
新世代の Blackwell プラットフォーム
19 年 2024 月 XNUMX 日、NVIDIA は GTC で新世代の Blackwell アーキテクチャ プラットフォームを発表しました。
この新しいプラットフォームには、新しい AI チップ GB200、第 576 世代の Transformer エンジン (独自の Blackwell Tensor コア テクノロジーを利用して AI 推論機能とモデル サイズを 9 倍にする)、第 XNUMX 世代 NVLink ソリューション (数兆のパラメーターと複雑な AI モデルを高速化するように設計) が含まれます。 、最大 XNUMX 個の GPU を相互接続でき、GPU スループットが XNUMX 倍向上します)、RAS (信頼性、可用性、および保守性) エンジン (潜在的な障害を早期に特定し、ダウンタイムを削減し、インテリジェントなリカバリおよびメンテナンス機能を強化します)、インテリジェント セキュリティ サービス (全体的なパフォーマンスを損なうことなく AI モデルと顧客データを保護し、医療や金融などの高度なデータ プライバシー要件がある業界向けにカスタマイズされた次世代のネイティブ インターフェイス暗号化プロトコルをサポートします。
図 1: NVIDIA が次世代 Blackwell プラットフォームを発表

NVIDIA の NVLink 次世代ネットワーク アーキテクチャ分析
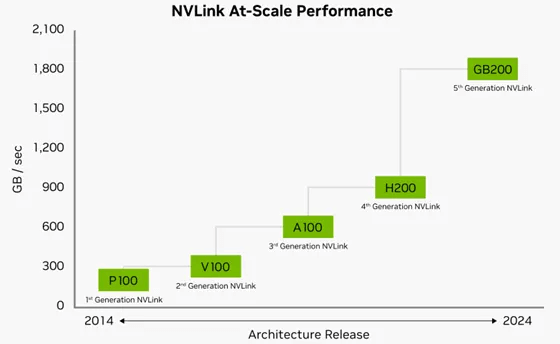
NVIDIA の第 1.8 世代 NVLink は、シングルコア Blackwell GPU あたり合計 18TB/秒の帯域幅を備え、大規模なマルチ GPU クラスターのスケーラビリティを大幅に向上します。各 Blackwell Tensor Core GPU は最大 100 個の NVLink 1.8GB/秒接続をサポートし、最大 200TB/秒の合計帯域幅を提供します。この帯域幅パフォーマンスは、NVIDIA の前世代 H14 製品の 5.0 倍、PCIe 200 テクノロジの 72 倍です。GBXNUMX NVLXNUMX サーバー プラットフォームは、NVIDIA の最新の NVLink テクノロジを活用して、世界で最も複雑な大規模 AI モデルに優れたスケーラビリティを提供します。
図 2: NVIDIA の第 5 世代 NVLink ネットワーク アーキテクチャのパフォーマンス
千枚のカードクラスタをサポートするNVIDIAの新しいIBスイッチプラットフォームQuantum-X800
NVIDIA は世界初のエンドツーエンドを導入しました 800G インフィニバンド ネットワーク スイッチ プラットフォーム、Quantum-X800 は、兆パラメータ スケールの AI ラージ モデル向けに調整されています。新しい NVIDIA IB スイッチ プラットフォームは、ハードウェア ベースのネットワーク内コンピューティング テクノロジ、スケーラブルな階層型集約削減プロトコル SHARP v4、適応ルーティング、およびリモート監視に基づくネットワーク輻輳制御をサポートします。これは XNUMX つのコア コンポーネントで構成されます。
NVIDIA Quantum-X800 Q3400-RA 4U InfiniBand スイッチ: シングルチャネル 200Gb/s テクノロジを採用した世界初のスイッチで、ネットワーク パフォーマンスと伝送速度を大幅に向上します。このスイッチは、144 個の 800T OSFP-XD 光モジュール (NVIDIA の UFM 統合ファブリック マネージャを介して接続) によって、それぞれ 72GB/s の速度を持つ 1.6 個のポートを提供します。新しい Quantum-X800 Q3400 スイッチの高性能を活用し、10,368 層のファットツリー ネットワーク トポロジにより、ネットワークの局所性を最大限に維持しながら、最大 3400 個のネットワーク インターフェイス カード (NIC) を非常に低いレイテンシで接続できます。Q19 スイッチは空冷式で、標準の 3400 インチ ラックと互換性があります。NVIDIA は、Open Compute Project (OCP) 21 インチ ラックに適した QXNUMX-LD 並列液体冷却モードも提供しています。
図 3: NVIDIA の新世代 IB スイッチ プラットフォーム Quantum-X800

NVIDIA ConnectX-8 SuperNIC ネットワーク インターフェイス カード: NVIDIA の最新世代のネットワーク アダプター アーキテクチャを活用し、エンドツーエンドの 800Gb/s ネットワークとパフォーマンス分離を提供します。これは、マルチテナント生成 AI クラウドを効率的に管理するために特別に設計されています。ConnectX-8 SuperNIC は、PCIe 800 経由で 6.0Gb/s のデータ スループットを提供し、NVIDIA GPU システムの内部 PCIe スイッチングを含むさまざまなアプリケーションに最大 48 の伝送チャネルを提供します。さらに、新しい SuperNIC は、NVIDIA の最新のネットワーク内コンピューティング テクノロジ、MPI_Alltoall、MPI タグ マッチング ハードウェア エンジン、および高品質サービスやネットワーク輻輳制御などの構造強化をサポートしています。ConnectX-8 SuperNIC は、シングル ポート OSFP224 およびデュアル ポート QSFP112 コネクタをサポートし、OCP3.0 や CEM PCIe x16 などのさまざまなフォーム ファクターと互換性があります。また、NVIDIA Socket Direct 16 チャネル補助拡張もサポートしています。
図 4: NVIDIA ConnectX-8 SuperNIC 新しい IB ネットワーク インターフェイス カード

LinkX ケーブルおよびトランシーバー: NVIDIA の Quantum-X800 プラットフォーム インターコネクト製品ポートフォリオには、パッシブ ダイレクト アタッチ ケーブル (DAC) およびリニア アクティブ銅線ケーブル (LACC) を備えた接続トランシーバーが含まれており、優先ネットワーク トポロジを構築するためのより高い柔軟性を提供します。この相互接続ソリューションには、特にデュアルポート シングルモード 2xDR4/2xFR4 接続トランシーバー、パッシブ DAC ケーブル、およびリニア アクティブ銅ケーブル LACC が含まれています。
図 5: NVIDIA LinkX ケーブルとトランシーバー

NVIDIA GB200 NVL72 ソリューション
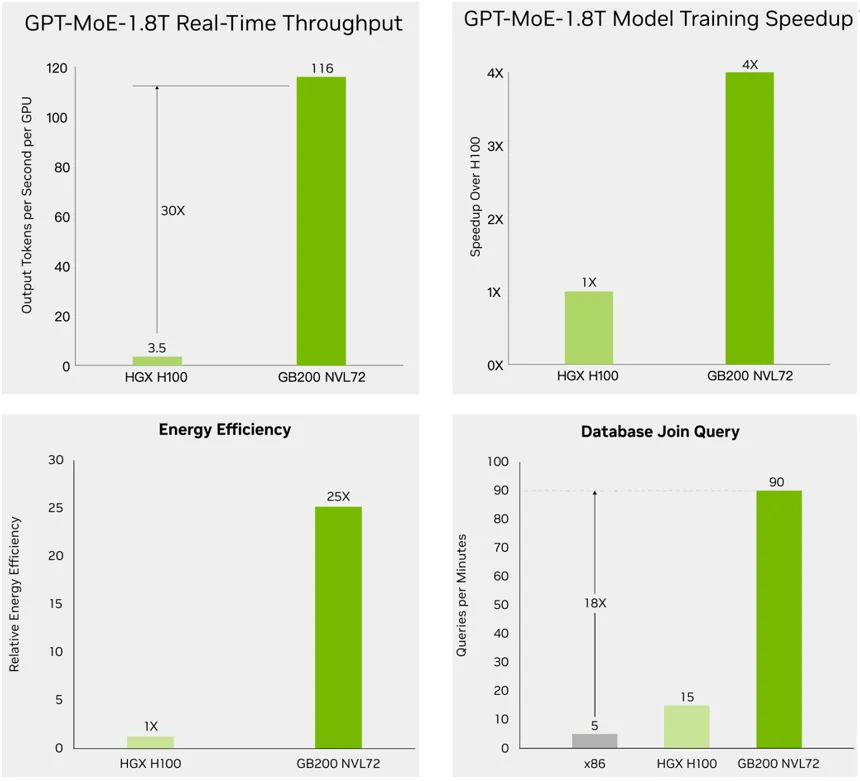
NVIDIA GB200NBL72 ソリューションは、推論速度が 30 倍、トレーニング速度が 4 倍、電力効率が 25 倍向上し、兆パラメータ AI モデルのデータ処理パフォーマンスが 18 倍向上します。
図 6: NVIDIA が GB200 NVL72 ソリューションをリリース

- 推論パフォーマンスの点では、GB200 NVL72 ソリューションは、FP4 AI をサポートする最新世代の Transformer エンジンを利用し、第 30 世代 NVLink を採用して、兆パラメータの大規模モデルに対する大規模言語モデル (LLM) の推論パフォーマンスを 72 倍向上させています。新しい Tensor Core マイクロフォーマットにより高い精度とスループットを実現し、液体冷却により XNUMX 個の GPU からなる大規模な GPU クラスターを単一のキャビネットに実装します。
- トレーニングのパフォーマンスに関しては、FP8 精度を備えた第 4 世代の Transformer エンジンにより、大規模な言語モデルと大規模なトレーニングの速度が 1.8 倍高速化されます。 InfiniBand スイッチ ネットワークと NVIDIA Magnum IO ソフトウェアを使用した第 XNUMX 世代 NVLink を通じて、GPU 間の相互接続速度 XNUMXTb/s を実現します。
- 電力効率に関しては、水冷 GB200 NVL72 はデータセンターのエネルギー消費を大幅に削減します。液体冷却テクノロジーは、サーバー ラックの設置面積を削減しながらコンピューティング密度を向上させ、大規模な NVLink ドメイン アーキテクチャ内で高帯域幅、低遅延の GPU 通信を可能にします。前世代の NVIDIA H100 空冷キャビネットと比較して、GB200 水冷キャビネットは、水の使用量を効果的に削減しながら、同じ消費電力でパフォーマンスを 25 倍向上させます。
- データ処理パフォーマンスの点では、NVIDIA Blackwell アーキテクチャの高帯域幅メモリ パフォーマンス、NVLink-C2C テクノロジ、および専用の解凍エンジンを活用して、GB200 は重要なデータベース クエリ速度を CPU と比較して 18 倍高速化し、TCO コストを 5 倍削減します。
図 7: 200 倍優れた推論パフォーマンス、72 倍優れたトレーニング パフォーマンス、30 倍優れた電力効率を備えた NVIDIA の GB4 NVL25 ソリューション
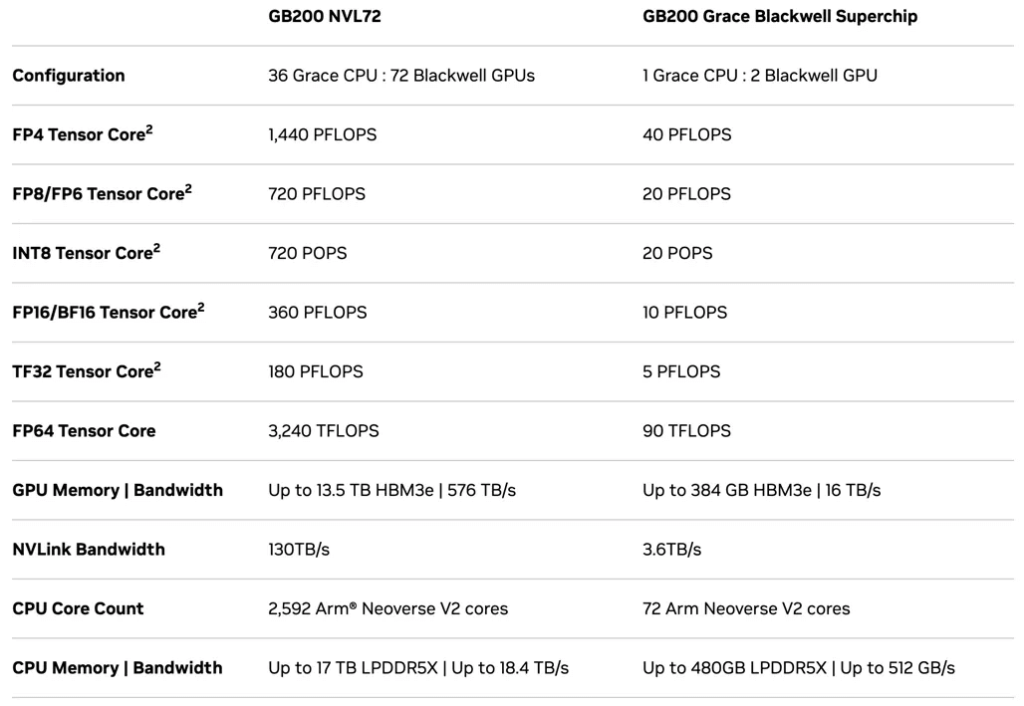
NVIDIA の GB200 NVL72 シングル キャビネットは、9 個の L1 NV スイッチ スイッチと 18 個のコンピューティング ノードで構成されます。各計算ノードはキャビネット内の単層 GPU トレイで構成され、各トレイには 2 つのモジュールが含まれています。各ユニットは 2 つの Blackwell GPU と 1 つの Grace CPU で構成され、トレイごとに合計 4 つの GPU になります。キャビネットには 18 個の計算ノード (上半分に 10 個、下半分に 9 個) が収容され、合計 72 個の Blackwell GPU と 36 個の Grace CPU が搭載されています。演算性能は1440PFLOPS(FP4)/720PFLOPS(FP8/FP6)/720PFLOPS(INT8)を実現し、GPUメモリは最大13.5TB(HBM3e)を搭載。相互接続パラメータには、72 個の OSFP シングルポート ConnectX-7 VPI (400G インフィニバンド)、ConnectX-8 ネットワーク カードのパフォーマンス パラメータはまだ更新されていません。 GB200 AI チップのパフォーマンスは 40PFLOPS (FP4)/20PFLOPS (FP8/FP6)/10PFLOPS (INT8) を達成でき、最大 GPU メモリは 384GB (HBM3e) です。
図 8: NVIDIA が GB200 Superchip AI チップを発表

NVIDIA、GB200 Superchip AI チップをリリース
NVIDIA GB200 NVL72 および GB200 AI チップの詳細なパフォーマンス パラメーター
NVIDIA の次世代 GB200 ネットワーク アーキテクチャの銅線接続と光モジュールの要件の分析
224GB スイッチ時代には銅線接続が費用対効果の高い利点をもたらします
銅線接続は、スイッチとサーバーの高密度クラスタ化の傾向において、価格/パフォーマンスと消費電力の点で利点があり、銅線ケーブル接続は、段階的に 224Gb/s スイッチ時代の最良のソリューションになると期待されています。 NVIDIA の GB200 ソリューションにおける重要な変更点は、単一キャビネット内のスイッチと計算ノード間の相互接続と、以前の PCB-光モジュール-ケーブル接続の代わりに銅線ケーブル接続によるスイッチの内部接続にあります。 GB200 相互接続は、次の XNUMX つの主要なカテゴリに分類されます。
(1) GB200 NVL72 キャビネット間接続 (外部ケーブル): 大規模なデータセンターでは、並列コンピューティングのために多数のキャビネットが必要になることがよくあります。キャビネットを外部でネットワーク接続する必要がある場合、キャビネットは TOR スイッチを介して DAC/AOC ケーブルで接続されます (図 10 を参照)。キャビネットの数が多い場合は、外部相互接続をキャビネット内の配線機器の上に設置して、秩序正しく接続する必要があります。 ケーブル長が長い場合が多く、銅線ケーブルは 2 ~ 4 メートルを超えると接続要件を満たせないため、主に光ファイバーケーブルを使用して長距離相互接続を接続し、このリンク内の銅線ケーブルを完全に接続することはできません。光ファイバーケーブルを交換してください。
図 9: NVIDIA GB200 NVL72 キャビネット間の相互接続図

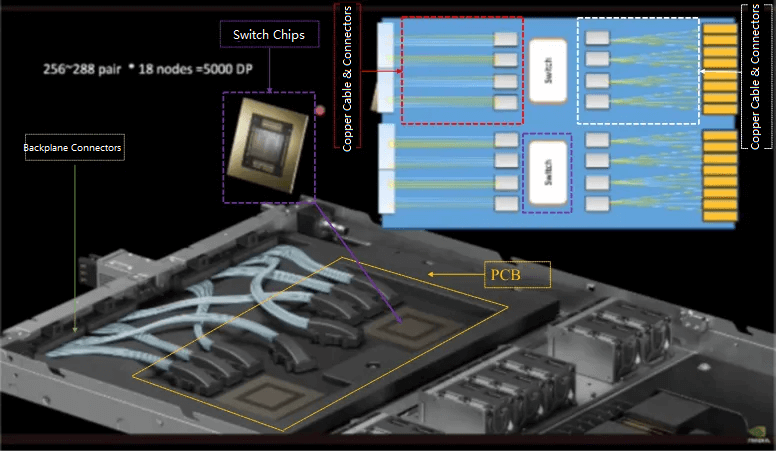
(2) GB200 NVL72 シングルキャビネット接続 (キャビネット内部ケーブル) – すべて銅線ケーブルに置き換えられました。 図 10 では、10 つのコンピューティング ノードと XNUMX つのスイッチが、図 XNUMX の黄色の領域の銅線ケーブルを介して内部接続されています。 銅線ケーブル バックプレーンは、PCB バックプレーン - 光モジュール - ケーブル接続を介した以前の TOR スイッチおよびコンピューティング ノードの使用を置き換えます。 224GB/s の単一チャネルを備えた新世代のスイッチの場合、800G/1.6T 光モジュールの消費電力は通常 16W を超え、GB200 NVL72 の接続方式が以前の光モジュールの接続に基づいている場合、消費電力が高いという問題が発生します。銅線接続は消費電力が少なく、光モジュールよりもコスト効率が高くなります。 Broadcom CEO も最近、銅線接続の姿勢を支持していることを示しました。 「通信ネットワーク内の光デバイスは多くの電力とコストを消費するため、Broadcom の新世代スイッチ開発では光デバイスの使用を避け、可能な限り銅線接続プログラムを使用しています。光デバイスは、銅線伝送が需要を満たせない場合にのみ使用されます。」
図 10: NVIDIA GB200 NVL72 シングル シャーシ内のスイッチとコンピューティング ノードの接続の概略図

図 11: NVIDIA GB200 NVL72 銅線ケーブル バックプレーンとバックプレーン コネクタの概略図

3) NV スイッチ内部 – 銅線ケーブルを使用してバックプレーン コネクタからスイッチ チップへの接続を実現します。シングル チャネル 224Gb/s スイッチの場合、図 13 の黄色の部分に示すように、PCB ボードの面積も制限されます。領域全体をカバーするには十分ではないため、長距離にわたるリンク接続を実現することはできません。銅ジャンパ線はバックプレーンからスイッチチップまでの接続を実現できます。
図 12: NVIDIA GB200 NVL72 スイッチの内部銅線接続ソリューションの概略図
1.6T光モジュール GB200 ソリューションによって促進される大量生産の機会をもたらすことが期待されています。
NVIDIA の新世代 Blackwell プラットフォームは、より高い伝送速度を備えた 1.6T 光モジュールの需要を促進します。 NVIDIA が新たにリリースした Quantum-X800 Q3400-RA 4U InfiniBand スイッチのパフォーマンスによると、シングル チャネル 200Gb/s テクノロジーを搭載した世界初のスイッチであり、144 個の 800T OSFP によって実現される 72GB/s の接続速度を備えた 1.6 ポートを提供します。光モジュール。したがって、GB200 ソリューションにおける新世代スイッチの段階的な適用により、1.6T 光モジュールの需要が高まることが予想されます。
大規模な GPU クラスター アプリケーション シナリオにおける Blackwell プラットフォームでは、キャビネット間の相互接続を実現するために依然として光モジュールが必要であり、800G 光モジュールの需要は維持されるでしょう。
(1) GB200 シングル キャビネット (72 GPU に対応): 新世代の GB200 シングル キャビネット プログラムでは、相互接続を実現するために光モジュールは不要になります。
(2) 1 ~ 8 個の GB200 NVL72 クラスター (72 ~ 576 GPU に相当) の間では、キャビネット間の相互接続を実現するために、依然としていくつかの 800G 光モジュールが必要です。データの 20% をキャビネット間で送信する必要がある場合、7200Gb の NVLink 単方向総伝送帯域幅は、800 つの GPU と 1G 光モジュールの需要比 2:XNUMX に相当します。
(3) 8 個以上の大規模 GB200 NVL72 クラスター (576 個以上の GPU に相当) は、GPU と 3G 光モジュールの需要の比率 800:1 に応じて、InfiniBand レイヤ 2.5 ネットワークを構成することが期待されます。第 1 層が 2:200 の場合、GB1 全体の需要比率は 4.5:XNUMX になると予想されます。
関連製品:
-
 OSFP-800G-FR4 800G OSFP FR4 (回線あたり 200G) PAM4 CWDM デュプレックス LC 2km SMF 光トランシーバー モジュール
$3500.00
OSFP-800G-FR4 800G OSFP FR4 (回線あたり 200G) PAM4 CWDM デュプレックス LC 2km SMF 光トランシーバー モジュール
$3500.00
-
 OSFP-800G-2FR2L 800G OSFP 2FR2 (回線あたり 200G) PAM4 1291/1311nm 2km DOM デュプレックス LC SMF 光トランシーバ モジュール
$3000.00
OSFP-800G-2FR2L 800G OSFP 2FR2 (回線あたり 200G) PAM4 1291/1311nm 2km DOM デュプレックス LC SMF 光トランシーバ モジュール
$3000.00
-
 OSFP-800G-2FR2 800G OSFP 2FR2 (回線あたり 200G) PAM4 1291/1311nm 2km DOM デュアル CS SMF 光トランシーバ モジュール
$3000.00
OSFP-800G-2FR2 800G OSFP 2FR2 (回線あたり 200G) PAM4 1291/1311nm 2km DOM デュアル CS SMF 光トランシーバ モジュール
$3000.00
-
 OSFP-800G-DR4 800G OSFP DR4 (回線あたり 200G) PAM4 1311nm MPO-12 500m SMF DDM 光トランシーバー モジュール
$3000.00
OSFP-800G-DR4 800G OSFP DR4 (回線あたり 200G) PAM4 1311nm MPO-12 500m SMF DDM 光トランシーバー モジュール
$3000.00
-
 NVIDIA MMS4X00-NM-FLT 互換 800G ツインポート OSFP 2x400G フラットトップ PAM4 1310nm 500m DOM デュアル MTP/MPO-12 SMF 光トランシーバー モジュール
$1199.00
NVIDIA MMS4X00-NM-FLT 互換 800G ツインポート OSFP 2x400G フラットトップ PAM4 1310nm 500m DOM デュアル MTP/MPO-12 SMF 光トランシーバー モジュール
$1199.00
-
 NVIDIA MMA4Z00-NS-FLT 互換 800Gb/s ツインポート OSFP 2x400G SR8 PAM4 850nm 100m DOM デュアル MPO-12 MMF 光トランシーバー モジュール
$650.00
NVIDIA MMA4Z00-NS-FLT 互換 800Gb/s ツインポート OSFP 2x400G SR8 PAM4 850nm 100m DOM デュアル MPO-12 MMF 光トランシーバー モジュール
$650.00
-
 NVIDIA MMS4X00-NM 互換 800Gb/s ツインポート OSFP 2x400G PAM4 1310nm 500m DOM デュアル MTP/MPO-12 SMF 光トランシーバー モジュール
$900.00
NVIDIA MMS4X00-NM 互換 800Gb/s ツインポート OSFP 2x400G PAM4 1310nm 500m DOM デュアル MTP/MPO-12 SMF 光トランシーバー モジュール
$900.00
-
 NVIDIA MMA4Z00-NS 互換 800Gb/s ツインポート OSFP 2x400G SR8 PAM4 850nm 100m DOM デュアル MPO-12 MMF 光トランシーバー モジュール
$650.00
NVIDIA MMA4Z00-NS 互換 800Gb/s ツインポート OSFP 2x400G SR8 PAM4 850nm 100m DOM デュアル MPO-12 MMF 光トランシーバー モジュール
$650.00
-
 NVIDIA MMS1Z00-NS400 互換 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 FEC 光トランシーバー モジュール付き
$700.00
NVIDIA MMS1Z00-NS400 互換 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 FEC 光トランシーバー モジュール付き
$700.00
-
 NVIDIA MMS4X00-NS400 互換 400G OSFP DR4 フラットトップ PAM4 1310nm MTP/MPO-12 500m SMF FEC 光トランシーバー モジュール
$700.00
NVIDIA MMS4X00-NS400 互換 400G OSFP DR4 フラットトップ PAM4 1310nm MTP/MPO-12 500m SMF FEC 光トランシーバー モジュール
$700.00
-
 NVIDIA MMS4X50-NM 互換 OSFP 2x400G FR4 PAM4 1310nm 2km DOM デュアルデュプレックス LC SMF 光トランシーバー モジュール
$1200.00
NVIDIA MMS4X50-NM 互換 OSFP 2x400G FR4 PAM4 1310nm 2km DOM デュアルデュプレックス LC SMF 光トランシーバー モジュール
$1200.00
-
 OSFP-XD-1.6T-4FR2 1.6T OSFP-XD 4xFR2 PAM4 1291/1311nm 2km SN SMF 光トランシーバ モジュール
$15000.00
OSFP-XD-1.6T-4FR2 1.6T OSFP-XD 4xFR2 PAM4 1291/1311nm 2km SN SMF 光トランシーバ モジュール
$15000.00
-
 OSFP-XD-1.6T-2FR4 1.6T OSFP-XD 2xFR4 PAM4 2x CWDM4 2km デュアルデュプレックス LC SMF 光トランシーバーモジュール
$20000.00
OSFP-XD-1.6T-2FR4 1.6T OSFP-XD 2xFR4 PAM4 2x CWDM4 2km デュアルデュプレックス LC SMF 光トランシーバーモジュール
$20000.00
-
 OSFP-XD-1.6T-DR8 1.6T OSFP-XD DR8 PAM4 1311nm 2km MPO-16 SMF 光トランシーバー モジュール
$12000.00
OSFP-XD-1.6T-DR8 1.6T OSFP-XD DR8 PAM4 1311nm 2km MPO-16 SMF 光トランシーバー モジュール
$12000.00