
Huawei a récemment marqué le secteur grâce à son accélérateur d'IA innovant et à son architecture rack. CloudMatrix M8, la dernière solution de supercalcul cloud développée en Chine, a été officiellement dévoilée. Basée sur le processeur Ascend 910C, cette solution se positionne comme un concurrent direct du système GB200 NVL72 de Nvidia, affichant des avantages technologiques supérieurs à ceux des solutions rack de Nvidia sur plusieurs points clés. Les avancées techniques ne se limitent pas à la puce ; elles s'étendent à l'architecture de l'accélérateur, à la topologie du réseau, à la technologie d'interconnexion optique et à la pile logicielle, entre autres dimensions système.

Le NPU Ascend 910C est doté d'un boîtier double puce, interconnecté via un bus haut débit. Chaque puce de NPU intègre 7 x 224 Gbit/s dans le plan de bus unifié (UB) et fournit une bande passante unidirectionnelle de 200 Gbit/s dans le plan RDMA. Cette architecture permet un calcul haute performance pour les charges de travail d'IA, garantissant un traitement efficace des données et une interconnectivité optimale au sein de la plateforme CloudMatrix 910C.
Pour SemiAnalysis, les puces Ascend de Huawei sont loin d'être inconnues. À une époque où l'importance du système global dépasse la seule conception de la microarchitecture, Huawei repousse sans cesse les limites de performance des systèmes d'intelligence artificielle. Malgré certains compromis techniques, dans le contexte des contrôles à l'exportation et des capacités de production nationales limitées, le cadre actuel de contrôle des exportations de la Chine semble encore comporter des failles exploitables.
Si la technologie des puces de Huawei accuse un retard d'une génération sur celle de ses concurrents, sa solution d'extension est sans doute en avance d'une génération sur les offres actuelles de Nvidia et d'AMD. La CloudMatrix 384 (CM384), par exemple, est composée de 384 puces Ascend 910C interconnectées via une topologie entièrement connectée. La philosophie de conception est claire : en intégrant un nombre cinq fois supérieur de puces Ascend, la solution compense efficacement le fait que les performances d'un seul GPU ne représentent qu'un tiers de celles de la série Blackwell de Nvidia.
Le super-nœud CloudMatrix 384 utilise une topologie réseau sophistiquée avec trois plans complémentaires : le plan UB pour les interconnexions non bloquantes entre 384 NPU et 192 CPU ; le plan RDMA pour les communications scale-out utilisant RoCE avec un débit allant jusqu'à 400 Gbit/s par NPU ; et le plan VPC pour une connectivité plus étendue aux centres de données. Cette conception prend en charge les clusters de calcul à très grande échelle, permettant une collaboration efficace pour les applications pilotées par l'IA.
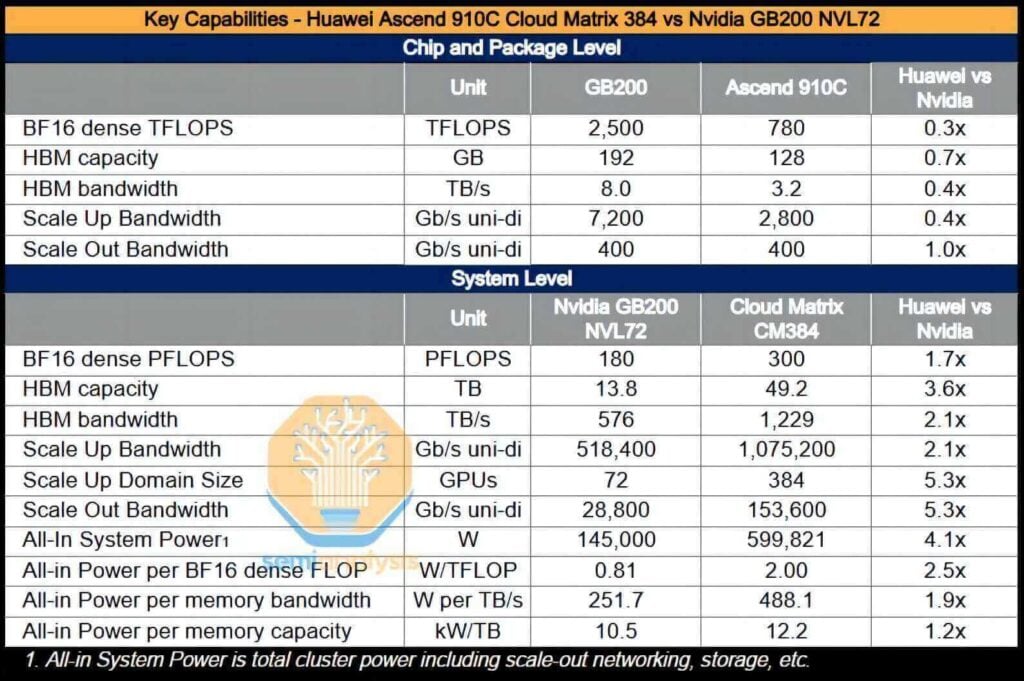
Le système CloudMatrix complet est capable de fournir des performances de calcul intensives de 16 pétaflops, soit près du double de celles du GB300 NVL200. Avec une capacité mémoire totale multipliée par plus de 72 et une bande passante mémoire multipliée par 3.6, Huawei – et par extension la Chine – est désormais en mesure de déployer des systèmes d'IA supérieurs à ceux de Nvidia.
De plus, le CM384 est particulièrement adapté aux domaines où la Chine possède des atouts majeurs, tels que ses capacités de production de réseaux nationaux, ses logiciels d'infrastructure conçus pour atténuer les pannes de réseau et son potentiel d'évolutivité vers des applications plus vastes grâce à l'amélioration du rendement de fabrication. Cependant, cette solution présente des inconvénients : sa consommation énergétique est 3.9 fois supérieure à celle du GB200 NVL72, avec un rendement par flop divisé par 2.3, une efficacité de la bande passante mémoire (par To/s) divisée par 1.8 et une efficacité de la mémoire à haut débit (HBM) par To divisée par 1.1.
Le super-nœud CloudMatrix 384 utilise 6,912 400 modules optiques 5,376 G pour construire un réseau d'interconnexion optique à large bande passante et faible latence. Le plan UB nécessite 384 7 modules pour connecter 1,536 NPU, chaque NPU utilisant 384 modules de manière bidirectionnelle. Le plan RDMA utilise 768 384 modules, dont XNUMX pour les cartes réseau des serveurs, XNUMX pour les commutateurs de couche feuille et XNUMX pour les commutateurs de couche spine, dans une architecture Fat Tree à deux couches. Cette allocation précise garantit une communication non bloquante et une évolutivité optimale pour les charges de travail d'IA et de calcul scientifique à grande échelle.
Malgré ces lacunes en matière d'efficacité énergétique, la question de la consommation d'énergie ne constitue pas une contrainte majeure dans le contexte chinois. Alors que l'Occident affirme souvent que le développement de l'intelligence artificielle est limité par l'approvisionnement en électricité, la situation en Chine est tout autre. Au cours de la dernière décennie, alors que les pays occidentaux ont déployé des efforts considérables pour faire évoluer leurs infrastructures électriques dépendantes du charbon vers des sources d'énergie renouvelables et du gaz naturel plus respectueuses de l'environnement, et pour améliorer l'efficacité énergétique par habitant, la Chine est confrontée à une demande croissante d'électricité en raison d'un niveau de vie élevé et d'investissements massifs.
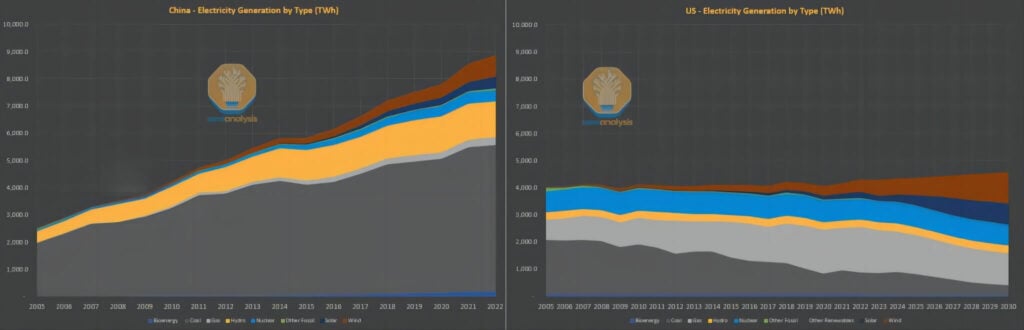
Bien que le système énergétique chinois ait traditionnellement largement reposé sur le charbon, le pays est aujourd'hui le premier pays au monde en termes de capacités installées d'énergie solaire, hydraulique et éolienne, et il est actuellement à l'avant-garde du déploiement de l'énergie nucléaire. En revanche, la capacité nucléaire des États-Unis reste à des niveaux qui rappellent ceux des années 1970. En résumé, les capacités de modernisation et d'expansion du réseau électrique américain ont considérablement diminué, tandis que la capacité supplémentaire introduite en Chine depuis 2011 est comparable à l'échelle du réseau américain dans son ensemble.
Dans un contexte où l'électricité est relativement abondante et où les contraintes de consommation énergétique sont moins critiques, il devient logique, d'un point de vue technique, de renoncer aux exigences strictes de densité de puissance au profit d'une évolutivité plus large, notamment en intégrant des avancées telles que la technologie d'interconnexion optique à la conception. En effet, la conception du CM384 prend même en compte les contraintes système qui s'étendent au-delà du rack. Nous pensons que les limites des ambitions chinoises en matière d'IA ne sont pas uniquement déterminées par des problèmes d'alimentation électrique ; la solution de Huawei continue d'offrir diverses perspectives d'expansion durable et évolutive.
Une idée fausse répandue est que la puce Huawei 910C est entièrement fabriquée en Chine. Bien que le processus de conception soit entièrement réalisé en Chine, la production réelle reste fortement dépendante des intrants étrangers. Qu'il s'agisse de la mémoire à haut débit (HBM) de Samsung ou d'équipements provenant des États-Unis, des Pays-Bas ou du Japon, le processus de production dépend encore fortement de la chaîne d'approvisionnement mondiale.
Huawei»s Chemin d'approvisionnement HBM
La dépendance de la Chine à l'égard des sources externes dans les domaines technologiques de pointe n'est qu'une partie du défi ; sa dépendance à la mémoire à large bande passante (MBP) est encore plus marquée. À l'heure actuelle, la Chine n'a pas encore atteint une production nationale de masse stable de MBP ; Changxin Storage (CXMT) devrait avoir besoin d'au moins un an de plus pour atteindre cette envergure. Heureusement, Samsung s'est imposé comme le principal fournisseur de MBP pour la Chine, et Huawei a ainsi constitué un stock préventif de 13 millions de piles MBP, une quantité suffisante pour emballer 1.6 million de puces Ascend 910C. Il convient de noter que cette accumulation a eu lieu avant l'entrée en vigueur de l'interdiction d'exportation de MBP.
Il convient également de noter que des composants HBM interdits continuent de revenir en Chine par des canaux parallèles. Les restrictions actuelles à l'exportation de HBM ne s'appliquent qu'aux unités de conditionnement HBM d'origine ; les puces intégrant du HBM peuvent toujours être transportées légalement, à condition de ne pas dépasser les limites d'opérations en virgule flottante (FLOPS) stipulées. À cet égard, CoAsia Electronics, distributeur exclusif de Samsung en Grande Chine, a régulièrement fourni du HBM2E à Faraday, société de conception ASIC. Faraday utilise ensuite la technologie SPIL (Siliconware Precision) pour conditionner ces composants mémoire avec des puces logiques 16 nm économiques.
Faraday expédie ensuite le produit fini en Chine dans un boîtier système. Bien que cette pratique soit conforme aux réglementations techniques, la conception intègre des billes de soudure à très faible intensité et basse température, qui permettent au HBM de se détacher facilement du boîtier. En substance, ce que l'on appelle « boîtier » équivaut dans ce cas à un assemblage peu intégré et presque formalisé.
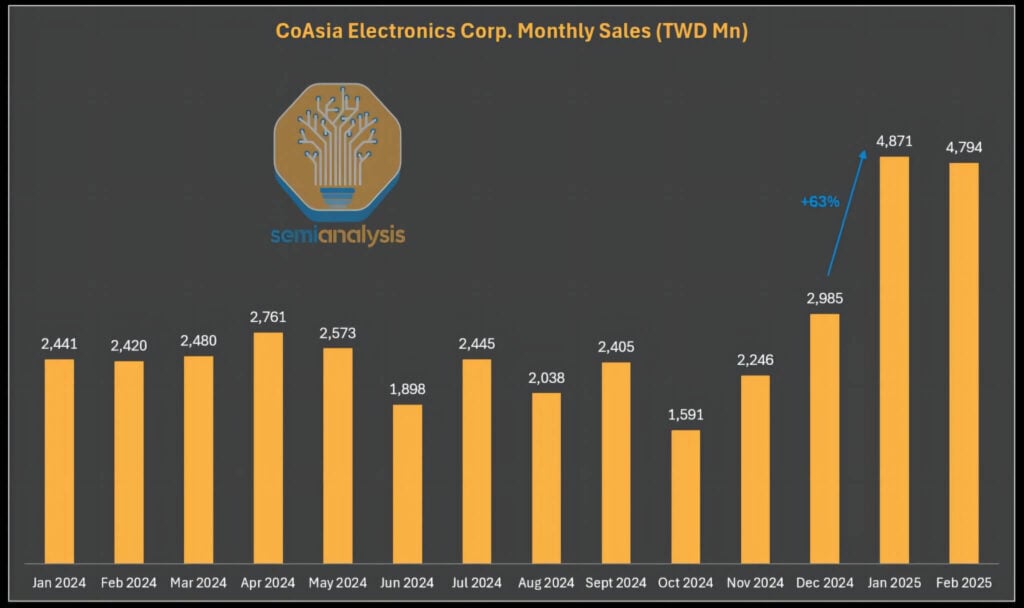
Depuis l'entrée en vigueur des contrôles à l'exportation en 2025, les revenus de CoAsia Electronics ont fortement augmenté, une évolution qui semble tout sauf fortuite.
Les fonderies chinoises conservent leur potentiel de croissance
Bien que l'industrie chinoise des semi-conducteurs dépende encore de la production étrangère, les capacités de sa chaîne d'approvisionnement nationale se sont rapidement améliorées et ont longtemps été sous-estimées. Nous continuons de surveiller de près les performances industrielles de SMIC (Semiconductor Manufacturing International Corporation) et de CXMT (ChangXin Memory Technologies). Malgré les défis persistants liés au rendement et à la capacité, la trajectoire à long terme vers une production évolutive de GPU chinois reste remarquable.
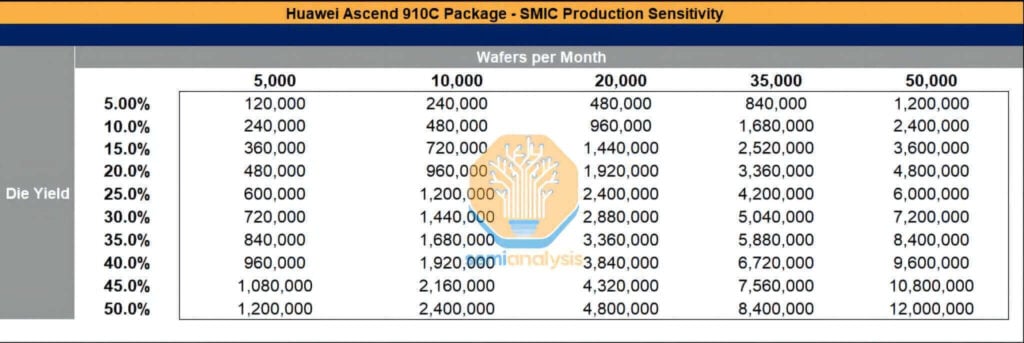
Malgré la pression des sanctions, SMIC et CXMT ont acquis des équipements de fabrication d'une valeur de plusieurs dizaines de milliards de dollars, tout en continuant d'importer des quantités importantes de produits chimiques et de matériaux d'origine étrangère. SMIC, par exemple, développe ses capacités de traitement avancé à Shanghai, Shenzhen et Pékin. Sa production mensuelle de plaquettes devrait approcher les 50,000 910 unités cette année, et cette expansion soutenue est également stimulée par l'acquisition continue d'équipements étrangers, conjuguée à une application peu rigoureuse des sanctions. Si les taux de rendement s'améliorent, le volume de conditionnement des puces Ascend XNUMXC pourrait atteindre des niveaux considérables.
Bien que TSMC ait déjà alloué 2.9 millions de plaquettes à la production en 2024-2025, ce qui représente une capacité suffisante pour produire environ 800,000 910 puces Ascend 1.05B et 910 million de puces Ascend XNUMXC, le potentiel de SMIC de connaître une croissance explosive de sa capacité demeure si la mémoire à large bande passante (HBM), l'équipement de fabrication de plaquettes, les ressources de maintenance de l'équipement et les produits chimiques essentiels (tels que la résine photosensible) ne sont pas efficacement réglementés.
Architecture du système CloudMatrix 384
L'analyse suivante examine la conception architecturale du système CloudMatrix 384, en examinant ses réseaux d'extension verticaux et horizontaux, la budgétisation de la consommation d'énergie et la structure globale des coûts.
Le système CloudMatrix complet est réparti sur 16 racks. Douze d'entre eux accueillent chacun 12 GPU, tandis que quatre racks supplémentaires, situés au centre, servent de racks de commutation d'extension verticale. Pour réaliser un cluster hyperscale, Huawei utilise une approche d'extension verticale inter-racks intégrant la technologie de communication optique. Cette stratégie permet une interconnexion complète entre des centaines de GPU, mais présente des défis techniques considérables.

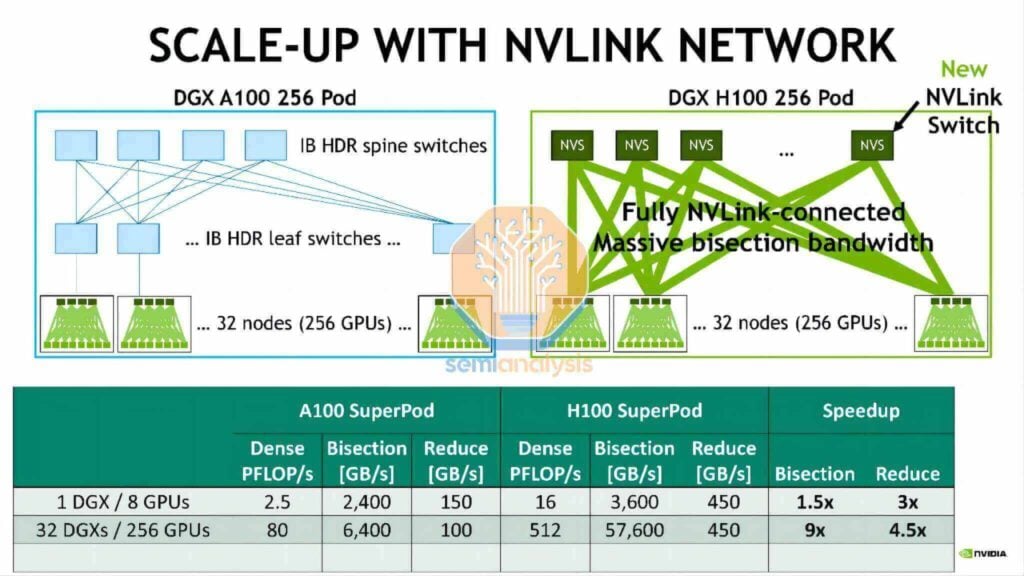
Similitude avec le DGX H100 NVL256 « Ranger »
Dès 2022, Nvidia a présenté la plateforme DGX H100 NVL256 « Ranger ». Cependant, le système n'a jamais atteint la production de masse. Cela s'expliquait par son coût prohibitif, sa consommation énergétique excessive et ses problèmes de fiabilité inhérents, liés à la surabondance des besoins en émetteurs-récepteurs optiques et à une architecture réseau double couche. En revanche, le Huawei CloudMatrix Pod adopte une approche plus radicale : sa conception réseau nécessite 6,912 400 modules optiques linéaires enfichables (LPO) XNUMX G, dont la grande majorité facilite l'interconnectivité réseau à expansion verticale.
Évaluation de la topologie d'extension verticale CloudMatrix 384
Cette section propose une évaluation approfondie de l'architecture rack d'extension verticale de Huawei sur 384 puces, une conception qui rivalise avec NVLink. L'analyse couvre les réseaux d'extension verticale et horizontale, une analyse détaillée de la consommation électrique du système et une évaluation de l'impact de l'application à grande échelle de modules optiques (et de l'absence de câbles en cuivre qui en découle) sur les performances et les coûts globaux. L'analyse aborde également les implications financières du déploiement massif de modules LPO par Huawei.
Paramètres de base
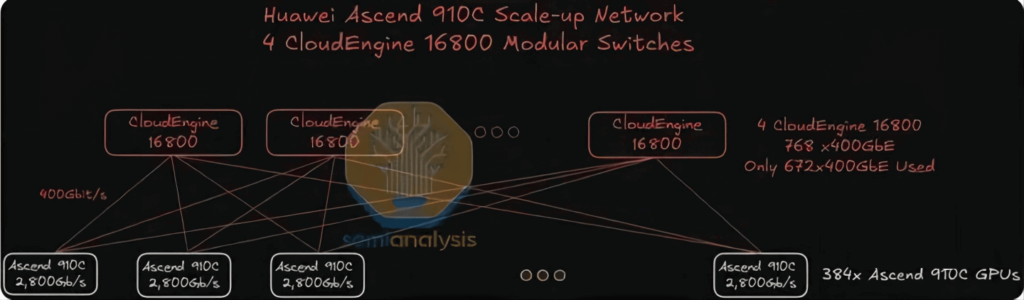
Chaque GPU Huawei Ascend 910C offre une bande passante d'extension verticale unidirectionnelle de 2,800 7,200 Gbit/s, un chiffre comparable à celui de 200 72 Gbit/s fourni par le NVL72 GBXNUMX de Nvidia. Alors que le NVLXNUMX de Nvidia assure son interconnexion réseau verticale via un câblage en cuivre direct haute densité, Huawei adopte une approche plus simple : le déploiement de sept Émetteurs-récepteurs optiques 400G par GPU dans une configuration empilée pour atteindre le chiffre de 2,800 XNUMX Gbit/s.
Cette stratégie s'accompagne toutefois d'un coût plus élevé, d'une consommation énergétique considérablement accrue et de défis liés à la gestion du flux d'air et à la facilité d'installation et de maintenance. Malgré ces obstacles, cette approche répond parfaitement aux objectifs fonctionnels du système. Le réseau d'extension verticale utilise une architecture monocouche pour interconnecter tous les GPU via 16,800 3 commutateurs modulaires disposés selon une topologie plate à un seul niveau. Ces commutateurs utilisent les cartes de ligne et les plans de matrice de commutation propriétaires de Huawei, avec un mécanisme de pulvérisation cellulaire similaire à celui des cartes de ligne Jericho3 de Broadcom associées aux cartes de matrice de commutation RamonXNUMX des commutateurs modulaires Arista.
Extension d'interconnexion optique verticale et conception sans cuivre
Le déploiement de 5,000 XNUMX modules optiques pour une expansion verticale peut entraîner des problèmes de fiabilité. Pour atténuer ce problème, un logiciel de formation de haute qualité et tolérant aux pannes est nécessaire pour gérer les défaillances potentielles pouvant survenir lors d'un déploiement de modules optiques à si grande échelle.
Chaque CloudMatrix 384 Pod est équipé de 6,912 400 modules/émetteurs-récepteurs optiques 5,376G. Parmi ceux-ci, 1,536 XNUMX sont destinés au réseau d'extension vertical, tandis que les XNUMX XNUMX restants servent au réseau d'extension horizontal.
Un seul Pod contient 384 puces Ascend 910C, chacune offrant une bande passante d'interconnexion de 2.8 Tbit/s pour les communications d'extension verticale. Par conséquent, chaque puce nécessite sept émetteurs-récepteurs 400G, soit 384 GPU × 7 = 2,688 2,688 émetteurs-récepteurs par Pod. Compte tenu de la topologie plate monocouche, le commutateur doit reproduire ce déploiement avec 5,376 400 émetteurs-récepteurs, ce qui représente une utilisation totale de XNUMX XNUMX émetteurs-récepteurs XNUMXG dans le réseau d'extension verticale.
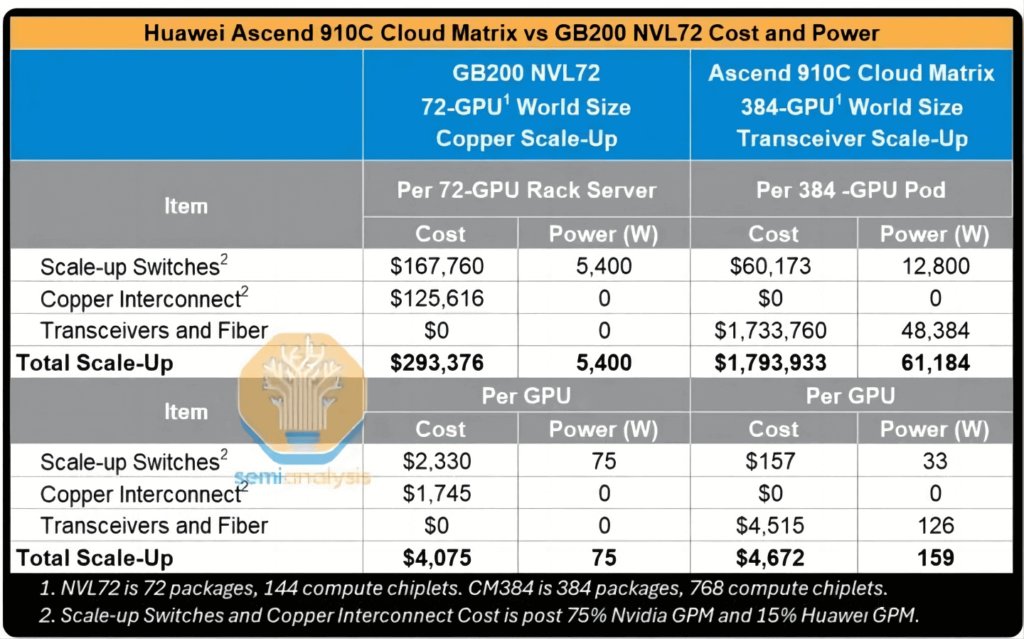
Si l'on utilise des émetteurs-récepteurs optiques linéaires enfichables (LPO) 400G, vendus moins de 200 $ chacun et consommant environ 6.5 W par module, le coût total de possession (TCO) du réseau d'extension verticale du supernœud serait environ six fois supérieur à celui d'un rack NVL72, avec une consommation électrique dix fois supérieure à celle du NVL72. Même par GPU, bien que la consommation électrique soit deux fois supérieure à celle du NVL72 et que le coût reste relativement comparable, les performances de calcul n'atteignent que 30 % de celles du NVL72.
Évaluation de la topologie d'extension horizontale CloudMatrix 384
Le CloudMatrix 384 adopte une topologie optimisée double couche à 8 voies. Chaque commutateur modulaire CloudEngine pour extension horizontale est équipé de 768 ports 400G : 384 d'entre eux sont connectés en aval à 384 GPU, tandis que les 384 autres sont réservés à l'interconnexion en amont. Chaque pod contenant 384 GPU (chacun équipé d'une carte d'interface réseau 400G), un commutateur leaf supplémentaire est nécessaire pour accéder au-delà des 0.5 commutateurs spine.
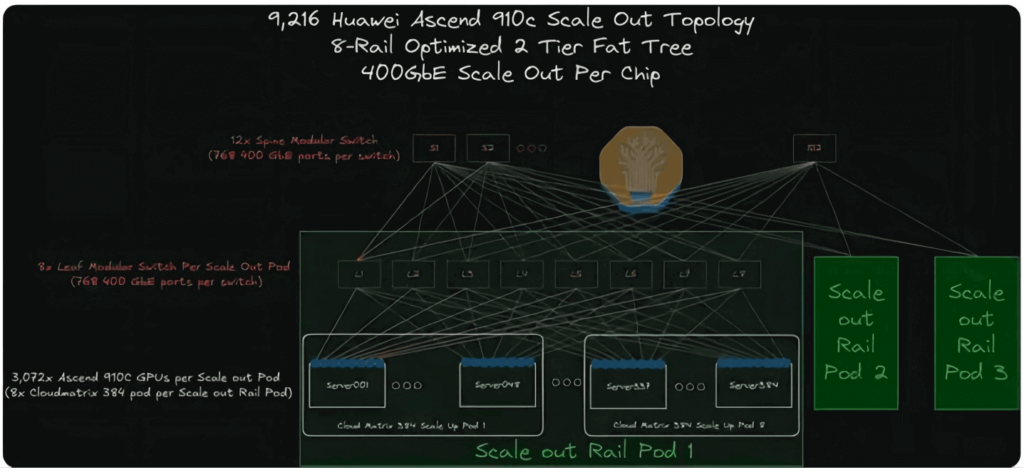
Le calcul des émetteurs-récepteurs pour ce réseau est simple :
- Côté GPU : 384 émetteurs-récepteurs 400G sont nécessaires (un par GPU) ;
- Couche feuille : Étant donné que la moitié des ports sont utilisés pour la connexion ascendante (reliant les GPU à la couche dorsale), le nombre d'émetteurs-récepteurs requis doit être doublé ;
- Total : Le réseau d'extension horizontale nécessite donc 384 × 4 = 1,536 400 émetteurs-récepteurs XNUMXG.
Émetteurs-récepteurs LPO
Une mesure potentielle proposée par Huawei pour réduire la consommation énergétique globale du cluster est l'adoption de modules optiques linéaires enfichables (LPO) pour la transmission optique. Ces modules sont conçus pour transmettre des données directement via des signaux optiques, sans nécessiter de processeur de signal numérique (DSP) interne. Contrairement aux émetteurs-récepteurs classiques, qui convertissent les signaux analogiques en signaux numériques pour l'étalonnage/la récupération de la synchronisation avant de les reconvertir en analogique, les modules LPO assurent une transmission linéaire directe des signaux électriques de l'hôte au dispositif optique. Cette conception simplifie l'architecture interne du module, permettant une réduction de plus de 30 % de la consommation énergétique et des coûts. Cependant, le nombre important d'émetteurs-récepteurs étant toujours nécessaire, la consommation énergétique globale du cluster CM384 reste nettement supérieure à celle du NVL72.
Niveau de puce
Les accélérateurs Ascend 910B et 910C de Huawei représentent le summum des GPU fabriqués en Chine. Malgré certaines contraintes technologiques, leurs performances restent exceptionnelles. Cependant, au niveau de la puce, leurs performances n'atteignent pas encore celles des produits NVIDIA comparables.
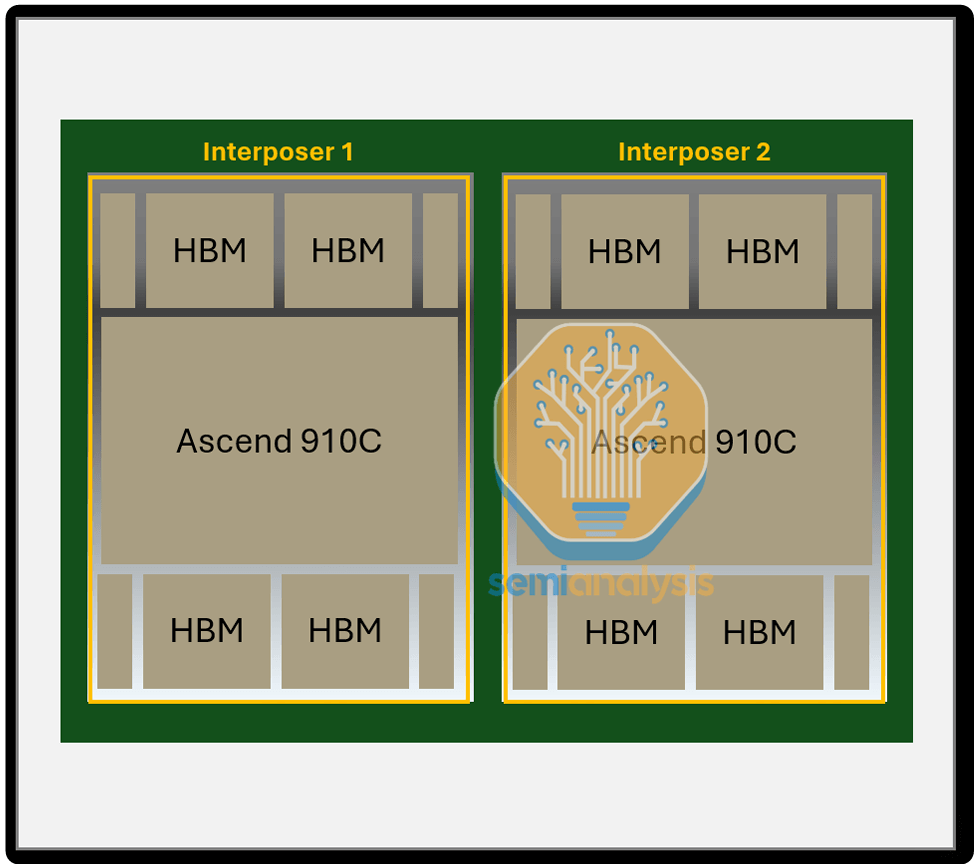
L'Ascend 910C est une itération du 910B, intégrant les couches intercalaires de deux puces 910B sur un seul substrat. Cette intégration double efficacement les performances de calcul monopuce ainsi que la bande passante mémoire.
Estimation de la consommation d'énergie au niveau du système
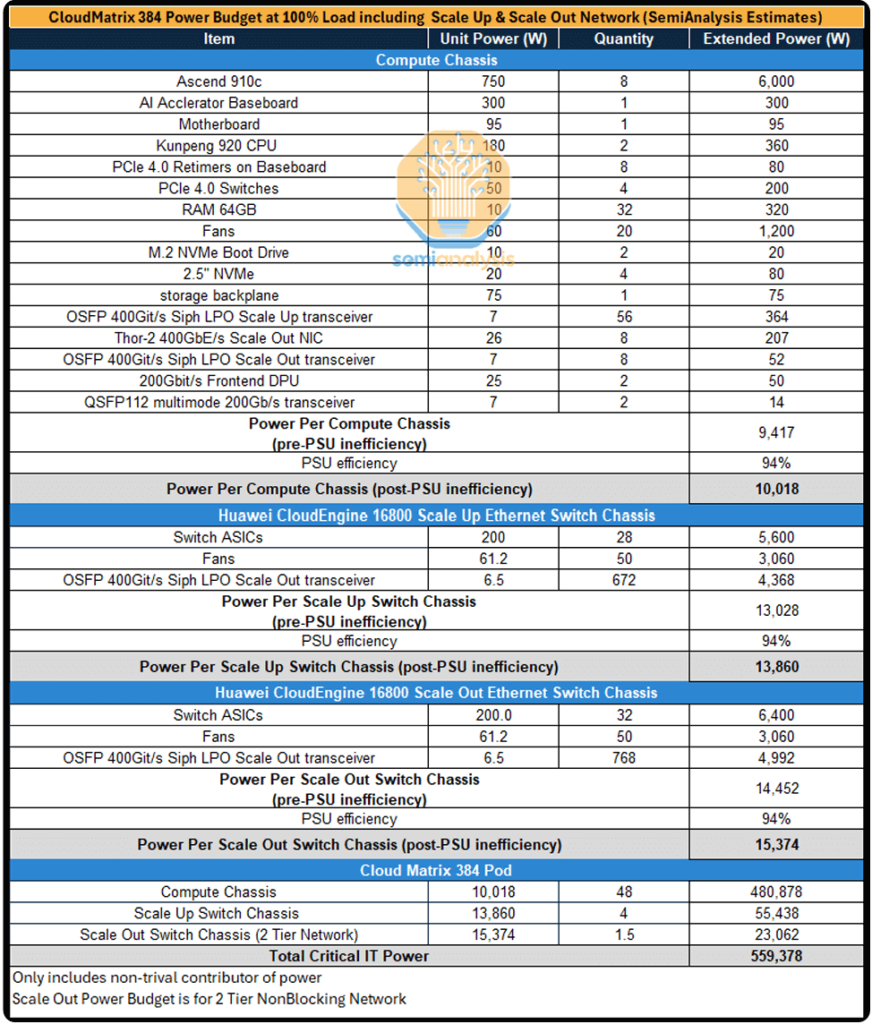
En raison du déploiement massif d'émetteurs-récepteurs optiques dans les réseaux d'extension verticaux et horizontaux, la consommation électrique d'un cluster de 384 GPU est extrêmement élevée. On estime qu'un seul supernœud CM384 consomme près de 500 kilowatts, soit plus de quatre fois les 145 kilowatts environ consommés par un rack NVIDIA GB200 NVL72.
Comparaison de l'efficacité énergétique d'un seul GPU
À l'échelle de chaque GPU, la consommation énergétique globale des GPU Huawei représente environ 70 à 80 % de celle des GPU NVIDIA NVL72 B200. En termes de performances globales des supernœuds, la solution Huawei offre un nombre d'opérations en virgule flottante (FLOPS) 70 % supérieur à celui du NVL72. Cependant, cette conception architecturale présente les inconvénients suivants en termes d'efficacité énergétique :
- Consommation d'énergie par FLOP : 2.3 fois plus élevée,
- Consommation d'énergie par To/s de bande passante mémoire : 1.8 fois plus élevée,
- Consommation d'énergie par To de capacité de mémoire HBM : 1.1 fois plus élevée.
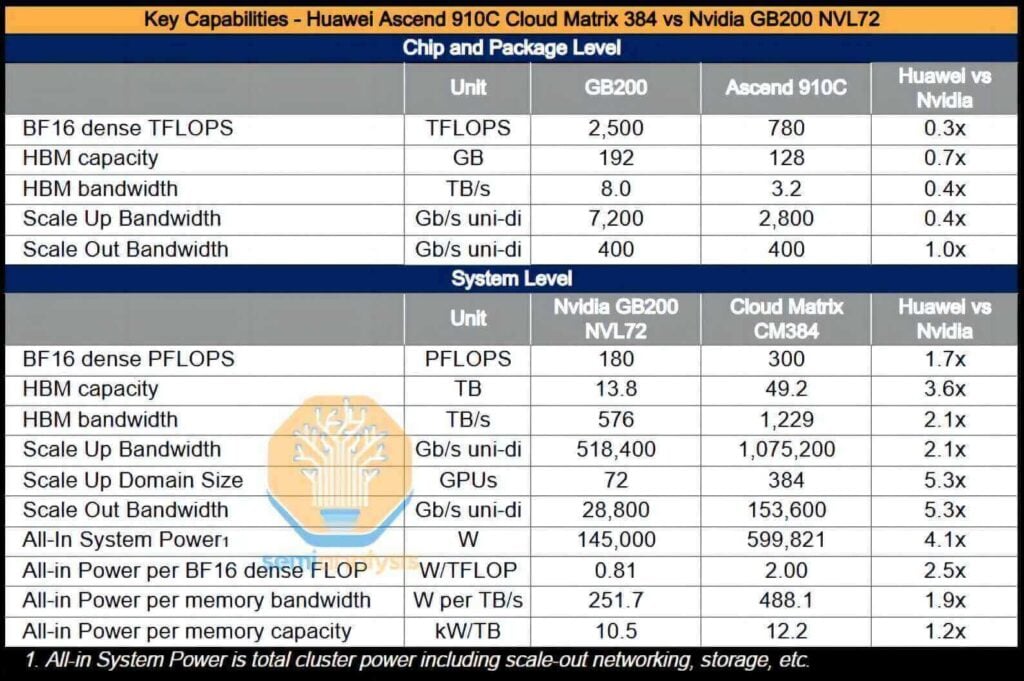
Ces dépenses supplémentaires et cette consommation d'énergie accrue représentent des coûts que la Chine doit supporter pour rivaliser avec les performances informatiques occidentales. Compte tenu de ses abondantes réserves énergétiques et de l'importance de la sécurité nationale dans de tels projets, ces coûts sont considérés comme relativement gérables. L'avantage énergétique de la Chine constituera probablement un atout essentiel, permettant aux centres de données de se développer en taille et en vitesse.
Produits associés:
-
 OSFP-400G-SR8 400G SR8 OSFP PAM4 850nm MTP/MPO-16 100m OM3 MMF FEC Module Émetteur-Récepteur Optique
$225.00
OSFP-400G-SR8 400G SR8 OSFP PAM4 850nm MTP/MPO-16 100m OM3 MMF FEC Module Émetteur-Récepteur Optique
$225.00
-
 OSFP-400G-DR4 400G OSFP DR4 PAM4 1310nm MTP/MPO-12 500m SMF FEC Module émetteur-récepteur optique
$800.00
OSFP-400G-DR4 400G OSFP DR4 PAM4 1310nm MTP/MPO-12 500m SMF FEC Module émetteur-récepteur optique
$800.00
-
 OSFP-400G-PSM8 400G PSM8 OSFP PAM4 1550nm MTP/MPO-16 300m SMF FEC Module émetteur-récepteur optique
$1000.00
OSFP-400G-PSM8 400G PSM8 OSFP PAM4 1550nm MTP/MPO-16 300m SMF FEC Module émetteur-récepteur optique
$1000.00
-
 OSFP-400G-SR4-FLT 400G OSFP SR4 Flat Top PAM4 850nm 30m sur OM3/50m sur OM4 MTP/MPO-12 Module émetteur-récepteur optique FEC multimode
$550.00
OSFP-400G-SR4-FLT 400G OSFP SR4 Flat Top PAM4 850nm 30m sur OM3/50m sur OM4 MTP/MPO-12 Module émetteur-récepteur optique FEC multimode
$550.00
-
 OSFP-400G-DR4-FLT 400G OSFP DR4 Plat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Module Émetteur-Récepteur Optique
$700.00
OSFP-400G-DR4-FLT 400G OSFP DR4 Plat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Module Émetteur-Récepteur Optique
$700.00
-
 QSFP112-400G-SR4 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC Module Émetteur-Récepteur Optique
$450.00
QSFP112-400G-SR4 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC Module Émetteur-Récepteur Optique
$450.00
-
 QSFP112-400G-DR4 400G QSFP112 DR4 PAM4 1310nm 500m MTP/MPO-12 avec Module émetteur-récepteur optique KP4 FEC
$650.00
QSFP112-400G-DR4 400G QSFP112 DR4 PAM4 1310nm 500m MTP/MPO-12 avec Module émetteur-récepteur optique KP4 FEC
$650.00
-
 Module émetteur-récepteur optique QSFP112-400G-FR1 4x100G QSFP112 FR1 PAM4 1310nm 2km MTP/MPO-12 SMF FEC
$1200.00
Module émetteur-récepteur optique QSFP112-400G-FR1 4x100G QSFP112 FR1 PAM4 1310nm 2km MTP/MPO-12 SMF FEC
$1200.00
-
 NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m sur OM3/50m sur OM4 MTP/MPO-12 Module émetteur-récepteur optique FEC multimode
$550.00
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m sur OM3/50m sur OM4 MTP/MPO-12 Module émetteur-récepteur optique FEC multimode
$550.00
-
 NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Module Émetteur-Récepteur Optique
$700.00
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Module Émetteur-Récepteur Optique
$700.00
-
 Module émetteur-récepteur optique 1G QSFP00 VR400 PAM400 112 nm 4 m MTP/MPO-4 OM850 FEC compatible NVIDIA MMA50Z12-NS4
$550.00
Module émetteur-récepteur optique 1G QSFP00 VR400 PAM400 112 nm 4 m MTP/MPO-4 OM850 FEC compatible NVIDIA MMA50Z12-NS4
$550.00
-
 NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 avec Module émetteur-récepteur optique FEC
$700.00
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 avec Module émetteur-récepteur optique FEC
$700.00