
高性能コンピューティング (HPC) では、効率的で信頼性の高いデータ転送ほど重要なものはありません。 インフィニバンド この技術は、帯域幅が広く、待ち時間が短いことで知られており、GPU を使用する高速クラスターやシステムに最適です。このブログ記事では、Infiniband の構成要素、メリット、使用場所について説明します。Infiniband の機能と仕組みを理解することで、企業は HPC 環境の設定方法をより適切に選択できるようになり、中断のない高速データ処理が可能になります。
Infiniband とは何ですか?またその仕組みは何ですか?
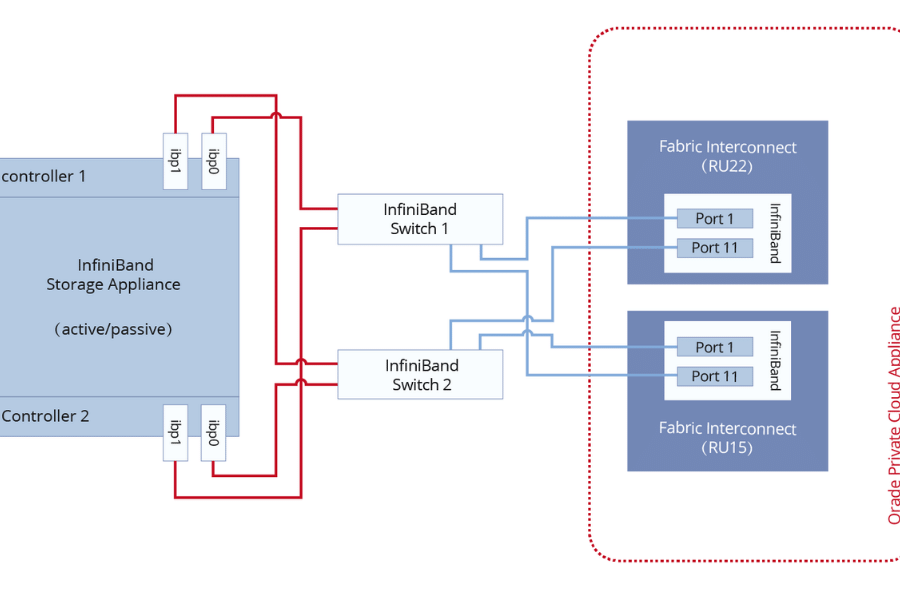
Infiniband テクノロジーを理解する
HPC 環境のニーズを満たすために、Infiniband は超高速ネットワーキング テクノロジです。スイッチド ファブリック トポロジで実行され、ノード間の通信のための効率的なパスの作成に役立ちます。 Infiniband のアーキテクチャは、データ パケットをルーティングするスイッチと、エンド デバイスに接続するホスト チャネル アダプタ (HCA) で構成されます。 Infiniband は、リモート ダイレクト メモリ アクセス (RDMA) を通じて、システム間のメモリの直接転送を可能にし、待ち時間を最小限に抑え、CPU の関与を軽減します。最大 200 Gbps のデータ転送速度に達し、遅延は 500 ナノ秒と低いため、高速な情報交換が必要な並列コンピューティングや機械学習ワークロードなどのアプリケーションに最適です。
Infiniband アーキテクチャと仕様
HPC 環境の高負荷データ伝送要件をサポートするために、Infiniband アーキテクチャは意図的に設計されています。その中心には、ホスト チャネル アダプタ (HCA) とスイッチという 2 つの主要コンポーネントがあります。 HCA は、エンドデバイス (サーバー、ストレージ システムなど) と InfiniBand ファブリック間のインターフェイスとして機能します。これらのアダプターには RDMA 機能があり、CPU を介さずにデバイス間で直接メモリーにアクセスできるため、遅延が大幅に削減されます。
一方、スイッチは、ネットワークを介してデータ パケットをルーティングし、ノード間の遅延を最小限に抑えた効率的な通信パスを確保します。InfiniBand では、1x レーンなどのさまざまなリンク速度と構成がサポートされており、これを集約して 4x レーンや 12x レーンなどのより高い帯域幅を実現できます。現在使用されている実装では、ポートあたり最大 200 Gbps の速度、つまり EDR (Enhanced Data Rate) または HDR (High Data Rate) がサポートされています。これにより、分子動力学シミュレーション、気象モデリング、大規模な機械学習など、多くのスループットを要求するアプリケーションに十分なスループットが提供されます。
さらに、予測可能なパフォーマンス レベルを維持しながら重要なデータ トラフィックを優先する QoS (サービス品質) メカニズムが InfiniBand に組み込まれました。さらに、スケーラビリティにより、数千のノード間のノンブロッキングな相互接続が可能になり、計算能力に合わせてネットワークも成長できるようになります。 InfiniBand が現代のスーパーコンピューターのバックボーン インフラストラクチャとして機能できるのは、この強力な設計原則のおかげです。
Infiniband の主な機能
- 非常に高速で非常に短い時間: Infiniband は、現在 HDR でポートあたり 200 Gbps という超高速データ転送速度と、一貫して低遅延の通信を提供します。そのため、リアルタイム分析や科学的シミュレーションなどの高速データ交換を必要とする HPC アプリケーションに最適です。
- RDMA(リモートダイレクトメモリアクセス): インフィニバンド RDMA 機能は、CPU の介入なしに、異なるデバイスのメモリ位置間で直接データ転送を可能にします。これによりレイテンシが大幅に短縮され、より多くの CPU リソースが他のタスクに割り当てられるため、システム全体のパフォーマンスが向上します。
- スケーラビリティ: Infiniband は優れたスケーラビリティを実現するように設計されており、数千のノードを大規模な HPC クラスターに接続できます。非ブロッキング アーキテクチャにより、ネットワークが拡大してもボトルネックにならないため、大規模な計算を実行したり、データ集約型アプリケーションを同時に実行したりできます。
- サービス品質 (QoS): QoS メカニズムは Infiniband に統合されており、ネットワーク トラフィックを制御し、優先順位を付けます。この機能は、他のストリームよりも優先する必要がある重要なストリームがある場合に不可欠となり、そのような環境で持続的なパフォーマンス レベルを確保できます。
- 柔軟なトポロジと構成: ファブリックはファット ツリー、メッシュ、トーラスなどのさまざまなトポロジをサポートしているため、ネットワークを特定のパフォーマンス要件やスケーラビリティのニーズに合わせることができます。さらに、異なるレーン構成 (1x、4x、12x) のサポートにより、必要な帯域幅を柔軟に実現できます。
- 信頼性と耐障害性: 高度なエラー検出/修正メカニズムが Infiniband で使用されているため、システム内で常に信頼性の高い通信が確実に行われるようにしながら、送信中にデータの整合性が維持されます。つまり、リンクレベルのフロー制御と適応型ルーティングの組み合わせが貢献します。高い信頼性を目指しているため、ミッションクリティカルなアプリケーションに適用できます。
Infiniband は Ethernet とどう違うのですか?

インフィニバンドとイーサネット: 低遅延をめぐる戦い
Infiniband を低遅延の点で Ethernet と比較すると、その構造と設計により、Infiniband の方が Ethernet よりも優れたパフォーマンスを発揮することが通常観察されます。 Infiniband の重要な機能の 1 つは、通信オーバーヘッドの低減であり、これにより遅延の減少につながります。さらに、リモート ダイレクト メモリ アクセス (RDMA) がこのテクノロジによってサポートされているため、CPU を介さずにメモリから直接コンピュータ間のデータ転送が可能になり、遅延が軽減され、処理能力が解放されます。
それどころか、イーサネットは、特にデータセンター ブリッジング (DCB) や RDMA over Converged Ethernet (RoCE) を備えた現在では、他のネットワークよりもカバー範囲が広く、安価であることが知られています。それでも、これらの改善が行われた後でも、イーサネットは常に Infiniband よりも一般に高い遅延を示します。
したがって、複雑なシミュレーションや高性能コンピューティング (HPC) など、超低レイテンシと高スループットの両方を必要とするアプリケーションでは、ほとんどの場合、InfiniBand が好まれます。
Infiniband による高帯域幅の提供: 速度とスループットの比較
Infiniband は、帯域幅とスループットの点で Ethernet を上回っています。実際、Infiniband HDR (High Data Rate) はポートあたり最大 200 Gbps の速度を提供し、これは Ethernet で最先端の 400 Gbps や一般的な 100 Gbps よりもはるかに高速です。さらに、Infiniband では多くのレーンを集約できるため、スループットに対するアプリケーションのニーズに応じたスケーラビリティにより、データ転送効率が高くなります。このテクノロジのアーキテクチャは、大量の低遅延処理を組み込んでゼロから設計されているため、HPC クラスターやハイパースケール データ センターで発生するような大量の情報を扱うユースケースに最適です。
信頼性と拡張性: イーサネットに対する Infiniband の利点
イーサネットと比較して、Infiniband は信頼性と拡張性が高く、大規模システムの機能をサポートするために必要です。長距離であっても、データの整合性を維持するのに十分な強力なエラー検出および訂正方法を備えているため、再送信率が低下し、均一なパフォーマンスが保証されます。さらに、レイテンシーの観点から予測可能性を保証する決定的な操作の性質を持っています。この機能は、緊密に調整されたプロセスを必要とするアプリケーションを扱う場合に重要になります。
同様に、InfiniBand の QoS (Quality of Service) 機能では、帯域幅を決定論的に割り当てることができるため、さまざまな要件を持つさまざまなワークロードにわたってパフォーマンスが維持されます。InfiniBand は、拡張性を確保するために、多数のノードを効果的にサポートできるため、パフォーマンスが著しく低下することなくコンピューティング リソースを増やすことができます。そのため、InfiniBand は、大量の情報を広範囲にわたって頻繁に転送および処理する必要があるスーパーコンピュータ クラスターやエンタープライズ レベルのデータ センターなどの環境に最適な選択肢となります。
Infiniband ネットワークの利点は何ですか?

低遅延と高パフォーマンス
InfiniBand ネットワークは非常に高速であるという評判があり、そのため低遅延で高性能なネットワークとして知られています。事情通によると、InfiniBand の遅延は 100 ns まで短縮できると報告されており、これは Ethernet よりもはるかに短いものです。この非常に短い時間により、パケットが迅速に到着することが保証されるため、遅延に敏感なアプリケーション プログラムのパフォーマンスが向上します。
さらに、InfiniBand は非常に高いスループットをサポートしており、今日のシステムでは接続ごとに最大 200 ギガビット/秒 (Gbps) が提供されます。この高い帯域幅は、HPC クラスター内またはデータ センター間で大量のデータ転送を処理する場合に必要です。レイテンシが高く、データ レートが低いことがある Ethernet と比較すると、InfiniBand は、要求の厳しいアプリケーションの中でも特に高性能コンピューティングに適した効率的で堅牢なソリューションです。
リモート ダイレクト メモリ アクセス (RDMA)
信頼できる情報源によると、リモート ダイレクト メモリ アクセス (RDMA) は、OS を使用せずに 2 台のコンピュータのメモリ間でデータを転送できる Infiniband ネットワークの主要機能です。これにより、データの直接パスが作成され、待ち時間が短縮され、CPU オーバーヘッドも低くなります。RDMA は、ゼロコピー ネットワーキングを有効にすることでパフォーマンスを向上させます。つまり、従来のネットワーク プロトコルのように、情報が最初にオペレーティング システム バッファーを通過するのではなく、アプリケーション バッファーからネットワークに直接移動します。
報告によると、この技術は 1 マイクロ秒という低レイテンシを実現し、1 秒あたり数百ギガビットのデータ転送をサポートできるとのことです。このような速度であれば、RDMA がリアルタイム処理能力と高スループットを必要とするアプリケーション、たとえば金融取引システムや大規模データ分析で使用される分散データベースで最も役立つ理由が明らかになります。RDMA はカーネル バイパスもサポートしており、アプリケーションがネットワーク ハードウェアと直接通信できるため、レイテンシがさらに短縮され、データ転送の効率が向上します。
要約すると、リモート ダイレクト メモリ アクセス (RDMA) は、高帯域幅、低レイテンシ、CPU の効率的な使用を実現するため、情報に迅速にアクセスしたりパフォーマンスを向上させる必要がある場合には不可欠なテクノロジであることが証明されています。
HDR Infinibandと今後の展望
ネットワーク技術の次のステップは、データセンターや高性能コンピューティング環境の需要を満たすように設計された HDR (High Data Rate) Infiniband に代表されます。このシステムでは、あるポイントから別のポイントに情報を転送する際に 200 Gbps を達成できるため、低遅延でより高いデータ レートの要件に対応できます。
HDR Infiniband は、以前のバージョンとは異なる多くの機能を備えています。その 1 つは、信号の完全性とエラー訂正機能を向上させる最新世代のスイッチ シリコン テクノロジーを使用していることです。これにより、長距離であってもデータ伝送の信頼性が向上し、大規模な分散システムに適しています。
HDR Infiniband のもう 1 つの重要な側面は、EDR (Extreme data Rate) およびその先のイネーブラーとしての将来の役割であり、したがって、超低遅延を必要とする複雑なシミュレーション、大規模な分析、およびリアルタイム アプリケーションを促進します。さらに、AI/ML ワークロードの進歩により、HDR Infiniband によって提供されるような、高帯域幅でありながら遅延が短いネットワークに対するニーズがますます高まることになります。
膨大な量の情報を迅速に処理することにより、これらのネットワークを導入することで、自律走行車や仮想現実など、さまざまな分野で科学研究の進歩を加速することができます。結論として、これは HDR InfiniBand が現在の高性能ネットワークのニーズに対するソリューションを提供するだけでなく、次世代の計算およびデータ集約型アプリケーションのサポートに向けた将来を見据えたアプローチも示していることを意味します。
Infiniband はデータセンターと HPC でどのように使用されますか?

高性能コンピューティング (HPC) における Infiniband
世界最速のスーパーコンピューターは、Infiniband を利用してノード間の高速データ転送を可能にしています。これは、特に大規模なシミュレーション、科学研究、分析に必要です。さらに重要なことは、共有ストレージやメモリ アクセスに関連する従来のボトルネックを取り除くネットワーク ブースト並列コンピュータ アーキテクチャを作成することで、HPC システム内のコンピューティング デバイスを相互に直接接続し、クラスタがこれらのアプリケーションをこれまでよりも高速に処理できるようになることです。これにより、各ノードが他のノードから独立して独自のリソースにアクセスできるようになります。
データセンターでの Infiniband の統合
現在のデータセンターでは、InfiniBand の統合により、データ集約型のタスクに不可欠な高速相互接続が提供され、パフォーマンスとスケーラビリティが向上します。特に、サーバー、ストレージ システム、およびその他のネットワーク デバイス間の高速通信を目的として導入され、データセンターの運用がより効率的になります。リモート ダイレクト メモリ アクセス (RDMA) などの高度な機能により、CPU オーバーヘッドが削減され、情報の転送速度が向上します。また、独自の拡張可能な設計により、段階的に容量を追加しながら、施設内で需要が以前よりも大きくなった場合でも、長期間にわたって継続的な生産性を確保できます。したがって、InfiniBand テクノロジを使用することで、データセンター内でより高いスループット レートとより低いレイテンシを実現でき、クラウド コンピューティングからビッグ データ分析や機械学習に至るまで、さまざまなアプリケーションのサポートに必要な効率が向上します。
GPU クラスターと AI 用の Infiniband
GPU クラスターと AI アプリケーションは、高帯域幅と低レイテンシの要件を適切に処理できるため、Infiniband に依存しています。AI モデルが複雑になり、GPU ワークロードが大きくなるにつれて、Infiniband インターコネクトにより GPU 間の高速データ共有が可能になり、トレーニングと推論の時間が短縮されます。このようなパフォーマンスの向上は、CPU 使用率を削減し、データ転送効率を向上させる RDMA サポートやハードウェア オフロードなどの機能によって可能になります。AI システムに InfiniBand を大規模に導入すると、ボトルネックが最小限に抑えられるため、GPU リソースを最適に活用でき、計算が高速化されるとともに人工知能モデルのスケーリング効率が向上すると同時に、このテクノロジーにより大量のデータをより高精度で迅速に処理できるようになります。これにより、より大きなデータセットをより高速かつ正確に処理できるようになります。このように、GPU クラスター内で Infiniband を使用すると、ディープラーニング アルゴリズムからさまざまな生活分野に適用できる予測分析に至るまで、AI 研究の機能が大幅に向上します。
Infiniband ネットワークのコンポーネントは何ですか?

Infiniband スイッチとアダプタ
InfiniBand スイッチとアダプターは、InfiniBand ネットワークの重要なコンポーネントです。 Infiniband スイッチとも呼ばれるファブリック スイッチは、ネットワーク経由でデータ パケットを転送する役割を果たします。これらのスイッチは複数のデバイスをリンクして、それらの間の高速通信とデータ転送を可能にします。これらには、8 ~ 648 ポートの範囲の異なるポート番号があります。これらは、ネットワーク インフラストラクチャを効果的に拡張するために必要な Fat-Tree や Clos などのさまざまなトポロジを相互接続します。
一方、ホスト チャネル アダプタ (HCA) は Infiniband アダプタとも呼ばれ、サーバーやストレージ システムなどのネットワーク デバイスにインストールされ、InfiniBand ファブリックへの接続を可能にします。HCA は Infiniband 経由の直接メモリ アクセス (RDMA) を容易にし、CPU オーバーヘッドを削減して情報の転送速度を向上させます。HCA は、アプリケーションを提供する最新のデータ センターで高スループットと低レイテンシの要件を満たすために必要な、QDR (Quad Data Rate) や FDR (Fourteen Data Rate) などの重要な機能をサポートします。
これら 2 種類のデバイスは、InfiniBand ネットワークの主要部分を構成します。それぞれの目的は異なりますが、幅広い高性能コンピューティング アプリケーションにわたって効率的で信頼性の高い通信を実現することを目指しています。
Infiniband ケーブルとコネクタ
InfiniBand ネットワークを構築するには、ケーブルとコネクタが必要です。これら 2 つのコンポーネントは、ネットワークのスイッチ、アダプター、その他のデバイスに接続されます。通常、これらのケーブルには銅線と光ファイバーの 2 つのタイプがあります。銅線ケーブルは光ファイバーよりも安価で設置が簡単であるため、短距離の場合に使用されます。 SDR (シングル データ レート)、DDR (ダブル データ レート)、および QDR (クアッド データ レート) は、銅ケーブルが処理できるサポートされる速度の一部です。長距離やより高いパフォーマンスが要求される場合は、より少ない信号損失でより多くの帯域幅を実現できる光ファイバー ケーブルの使用が推奨されます。
InfiniBandコネクタには、次のような標準化されたフォーマットがいくつかあります。 QSFP (Quad Small Form-factor Pluggable) は、高密度設計により QDR、FDR、EDR の高速データ転送速度をサポートできます。このコネクタは汎用性が高く、銅線ケーブルと光ファイバー ケーブルの両方で使用できるため、ネットワーク プランニングが柔軟かつスケーラブルになります。
結論として、インフィニバンド ケーブルとそのコネクタは、ネットワーク内で効率的な通信を行うためにさまざまな速度と距離の組み合わせが必要となる場合がある、強力で適応性のある高性能ネットワーキング インフラストラクチャをセットアップする際の重要な要素として機能します。
ポートとノードの構成
InfiniBand ネットワークでは、ポートとノードの構成は、パフォーマンスと信頼性を最適化する目的でネットワーク ポートとノードを設定および管理するプロセスです。この場合のポートは、デバイスがネットワークに接続するためのインターフェイスを指します。スイッチまたはアダプタには、複数の接続をサポートするために多数のポートがある場合があります。一方、ノードは、サーバーやストレージ デバイスなど、ネットワークに接続された個々のデバイスまたはシステムです。
ポートを構成するには、ポートにアドレスを付与するとともに、ネットワークの負荷が分散されるようにポートが適切に割り当てられていることを確認する必要があります。InfiniBand スイッチは、ポート マッピングとデータ パスの最適化に高度なアルゴリズムを使用します。これにより、動的な割り当てが可能になり、すべてのポイントでスループットが最大化されると同時に、システムの任意のセクション内での遅延が最小化されます。
一方、ノードを構成する場合は、ノード GUID (Globally Unique Identifier) やサブネット マネージャーのポリシーなどのいくつかのネットワーク パラメーターを指定する必要があります。サブネット マネージャーは、ファブリック トポロジ記述内のすべてのノードを検出し、相互接続とともに各ノードを構成します。パフォーマンス監視や障害管理などのタスクの中でもパス解決を実行し、潜在的な問題が発生した場合に即座に対処することでネットワークの効率的な運用を保証します。
InfiniBand ネットワークで低遅延を特徴とする高速通信を実現するには、ポートとノードの構成を効果的に行う必要があります。したがって、管理者はこれらのコンポーネントを慎重に計画し、管理して、シームレスなデータ転送が行えるようにする必要があります。これにより、高性能コンピューティング目的で使用される環境の堅牢なパフォーマンスが保証されます。
よくある質問(FAQ)
Q: Infiniband とは何ですか?また、他のネットワーク テクノロジーとどう違うのですか?
A: 主に高性能コンピューティング環境で使用されている InfiniBand は、低遅延の高速ネットワーク テクノロジです。従来のイーサネット ネットワークよりもはるかに高いデータ転送速度と低い遅延を備えているため、サーバー、ストレージ デバイス、GPU の相互接続に便利です。また、大量のデータを効率的に処理できるため、スーパーコンピューターでもこのテクノロジが使用されています。
Q: Infiniband 仕様は誰が管理していますか?
A: InfiniBand Trade Association (IBTA) は、InfiniBand 仕様の維持と開発を行っています。IBTA は、さまざまなベンダーの製品が連携して動作し、幅広いソリューションを作成できるようにします。
Q: データ転送に Infiniband を使用する主な利点は何ですか?
A: 従来のネットワーク技術と見なされているギガビット イーサネットやファイバー チャネルと比較すると、データ転送にインフィニバンドを使用すると、レイテンシの低減、スループットの向上、スケーラビリティの向上など、多くの利点が得られます。そのため、データセンターや HPC クラスターなど、情報の高速かつ信頼性の高い移動が必要なシナリオに適しています。
Q: Infiniband はイーサネット ネットワークと組み合わせて使用できますか?
A: はい。両者の統合を可能にする適切なゲートウェイまたはアダプタを使用することで、組織は既存のイーサネット インフラストラクチャとの互換性を維持しながら、インフィニバンドが提供するより高速な速度を享受できます。
Q: Infiniband はどのくらいのデータ転送速度をサポートできますか?
A: 400 Gbps (ギガビット/秒) の NDR (Next Data Rate) により、InfiniBand は、AI ワークロードや科学シミュレーションなど、非常に高いスループットを必要とする非常に要求の厳しいアプリケーションでも処理できます。
Q: Infiniband は、重要なアプリケーションに対してサービス品質 (QoS) を保証するためにどのような方法を採用していますか?
A: トラフィックに優先順位を付け、帯域幅を InfiniBand で割り当てて QoS をサポートできます。これにより、重要なプログラムが十分なネットワーク リソースを確保して、最高のパフォーマンスを発揮できるようになります。仮想レーンとサービス レベルは、一貫性と信頼性のあるデータ転送を保証する機能の 1 つです。
Q: InfiniBand ネットワーク アーキテクチャのコンポーネントにはどのようなものがありますか?
A: InfiniBand ネットワーク アーキテクチャ内のコンポーネントには、ホスト チャネル アダプタ (HCA)、ターゲット チャネル アダプタ (TCA)、InfiniBand スイッチ、ネットワーク アダプタなどがあり、これらが組み合わさってスイッチ ファブリックを形成し、サーバーとストレージ デバイスを相互接続して、それらの間の高速通信を可能にします。
Q: Infiniband はどのようにして他のネットワーク テクノロジーと比較して低遅延を実現するのですか?
A: 従来のイーサネット ネットワークとは異なり、このテクノロジーは最適化されたプロトコル スタックと効率的なハードウェア設計を利用することで、低レイテンシを実現します。これを実現するために、CPU から処理タスクをオフロードする HCA を使用し、ネットワーク経由でデータを移動するのに要する時間を短縮します。その結果、レイテンシが大幅に短縮されます。
Q: Infiniband 製品とソリューションを提供している企業は何ですか?
A: こうした種類のアイテムの主なサプライヤーは、NVIDIA (旧 Mellanox)、Intel、および高性能コンピューティングとデータセンター技術を専門とするその他の企業です。これらの企業は、高速クラスター/相互接続の構築に必要なその他のコンポーネントの中でも、アダプターやスイッチなどのさまざまなモデルを通じて、さまざまな速度のクラスターを提供しています。
Q: Infiniband は、ハイ パフォーマンス コンピューティングで GPU を接続するとうまく機能しますか?
A: はい、低レイテンシと高データ転送速度の組み合わせにより、これら 2 つのデバイス間の接続が最適化され、そのような機能を必要とするディープラーニングや科学的シミュレーションなどの計算タスクを実行するときに通信が効率的になるため、効率的に機能します。
関連製品:
-
 NVIDIA MMS4X00-NM 互換 800Gb/s ツインポート OSFP 2x400G PAM4 1310nm 500m DOM デュアル MTP/MPO-12 SMF 光トランシーバー モジュール
$900.00
NVIDIA MMS4X00-NM 互換 800Gb/s ツインポート OSFP 2x400G PAM4 1310nm 500m DOM デュアル MTP/MPO-12 SMF 光トランシーバー モジュール
$900.00
-
 10m(33ft)12ファイバーメス-メスMPOトランクケーブル極性B LSZH OS2 / 9シングルモード
$32.00
10m(33ft)12ファイバーメス-メスMPOトランクケーブル極性B LSZH OS2 / 9シングルモード
$32.00
-
 NVIDIA MMA4Z00-NS 互換 800Gb/s ツインポート OSFP 2x400G SR8 PAM4 850nm 100m DOM デュアル MPO-12 MMF 光トランシーバー モジュール
$650.00
NVIDIA MMA4Z00-NS 互換 800Gb/s ツインポート OSFP 2x400G SR8 PAM4 850nm 100m DOM デュアル MPO-12 MMF 光トランシーバー モジュール
$650.00
-
 NVIDIA MFP7E10-N015 互換 15 メートル (49 フィート) 8 ファイバー 低挿入損失 メス - メス MPO トランク ケーブル 極性 B APC - APC LSZH マルチモード OM3 50/125
$54.00
NVIDIA MFP7E10-N015 互換 15 メートル (49 フィート) 8 ファイバー 低挿入損失 メス - メス MPO トランク ケーブル 極性 B APC - APC LSZH マルチモード OM3 50/125
$54.00
-
 NVIDIA MCP4Y10-N00A 互換 0.5m (1.6 フィート) 800G ツインポート 2x400G OSFP から 2x400G OSFP InfiniBand NDR パッシブ ダイレクト アタッチ銅線ケーブル
$105.00
NVIDIA MCP4Y10-N00A 互換 0.5m (1.6 フィート) 800G ツインポート 2x400G OSFP から 2x400G OSFP InfiniBand NDR パッシブ ダイレクト アタッチ銅線ケーブル
$105.00
-
 NVIDIA MFA7U10-H015 互換性のある 15 メートル (49 フィート) 400G OSFP から 2x200G QSFP56 ツイン ポート HDR ブレークアウト アクティブ光ケーブル
$785.00
NVIDIA MFA7U10-H015 互換性のある 15 メートル (49 フィート) 400G OSFP から 2x200G QSFP56 ツイン ポート HDR ブレークアウト アクティブ光ケーブル
$785.00
-
 NVIDIA MCP7Y60-H001 互換 1m (3 フィート) 400G OSFP から 2x200G QSFP56 パッシブ ダイレクト アタッチ ケーブル
$99.00
NVIDIA MCP7Y60-H001 互換 1m (3 フィート) 400G OSFP から 2x200G QSFP56 パッシブ ダイレクト アタッチ ケーブル
$99.00
-
 NVIDIA MMS4X00-NM-FLT 互換 800G ツインポート OSFP 2x400G フラットトップ PAM4 1310nm 500m DOM デュアル MTP/MPO-12 SMF 光トランシーバー モジュール
$900.00
NVIDIA MMS4X00-NM-FLT 互換 800G ツインポート OSFP 2x400G フラットトップ PAM4 1310nm 500m DOM デュアル MTP/MPO-12 SMF 光トランシーバー モジュール
$900.00
-
 NVIDIA MMA4Z00-NS-FLT 互換 800Gb/s ツインポート OSFP 2x400G SR8 PAM4 850nm 100m DOM デュアル MPO-12 MMF 光トランシーバー モジュール
$650.00
NVIDIA MMA4Z00-NS-FLT 互換 800Gb/s ツインポート OSFP 2x400G SR8 PAM4 850nm 100m DOM デュアル MPO-12 MMF 光トランシーバー モジュール
$650.00
-
 NVIDIA MCP4Y10-N00A-FTF 互換 0.5m (1.6ft) 800G ツインポート 2x400G OSFP から 2x400G OSFP InfiniBand NDR パッシブ DAC、片側はフラットトップ、もう片側はフィントップ
$105.00
NVIDIA MCP4Y10-N00A-FTF 互換 0.5m (1.6ft) 800G ツインポート 2x400G OSFP から 2x400G OSFP InfiniBand NDR パッシブ DAC、片側はフラットトップ、もう片側はフィントップ
$105.00
-
 NVIDIA MCA4J80-N003-FTF 互換 3m (10 フィート) 800G ツインポート 2x400G OSFP から 2x400G OSFP InfiniBand NDR アクティブ銅線ケーブル、一方の端はフラット トップ、もう一方の端はフィン付きトップ
$600.00
NVIDIA MCA4J80-N003-FTF 互換 3m (10 フィート) 800G ツインポート 2x400G OSFP から 2x400G OSFP InfiniBand NDR アクティブ銅線ケーブル、一方の端はフラット トップ、もう一方の端はフィン付きトップ
$600.00
-
 NVIDIA MMA4Z00-NS400 互換 400G OSFP SR4 フラットトップ PAM4 850nm OM30 で 3m/OM50 で 4m MTP/MPO-12 マルチモード FEC 光トランシーバ モジュール
$550.00
NVIDIA MMA4Z00-NS400 互換 400G OSFP SR4 フラットトップ PAM4 850nm OM30 で 3m/OM50 で 4m MTP/MPO-12 マルチモード FEC 光トランシーバ モジュール
$550.00
-
 NVIDIA Mellanox MCX75510AAS-NEAT ConnectX-7 InfiniBand/VPI アダプター カード、NDR/400G、シングル ポート OSFP、PCIe 5.0x 16、トール ブラケット
$1650.00
NVIDIA Mellanox MCX75510AAS-NEAT ConnectX-7 InfiniBand/VPI アダプター カード、NDR/400G、シングル ポート OSFP、PCIe 5.0x 16、トール ブラケット
$1650.00
-
 NVIDIA Mellanox MCX653105A-HDAT-SP ConnectX-6 InfiniBand/VPI アダプター カード、HDR/200GbE、シングルポート QSFP56、PCIe3.0/4.0 x16、トール ブラケット
$1400.00
NVIDIA Mellanox MCX653105A-HDAT-SP ConnectX-6 InfiniBand/VPI アダプター カード、HDR/200GbE、シングルポート QSFP56、PCIe3.0/4.0 x16、トール ブラケット
$1400.00
-
 NVIDIA MCP7Y50-N001-FLT 互換 1m (3 フィート) 800G InfiniBand NDR ツインポート OSFP ~ 4x200G フラットトップ OSFP ブレイクアウト DAC
$255.00
NVIDIA MCP7Y50-N001-FLT 互換 1m (3 フィート) 800G InfiniBand NDR ツインポート OSFP ~ 4x200G フラットトップ OSFP ブレイクアウト DAC
$255.00
-
 NVIDIA MCA7J70-N004 互換 4m (13 フィート) 800G InfiniBand NDR ツインポート OSFP ~ 4x200G OSFP ブレークアウト ACC
$1100.00
NVIDIA MCA7J70-N004 互換 4m (13 フィート) 800G InfiniBand NDR ツインポート OSFP ~ 4x200G OSFP ブレークアウト ACC
$1100.00
-
 NVIDIA MCA7J60-N004 互換 4 メートル (13 フィート) 800G ツインポート OSFP から 2x400G OSFP InfiniBand NDR ブレークアウト アクティブ銅線ケーブル
$800.00
NVIDIA MCA7J60-N004 互換 4 メートル (13 フィート) 800G ツインポート OSFP から 2x400G OSFP InfiniBand NDR ブレークアウト アクティブ銅線ケーブル
$800.00
-
 NVIDIA MCP7Y00-N001-FLT 互換 1m (3 フィート) 800G ツインポート OSFP ~ 2x400G フラットトップ OSFP InfiniBand NDR ブレイクアウト DAC
$160.00
NVIDIA MCP7Y00-N001-FLT 互換 1m (3 フィート) 800G ツインポート OSFP ~ 2x400G フラットトップ OSFP InfiniBand NDR ブレイクアウト DAC
$160.00