
회사 개요
인공 지능(AI)은 의심할 여지 없이 정보 기술 분야의 핵심 주제가 되었으며, 지난 100년 동안 전례 없는 속도로 광범위한 관심을 사로잡았습니다. 이 주장은 Fortune 500 및 Global 2000 기업의 80명 이상의 최고 정보 책임자(CIO)를 대상으로 한 Futurum Group 설문 조사에서 뒷받침됩니다. 결과에 따르면 응답자의 약 50%가 현재 AI 파일럿 프로그램을 운영하고 있습니다. 또한 이 연구에서는 이러한 IT 리더의 XNUMX% 이상이 AI와 같은 신기술 구현을 가장 중요한 과제로 보고 있다는 사실을 확인했습니다. 또한 현대화, 혁신 및 AI 도입은 IT 조달 결정에 영향을 미치는 상위 XNUMX가지 요인에 지속적으로 포함됩니다.

이 기사에서는 Intel® Gaudi® 2 AI 가속기와 기업에 미치는 잠재적 영향에 대한 심층 분석을 다룹니다. 이 연구는 추론 워크로드 테스트 동안 Intel® Gaudi® 3 AI 가속기의 성능을 주요 경쟁업체의 성능과 비교합니다. 이러한 테스트는 두 가지 고유한 Llama 3.1 대규모 언어 모델(LLM)에 초점을 맞추었습니다. IT 및 비즈니스 임원에게 실용적이고 실행 가능한 통찰력을 제공하기 위해 AI 워크로드 성능을 실행하고 측정하는 특수 AI 테스트 플랫폼이 개발되었습니다. 이 연구는 상업용 AI 추론 플랫폼인 Kamiwaza(https://www.kamiwaza.ai/)와 협력하여 수행되었습니다. 함께 Kamiwaza 스택을 활용하는 AI 테스트 제품군을 설계하여 다양한 하드웨어 및 소프트웨어 플랫폼에서 AI LLM의 추론 성능을 정확하게 측정할 수 있었습니다.
주요 연구 결과 :
- 일련의 LLM 추론 테스트에서 Intel Gaudi 3는 Nvidia H100과 비슷한 성능을 보였습니다.
- Intel Gaudi 3의 성능은 H100에 비해 15% 낮을 수도 있고 30% 높을 수도 있는데, 시나리오에 따라 다릅니다.
- Intel Gaudi 3는 작은 입력과 큰 출력을 사용하는 추론 세션에서 H100보다 우수한 성과를 보인 반면, Nvidia는 큰 입력과 작은 출력을 사용하는 세션에서 탁월한 성과를 보였습니다.
- 비용을 고려할 때, Intel Gaudi 3는 Nvidia H100보다 달러당 더 높은 작업 부하를 달성했으며 그 이점은 10%에서 2.5배까지 다양합니다.
엔터프라이즈 AI 환경
AI는 지난 1년 동안 많은 회사의 초점이 되었지만, 대부분의 기업은 아직 AI 적용의 초기 단계에 있습니다. 기업이 시범 프로젝트를 시작하면서 주로 엔터프라이즈 데이터와 기타 지식 소스를 활용하여 프로덕션 환경을 위한 기존 기반 대규모 언어 모델(LLM)을 개선하는 데 중점을 둡니다.
데이터 프라이버시와 거버넌스에 대한 우려는 여전히 크며, 이는 많은 회사가 클라우드 솔루션을 도입하는 것 외에도 AI 도구를 로컬에 배포하는 것을 모색하는 이유 중 하나입니다. 학습 데이터와 런타임 추론 데이터 세트에 대한 제어를 유지하고 효과적인 거버넌스 프레임워크와 윤리적 AI 관행을 확립하려면 데이터, 툴체인 및 인프라에 대한 더 큰 제어가 필요합니다. 단일 상호 작용 세션 추론은 최소한의 하드웨어로 달성할 수 있지만, 대규모 배포에는 일반적으로 하드웨어 가속기가 필요하며, 특히 검색 증강 생성(RAG)과 같은 기술을 활용할 때 더욱 그렇습니다. 따라서 기업은 AI 가속기를 선택할 때 추론 워크로드의 가격과 성능을 신중하게 평가해야 합니다. 이는 AI 애플리케이션이 프로덕션 단계에 도달하면 전반적인 투자 수익률(ROI)에 직접적인 영향을 미치기 때문입니다.
확장성과 상호 연결성이 매우 중요한 엔터프라이즈 AI 구축 분야에서는 고속 네트워킹 기술의 통합이 Intel Gaudi3 및 Nvidia H100과 같은 가속기의 성능 최적화에 중요한 역할을 합니다. 예를 들어, 400G 및 800G 이더넷 솔루션을 활용하는 것과 함께 NDR 인피니밴드 초저지연 데이터 전송을 위해 여러 가속기의 원활한 클러스터링을 지원하여 추론 작업 중에도 대용량 데이터 세트를 효율적으로 처리할 수 있습니다. 광통신 제품 및 솔루션 전문 공급업체인 FiberMall은 AI 지원 네트워크에 최적화된 비용 효율적인 400G 및 800G 트랜시버와 케이블을 제공하며, 탁월한 대역폭으로 데이터 센터와 클라우드 환경을 지원합니다. 이를 통해 분산형 AI 시스템의 전반적인 처리량을 향상시킬 뿐만 아니라 실시간 처리의 병목 현상을 해결하여 Gaudi3 또는 H100 투자에 대한 ROI를 극대화하려는 기업에 이상적인 선택입니다.
LLM 추론
LLM을 사용하여 학습 모델에서 유용한 결과를 생성하는 프로세스를 추론이라고 합니다. LLM 추론은 일반적으로 사전 채우기와 디코딩의 두 단계로 구성됩니다. 이 두 단계는 함께 작동하여 입력 프롬프트에 대한 응답을 생성합니다.
첫째, 사전 채우기 단계는 텍스트를 토큰이라고 알려진 AI 표현으로 변환합니다. 이 토큰화 프로세스는 일반적으로 CPU에서 발생하고 토큰은 AI 가속기로 전송되어 출력을 생성하고 디코딩을 수행합니다. 모델은 이 프로세스를 반복적으로 실행하며, 각각의 새로운 토큰은 다음 토큰의 생성에 영향을 미칩니다. 궁극적으로 이 프로세스가 끝나면 생성된 시퀀스가 토큰에서 읽을 수 있는 텍스트로 다시 변환됩니다. 이 프로세스에 사용되는 주요 도구는 추론에 최적화된 특수 소프트웨어 스택입니다. 몇 가지 일반적인 예로는 오픈 소스 프로젝트 vLLM, Hugging Face의 TGI, 특정 AI 가속기에 대한 특수 버전이 있습니다. Nvidia는 TensorRT-LLM이라는 최적화된 추론 스택을 제공하는 반면 Intel은 Optimum Habana라는 최적화된 소프트웨어 스택을 제공합니다.
테스트 케이스를 엔터프라이즈 애플리케이션에 매핑
저희의 테스트는 입력 및 출력 토큰의 크기로 특징지어지는 네 가지 뚜렷한 조합 또는 워크로드 패턴에 초점을 맞춥니다. 일반적으로 이러한 조합은 기업이 프로덕션 배포 중에 마주칠 수 있는 다양한 실제 시나리오를 시뮬레이션하는 것을 목표로 합니다. 실제 사용에서 입력 및 출력 토큰의 크기는 범위가 매우 넓기 때문에 어떤 단일 조합과도 정확히 일치하지 않을 수 있습니다. 그러나 이 네 가지 조합은 잠재적 시나리오를 설명하기 위해 설계되었습니다.
일반적으로 소규모 토큰 입력 시나리오는 대화형 채팅과 같이 광범위한 컨텍스트가 없는 간단한 입력 명령에 해당합니다. 검색 증강 생성(RAG)을 사용하면 입력에 상당한 컨텍스트와 토큰이 추가되어 채팅 세션 중에 더 긴 입력 토큰과 더 짧은 출력 토큰이 생성됩니다. RAG를 사용한 콘텐츠 생성 또는 문서/코드 작성을 위한 반복적 최적화에서 워크로드는 긴 입력 및 출력 토큰으로 생성됩니다. 일반적인 시나리오에 대한 분석 결과, 긴 컨텍스트 입력 및 출력의 조합이 가장 가능성이 높은 시나리오이고 RAG가 없는 채팅 세션은 가장 가능성이 낮음을 나타냅니다. 나머지 두 시나리오는 다른 가능한 사용 사례를 나타냅니다. 추정 백분율은 고객과의 토론과 LLM에 대한 당사의 경험을 기반으로 합니다.
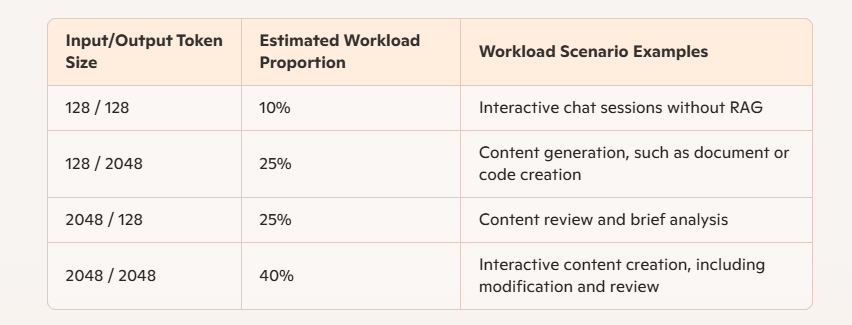
표 1: 추론 워크로드 유형 및 비율
표 1에서 볼 수 있듯이, 더 긴 출력을 가진 두 시나리오는 총 사용량의 65%를 차지하는 반면, 더 짧은 출력을 가진 두 시나리오는 나머지 35%를 차지합니다. 이러한 구분은 Intel Gaudi 3가 더 큰 출력 토큰이 있는 워크로드를 처리할 때 Nvidia H100보다 더 나은 성능을 발휘하기 때문에 중요합니다. 게다가 기업에서 가장 일반적인 워크로드의 경우 Gaudi 3 가속기는 Nvidia H100보다 성능 면에서 우위를 보입니다. 다음으로 이러한 워크로드의 자세한 결과를 제시하고 해당 가격/성능 비교를 제공합니다.
AI 추론 테스트 리뷰
입력 데이터를 효율적으로 처리하고 AI 가속기에 제출하기 위해 추론 소프트웨어는 입력 데이터를 토큰으로 변환한 다음 이러한 토큰을 일괄적으로 전송하여 전반적인 토큰 처리 속도를 개선합니다.
이전에 언급했듯이, 여러 LLM 추론 스택을 사용할 수 있습니다. 조사된 추론 프레임워크에는 다음이 포함됩니다.
- TGI: H100 및 Gaudi 3에 적합
- vLLM: H100 및 Gaudi 3에 적합
- Nvidia H100: Nvidia의 TensorRT-LLM 추론 스택
- Intel Gaudi 3: 최적의 Habana 추론 스택
참고: 우리는 각 가속기에 대한 최적의 솔루션을 선택했습니다. Nvidia H100 테스트의 경우 TensorRT-LLM을 사용했고 Intel Gaudi 3 테스트의 경우 Optimum Habana를 사용했습니다.
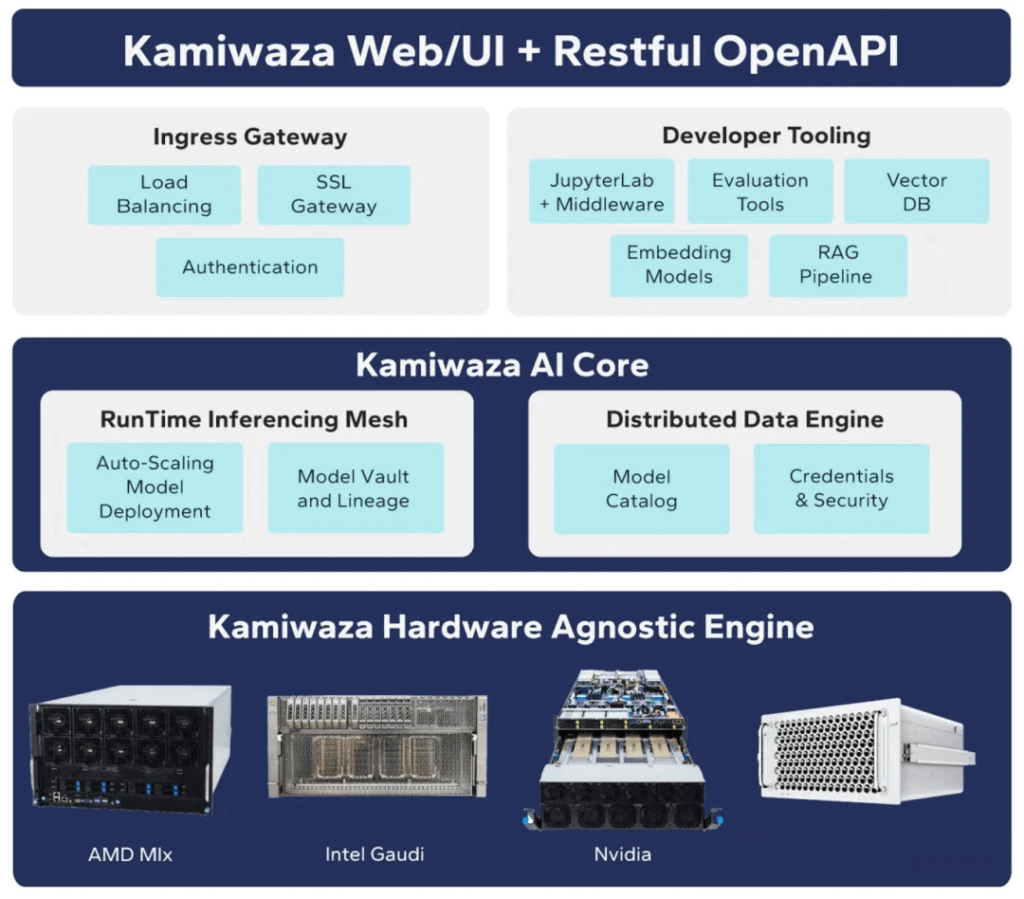
그림 1에서 볼 수 있듯이 Signal65/Kamiwaza AI 테스트 모음은 여러 GPU에서 다양한 LLM 모델의 추론 성능을 테스트하고 선택적으로 여러 노드를 지원할 수 있습니다. 추론에 사용된 하드웨어는 요청을 제출할 때 중요하지 않습니다. 이러한 프레임워크는 단순히 기본 도구입니다. Signal65/Kamiwaza Bench는 자동화 도구와 벤치마킹 기능을 제공하여 일괄 실험 구성에서 자동 실행, 로깅, 스코어링 및 시각화에 이르기까지 전체 벤치마킹 프로세스를 지원합니다.
테스트 방법론에는 두 가지 다른 오픈 소스 대규모 언어 모델을 사용하여 두 하드웨어 AI 가속기의 추론 성능을 비교하는 것이 포함되었습니다. 단일 AI 가속기 테스트의 경우 3.1GB 이상의 단일 가속기의 메모리 용량에 완전히 들어맞는 Llama 8 48B 모델을 선택했습니다. 3.1카드 서버 시스템을 완전히 활용하기 위해 Llama 70 16B 모델을 사용하여 추론 테스트 중에 8개의 가속기에 분산했습니다. 모든 추론은 가속기 처리량을 극대화하기 위해 배치 모드에서 수행되었습니다. 테스트는 대부분 양자화 기술을 사용하지 않고 "전체 가중치" 또는 FP70 데이터 크기에서 수행되었습니다. 일반적인 시나리오를 복제하는 데 중점을 두었고 주로 전체 가중치 모델을 테스트했습니다. 이러한 모델은 일반적으로 양자화된 데이터 크기를 사용하는 모델에 비해 훨씬 더 나은 결과, 즉 더 높은 정확도를 제공하기 때문입니다. XNUMXB 및 XNUMXB 모델의 경우 다양한 입력 및 출력 토큰 크기를 테스트했습니다. 단순화를 위해 네 가지 조합만 제시합니다. 모든 경우에 입력 및 출력 크기는 (입력/출력) 형식으로 표현됩니다.
또한, Llama 3.1 모델의 다중 노드 구성을 평가할 때, NDR 속도를 지원하는 InfiniBand와 같은 상호 연결 패브릭을 선택하는 것은 Gaudi3 및 H100 클러스터 간 동기화 유지에 필수적이며, 특히 입출력 토큰 비율이 높은 시나리오에서 더욱 그렇습니다. 800G 광 모듈기업은 탁월한 데이터 병렬 처리와 통신 오버헤드 감소를 달성하여 대규모 설정에서 추론 속도를 최대 50%까지 향상시킬 수 있습니다. FiberMall은 AI 통신 네트워크 분야의 선두 주자로, NDR 호환 스위치 및 400G DAC/AOC 케이블과 같은 가치 중심 솔루션을 제공하며, 이러한 솔루션은 기업, 액세스 및 무선 네트워크와 원활하게 통합됩니다.
비용 분석
가격 대비 성능을 비교하기 위해 두 가지 경쟁 솔루션에 대한 가격 데이터를 수집했습니다.
첫째, 공개적으로 접근 가능한 리셀러 Thinkmate.com에서 구성 견적을 받았는데, Thinkmate.com은 8개의 Nvidia H100 GPU가 장착된 GPU 서버에 대한 자세한 가격 데이터를 제공했습니다. 구체적인 정보는 표 2에 나와 있습니다. 또한, 여러 출처에서 "제안 소매 가격 $3"이라고 보고한 Gaudi 125,000 가속기에 대해 Intel에서 발표한 가격 데이터를 사용했습니다. Gaudi 3-XH20 시스템($32,613.22)의 기본 시스템 가격을 기반으로 시스템 가격을 구성한 다음, 보고된 8개의 Intel Gaudi 3 가속기($125,000) 비용을 추가하여 총 시스템 가격은 $157,613.22가 되었습니다. 이에 비해 8개의 Nvidia H100 GPU가 장착된 동일한 시스템은 $300,107.00입니다.
가격 계산
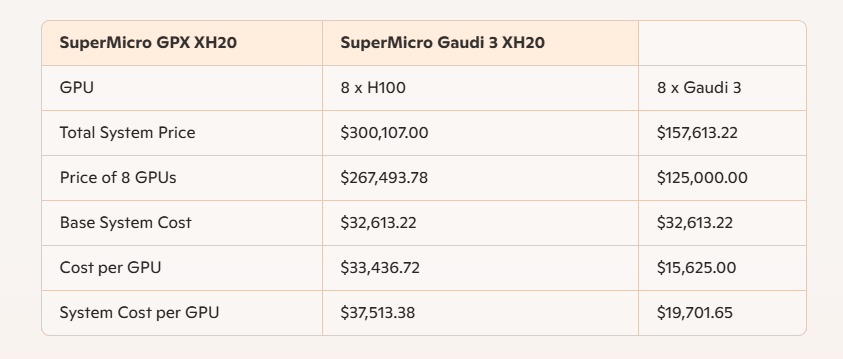
표 2: 100년 3월 10일 기준 H2025 및 Gaudi XNUMX AI 서버의 상세 가격.
성능 비교
이 맥락에서 "성능"이라는 용어는 두 가지 완전히 다른 AI 가속기 측정 방법에 적용되므로 매우 중요합니다. 성능 측정 기준 중 하나는 결과의 정확도로, 때때로 "모델 성능"이라고도 하는 핵심 요소입니다. 그러나 실험적 검증의 초점은 정확도가 아닙니다. 대신, 솔루션의 토큰 처리 속도를 결정하기 위해 초당 처리된 토큰 수로 표현되는 토큰 처리 속도를 측정하여 성능을 설명합니다.
또한, 더 높은 토큰 처리 속도가 모델 정확도를 손상시키지 않도록 하기 위해, 우리는 잘 알려진 여러 테스트를 사용하여 두 가속기의 모델 정확도를 측정했습니다. 결과는 Intel Gaudi 3와 Nvidia H100 간에 정확도에 유의미한 차이가 없음을 보여줍니다. 보고된 정확도는 약간씩 다르지만, 이러한 차이는 우리의 측정 오차 범위 내에 있습니다. 정확도 결과는 부록에 제공됩니다.
양자화된 모델 비교
우리는 덜 일반적인 사용 사례로 시작하지만, 이러한 결과는 "전체 가중치" 또는 FP16 데이터 유형 추론 모델에 비해 처리량이 더 높기 때문에 자주 인용됩니다. 다음 결과는 더 작은 "양자화된" 데이터 크기 FP8을 사용하여 모델 및 결과 품질을 희생하고 더 빠른 추론 성능을 달성합니다. 이러한 결과는 특정 사용자에게 관련이 있으며 그에 따라 제시됩니다.
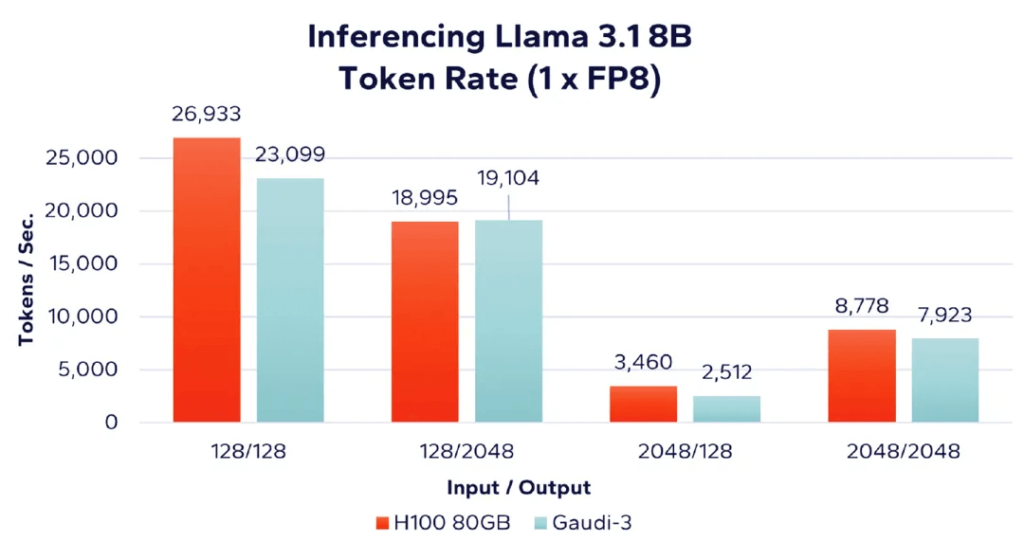
그림 2: 8비트 FP8 데이터 유형과의 추론 성능 비교
위 그림에서 "1 x FP8"은 단일 가속기 카드 사용을 나타내며 추론은 FP8 데이터 유형을 기반으로 합니다. 이러한 결과는 Intel Gaudi 100 가속기에 비해 추론 속도에서 양자화된 FP8 데이터 유형을 지원하는 Nvidia H3의 이점을 강조합니다. 그러나 H100이 FP8 데이터 유형에 최적화되었음에도 불구하고 Gaudi 3의 결과는 H100과 상당히 가깝습니다.
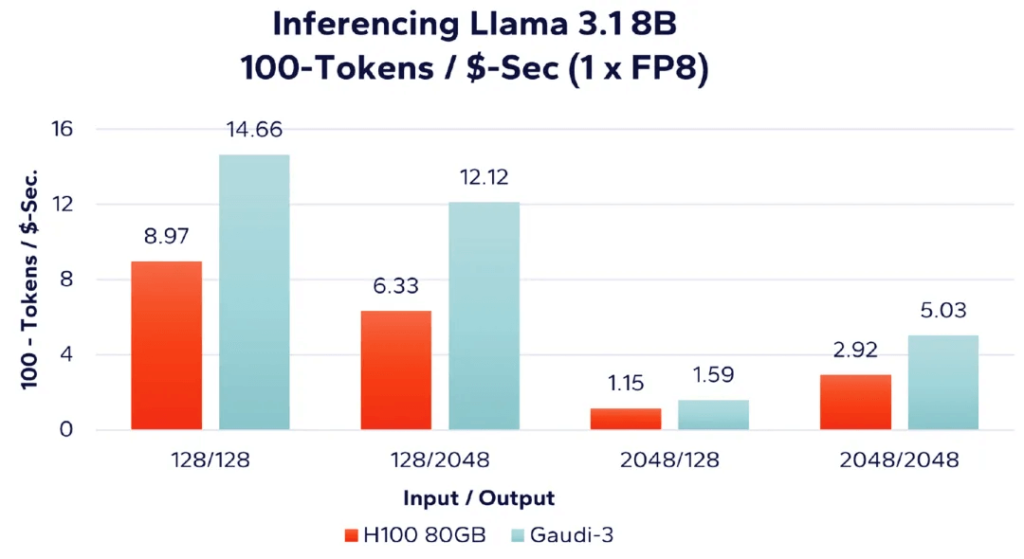
그림 3: 8비트 FP8 데이터 유형을 사용한 단위 비용당 토큰 처리 속도
그림 3에서 보듯이 단위 비용당 처리된 토큰 수를 평가할 때(토큰이 많을수록 좋음) Intel의 Gaudi 3가 네 가지 워크로드 조합 모두에서 더 나은 결과를 제공한다는 것을 알 수 있습니다. 예를 들어, 128개의 입력 토큰과 128개의 출력 토큰(그림 2의 가장 왼쪽 막대 그래프)을 표 1의 비용 데이터와 결합하면 다음과 같은 계산을 도출할 수 있습니다.
- Nvidia H100: 128/128 성능 = (26,933 토큰/초) / $300,107.00 = 0.089744(8.97%로 백분율 형태로 변환)
- Gaudi 3: 128/128 성능 = (23,099 토큰/초) / $157,613.22 = 0.1466 (백분율 형태로 변환하면 14.66%)
풀웨이트 라마 성능
그림 4에서는 단일 가속기와 100비트 데이터 유형을 사용하여 Llama 80 3B LLM을 실행하는 Nvidia H16 3.1GB 가속기와 Intel Gaudi 8 가속기의 성능을 비교합니다. 주목할 점은 Nvidia가 "FP16"을 사용하는 반면 Intel은 "BF16"을 사용하는데, 둘 다 정밀도는 동일하지만 표현 방식이 약간 다릅니다. 표시된 대로 Gaudi 3는 입력 대 출력 비율이 작은 워크로드에서 더 나은 성능을 보이는 반면, H100은 입력 대 출력 비율이 큰 워크로드에서 약간 더 우수한 성능을 보입니다.
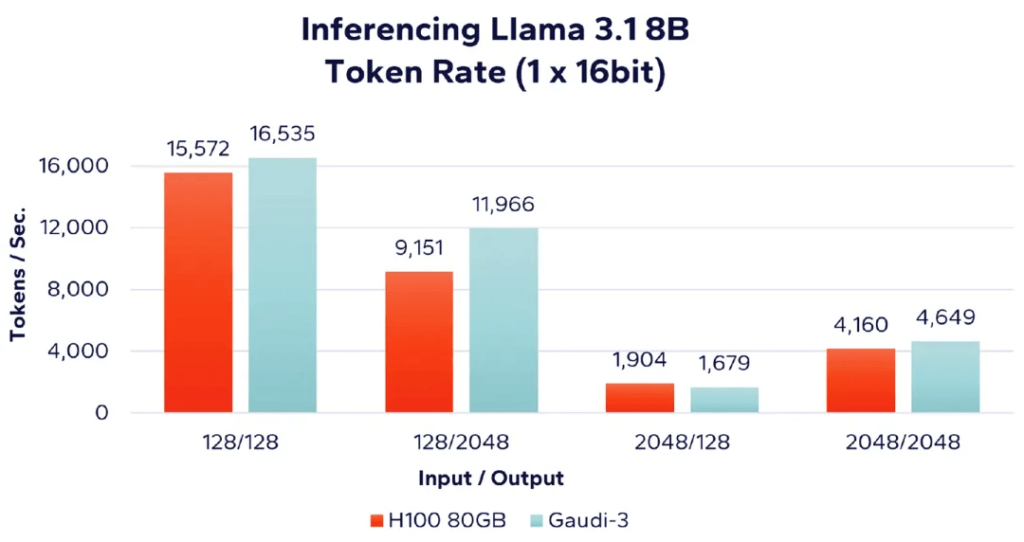
그림 4: Llama 8B – 단일 가속기 성능 비교(16비트)
다음으로, 더 큰 Llama 3.1 70B 모델을 사용하여 동일한 네 가지 작업 부하 시나리오에서 AI 가속기의 성능을 평가합니다. 메모리 요구 사항으로 인해 이 모델은 실행하기 위해 여러 개의 가속기가 필요합니다. 그림 5에서는 Nvidia H8과 Intel Gaudi 100을 비교하여 3개 가속기의 성능을 제시합니다. 레이블 "(8 x 16bit)"은 FP8 또는 BF16 데이터 유형의 16개 가속기를 사용함을 나타냅니다.
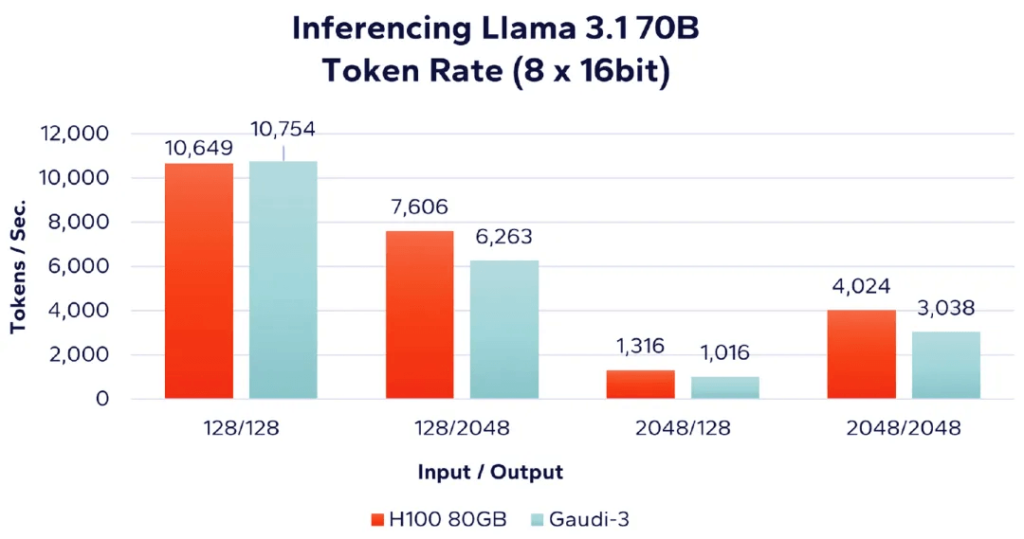
그림 5: Llama 70B – 8 가속기 성능 비교(16비트)
결과는 다시 한번 Nvidia가 입력 대 출력 비율이 높은 작업 부하에서 약간 더 나은 성능을 보인다는 것을 보여줍니다.
성능 및 비용 비교
앞서 언급했듯이, 많은 회사가 AI 가속기를 선택할 때 가장 중요하게 고려하는 사항 중 하나는 토큰 처리 속도와 비용 간의 관계입니다. 이 연구에서는 성능 대 비용 비율을 단위 비용당 처리된 토큰 수(토큰/초/USD)로 표현합니다.
먼저, 그림 6에서 단일 가속기를 사용하여 Llama 3.1 8B 모델을 실행한 결과를 분석하고 비용 요소를 통합합니다. 결과는 단위 비용당 처리된 토큰 수(즉, 초당/USD당 처리된 토큰)로 표시됩니다. 따라서 값이 높을수록 단위 비용당 처리된 토큰이 더 많음을 나타냅니다.
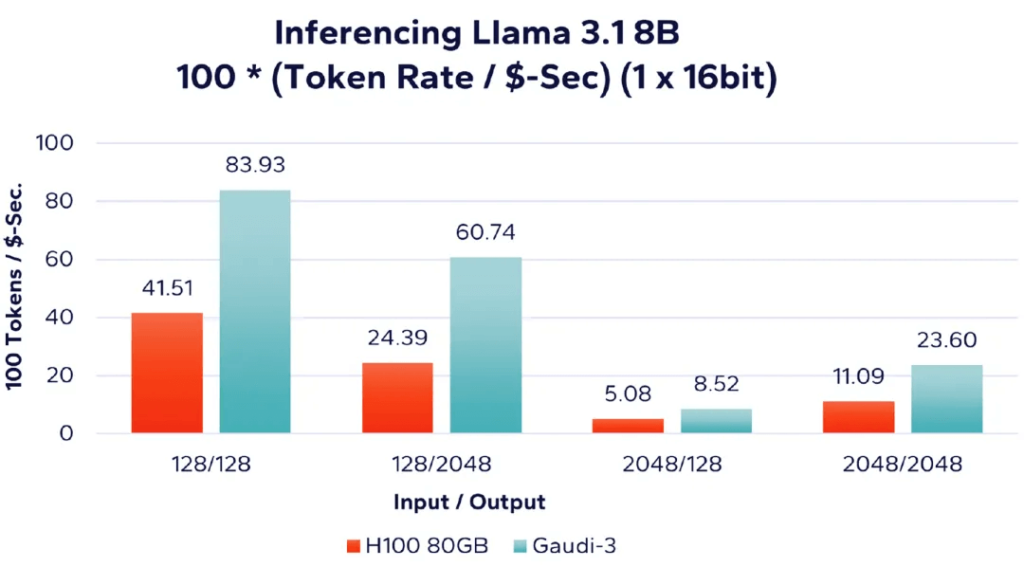
그림 6: Llama 8B – 달러당 단일 가속 토큰 처리 속도 비교(16비트)
다음으로, 그림 7은 여러 가속기를 사용하여 더 큰 Llama 3.1 70B 모델을 실행할 때 단위 비용당 성능을 보여줍니다. 이전과 마찬가지로 이 워크로드는 16개의 AI 가속기에서 전체 8비트 정밀도로 실행됩니다.
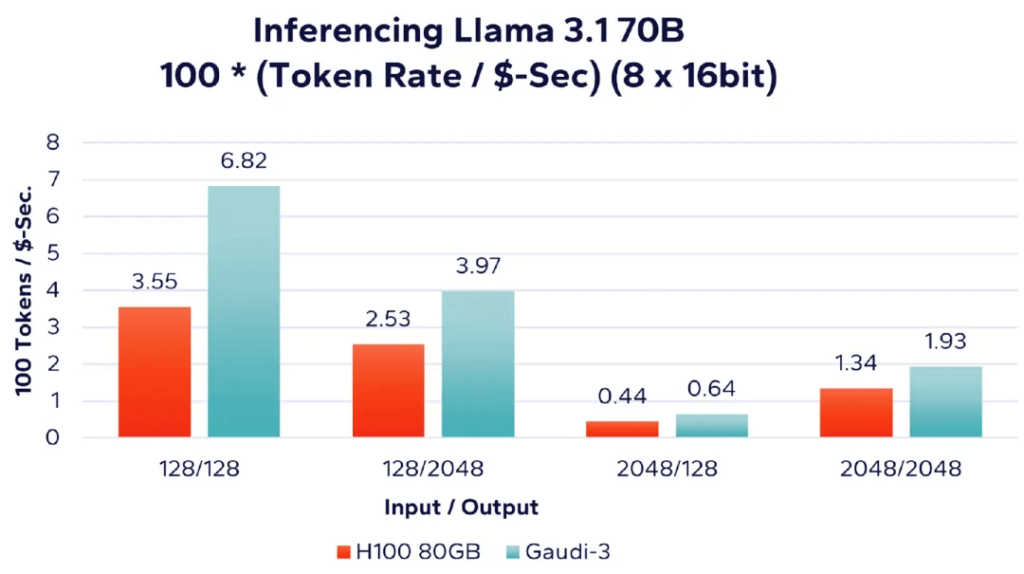
그림 7: Llama 70B – 8 가속기 토큰 처리 속도당 달러 비교(16비트)
성능 요약
여러 데이터 포인트에서 알 수 있듯이 성능 관점에서만 보면 Nvidia H100과 Intel Gaudi 3는 테스트된 Llama 3.1 워크로드 세트에서 비슷한 추론 속도를 제공합니다. 어떤 경우에는 Nvidia가 약간 앞서고, 다른 경우에는 Intel Gaudi 3가 더 나은 성능을 보입니다.
가격 데이터에 따르면 Intel의 Gaudi 3는 Nvidia H10에 비해 단위 비용당 100% 더 높은 성능을 제공하며, 어떤 경우에는 최대 2.5배까지 더 높습니다. 기업은 AI로 생산성을 높이기 위한 애플리케이션을 빠르게 개발하고 있습니다. AI 강화 애플리케이션이 보편화됨에 따라 경쟁 압력은 단순히 운영 AI 애플리케이션을 보유하는 것에서 품질과 비용 효율성을 기반으로 차별화하는 것으로 전환될 것입니다. 지금까지 AI 분야의 많은 보고와 과대 광고는 하이퍼스케일 배포와 최신 AI 모델을 개발하고 학습하는 데 사용되는 수천 개의 AI 가속기에 집중되었습니다. 하이퍼스케일 기업은 이러한 노력을 위한 리소스를 보유하고 있지만 대부분의 기업의 경우 기본적인 Transformer 또는 Diffusion 모델을 개발하고 학습하는 것은 실행 가능하지도 비용 효율적이지 않습니다. 게다가 기업의 주요 사용 사례는 추론 워크로드를 실행하는 프로덕션 배포가 될 것입니다. 이러한 워크로드를 연구하기 위해 Signal65 벤치마크 제품군을 사용하는 것은 성능 및 비용 효율성 지표에 대한 의미 있는 통찰력을 제공하여 고위 기업 의사 결정권자가 AI 추론 플랫폼에 대한 정보에 입각한 조달 결정을 내리는 데 도움이 되는 것을 목표로 합니다. Nvidia H100은 Intel Gaudi 3 AI 가속기보다 약간의 성능 이점이 있을 수 있지만, 비용 차이를 고려할 때 Intel의 Gaudi 3는 우리가 제시한 다양한 추론 워크로드에서 상당한 비용 효율성 이점을 보여줍니다.
관련 상품:
-
 QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310nm 500m MTP / MPO SMF FEC 광 트랜시버 모듈
$400.00
QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310nm 500m MTP / MPO SMF FEC 광 트랜시버 모듈
$400.00
-
 QSFP-DD-400G-SR4 QSFP-DD 400G SR4 PAM4 850nm 100m MTP/MPO-12 OM4 FEC 광 트랜시버 모듈
$450.00
QSFP-DD-400G-SR4 QSFP-DD 400G SR4 PAM4 850nm 100m MTP/MPO-12 OM4 FEC 광 트랜시버 모듈
$450.00
-
 NVIDIA MMA4Z00-NS400 호환 400G OSFP SR4 플랫 탑 PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 다중 모드 FEC 광 트랜시버 모듈
$550.00
NVIDIA MMA4Z00-NS400 호환 400G OSFP SR4 플랫 탑 PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 다중 모드 FEC 광 트랜시버 모듈
$550.00
-
 NVIDIA MMS4X00-NS400 호환 400G OSFP DR4 플랫 탑 PAM4 1310nm MTP/MPO-12 500m SMF FEC 광 트랜시버 모듈
$700.00
NVIDIA MMS4X00-NS400 호환 400G OSFP DR4 플랫 탑 PAM4 1310nm MTP/MPO-12 500m SMF FEC 광 트랜시버 모듈
$700.00
-
 NVIDIA MMA1Z00-NS400 호환 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC 광 트랜시버 모듈
$550.00
NVIDIA MMA1Z00-NS400 호환 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC 광 트랜시버 모듈
$550.00
-
 NVIDIA MMS1Z00-NS400 호환 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12(FEC 광 트랜시버 모듈 포함)
$700.00
NVIDIA MMS1Z00-NS400 호환 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12(FEC 광 트랜시버 모듈 포함)
$700.00
-
 NVIDIA MMA4Z00-NS 호환 800Gb/s 트윈 포트 OSFP 2x400G SR8 PAM4 850nm 100m DOM 듀얼 MPO-12 MMF 광 트랜시버 모듈
$650.00
NVIDIA MMA4Z00-NS 호환 800Gb/s 트윈 포트 OSFP 2x400G SR8 PAM4 850nm 100m DOM 듀얼 MPO-12 MMF 광 트랜시버 모듈
$650.00
-
 NVIDIA MMA4Z00-NS-FLT 호환 800Gb/s 트윈 포트 OSFP 2x400G SR8 PAM4 850nm 100m DOM 듀얼 MPO-12 MMF 광 트랜시버 모듈
$650.00
NVIDIA MMA4Z00-NS-FLT 호환 800Gb/s 트윈 포트 OSFP 2x400G SR8 PAM4 850nm 100m DOM 듀얼 MPO-12 MMF 광 트랜시버 모듈
$650.00
-
 NVIDIA MMS4X00-NM 호환 800Gb/s 트윈 포트 OSFP 2x400G PAM4 1310nm 500m DOM 듀얼 MTP/MPO-12 SMF 광 트랜시버 모듈
$900.00
NVIDIA MMS4X00-NM 호환 800Gb/s 트윈 포트 OSFP 2x400G PAM4 1310nm 500m DOM 듀얼 MTP/MPO-12 SMF 광 트랜시버 모듈
$900.00
-
 NVIDIA MMS4X00-NM-FLT 호환 800G 트윈 포트 OSFP 2x400G 플랫 탑 PAM4 1310nm 500m DOM 듀얼 MTP/MPO-12 SMF 광 트랜시버 모듈
$1199.00
NVIDIA MMS4X00-NM-FLT 호환 800G 트윈 포트 OSFP 2x400G 플랫 탑 PAM4 1310nm 500m DOM 듀얼 MTP/MPO-12 SMF 광 트랜시버 모듈
$1199.00
-
 NVIDIA MMS4X50-NM 호환 OSFP 2x400G FR4 PAM4 1310nm 2km DOM 이중 이중 LC SMF 광 트랜시버 모듈
$1200.00
NVIDIA MMS4X50-NM 호환 OSFP 2x400G FR4 PAM4 1310nm 2km DOM 이중 이중 LC SMF 광 트랜시버 모듈
$1200.00
-
 NVIDIA MCP7Y70-H001 호환 1m(3피트) 400G 트윈 포트 2x200G OSFP - 4x100G QSFP56 패시브 브레이크아웃 직접 연결 구리 케이블
$120.00
NVIDIA MCP7Y70-H001 호환 1m(3피트) 400G 트윈 포트 2x200G OSFP - 4x100G QSFP56 패시브 브레이크아웃 직접 연결 구리 케이블
$120.00
-
 NVIDIA MCP7Y60-H001 호환 1m(3피트) 400G OSFP - 2x200G QSFP56 패시브 직접 연결 케이블
$99.00
NVIDIA MCP7Y60-H001 호환 1m(3피트) 400G OSFP - 2x200G QSFP56 패시브 직접 연결 케이블
$99.00
-
 NVIDIA MFA7U10-H003 호환 3m(10ft) 400G OSFP - 2x200G QSFP56 트윈 포트 HDR 브레이크아웃 활성 광 케이블
$750.00
NVIDIA MFA7U10-H003 호환 3m(10ft) 400G OSFP - 2x200G QSFP56 트윈 포트 HDR 브레이크아웃 활성 광 케이블
$750.00
-
 NVIDIA MCP7Y00-N001 호환 1m(3피트) 800Gb 트윈 포트 OSFP - 2x400G OSFP InfiniBand NDR 브레이크아웃 직접 연결 구리 케이블
$160.00
NVIDIA MCP7Y00-N001 호환 1m(3피트) 800Gb 트윈 포트 OSFP - 2x400G OSFP InfiniBand NDR 브레이크아웃 직접 연결 구리 케이블
$160.00
-
 NVIDIA MCA7J60-N004 호환 4m(13피트) 800G 트윈 포트 OSFP - 2x400G OSFP InfiniBand NDR 브레이크아웃 활성 구리 케이블
$800.00
NVIDIA MCA7J60-N004 호환 4m(13피트) 800G 트윈 포트 OSFP - 2x400G OSFP InfiniBand NDR 브레이크아웃 활성 구리 케이블
$800.00
-
 NVIDIA MCP7Y10-N001 호환 가능한 1m(3피트) 800G InfiniBand NDR 트윈 포트 OSFP - 2x400G QSFP112 브레이크아웃 DAC
$155.00
NVIDIA MCP7Y10-N001 호환 가능한 1m(3피트) 800G InfiniBand NDR 트윈 포트 OSFP - 2x400G QSFP112 브레이크아웃 DAC
$155.00
-
 NVIDIA MCP7Y50-N001 호환 1m(3ft) 800G InfiniBand NDR 트윈 포트 OSFP - 4x200G OSFP 브레이크아웃 DAC
$255.00
NVIDIA MCP7Y50-N001 호환 1m(3ft) 800G InfiniBand NDR 트윈 포트 OSFP - 4x200G OSFP 브레이크아웃 DAC
$255.00