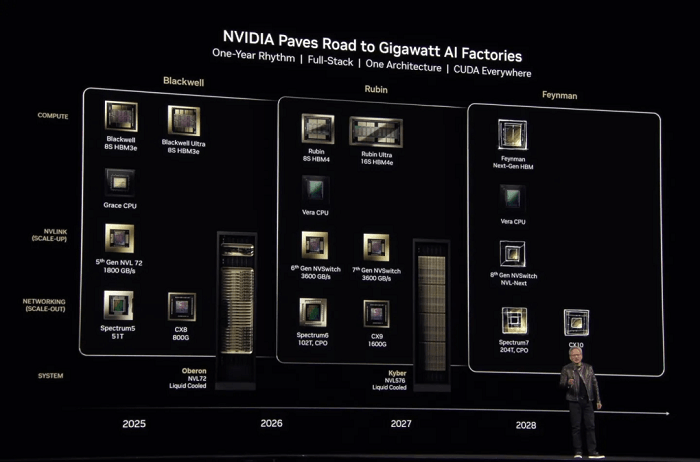
Na última década, a NVIDIA lançou 13 gerações de arquiteturas de GPU, com média de mais de uma nova geração por ano. Isso inclui nomes icônicos como Tesla, Fermi, Kepler, Maxwell, Pascal, Turing, Ampere, Hopper e, mais recentemente, Rubin. O comprometimento de Huang com a Scaling Law tem sido uma força motriz por trás dessas inovações.
Em relação ao desempenho, o Blackwell Ultra oferece atualizações substanciais em comparação ao Blackwell, incluindo um aumento na capacidade de memória HBM3e de 192 GB para 288 GB. A NVIDIA também comparou o Blackwell Ultra ao chip H100 lançado em 2022, observando sua capacidade de fornecer 1.5 vezes o desempenho de inferência FP4. Isso se traduz em uma vantagem significativa: um cluster NVL72 executando o modelo DeepSeek-R1 671B pode fornecer respostas interativas em 10 segundos, em comparação com 1.5 minutos com o H100. O Blackwell Ultra processa 1,000 tokens por segundo, 10 vezes mais que o H100.

A NVIDIA também oferecerá o sistema de rack único GB300 NVL72, com:
1.1 exaflops de FP4,
20 TB de memória HBM,
40 TB de “memória rápida”
130 TB/s de largura de banda NVLink e
14.4 TB/s de velocidade de rede.
Reconhecendo o desempenho impressionante do Blackwell Ultra, Huang brincou sobre suas preocupações de que os clientes poderiam pular a compra do H100. Ele se referiu a si mesmo com humor como o "chefe destruidor de receitas", admitindo que, em casos limitados, os chips Hopper são "ok", mas tais cenários são raros. Concluindo com sua linha clássica, ele declarou: "Compre mais, economize mais. É ainda melhor do que isso. Agora, quanto mais você compra, mais você ganha."
A arquitetura Rubin representa um passo inovador para a NVIDIA. Jensen Huang enfatizou: “Essencialmente, tudo, exceto o rack, é totalmente novo.”
Desempenho FP4 aprimorado: as GPUs Rubin alcançam 50 petaflops, superando os 20 petaflops da Blackwell. O Rubin Ultra compreende um único chip com duas GPUs Rubin interconectadas, fornecendo 100 petaflops de desempenho FP4 — o dobro do Rubin — e quase quadruplicando a memória para 1 TB.
Rack NVL576 Rubin Ultra: oferece 15 exaflops de inferência FP4 e 5 exaflops de treinamento FP8, apresentando desempenho 14 vezes maior que os racks Blackwell Ultra.

Huang também explicou a integração da tecnologia fotônica para escalar sistemas, incorporando-a aos switches de rede fotônica de silício Spectrum-X e Quantum-X da NVIDIA. Essas inovações misturam comunicação eletrônica e óptica, permitindo que fábricas de IA interconectem milhões de GPUs em todos os locais, ao mesmo tempo em que reduzem o consumo de energia e os custos.

Os switches são excepcionalmente eficientes, alcançando 3.5 vezes mais eficiência energética, 63 vezes mais integridade de sinal, 10 vezes mais resiliência de rede e implantação mais rápida em comparação aos métodos tradicionais.
Computadores para a era da IA
Expandindo além de chips de nuvem e data centers, a NVIDIA lançou supercomputadores de IA de desktop equipados com a plataforma NVIDIA Grace Blackwell. Projetados para desenvolvedores de IA, pesquisadores, cientistas de dados e estudantes, esses dispositivos permitem prototipagem, ajuste fino e inferência de grandes modelos no nível de desktop.

Os principais produtos incluem:
Supercomputadores DGX: Apresentando a plataforma NVIDIA Grace Blackwell para recursos inigualáveis de implantação local ou na nuvem.
Estação DGX: Uma estação de trabalho de alto desempenho equipada com Blackwell Ultra.

Llama Nemotron Inference Series: Uma família de modelos de IA de código aberto que oferece raciocínio, codificação e tomada de decisão multietapas aprimorados. Os aprimoramentos da NVIDIA aumentam a precisão em 20%, a velocidade de inferência em 5x e a eficiência de custo operacional. Empresas líderes como Microsoft, SAP e Accenture estão fazendo parceria com a NVIDIA para desenvolver novos modelos de inferência.
A Era da Robótica de Uso Geral
Jensen Huang declarou que os robôs são a próxima indústria de US$ 10 trilhões, abordando uma escassez global de mão de obra que deve atingir 50 milhões de trabalhadores até o final do século. A NVIDIA revelou o Isaac GR00T N1, o primeiro modelo aberto e totalmente personalizável de inferência humanoide e base de habilidades do mundo, juntamente com uma nova estrutura de geração de dados e aprendizado de robótica. Isso abre caminho para a próxima fronteira em IA.
Além disso, a NVIDIA lançou o Cosmos Foundation Model para desenvolvimento de IA física. Este modelo aberto e personalizável capacita os desenvolvedores com controle sem precedentes sobre a geração de mundos, criando conjuntos de dados vastos e sistematicamente infinitos por meio da integração com o Omniverse.
Huang também apresentou Newton, um mecanismo de física de código aberto para simulação de robótica desenvolvido em conjunto com o Google DeepMind e a Disney Research. Em um momento memorável, um robô em miniatura chamado “Blue”, que já havia aparecido no GTC do ano passado, surgiu no palco novamente, encantando o público.

A jornada contínua da NVIDIA tem sido sobre encontrar aplicações para suas GPUs, desde as inovações de IA com AlexNet há mais de uma década até o foco atual em robótica e IA física. As aspirações da NVIDIA para a próxima década darão frutos? O tempo dirá.
Produtos relacionados:
-
 Compatível com NVIDIA MMA4Z00-NS400 400G OSFP SR4 Flat Top PAM4 850nm 30m em OM3/50m em OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
Compatível com NVIDIA MMA4Z00-NS400 400G OSFP SR4 Flat Top PAM4 850nm 30m em OM3/50m em OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
 Compatível com NVIDIA MMS4X00-NS400 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Módulo transceptor óptico
$700.00
Compatível com NVIDIA MMS4X00-NS400 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Módulo transceptor óptico
$700.00
-
 Módulo transceptor óptico compatível com NVIDIA MMA1Z00-NS400 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC
$550.00
Módulo transceptor óptico compatível com NVIDIA MMA1Z00-NS400 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC
$550.00
-
 NVIDIA MMS1Z00-NS400 Compatível 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 com Módulo Transceptor Óptico FEC
$700.00
NVIDIA MMS1Z00-NS400 Compatível 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 com Módulo Transceptor Óptico FEC
$700.00
-
 Compatível com NVIDIA MMA4Z00-NS 800Gb/s Porta dupla OSFP 2x400G SR8 PAM4 850nm 100m DOM Módulo transceptor óptico MPO-12 MMF duplo
$650.00
Compatível com NVIDIA MMA4Z00-NS 800Gb/s Porta dupla OSFP 2x400G SR8 PAM4 850nm 100m DOM Módulo transceptor óptico MPO-12 MMF duplo
$650.00
-
 Compatível com NVIDIA MMA4Z00-NS-FLT 800Gb/s Porta dupla OSFP 2x400G SR8 PAM4 850nm 100m DOM Módulo transceptor óptico MPO-12 MMF duplo
$650.00
Compatível com NVIDIA MMA4Z00-NS-FLT 800Gb/s Porta dupla OSFP 2x400G SR8 PAM4 850nm 100m DOM Módulo transceptor óptico MPO-12 MMF duplo
$650.00
-
 Compatível com NVIDIA MMS4X00-NM 800Gb/s Porta dupla OSFP 2x400G PAM4 1310nm 500m DOM Módulo transceptor óptico MTP/MPO-12 SMF duplo
$900.00
Compatível com NVIDIA MMS4X00-NM 800Gb/s Porta dupla OSFP 2x400G PAM4 1310nm 500m DOM Módulo transceptor óptico MTP/MPO-12 SMF duplo
$900.00
-
 Compatível com NVIDIA MMS4X00-NM-FLT 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Módulo transceptor óptico MTP/MPO-12 SMF duplo
$1199.00
Compatível com NVIDIA MMS4X00-NM-FLT 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Módulo transceptor óptico MTP/MPO-12 SMF duplo
$1199.00
-
 Módulo transceptor óptico compatível com NVIDIA MMS4X50-NM OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF
$1200.00
Módulo transceptor óptico compatível com NVIDIA MMS4X50-NM OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF
$1200.00
-
 NVIDIA MCP7Y00-N001 Compatível com 1 m (3 pés) 800 Gb OSFP de porta dupla a 2x400G OSFP InfiniBand NDR Breakout Cabo de cobre de conexão direta
$160.00
NVIDIA MCP7Y00-N001 Compatível com 1 m (3 pés) 800 Gb OSFP de porta dupla a 2x400G OSFP InfiniBand NDR Breakout Cabo de cobre de conexão direta
$160.00
-
 NVIDIA MCA7J60-N004 Compatível com 4m (13 pés) 800G OSFP de duas portas a 2x400G OSFP InfiniBand NDR Breakout Cabo de cobre ativo
$800.00
NVIDIA MCA7J60-N004 Compatível com 4m (13 pés) 800G OSFP de duas portas a 2x400G OSFP InfiniBand NDR Breakout Cabo de cobre ativo
$800.00
-
 NVIDIA MCP7Y10-N001 compatível com 1m (3 pés) 800G InfiniBand NDR OSFP de porta dupla para 2x400G QSFP112 Breakout DAC
$155.00
NVIDIA MCP7Y10-N001 compatível com 1m (3 pés) 800G InfiniBand NDR OSFP de porta dupla para 2x400G QSFP112 Breakout DAC
$155.00
-
 NVIDIA MCP7Y50-N001 Compatível com 1m (3 pés) 800G InfiniBand NDR OSFP de porta dupla para 4x200G OSFP Breakout DAC
$255.00
NVIDIA MCP7Y50-N001 Compatível com 1m (3 pés) 800G InfiniBand NDR OSFP de porta dupla para 4x200G OSFP Breakout DAC
$255.00
-
 Compatível com NVIDIA MCA7J70-N004 4m (13 pés) 800G InfiniBand NDR Twin-port OSFP para 4x200G OSFP Breakout ACC
$1100.00
Compatível com NVIDIA MCA7J70-N004 4m (13 pés) 800G InfiniBand NDR Twin-port OSFP para 4x200G OSFP Breakout ACC
$1100.00
-
 NVIDIA MCA4J80-N003 compatível com 800G Twin-port 2x400G OSFP para 2x400G OSFP InfiniBand NDR cabo de cobre ativo
$600.00
NVIDIA MCA4J80-N003 compatível com 800G Twin-port 2x400G OSFP para 2x400G OSFP InfiniBand NDR cabo de cobre ativo
$600.00
-
 NVIDIA MCP4Y10-N002-FLT compatível com 2 m (7 pés) 800G de porta dupla 2x400G OSFP a 2x400G OSFP InfiniBand NDR DAC passivo, parte superior plana em uma extremidade e parte superior plana na outra
$300.00
NVIDIA MCP4Y10-N002-FLT compatível com 2 m (7 pés) 800G de porta dupla 2x400G OSFP a 2x400G OSFP InfiniBand NDR DAC passivo, parte superior plana em uma extremidade e parte superior plana na outra
$300.00
-
 NVIDIA MCP4Y10-N00A Compatível com 0.5 m (1.6 pés) 800G Porta dupla 2x400G OSFP a 2x400G OSFP InfiniBand NDR Passivo Cabo de cobre de conexão direta
$105.00
NVIDIA MCP4Y10-N00A Compatível com 0.5 m (1.6 pés) 800G Porta dupla 2x400G OSFP a 2x400G OSFP InfiniBand NDR Passivo Cabo de cobre de conexão direta
$105.00
-
 NVIDIA MCA4J80-N003-FLT compatível com 3m (10 pés) 800G de porta dupla 2x400G OSFP a 2x400G OSFP InfiniBand NDR cabo de cobre ativo, parte superior plana em uma extremidade e parte superior plana na outra
$600.00
NVIDIA MCA4J80-N003-FLT compatível com 3m (10 pés) 800G de porta dupla 2x400G OSFP a 2x400G OSFP InfiniBand NDR cabo de cobre ativo, parte superior plana em uma extremidade e parte superior plana na outra
$600.00