
ファーウェイは最近、革新的なAIアクセラレータとラックレベルアーキテクチャにより、業界に大きな影響を与えました。中国が開発した最新のクラウドスーパーコンピューティングソリューションであるCloudMatrix M8が正式に発表されました。Ascend 910Cプロセッサを搭載したこのソリューションは、NVIDIAのGB200 NVL72システムと直接競合する位置付けにあり、複数の主要指標においてNVIDIAのラックレベル製品と比較して優れた技術的優位性を示しています。エンジニアリングのブレークスルーはチップレベルにとどまらず、アクセラレータアーキテクチャ、ネットワークトポロジ、光インターコネクト技術、ソフトウェアスタックなど、システムレベルのあらゆる側面に及んでいます。

Ascend 910C NPUは、高帯域幅バスを介して相互接続されたデュアルダイパッケージを採用しています。各NPUのシングルダイは、ユニファイドバス(UB)プレーンに7×224Gbpsの帯域幅を統合し、RDMAプレーンで200Gbpsの単方向帯域幅を提供します。このアーキテクチャにより、AIワークロード向けの高性能コンピューティングが可能になり、CloudMatrix 910Cプラットフォーム内での効率的なデータ処理と相互接続性が確保されます。
SemiAnalysisにとって、HuaweiのAscendチップは決して馴染みのないものではありません。システム全体の重要性がマイクロアーキテクチャ設計のみよりも重視される時代において、Huaweiは人工知能システムの性能限界を絶えず押し広げています。技術的なトレードオフは確かに存在しますが、輸出規制と限られた国内製造能力という状況下では、中国の現在の輸出管理体制には依然として悪用可能な抜け穴が存在しているように見受けられます。
Huaweiのチップ技術は競合他社より384世代遅れているかもしれませんが、その拡張ソリューションは、NvidiaやAMDの現行市場製品より384世代先を進んでいると言えるでしょう。例えば、CloudMatrix 384(CM910)は、XNUMX個のAscend XNUMXCチップを完全接続トポロジーで相互接続した構成です。その設計思想は明確です。AscendチップをXNUMX倍も搭載することで、単体GPUの性能がNvidiaのBlackwellシリーズのXNUMX分のXNUMXに過ぎないという問題を効果的に補うのです。
CloudMatrix 384スーパーノードは、384つの補完的なプレーンを備えた高度なネットワークトポロジを採用しています。192個のNPUと400個のCPU間のノンブロッキングな全対全相互接続を実現するUBプレーン、NPUあたり最大XNUMXGbpsのRoCEを用いたスケールアウト通信を実現するRDMAプレーン、そしてより広範なデータセンター接続を実現するVPCプレーンです。この設計は超大規模コンピューティングクラスタをサポートし、AI駆動型アプリケーションの効率的な連携を実現します。
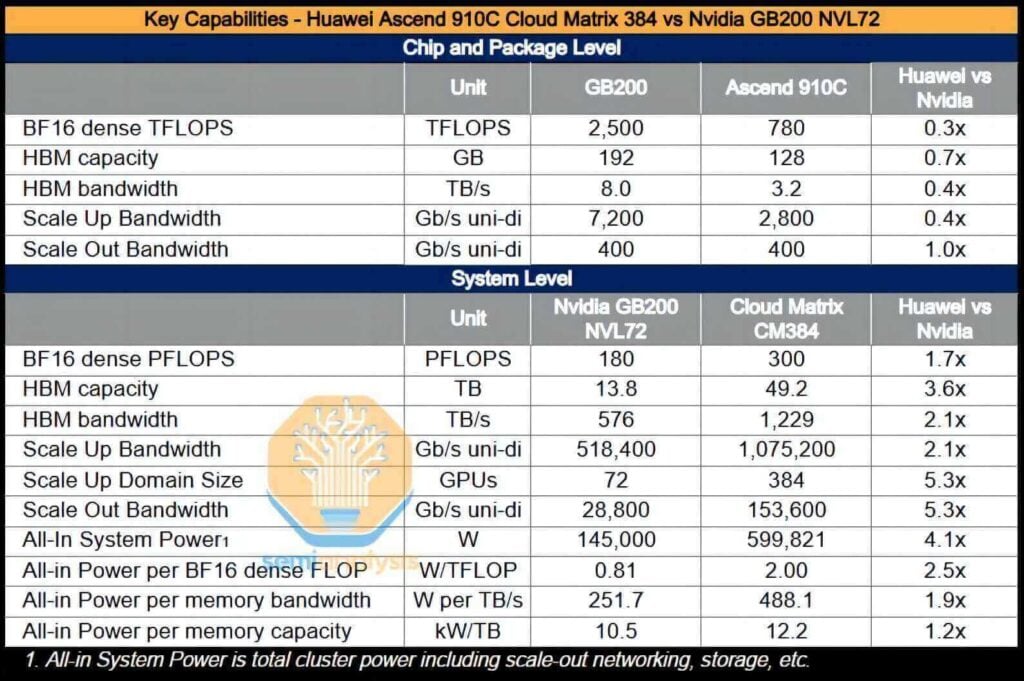
CloudMatrixシステム全体は、16ペタフロップスのBF300コンピューティング性能を実現し、GB200 NVL72のほぼ3.6倍に相当します。総メモリ容量は2.1倍以上、メモリ帯域幅はXNUMX倍に増加し、Huawei、ひいては中国は、NVIDIAが提供するAIシステムを上回るAIシステムを展開する能力を獲得しました。
さらに、CM384は、中国が明確な優位性を持つ分野、例えば国内ネットワーク生産能力、ネットワーク障害を軽減するインフラソフトウェア、製造歩留まりの向上による大規模アプリケーションへのスケールアップの可能性などと特によく合致しています。しかし、このソリューションにも欠点がないわけではありません。消費電力はGB3.9 NVL200の72倍、FLOPあたりの効率は2.3分の1.8、メモリ帯域幅効率(TB/sあたり)は1.1分のXNUMX、高帯域幅メモリ(HBM)容量効率はTBあたりXNUMX分のXNUMXとなっています。
CloudMatrix 384スーパーノードは、6,912個の400G光モジュールを活用し、高帯域幅・低遅延の光インターコネクトネットワークを構築します。UBプレーンは、5,376個のNPUを接続するために384個のモジュールを必要とし、各NPUは7個のモジュールを双方向に使用します。RDMAプレーンは、1,536層のファットツリーアーキテクチャにおいて、サーバーNIC用に384個、リーフ層スイッチ用に768個、スパイン層スイッチ用に384個、合計XNUMX個のモジュールを使用します。この正確な割り当てにより、大規模なAIおよび科学計算ワークロードにおけるノンブロッキング通信とスケーラビリティが確保されます。
エネルギー効率におけるこうした欠点にもかかわらず、電力消費の問題は中国において重大な制約とはなっていない。欧米諸国はしばしば人工知能(AI)の発展は電力供給によって制限されると主張するが、中国の状況は全く逆である。過去10年間、欧米諸国は石炭依存の電力インフラをより環境に優しい天然ガスや再生可能エネルギー源への移行、そして一人当たりのエネルギー効率の向上に多大な努力を払ってきたが、中国は生活水準の向上と大規模な投資によって電力需要の増大に直面している。
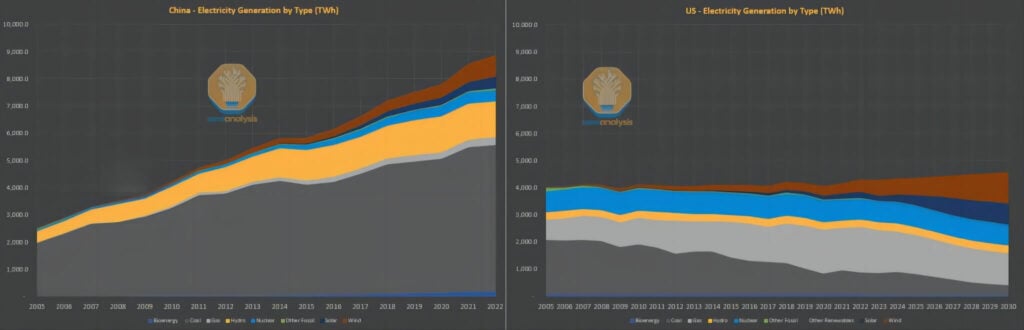
中国のエネルギーシステムは伝統的に石炭火力発電に大きく依存してきたものの、現在では太陽光、水力、風力発電の設備容量で世界をリードし、原子力発電の導入でも最前線に立っています。対照的に、米国の原子力発電容量は1970年代を彷彿とさせる水準にとどまっています。つまり、米国の電力網の改修・拡張能力は著しく低下しているのに対し、中国で2011年以降に導入された追加的な電力網容量は、米国の電力網全体の規模に匹敵する規模となっています。
電力が比較的豊富で、エネルギー消費の制約がそれほど厳しくないシナリオでは、特に光インターコネクト技術などの先進技術を設計に取り入れる場合、厳しい電力密度要件を放棄してより広範なスケーリングを優先することが、エンジニアリング上の論理的な判断となります。実際、CM384の設計は、ラックを超えたシステムレベルの制約も考慮しています。中国のAIへの野望を阻んでいるのは、電力供給の懸念だけではないというのが私たちの見解です。ファーウェイのソリューションは、持続的かつスケーラブルな拡張のための様々な道筋を提供し続けています。
Huawei 910Cチップは中国国内で完全に製造されているという誤解がよくあります。設計プロセスは完全に中国国内で行われていますが、実際の生産は依然として海外からの原材料に大きく依存しています。Samsungの高帯域幅メモリ(HBM)であれ、米国、オランダ、日本の設備であれ、生産プロセスは依然としてグローバルサプライチェーンに大きく依存しています。
Huawei社'HBM調達パス
中国が最先端技術分野で外部調達に依存していることは、課題の一部に過ぎません。高帯域幅メモリ(HBM)への依存はさらに深刻です。現在、中国はHBMの安定した国内量産をまだ達成していません。長鑫ストレージ(CXMT)が量産体制に入るには、少なくともあと13年かかると見込まれています。幸いなことに、サムスンが中国におけるHBMの主要サプライヤーとして台頭し、その結果、ファーウェイは1.6万枚のHBMスタックを事前に備蓄しました。これは、Ascend 910CチップXNUMX万個をパッケージ化するのに十分な量です。注目すべきは、この備蓄がHBM輸出禁止措置の施行前に行われたことです。
禁止されたHBMコンポーネントがグレーチャネルを通じて中国に流入し続けていることも注目に値します。現在のHBM輸出規制は、オリジナルのHBMパッケージユニットにのみ適用されます。HBMを組み込んだチップは、規定の浮動小数点演算(FLOPS)制限を超えない限り、合法的に輸送できます。この点に関して、Samsungの中華圏における唯一の販売代理店であるCoAsia Electronicsは、ASIC設計サービス企業のFaradayにHBM2Eを継続的に供給しています。Faradayは、これらのメモリコンポーネントを、コスト効率の高い16nmロジックチップとSPIL(Siliconware Precision)でパッケージ化しています。
その後、ファラデー社は完成品をシステムレベルのパッケージに収めて中国へ出荷します。この方法は技術規制に準拠していますが、設計には極めて低強度で低温のはんだバンプが組み込まれており、HBMをパッケージから容易に取り外すことができます。つまり、この場合のいわゆる「パッケージング」とは、緩く統合され、ほぼ形式化されたアセンブリに相当します。
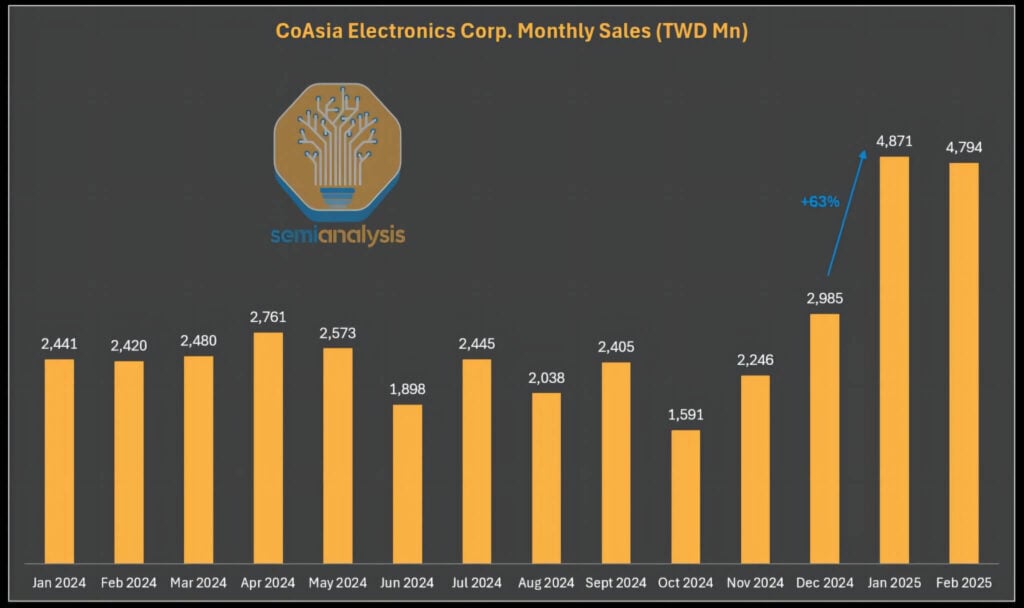
2025年に輸出規制が施行されて以来、CoAsia Electronicsの収益は急増しており、これは決して偶然ではないようだ。
中国国内のファウンドリーは成長の可能性を維持
中国の半導体産業は依然として海外生産に依存していますが、国内サプライチェーンの能力は急速に向上しており、長らく過小評価されてきました。私たちは、SMIC(Semiconductor Manufacturing International Corporation)とCXMT(ChangXin Memory Technologies)の製造力を引き続き注視しています。歩留まりと生産能力に関する課題は依然として残っていますが、中国製GPUのスケーラブルな生産に向けた長期的な軌道は依然として注目に値します。
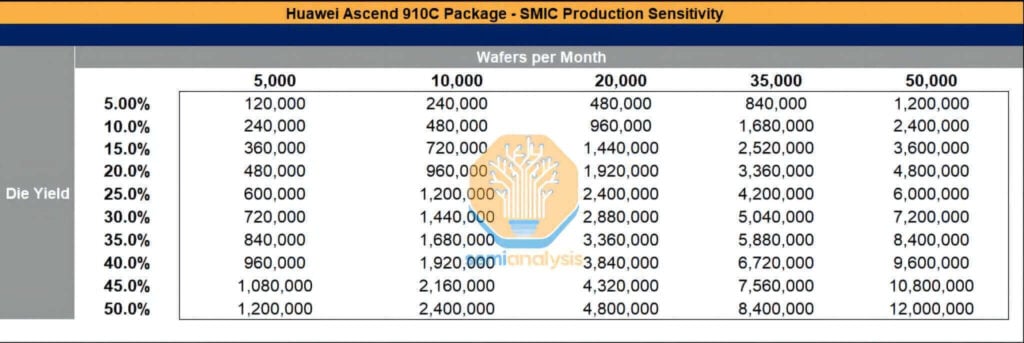
SMICとCXMTは制裁の圧力下でも数百億ドル相当の製造設備を確保しており、同時に大量の化学薬品や材料を海外から独占的に輸入し続けています。例えばSMICは、上海、深圳、北京で先端プロセス能力を拡大しています。今年の月間ウェハ生産量は50,000万枚に迫ると予測されており、継続的な海外設備の導入と、それほど厳格ではない制裁措置の執行によって、持続的な拡大がさらに推進されています。歩留まりが改善すれば、Ascend 910Cチップのパッケージング量は相当なレベルに達する可能性があります。
TSMC はすでに 2.9 ~ 2024 年の生産用に 2025 万枚のウェーハを割り当てており、これは Ascend 800,000B チップ約 910 万個と Ascend 1.05C チップ約 910 万個を生産するのに十分な能力ですが、高帯域幅メモリ (HBM)、ウェーハ製造装置、装置保守リソース、および必須化学物質 (フォトレジストなど) が効果的に規制されない限り、SMIC の生産能力が爆発的に増加する可能性は依然として残っています。
CloudMatrix 384 システムアーキテクチャ
以下の分析では、CloudMatrix 384 システムのアーキテクチャ設計を詳しく調べ、垂直および水平拡張ネットワーク、電力消費予算、および全体的なコスト構造を検討します。
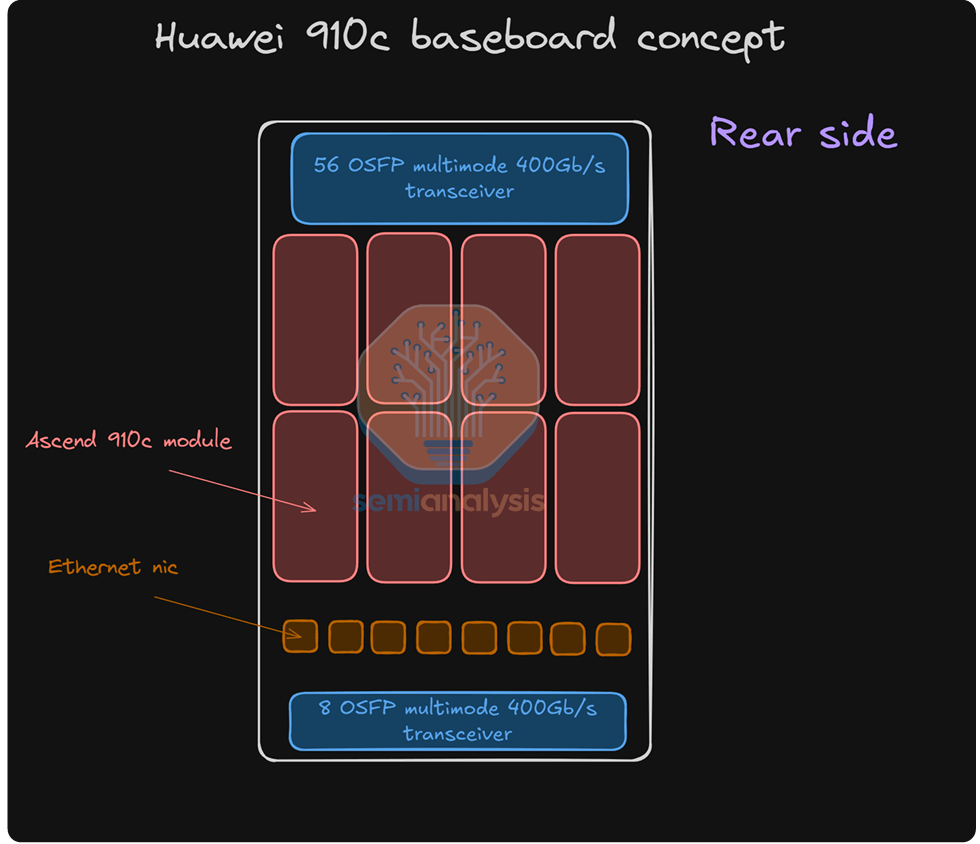
CloudMatrixシステム全体は16個のラックに分散配置されています。そのうち12個のコンピューティングラックにはそれぞれ32個のGPUが搭載され、中央に配置されたXNUMX個のラックは垂直拡張スイッチラックとして機能します。ハイパースケールクラスタを実現するために、ファーウェイは光通信技術を統合したラック間垂直拡張アプローチを採用しています。この戦略は数百個のGPU間の完全な相互接続を可能にしますが、かなりの技術的課題を伴います。

DGX H100 NVL256「レンジャー」との類似点
NVIDIAは2022年という早い時期にDGX H100 NVL256「Ranger」プラットフォームを発表しましたが、このシステムは量産には至りませんでした。これは、法外なコスト、過剰な消費電力、そして過剰な光トランシーバー要件と二重層ネットワークアーキテクチャに起因する固有の信頼性問題が原因でした。一方、Huawei CloudMatrix Podはより極端なアプローチを採用しています。ネットワーク設計には6,912個の400Gリニアプラガブルオプティカル(LPO)モジュールが必要であり、その大部分は垂直拡張ネットワーク相互接続を可能にします。
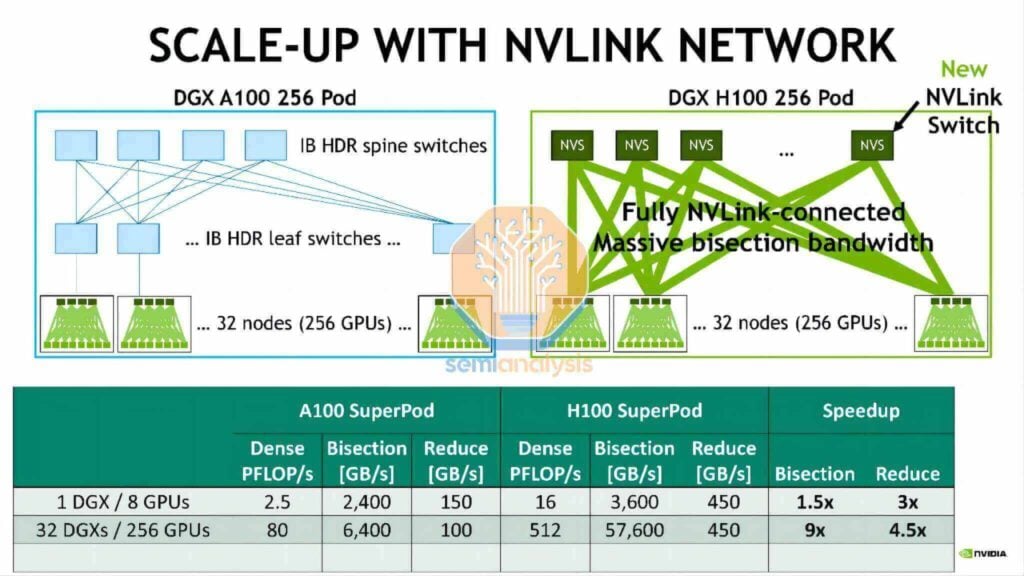
CloudMatrix 384垂直拡張トポロジーの評価
このセクションでは、384チップに及ぶHuaweiの垂直拡張ラックアーキテクチャ(NVLinkに匹敵する設計)を詳細に評価します。分析では、垂直および水平拡張ネットワーク、システム消費電力の包括的な内訳、そして光モジュールの大規模導入(およびそれに伴う銅線ケーブルの不使用)が全体的なパフォーマンスとコストに及ぼす影響について評価します。特に、HuaweiのLPOモジュールの広範な導入に伴うコストへの影響についても触れています。
コアパラメータ
Huawei Ascend 910C GPUは、2,800基あたり7,200 Gbit/sの単方向垂直拡張帯域幅を提供します。これは、NVIDIAのGB200 NVL72がGPUあたり72 Gb/sの垂直拡張帯域幅を提供するのとほぼ同等の規模です。NVIDIA NVLXNUMXは高密度の直接銅線ケーブルで垂直ネットワーク相互接続を実現していますが、Huaweiはよりシンプルなアプローチを採用し、XNUMX本のケーブルを配備しています。 400G光トランシーバー スタック構成では GPU あたり 2,800 Gbit/s の数値に達します。
しかし、この戦略はコストが高く、消費電力が大幅に増加するだけでなく、エアフロー管理や設置・保守の容易性にも課題が残ります。これらの課題にもかかわらず、このアプローチはシステムの機能目標をうまく達成しています。垂直拡張ネットワーク自体は単層アーキテクチャを採用し、フラットな単層トポロジに配置された16,800台のモジュラースイッチを介してすべてのGPUを相互接続します。これらのスイッチは、Huawei独自のラインカードとスイッチングマトリクスプレーンを活用し、BroadcomのJericho3ラインカードとAristaのモジュラースイッチに搭載されているRamon3スイッチングマトリクスカードを組み合わせたものと同様のセルスプレーメカニズムを採用しています。
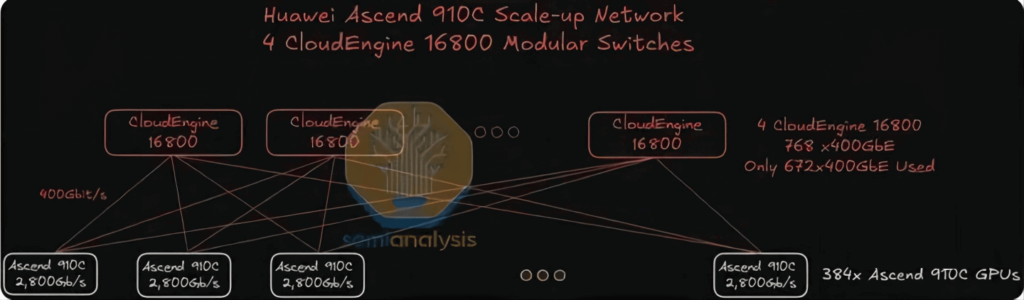
垂直光インターコネクト拡張と銅線フリー設計
垂直拡張のために5,000個の光モジュールを導入すると、信頼性の問題が発生する可能性があります。これを軽減するには、このような大規模な光モジュールの導入によって発生する可能性のある潜在的な障害に対処するための、高品質のフォールトトレラントトレーニングソフトウェアが必要です。
各CloudMatrix 384 Podには、合計6,912個の400G光モジュール/トランシーバーが搭載されています。このうち5,376個は垂直拡張ネットワーク用に割り当てられ、残りの1,536個は水平拡張ネットワーク用に割り当てられます。
384つのPodには910個のAscend 2.8Cチップが搭載され、各チップは垂直拡張通信用に400Tbpsの相互接続帯域幅を提供します。したがって、各チップには384個の7Gトランシーバが必要となり、Podあたり2,688個のGPU × 2,688 = 5,376個のトランシーバが必要になります。単層のフラットトポロジーであるため、スイッチ側ではこの展開を400個のトランシーバでミラーリングする必要があり、垂直拡張ネットワークでは合計XNUMX個のXNUMXGトランシーバを使用することになります。
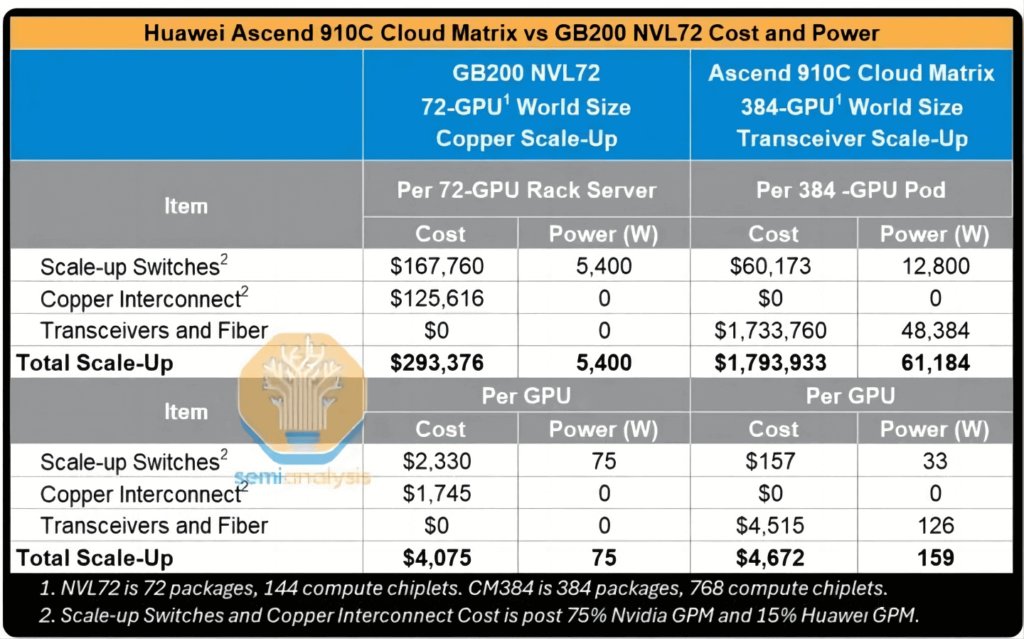
400Gリニアプラガブルオプティカル(LPO)トランシーバー(200台あたり6.5ドル未満、モジュールあたり約72Wの消費電力)を使用した場合、スーパーノードの垂直拡張ネットワークの総所有コスト(TCO)はNVL72ラックの約72倍、消費電力はNVL30の72倍を超えます。GPUあたりで見ても、消費電力はNVLXNUMXのXNUMX倍でコストは比較的同程度ですが、計算性能はNVLXNUMXのXNUMX%にしか達しません。
CloudMatrix 384 水平拡張トポロジー評価
CloudMatrix 384は、デュアルレイヤー8トラックの最適化されたトポロジを採用しています。水平拡張用のCloudEngineモジュラースイッチには、768個の400Gポートが搭載されており、そのうち384個は384基のGPUに下位接続し、残りの384ポートは上位接続用に予約されています。各Podには384基のGPU(それぞれに400Gネットワークインターフェースカードを搭載)が搭載されているため、0.5台のスパインスイッチを超えるアクセスには、追加のリーフスイッチが必要です。
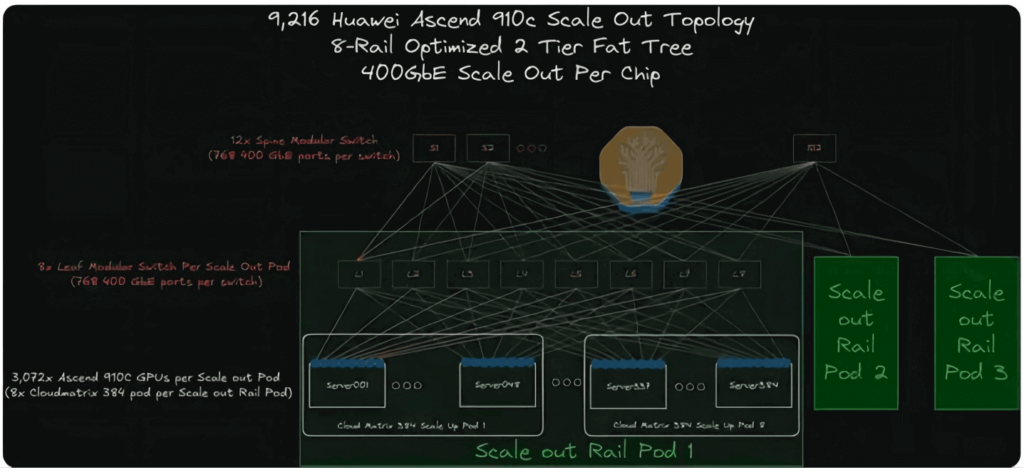
このネットワークのトランシーバーの計算は簡単です。
- GPU 側: 384 個の 400G トランシーバーが必要です (GPU ごとに XNUMX 個)。
- リーフ レイヤー: ポートの半分は上向きの接続 (GPU とスパイン レイヤーのリンク) に使用されるため、必要なトランシーバーの数は 2 倍にする必要があります。
- 合計:水平拡張ネットワークには、384 × 4 = 1,536 個の 400G トランシーバーが必要です。
LPO トランシーバー
ファーウェイが提案するクラスタ全体の消費電力を削減する潜在的な対策の30つは、光伝送用のリニアプラガブルオプティカル(LPO)モジュールの採用です。LPOモジュールは、内部デジタル信号プロセッサ(DSP)を必要とせず、光信号を介して直接データを伝送するように設計されています。従来のトランシーバは、タイミングの調整/回復のためにアナログ信号をデジタルに変換してから再びアナログに変換しますが、LPOモジュールは、ホストから光デバイスへの電気信号を直接線形伝送します。この設計により、モジュールの内部アーキテクチャが簡素化され、消費電力とコストの両方が384%以上削減されます。ただし、多数のトランシーバが依然として必要なため、CM72クラスタの全体的な消費電力は、NVLXNUMXと比較して依然として大幅に高くなります。
チップレベル
HuaweiのAscend 910Bおよび910Cアクセラレータは、中国製GPUの最高峰です。一定の技術的制約があるにもかかわらず、そのパフォーマンスは依然として卓越しています。しかし、チップレベルでは、同等のNVIDIA製品にはまだ及ばない状況です。
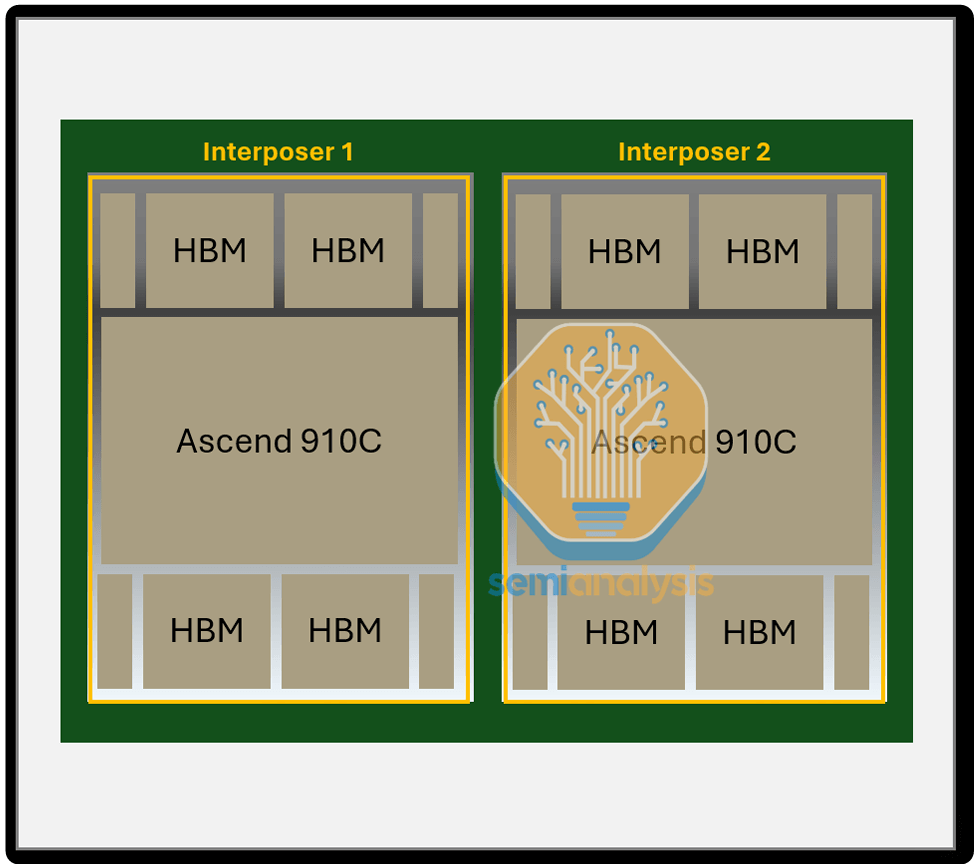
Ascend 910Cは910Bの派生製品であり、910つのXNUMXBチップのインターポーザー層を単一の基板に統合しています。この統合により、シングルチップのコンピューティング性能とメモリ帯域幅が実質的にXNUMX倍になります。
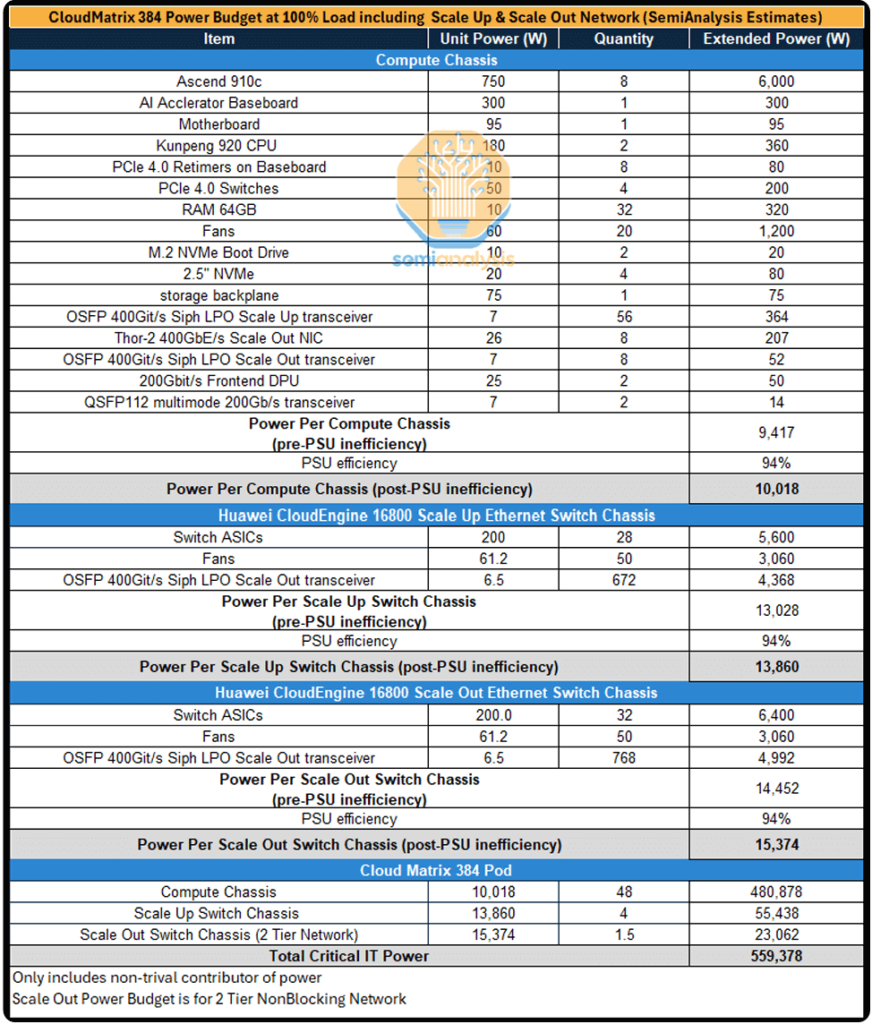
システムレベルの消費電力の見積もり
垂直および水平拡張ネットワークの両方に光トランシーバーが広範囲に導入されているため、384基のGPUを搭載したクラスターの消費電力は非常に高くなります。CM384スーパーノード500基あたりの消費電力は約145キロワットと推定されており、これはNVIDIA GB200 NVL72ラックの約XNUMXキロワットのXNUMX倍以上です。
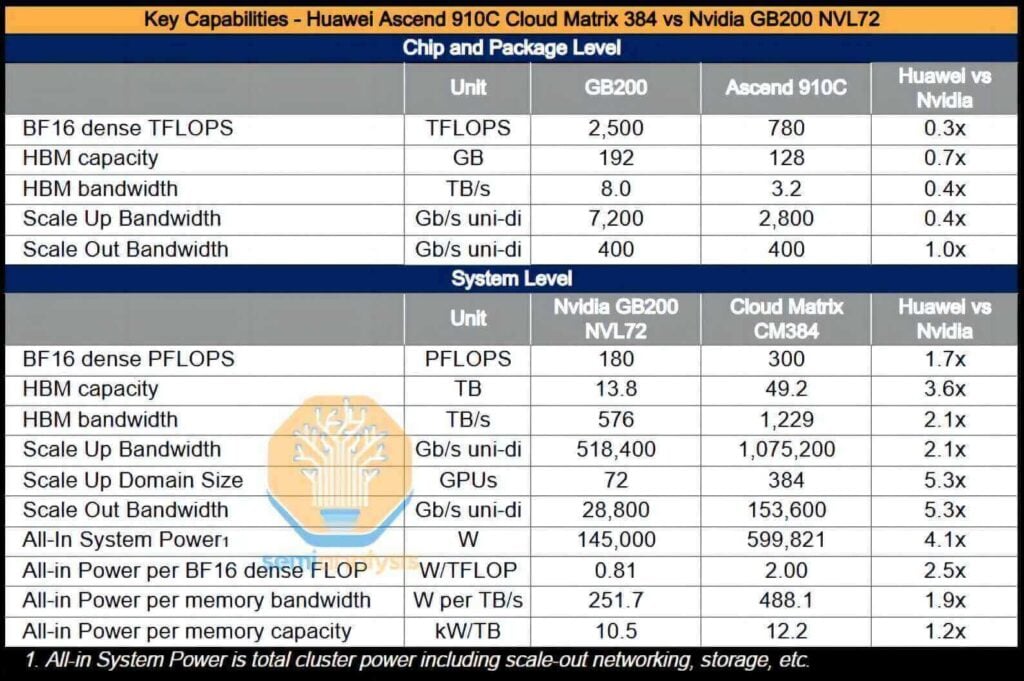
シングルGPUのエネルギー効率の比較
個々のGPUベースで見ると、Huawei GPUの総消費電力はNVIDIA NVL70 B80 GPUの約72%~200%です。スーパーノード全体のパフォーマンスに関しては、HuaweiソリューションはNVL70と比較して72%高い浮動小数点演算/秒(FLOPS)を実現します。ただし、アーキテクチャ設計により、エネルギー効率に関して以下のデメリットが生じます。
- FLOPあたりの消費電力: 2.3倍
- メモリ帯域幅1.8TB/秒あたりの消費電力: XNUMX倍
- HBM メモリ容量 1.1 TB あたりの消費電力: XNUMX 倍。
これらの追加支出と消費電力の増加は、中国が西側諸国の計算性能レベルに追いつくために負担しなければならないコストです。中国の豊富なエネルギー資源と、こうしたプロジェクトにおける国家安全保障の重要性を考えると、これらのコストは比較的管理可能な範囲にあると考えられます。中国のエネルギー優位性は、データセンターの規模と速度の両面での拡張を可能にする重要な資産となるでしょう。
関連製品:
-
 OSFP-400G-SR8 400G SR8 OSFP PAM4 850nm MTP/MPO-16 100m OM3 MMF FEC 光トランシーバー モジュール
$225.00
OSFP-400G-SR8 400G SR8 OSFP PAM4 850nm MTP/MPO-16 100m OM3 MMF FEC 光トランシーバー モジュール
$225.00
-
 OSFP-400G-DR4 400G OSFP DR4 PAM4 1310nm MTP / MPO-12 500m SMFFEC光トランシーバーモジュール
$800.00
OSFP-400G-DR4 400G OSFP DR4 PAM4 1310nm MTP / MPO-12 500m SMFFEC光トランシーバーモジュール
$800.00
-
 OSFP-400G-PSM8 400G PSM8 OSFP PAM4 1550nm MTP/MPO-16 300m SMF FEC 光トランシーバー モジュール
$1000.00
OSFP-400G-PSM8 400G PSM8 OSFP PAM4 1550nm MTP/MPO-16 300m SMF FEC 光トランシーバー モジュール
$1000.00
-
 OSFP-400G-SR4-FLT 400G OSFP SR4 フラットトップ PAM4 850nm OM30 で 3m/OM50 で 4m MTP/MPO-12 マルチモード FEC 光トランシーバ モジュール
$550.00
OSFP-400G-SR4-FLT 400G OSFP SR4 フラットトップ PAM4 850nm OM30 で 3m/OM50 で 4m MTP/MPO-12 マルチモード FEC 光トランシーバ モジュール
$550.00
-
 OSFP-400G-DR4-FLT 400G OSFP DR4 フラットトップ PAM4 1310nm MTP/MPO-12 500m SMF FEC 光トランシーバ モジュール
$700.00
OSFP-400G-DR4-FLT 400G OSFP DR4 フラットトップ PAM4 1310nm MTP/MPO-12 500m SMF FEC 光トランシーバ モジュール
$700.00
-
 QSFP112-400G-SR4 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC 光トランシーバー モジュール
$450.00
QSFP112-400G-SR4 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC 光トランシーバー モジュール
$450.00
-
 QSFP112-400G-DR4 400G QSFP112 DR4 PAM4 1310nm 500m MTP/MPO-12、KP4 FEC 光トランシーバ モジュール付き
$650.00
QSFP112-400G-DR4 400G QSFP112 DR4 PAM4 1310nm 500m MTP/MPO-12、KP4 FEC 光トランシーバ モジュール付き
$650.00
-
 QSFP112-400G-FR1 4x100G QSFP112 FR1 PAM4 1310nm 2km MTP/MPO-12 SMF FEC 光トランシーバ モジュール
$1200.00
QSFP112-400G-FR1 4x100G QSFP112 FR1 PAM4 1310nm 2km MTP/MPO-12 SMF FEC 光トランシーバ モジュール
$1200.00
-
 NVIDIA MMA4Z00-NS400 互換 400G OSFP SR4 フラットトップ PAM4 850nm OM30 で 3m/OM50 で 4m MTP/MPO-12 マルチモード FEC 光トランシーバ モジュール
$550.00
NVIDIA MMA4Z00-NS400 互換 400G OSFP SR4 フラットトップ PAM4 850nm OM30 で 3m/OM50 で 4m MTP/MPO-12 マルチモード FEC 光トランシーバ モジュール
$550.00
-
 NVIDIA MMS4X00-NS400 互換 400G OSFP DR4 フラットトップ PAM4 1310nm MTP/MPO-12 500m SMF FEC 光トランシーバー モジュール
$700.00
NVIDIA MMS4X00-NS400 互換 400G OSFP DR4 フラットトップ PAM4 1310nm MTP/MPO-12 500m SMF FEC 光トランシーバー モジュール
$700.00
-
 NVIDIA MMA1Z00-NS400互換400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC光トランシーバーモジュール
$550.00
NVIDIA MMA1Z00-NS400互換400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC光トランシーバーモジュール
$550.00
-
 NVIDIA MMS1Z00-NS400 互換 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 FEC 光トランシーバー モジュール付き
$700.00
NVIDIA MMS1Z00-NS400 互換 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 FEC 光トランシーバー モジュール付き
$700.00