
DeepSeek는 추론에 대한 수요의 폭발로 이어졌고, Nvidia의 "컴퓨팅 파워 패권"에 구멍이 생겼습니다. 새로운 세계로 가는 문이 점차 열렸습니다. ASIC 칩이 이끄는 컴퓨팅 파워 혁명이 침묵에서 소음으로 이동하고 있습니다.
최근 코어 플로우 싱크탱크는 정보통을 인용해 딥시크가 자체 AI 칩을 개발할 준비를 하고 있다고 전했습니다. 이 떠오르는 기업과 비교하면 알리바바, 바이두, 바이트댄스와 같은 국내 거대 기업들은 이미 "자체 연구"의 문을 일찍 넘었습니다.
바다 건너편에서는 OpenAI의 자체 개발 칩에 대한 새로운 진전도 올해 초에 공개되었습니다. 외국 언론은 Broadcom이 이를 위해 맞춤 제작한 첫 번째 칩이 몇 달 안에 TSMC에서 생산될 것이라고 밝혔습니다. 이전에는 Sam Altman이 설계와 제조를 모두 아우르는 "칩 제국"을 건설하기 위해 7조 달러를 모금할 계획이라고 보도되었습니다. 또한 Google, Amazon, Microsoft, Meta도 "자체 연구 열풍"에 합류했습니다.
분명한 신호 중 하나는 DeepSeek, OpenAI, 중국 기업 또는 실리콘 밸리 거대 기업이든 컴퓨팅 파워 시대에 뒤처지고 싶어하는 사람은 없다는 것입니다. 그리고 ASIC 칩은 새로운 세계에 진입하기 위한 티켓이 될 수 있습니다.
이것이 엔비디아를 "죽일" 것인가? 아니면 두 번째 엔비디아를 "재창조"할 것인가? 아직 답은 없습니다. 그러나 상류 산업 체인의 기업들이 이미 이 "자체 개발 물결"의 활력을 예견했다는 것은 분명합니다. 예를 들어, 주요 제조업체에 설계 및 맞춤화 서비스를 제공하는 Broadcom은 성과에서 "이륙"했습니다. 2024년 AI 사업 수익은 전년 대비 240% 증가한 3.7억 달러에 달했습니다. 1년 2025분기 AI 사업 수익은 전년 대비 4.1% 증가한 77억 달러였습니다. 그 중 80%가 ASIC 칩 설계에서 발생했습니다. Broadcom의 눈에 ASIC 칩 시장은 90억 달러 이상의 가치가 있습니다.
GPU에서 ASIC까지 컴퓨팅 파워 경제학은 분수령에 도달하고 있습니다.
저비용은 AI 추론의 폭발을 위한 전제 조건입니다. 반면, 범용 GPU 칩은 AI 폭발을 위한 황금 족쇄가 되었습니다.
NVIDIA의 H100과 A100은 대규모 모델 학습의 절대적인 왕이며, B200과 H200조차도 기술 거물들이 찾고 있습니다. Financial Times는 이전에 Omdia의 데이터를 인용하여 2024년에 Nvidia의 Hopper 아키텍처 칩의 주요 고객은 Microsoft, Meta, Tesla/xAI 등이고, 그 중 Microsoft의 주문은 500,000에 이를 것이라고 했습니다.
하지만 범용 GPU의 절대적 지배자로서 NVIDIA 제품 솔루션의 반대편도 점차 드러나고 있습니다. 바로 높은 비용과 불필요한 에너지 소비입니다.
비용 측면에서 단일 H100은 30,000달러 이상입니다. 수천억 개의 매개변수로 모델을 학습하려면 수만 개의 GPU와 네트워크 하드웨어, 스토리지 및 보안에 대한 후속 투자가 필요하며 총 500억 달러가 넘습니다. HSBC 데이터에 따르면 최신 세대 GB200 NVL72 솔루션은 캐비닛당 3만 달러 이상이며 NVL36은 약 1.8만 달러입니다.
범용 GPU를 기반으로 한 모델 학습은 너무 비싸다고 할 수 있지만, 무한한 컴퓨팅 파워를 가진 실리콘 밸리는 여전히 "큰 힘이 벽돌을 날린다"는 이야기를 선호하고 있으며, 자본 지출은 줄어들지 않았습니다. 얼마 전, 최근 Grok-3를 발표한 머스크의 xAI는 학습을 위해 200,000만 개의 GPU를 서버 규모로 보유하고 있습니다.
텐센트 테크놀로지와 실리콘 래빗 레이싱이 공동으로 발표한 "20,000년 주요 AI 통찰력에 대한 2025만 단어 상세 설명" 기사에 따르면, 하이퍼스케일 데이터 센터 운영자는 200년 자본 지출(CapEx)이 2024억 달러를 초과할 것으로 예상하고, 이 수치는 250년까지 2025억 달러에 가까워질 것으로 예상되며, 주요 리소스가 인공지능에 할당될 것이라고 언급했습니다.
에너지 소비 측면에서 SemiAnalysis의 계산에 따르면 100,000만 장의 H100 클러스터는 총 전력 소비량이 150MW이고 연간 1.59TWh의 전기를 소비합니다. 킬로와트시당 0.078달러로 계산하면 연간 전기 요금은 최대 123.9억 30만 달러에 달합니다. OpenAI가 공개한 데이터와 비교했을 때 추론 단계에서 GPU의 컴퓨팅 전력 사용률은 50%-XNUMX%에 불과하며 "대기 중 계산" 현상이 현저합니다. 이러한 비효율적인 성능 활용은 추론 시대에 심각한 자원 낭비입니다.
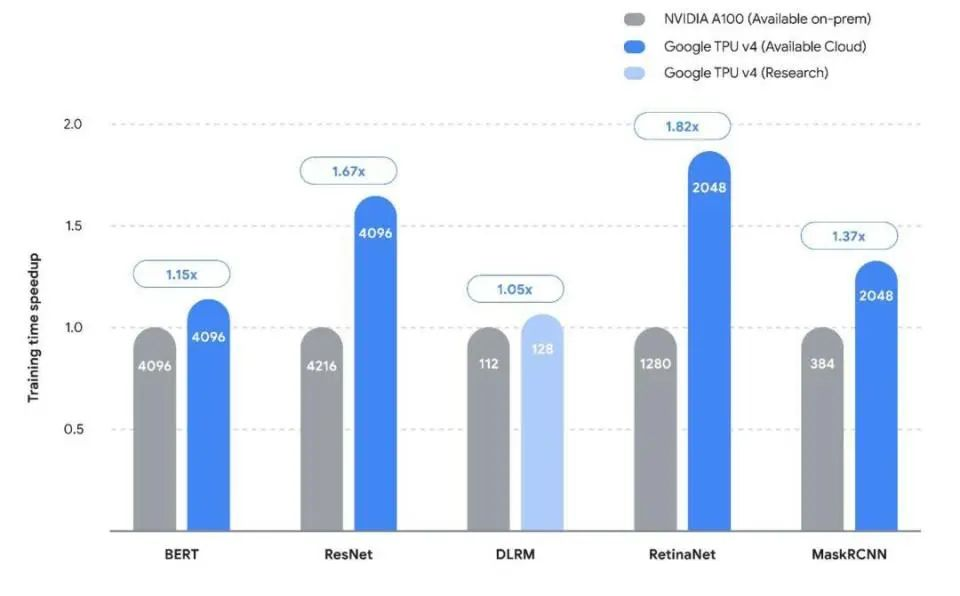
Google은 이전에 다양한 아키텍처 모델에 대해 TPU V4 및 A100 학습 속도를 발표했습니다.
선도적인 성과, 높은 가격, 낮은 효율성, 생태적 장벽으로 인해 업계는 지난 1년 동안 "세계는 오랫동안 엔비디아로 인해 고통을 받았다"고 말해야 했습니다. 클라우드 공급업체는 점차 하드웨어 자율성을 잃고 있으며, 공급망 위험과 더불어 AMD는 일시적으로 "성장할 수 없습니다". 많은 요인으로 인해 거대 기업은 자체 ASIC 전용 칩을 개발하기 시작했습니다.
그 이후로 AI 칩 전장은 기술 경쟁에서 경제 게임으로 전환되었습니다. Southwest Securities의 조사에서 결론 내린 바와 같이 "모델 아키텍처가 융합 기간에 접어들면 컴퓨팅 파워에 투자한 모든 달러는 정량화된 경제적 이익을 창출해야 합니다." 북미 클라우드 공급업체가 보고한 최근의 진전을 판단해보면 ASIC은 특정 대체 이점을 보여주었습니다.
- Google: Broadcom이 Google을 위해 맞춤 제작한 TPU v5 칩의 단위 컴퓨팅 전력 비용은 Llama-70 추론 시나리오에서 H100보다 3% 낮습니다.
- Amazon: 3nm 공정을 적용한 AWS Trainium 3은 동일한 컴퓨팅 성능을 갖춘 범용 GPU에 비해 에너지를 1/3만 소모하여 연간 10만 달러 이상의 전기 비용을 절감합니다. Amazon의 2024년 Trainium 칩 출하량은 500,000만 개를 넘어선 것으로 알려졌습니다.
- Microsoft: IDC 데이터에 따르면 Microsoft Azure가 자체 ASIC을 개발한 이후 하드웨어 조달 비용 비중이 75%에서 58%로 떨어져 장기적으로 수동적인 협상 딜레마에서 벗어났습니다.
북미 ASIC 체인의 가장 큰 수혜자인 Broadcom의 추세는 데이터에서 점점 더 분명해지고 있습니다.
Broadcom의 2024년 AI 사업 매출은 3.7억 달러로 전년 대비 240% 증가했으며, 그 중 80%는 ASIC 설계 서비스에서 발생했습니다. 1년 2025분기에 AI 사업 매출은 4.1억 달러로 전년 대비 77% 증가했습니다. 동시에 4.4분기에 AI 매출이 44억 달러로 전년 대비 XNUMX% 증가할 것으로 예상합니다.
Broadcom은 연간 보고 기간 중 일찍이 ASIC 수익이 2027년에 폭발적으로 증가할 것이라고 안내했으며, ASIC 칩이 90년 후에 1억 달러 규모의 시장 규모에 도달할 것으로 예상되어 시장에 대한 허황된 꿈을 그렸습니다. 이 회사는 XNUMX분기 컨퍼런스 콜에서 이를 반복했습니다.
이러한 주요 산업 추세로 인해 Broadcom은 Nvidia와 TSMC에 이어 1조 달러가 넘는 시장 가치를 가진 세계 XNUMX위의 반도체 회사가 되었습니다. 또한 Marvell과 AIchip과 같은 회사들의 해외 주목을 받았습니다.
하지만 한 가지 강조해야 할 점이 있습니다. "ASIC은 좋지만 GPU를 죽이지는 못할 것입니다." Microsoft, Google, Meta는 모두 자체 제품을 개발하고 있지만 동시에 모두 Nvidia의 B200을 가장 먼저 출시하기 위해 경쟁하고 있습니다. 이는 실제로 두 당사자 간에 직접적인 경쟁 관계가 없음을 보여줍니다.
보다 객관적인 결론은 GPU가 여전히 고성능 학습 시장을 지배할 것이고, 다재다능함으로 인해 추론 시나리오에서 가장 중요한 칩이 될 것이라는 것입니다. 그러나 400억 달러에 달하는 AI 칩의 미래 블루오션 시장에서 ASIC의 침투 경로는 이미 명확하게 보입니다.
IDC는 2024년에서 2026년의 추론 시나리오에서 ASIC의 비중이 15%에서 40%로, 최대 160억 달러로 증가할 것으로 예측합니다. 이러한 변화의 최종 결과는 다음과 같을 수 있습니다. ASIC이 추론 시장의 80%를 차지하고 GPU는 교육 및 그래픽 분야로 후퇴합니다.
진짜 승자는 실리콘 웨이퍼와 시나리오를 모두 이해하는 "듀얼 플레이어"가 될 것입니다. Nvidia는 분명히 그중 하나입니다. ASIC에 대해 낙관적이라는 것은 분명히 Nvidia를 폄하하는 것이 아닙니다. 새로운 세계로 가는 가이드는 Nvidia 이외의 듀얼 플레이어를 찾고 ASIC의 새로운 시대에 돈을 버는 방법입니다.
ASIC의 "Scalpel"은 모든 비핵심 모듈을 절단합니다.
ASIC은 AI 추론에 좋다고 하지만, 어떤 종류의 칩일까요?
아키텍처 관점에서 GPU와 같은 범용 칩의 한계는 "1 대 100" 디자인입니다. 그래픽 렌더링, 과학적 컴퓨팅 및 다양한 모델 아키텍처와 같은 여러 요구 사항을 고려해야 하므로 핵심이 아닌 기능 모듈에 많은 양의 트랜지스터 리소스가 낭비됩니다.
NVIDIA GPU의 가장 큰 특징은 팔콘 로켓의 여러 엔진과 비교할 수 있는 많은 "작은 코어"를 가지고 있다는 것입니다. 개발자는 CUDA가 수년에 걸쳐 축적한 연산자 라이브러리를 사용하여 이러한 작은 코어를 병렬 컴퓨팅에 매끄럽고 효율적이며 유연하게 호출할 수 있습니다.
하지만 다운스트림 모델이 비교적 확실하다면 컴퓨팅 작업도 비교적 확실하고 유연성을 유지하기 위해 그렇게 많은 작은 코어가 필요하지 않습니다. 이것이 ASIC의 기본 원리이므로 완전 맞춤형 고컴퓨팅 파워 칩이라고도 합니다.
"메스처럼" 정밀한 절단을 통해 대상 시나리오와 긴밀하게 관련된 하드웨어 유닛만 유지하여 놀라운 효율성을 발휘하는데, 이는 구글과 아마존의 제품에서 검증되었습니다.

구글 TPU v5e AI 가속기 실제 촬영
GPU의 경우, 이를 부르는 가장 좋은 도구는 NVIDIA의 CUDA이고, ASIC 칩의 경우, 클라우드 공급업체가 직접 개발한 알고리즘으로 부릅니다. 이는 소프트웨어 공급업체로 시작한 대기업에게는 어려운 일이 아닙니다.
- Google TPU v4에서는 트랜지스터 리소스의 95%가 신경망 계산에 최적화된 행렬 곱셈 유닛과 벡터 처리 유닛에 사용되는 반면, GPU의 유사 유닛이 차지하는 비율은 60% 미만입니다.
- 기존 폰 노이만 아키텍처의 "컴퓨팅-스토리지" 분리 모델과 달리 ASIC은 알고리즘 특성을 중심으로 데이터 흐름을 사용자 정의할 수 있습니다. 예를 들어, Broadcom이 Meta에 맞게 사용자 정의한 권장 시스템 칩에서 컴퓨팅 유닛은 스토리지 컨트롤러 주위에 직접 내장되어 데이터 이동 거리를 70% 단축하고 대기 시간을 GPU의 1/8로 줄입니다.
- AI 모델의 50%-90% 희소 가중치 특성에 대응하여 Amazon Trainium2 칩에는 300값 계산 링크를 건너뛸 수 있는 희소 컴퓨팅 엔진이 내장되어 있어 이론적 성능을 XNUMX%까지 향상시킬 수 있습니다.
알고리즘이 고정되는 경향이 있을 때 ASIC은 결정론적 수직 시나리오에 대해 자연스러운 이점을 갖습니다. ASIC 설계의 궁극적인 목표는 칩 자체를 알고리즘의 "물리적 구체화"로 만드는 것입니다.
과거의 역사와 현재 현실에서 우리는 채굴 머신 칩과 같은 ASIC의 성공 사례를 찾아볼 수 있습니다.
초기에는 업계에서 채굴에 엔비디아의 GPU를 사용했습니다. 나중에 채굴의 난이도가 높아지면서 전기 소비량이 채굴 수익을 초과했고(현재 추론 요구 사항과 매우 유사), 채굴 전용 ASIC 칩이 폭발적으로 증가했습니다. GPU보다 다재다능함은 훨씬 떨어지지만 채굴 ASIC은 병렬성을 극대화합니다.
예를 들어, 비트메인의 비트코인 채굴 ASIC은 수만 개의 SHA-256 해시 컴퓨팅 유닛을 동시에 배치하여 단일 알고리즘에서 초선형 가속을 달성하고 컴퓨팅 전력 밀도는 GPU의 1,000배 이상입니다. 전용 기능이 크게 향상되었을 뿐만 아니라 시스템 수준에서 에너지 소비도 절감되었습니다.
또한, ASIC을 사용하면 주변 회로를 간소화할 수 있고(예: PCIe 인터페이스의 복잡한 프로토콜 스택이 더 이상 필요 없음), 메인보드 면적을 40% 줄이고, 전체 장비의 비용을 25% 절감할 수 있습니다.
낮은 비용, 높은 효율성, 하드웨어와 시나리오의 심층적 통합 지원 등 이러한 ASIC 기술 코어는 "계산적 무차별 대입"에서 "세련된 효율성 혁명"으로의 AI 산업의 변환 요구 사항에 자연스럽게 맞춰집니다.
추론 시대의 도래와 함께 ASIC 비용 이점은 채굴 기계의 역사를 반복하고 규모 효과 하에서 "데스 크로스"를 달성할 것입니다. 높은 초기 R&D 비용(단일 칩의 설계 비용은 약 50만 달러)에도 불구하고 한계 비용 감소 곡선은 범용 GPU보다 훨씬 가파릅니다.
예를 들어 구글 TPU v4를 살펴보면, 출하량이 100,000만 개에서 1만 개로 늘어났을 때, 개당 비용은 3,800달러에서 1,200달러로 급격히 떨어져 약 70%가 감소한 반면, GPU의 비용 감소는 보통 30%를 넘지 않습니다. 업계 체인의 최신 정보에 따르면, 구글 TPU v6는 1.6년에 2025만 개를 출하할 것으로 예상되며, 단일 칩의 컴퓨팅 파워는 이전 세대보다 XNUMX배 더 높습니다. ASIC의 비용 효율성은 여전히 빠르게 증가하고 있습니다.
이는 새로운 주제로 이어진다: 모든 사람이 자체 개발 ASIC 추세에 동참할 수 있을까? 이는 자체 연구 비용과 수요에 달려 있다.
7nm 공정의 ASIC 추론 가속기 카드의 계산에 따르면 IP 라이선스 비용, 노동비, 설계 도구, 마스크 템플릿 등을 포함한 일회성 테이프아웃 비용은 이후의 대량 생산 비용을 포함하지 않고 수억 위안에 달할 수 있습니다. 이와 관련하여 대기업은 더 큰 재정적 이점을 가지고 있습니다.
현재 구글, 아마존 등 클라우드 서비스 제공업체는 성숙한 고객 시스템을 갖추고 있으며, 연구개발과 판매의 폐쇄적 루프를 형성할 수 있으며, 자체 연구에 있어 본질적인 우위를 가지고 있습니다.
Meta와 같은 회사의 경우, 자체 개발 사업의 논리는 내부적으로 컴퓨팅 파워에 대한 엄청난 수요가 이미 있다는 것입니다. 올해 초, 주커버그는 1년에 약 2025GW의 컴퓨팅 파워를 출시하고 연말까지 1.3만 개 이상의 GPU를 보유할 계획이라고 밝혔습니다.
“새로운 지도”의 가치는 100억 달러가 훨씬 넘습니다.
채굴에 대한 수요만으로도 거의 10억 달러 규모의 시장이 형성됐고, Broadcom이 70년 말까지 AI ASIC 시장 규모가 90~2024억 달러에 이를 것이라고 발표했을 때 우리는 놀라지 않았고, 이 숫자가 보수적인 수치일 수도 있다고 생각했습니다.
이제 ASIC 칩의 산업적 추세는 더 이상 의문시되어서는 안 되며, 초점은 "새로운 지도"에서 게임 규칙을 마스터하는 방법에 맞춰져야 합니다. 거의 100억 달러 규모의 AI ASIC 시장에서 세 가지 명확한 계층이 형성되었습니다. "규칙을 정하는 ASIC 칩 설계자와 제조업체", "산업 체인 지원", "수직 시나리오의 패블리스"입니다.
첫 번째 계층은 규칙을 정하는 ASIC 칩 설계자와 제조업체입니다. 이들은 단가가 10,000달러가 넘는 ASIC 칩을 제조하고 상업적 사용을 위해 다운스트림 클라우드 공급업체와 협력할 수 있습니다. 대표적인 업체로는 Broadcom, Marvell, AIchip, 그리고 모든 고급 칩으로부터 이익을 얻을 파운드리 킹인 TSMC가 있습니다.
두 번째 계층은 지원 산업 사슬입니다. 시장의 주목을 끌고 있는 지원 논리에는 고급 패키징과 하류 산업 사슬이 포함됩니다.
- 고급 패키징: TSMC의 CoWoS 생산 용량의 35%가 SMIC, Changdian Technology, Tongfu Microelectronics 등 국내 대응업체를 포함한 ASIC 고객에게 이전되었습니다.
- 클라우드 벤더와 NVIDIA의 하드웨어 솔루션의 분리는 AEC 구리 케이블과 같은 새로운 하드웨어 기회를 제공합니다. Amazon의 자체 개발 단일 ASIC에는 3개의 AEC가 장착되어야 합니다. 7년에 2027만 개의 ASIC이 출하되면 해당 시장은 5억 달러를 초과할 것입니다. 서버와 PCB를 포함한 다른 기회도 유사한 논리에서 혜택을 볼 것입니다.
세 번째 계층은 만들어지고 있는 수직 시나리오의 Fabless입니다. ASIC의 본질은 수요 주도 시장입니다. 시나리오의 고통스러운 점을 먼저 포착할 수 있는 사람이 가격 책정권을 갖게 될 것입니다. ASIC의 유전자는 수직 시나리오에 자연스럽게 적응되는 맞춤화입니다. 지능형 주행 칩을 예로 들어보겠습니다. 전형적인 ASIC 칩으로서 BYD와 다른 회사들이 지능형 주행에 올인하면서 이러한 유형의 제품은 폭발적인 성장기에 접어들기 시작했습니다.
글로벌 ASIC 산업 사슬의 3대 계층에 상응하는 기회는 국내 생산의 "3대 비밀 열쇠"로 간주될 수 있습니다.
금지령의 제한으로 인해 국내 GPU와 NVIDIA의 격차는 여전히 크고 생태적 건설도 긴 여정입니다. 그러나 ASIC의 경우 해외와 같은 출발선에 있습니다. 수직적 시나리오와 결합하면 많은 중국 Fabless 회사가 앞서 언급한 채굴기 ASIC, 스마트 구동 ASIC 및 Baidu의 Kunlun Core와 같이 에너지 효율이 더 높은 제품을 만들 수 있습니다.
지원 칩 제조는 주로 SMIC에 의존하고 있으며, ZTE의 자회사인 ZTE Microelectronics는 새로운 진입자입니다. 앞으로 국내 제조업체와 협력하여 "중국의 Broadcom은 누구일까?"라는 드라마를 연출할 가능성도 배제할 수 없습니다.
데이터 센터 제품의 Nvidia 주요 상류 공급업체
산업 사슬의 지지 부분은 생산이 비교적 쉽습니다. 해당 서버, 광 트랜시버, 스위치, PCB, 구리 케이블의 경우 국내 기업은 기술적 난이도가 낮아 본질적으로 경쟁력이 있습니다. 동시에 이러한 산업 사슬 기업은 국내 컴퓨팅 파워와 "공생" 관계를 맺고 있으며 ASIC 칩 산업 사슬이 없어지지 않을 것입니다.
적용 시나리오 측면에서는 앞서 언급한 지능형 주행 칩과 AI 추론 가속 카드 외에도 국내 설계 기업의 기회는 어떤 시나리오가 대중화될 수 있고, 어떤 기업이 그 기회를 잡을 수 있는지에 따라 달라집니다.
결론
AI가 단순한 훈련 작업에서 벗어나 에너지 효율성을 추구하는 추론의 심해로 도약함에 따라, 컴퓨팅 파워 전쟁의 후반부는 기술적 환상을 경제적 계산으로 전환할 수 있는 회사가 차지하게 될 것입니다.
ASIC 칩의 반격은 기술 혁명일 뿐만 아니라 효율성, 비용 및 음성에 대한 비즈니스적 계시이기도 합니다. 이 새로운 게임에서 중국 플레이어의 칩은 조용히 증가하고 있습니다. 기회는 항상 준비된 사람에게 찾아옵니다.