
빠르게 진화하는 AI 인프라 환경에서 AMD는 특히 수냉 기술 분야에서 판도를 바꾸는 기업으로 부상하고 있습니다. 데이터 센터가 성능과 효율성의 한계를 뛰어넘는 가운데, AMD의 최신 기술은 새로운 기준을 제시하고 있습니다. 광통신 제품 및 솔루션 전문 공급업체인 FiberMall은 글로벌 데이터 센터, 클라우드 컴퓨팅 환경, 엔터프라이즈 네트워크, 액세스 네트워크 및 무선 시스템에 비용 효율적인 솔루션을 제공하기 위해 최선을 다하고 있습니다. AI 기반 통신 네트워크 분야의 선도적인 입지를 굳건히 하고 있는 FiberMall은 고품질의 가치 중심 광통신 솔루션을 찾는 고객에게 이상적인 파트너입니다. 자세한 내용은 공식 웹사이트를 방문하거나 고객 지원팀에 직접 문의하세요.
이 블로그에서는 대규모 GPU 클러스터부터 혁신적인 MI350 시리즈까지, AMD의 AI 수냉 기술 혁신을 살펴봅니다. AI 애호가, 데이터 센터 운영자, 기술 투자자 등 누구에게나 이러한 통찰력은 AMD가 차세대 AI 컴퓨팅의 바람개비가 되고 있는 이유를 보여줍니다.
TensorWave, 북미 최대 규모의 AMD 수랭식 서버 클러스터 구축
AI 인프라 분야의 떠오르는 신생 기업인 TensorWave가 최근 북미 최대 규모의 AMD GPU 학습 클러스터 구축을 성공적으로 완료했다고 발표했습니다. 8,192개의 Instinct MI325X GPU 가속기로 구동되는 이 클러스터는 해당 GPU 모델을 사용하는 최초의 대규모 직접 액체 냉각(DLC) 클러스터입니다.

TensorWave는 AMD의 최첨단 하드웨어에 집중하여 기업, 연구 기관 및 개발자를 위한 효율적인 컴퓨팅 플랫폼을 구축합니다. 이 거대한 클러스터는 규모 면에서 신기록을 세울 뿐만 아니라 AI 개발에 새로운 활력을 불어넣습니다. 업계 전문가들은 AMD 기반 클러스터가 탁월한 비용 효율성을 제공하여 기존 클러스터 대비 최대 30%까지 비용을 절감할 수 있다고 지적합니다. NVIDIA의 DGX 시스템 동등한 컴퓨팅 성능을 위해.
더 많은 기업이 AMD GPU를 도입함에 따라 AI 인프라 비용이 더욱 낮아져 산업 전반의 AI 도입이 가속화될 수 있습니다. FiberMall은 이러한 고성능 환경에서의 광통신 요구를 충족하기 위해 원활한 데이터 전송을 보장하는 안정적이고 AI에 최적화된 솔루션을 제공합니다.

AMD, 완전 액체 냉각 아키텍처 탑재 MI350 칩 공개…시장 열광적 반응
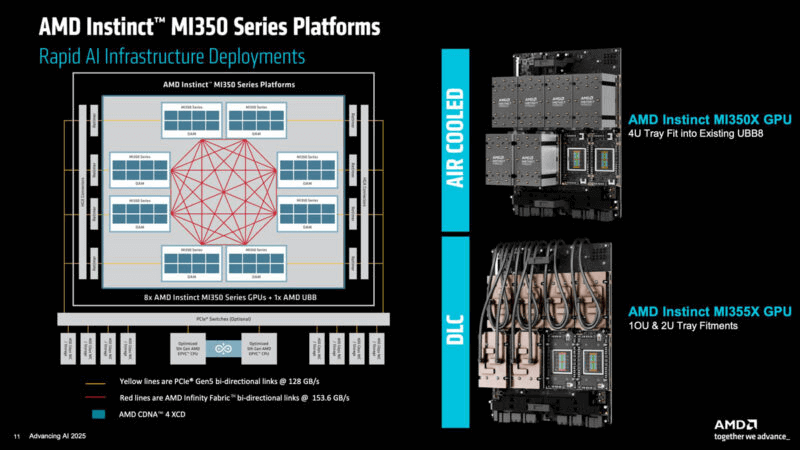
AMD는 12년 2025월 2025일 캘리포니아주 새너제이에서 "Advancing AI 350" 컨퍼런스를 개최하고 Instinct MI2,304 시리즈 GPU 가속기를 공식 출시했습니다. 이 GPU는 다중 카드 협업을 통해 초대규모 컴퓨팅 클러스터를 구현하며, 단일 노드는 최대 3개의 카드를 병렬로 연결하여 80.5GB의 HBM8E 메모리를 제공합니다. FP161 정밀도에서 6PFlops 이상, FP4/FP200 저정밀 컴퓨팅에서 XNUMXPFlops 이상의 최고 성능을 발휘하여 NVIDIA의 GBXNUMX에 필적합니다.
카드 간 연결은 양방향 Infinity Fabric 채널을 사용하며, CPU 연결은 128GB/s PCIe 5.0을 활용하여 병목 현상 없는 데이터 전송을 지원합니다. AMD는 공랭식과 수랭식을 모두 제공합니다. 공랭식은 최대 64개의 카드를 지원하고, 수랭식은 다양한 슈퍼컴퓨팅 요구 사항을 충족하기 위해 최대 128개의 카드(2U~5U 랙)까지 확장 가능합니다.



MI350X 모듈은 공랭식 사용 시 1,000W를 소모하는 반면, 고성능 MI355X는 주로 수랭 방식을 사용하며 1,400W를 소모합니다. Supermicro, Pegatron, Gigabyte와 같은 파트너사들은 이미 MI350 시리즈 수랭식 서버를 출시했습니다.


글로벌 하이엔드 AI 칩 시장에서 엔비디아는 80% 이상의 점유율을 차지하고 있지만, GB350 성능에 필적하는 AMD의 MI200 부활은 변화를 예고합니다. 수냉 생태계에서 AMD의 성장은 엔비디아의 독주에 대한 대안을 제시하며 더욱 건전한 경쟁을 촉진합니다. 주요 하이퍼스케일러와 Neo Cloud를 포함한 주요 클라우드 제공업체들이 MI350을 통합할 예정이며, Dell, HPE, Supermicro도 그 뒤를 따를 것입니다. 양산은 이달 초 시작되었으며, 초기 파트너 서버와 CSP 인스턴스는 3년 2025분기로 예정되어 있습니다. 많은 업체들이 이를 선호하고 있습니다. 수냉식 변종.

AI 기반 광 네트워크 분야에서 FiberMall이 보유한 전문 지식은 이러한 배포를 보완하여 고대역폭 AI 클러스터를 위한 비용 효율적인 상호 연결을 제공합니다.
AMD의 액체 냉각 시장에 대한 강력한 영향
NVIDIA의 거의 독점적인 지위는 파트너를 단념시키는 제한적인 화이트리스트를 포함하여 수냉 기술의 발전을 자사 생태계에 묶어두었습니다. AMD의 대규모 수냉 클러스터와 MI350 출시는 호재로, 화웨이와 같은 경쟁사와 함께 NVIDIA에 도전장을 내밀 가능성이 있습니다. 이는 NVIDIA의 영향력 밖에 있는 수냉 공급업체들에게 활력을 불어넣을 수 있습니다.
AMD는 MI350이 38년 안에 AI 플랫폼의 에너지 효율을 20배 높이고 2030년까지 95배 더 향상시킬 계획이라고 주장하며, 이를 통해 에너지 사용량을 최대 XNUMX%까지 줄일 수 있을 것이라고 밝혔습니다.
심층 분석: AMD MI350 시리즈 칩, OAM, UBB, 수랭식 서버 및 랙 배포
AMD는 Advancing AI 2025에서 MI350X와 MI350X를 포함한 Instinct MI355 시리즈를 출시하여 NVIDIA의 Blackwell과 정면으로 경쟁할 태세를 갖추었습니다.

Instinct MI350 개요
두 모델 모두 288TB/s 대역폭의 3GB HBM8E 메모리를 탑재하고 있습니다. MI355X는 최대 64W TDP로 FP79 16TFlops, FP5 8PFlops, FP10 6PFlops, FP4/FP20 1,400PFlops의 완벽한 성능을 제공합니다. MI350X는 8% 축소되어 FP18.4에서 최대 4PFlops, 1,000W TDP를 구현합니다.
AMD Instinct MI350 시리즈 칩
MI350X와 MI355X는 TSMC의 3nm(N3P) 및 3nm 공정을 사용하여 6D 하이브리드 본딩 아키텍처를 기반으로 구축된 칩 디자인을 공유합니다.


비교: AMD MI350X vs. NVIDIA B200/GB200
| 매개 변수 | AMD MI350X | 엔비디아 B200 | 엔비디아 GB200 |
| 아키텍처 | CDNA 4 (3D 하이브리드 본딩) | 블랙웰(듀얼 다이 통합) | 블랙웰 + 그레이스 CPU(듀얼 B200 + 1 그레이스) |
| 프로세스 노드 | TSMC 3nm(N3P) + 6nm(IOD) 하이브리드 패키징 | TSMC 4nm(N4P) | TSMC 4nm(N4P) |
| 트랜지스터 | 185 억 | 208 억 | 416억(듀얼 B200) |
| 메모리 구성 | 288GB HBM3E(12Hi 스택), 8TB/s 대역폭 | 192GB HBM3E(8Hi 스택), 7.7TB/s 대역폭 | 384GB HBM3E(듀얼 B200), 15.4TB/s 대역폭 |
| FP4 계산 | 18.4 PFLOPS(36.8 PFLOPS 희소) | 20 PFLOPS(FP4 고밀도) | 40 PFLOPS(듀얼 B200) |
| FP8 계산 | 9.2 PFLOPS(18.4 PFLOPS 희소) | 10PFLOPS | 20PFLOPS |
| FP32 계산 | 144 TFLOPS | 75 TFLOPS | 150 TFLOPS |
| FP64 계산 | 72 TFLOPS(2x B200 이중 정밀도) | 37 TFLOPS | 74 TFLOPS |
| 상호 연결 | 153.6GB/s Infinity Fabric(노드당 8개 카드), 최대 128개 카드까지 가능한 Ultra Ethernet | 1.8TB/s NVLink 5.0(카드당), NVL576에 72개 카드 | 1.8TB/s NVLink 5.0(B200당), 129.6카드 클러스터에서 양방향 72TB/s |
| 전력 소비 | 1000W(공랭식) | 1000W(액체 냉각) | 2700W(듀얼 B200 + 그레이스) |
| 소프트웨어 생태계 | PyTorch/TensorFlow 최적화, FP7/FP4 지원이 포함된 ROCm 6 | FP12.5/FP4 정밀도, TensorRT-LLM 추론을 갖춘 CUDA 8+ | 12.5조 개 매개변수 모델을 위한 Grace CPU 최적화 기능을 갖춘 CUDA XNUMX+ |
| 일반적인 성능 | Llama 3.1 405B 추론은 B30보다 200% 더 빠릅니다. 8-카드 FP4는 147 PFLOPS입니다. | GPT-3 교육 4x H100; 단일 카드 FP4 추론 5x H100 | 72 EFLOPS의 72-카드 NVL4 FP1.4; 추론 비용은 H25보다 100% 낮음 |
| 가격(2025) | $25,000 (최근 67% 증가, B17보다 여전히 200% 낮음) | $30,000 | 60,000달러 이상 (듀얼 B200 + 그레이스) |
| 효율성: | 와트당 HBM 대역폭 30% 증가, B40보다 달러당 토큰 200% 증가 | 트랜지스터당 FP25 4% 증가, NVLink 효율성 50% 향상 | FP14.8용 액체 냉각에서 4 PFLOPS/W |
| 차별화 | 고유한 FP6/FP4 이중 정밀도 추론; 288B 매개변수 모델용 520GB | FP2용 4세대 트랜스포머 엔진, 신뢰성을 위한 칩 레벨 RAS | Grace CPU 통합 메모리; 데이터 로딩을 위한 압축 해제 엔진 |
MI350X는 B60(200GB)보다 192% 더 많은 메모리와 동일한 대역폭을 제공합니다. FP64/FP32에서는 약 1배, FP6에서는 최대 1.2배, 저정밀도에서는 약 10% 더 우수합니다. 추론 성능은 30% 이상 일치하거나 능가하며, 학습 성능은 FP10 미세 조정에서 동등하거나 8% 이상 앞서 있습니다. 이 모든 것이 더 높은 비용 효율성(달러당 40% 더 많은 토큰)으로 제공됩니다.
AMD 인스팅트 MI350 OAM
OAM 폼 팩터는 컴팩트하며 MI325X와 유사한 두꺼운 PCB를 사용합니다.

AMD 인스팅트 MI350 UBB
다음은 350개의 다른 GPU와 함께 UBB에 설치된 MIXNUMX OAM 패키지로 총 XNUMX개입니다.

AMD Instinct MI350 UBB 8 GPU 냉각 없음 2
이와 관련된 또 다른 관점은 다음과 같습니다.

AMD Instinct MI350 UBB 8 GPU 냉각 없음 1
8개의 GPU가 설치된 UBB 전체를 살펴보겠습니다.

AMD Instinct MI350 UBB 8 GPU 냉각 기능 없음
여러 면에서 이 제품은 이전 세대의 AMD Instinct MI325X 보드와 비슷한데, 그게 요점입니다.

AMD Instinct MI350 UBB 8 GPU 냉각 없음 3
한쪽 끝에는 UBB 커넥터와 PCIe 리타이머용 방열판이 있습니다.

AMD Instinct MI350X UBB PCIe 리타이머
관리를 위한 SMC도 있습니다.

AMD 인스팅트 MI350 SMC
보드 자체 외에 냉각 기능도 있습니다.
AMD Instinct MI350X 공랭식 쿨러
여기 대형 공랭식 히트싱크가 장착된 OAM 모듈이 있습니다. 이 공랭식 쿨러는 AMD Instinct MI350X입니다.

AMD Instinct MI350X 쿨러
UBB에는 이런 제품이 여덟 개 있습니다. 위에서 본 것과 비슷한데, 큰 히트싱크가 여덟 개뿐입니다.

AMD Instinct MI350X UBB 8 GPU
SMC와 핸들 쪽에서 본 방열판의 또 다른 모습입니다.

AMD Instinct MI350X UBB 8 GPU 히트싱크 프로필
참고로 AMD MI300X의 UBB는 다음과 같습니다.

AMD MI300X 8 GPU OAM UBB 1
AMD는 또한 더 높은 TDP와 카드당 더 높은 성능을 제공하는 MI355X 액체 냉각 버전을 보유하고 있습니다.
AMD MI350 시리즈 AI 서버
파트너사로는 Supermicro(4U/2U 액체 냉각, 최대 355개 MI7X), Compal(4U, 최대 355개), ASRock(XNUMXU, XNUMX개 MIXNUMXX) 등이 있습니다.
MI350 랙 배포
단일 노드는 최대 2,304개 카드(161GB 메모리, 최대 6 PFlops FP4/FP64)까지 지원합니다. 공랭식은 최대 128개 카드, 수랭식은 최대 128개 카드까지 확장 가능합니다. 36개 카드 구성은 2.57TB 메모리와 최대 6 EFlops FP4/FPXNUMX를 제공합니다.
결론: AMD의 액체 냉각 혁명
AMD MI350 시리즈와 TensorWave의 클러스터는 AI 수냉 시스템의 핵심적인 변화를 강조하며 독점 기업에 도전하고 효율성을 향상시킵니다. AI 수요가 급증함에 따라 이러한 혁신은 비용 절감과 확장성을 약속합니다.
FiberMall은 최고 수준의 광통신 솔루션으로 귀사의 AI 인프라를 지원할 준비가 되어 있습니다. 맞춤형 상담을 원하시면 웹사이트를 방문하시거나 고객 지원팀에 문의하세요.
관련 상품:
-
 OSFP-400GF-MPO1M 400G OSFP SR4 MPO-12 암 플러그 피그테일 1m 침지 액체 냉각 광 트랜시버
$1950.00
OSFP-400GF-MPO1M 400G OSFP SR4 MPO-12 암 플러그 피그테일 1m 침지 액체 냉각 광 트랜시버
$1950.00
-
 OSFP-400GM-MPO1M 400G OSFP SR4 MPO-12 수컷 플러그 피그테일 1m 침지 액체 냉각 광 트랜시버
$1950.00
OSFP-400GM-MPO1M 400G OSFP SR4 MPO-12 수컷 플러그 피그테일 1m 침지 액체 냉각 광 트랜시버
$1950.00
-
 OSFP-400GF-MPO3M 400G OSFP SR4 MPO-12 암 플러그 피그테일 3m 침지 액체 냉각 광 트랜시버
$1970.00
OSFP-400GF-MPO3M 400G OSFP SR4 MPO-12 암 플러그 피그테일 3m 침지 액체 냉각 광 트랜시버
$1970.00
-
 OSFP-400GM-MPO3M 400G OSFP SR4 MPO-12 수컷 플러그 피그테일 3m 침지 액체 냉각 광 트랜시버
$1970.00
OSFP-400GM-MPO3M 400G OSFP SR4 MPO-12 수컷 플러그 피그테일 3m 침지 액체 냉각 광 트랜시버
$1970.00
-
 OSFP-400GF-MPO60M 400G OSFP SR4 MPO-12 암 플러그 피그테일 60m 침지 액체 냉각 광 트랜시버
$2025.00
OSFP-400GF-MPO60M 400G OSFP SR4 MPO-12 암 플러그 피그테일 60m 침지 액체 냉각 광 트랜시버
$2025.00
-
 OSFP-400GM-MPO60M 400G OSFP SR4 MPO-12 수컷 플러그 피그테일 60m 침지 액체 냉각 광 트랜시버
$2025.00
OSFP-400GM-MPO60M 400G OSFP SR4 MPO-12 수컷 플러그 피그테일 60m 침지 액체 냉각 광 트랜시버
$2025.00
-
 OSFP-800G85F-MPO60M 800G OSFP SR8 MPO-12 암 플러그 피그테일 60m 침지 액체 냉각 광 트랜시버
$2400.00
OSFP-800G85F-MPO60M 800G OSFP SR8 MPO-12 암 플러그 피그테일 60m 침지 액체 냉각 광 트랜시버
$2400.00
-
 OSFP-800G85M-MPO60M 800G OSFP SR8 MPO-12 수컷 플러그 피그테일 60m 침지 액체 냉각 광 트랜시버
$2400.00
OSFP-800G85M-MPO60M 800G OSFP SR8 MPO-12 수컷 플러그 피그테일 60m 침지 액체 냉각 광 트랜시버
$2400.00
-
 OSFP-800G85F-MPO5M 800G OSFP SR8 MPO-12 암 플러그 피그테일 5m 침지 액체 냉각 광 트랜시버
$2330.00
OSFP-800G85F-MPO5M 800G OSFP SR8 MPO-12 암 플러그 피그테일 5m 침지 액체 냉각 광 트랜시버
$2330.00
-
 OSFP-800G85M-MPO5M 800G OSFP SR8 MPO-12 수컷 플러그 피그테일 5m 침지 액체 냉각 광 트랜시버
$2330.00
OSFP-800G85M-MPO5M 800G OSFP SR8 MPO-12 수컷 플러그 피그테일 5m 침지 액체 냉각 광 트랜시버
$2330.00
-
 OSFP-800G85F-MPO1M 800G OSFP SR8 MPO-12 암 플러그 피그테일 1m 침지 액체 냉각 광 트랜시버
$2250.00
OSFP-800G85F-MPO1M 800G OSFP SR8 MPO-12 암 플러그 피그테일 1m 침지 액체 냉각 광 트랜시버
$2250.00
-
 OSFP-800G85M-MPO1M 800G OSFP SR8 MPO-12 수컷 플러그 피그테일 1m 침지 액체 냉각 광 트랜시버
$2250.00
OSFP-800G85M-MPO1M 800G OSFP SR8 MPO-12 수컷 플러그 피그테일 1m 침지 액체 냉각 광 트랜시버
$2250.00