
Le 23 mai, la quatrième session du Forum chinois de développement de haute qualité 2024, organisée conjointement par CIOE (China International Optoelectronic Expo) et C114 Communications Network, s'est tenue avec succès sur le thème « L'ère de l'IA : nouvelles tendances en matière d'interconnexion optique des centres de données ». Technologie". L'architecte d'interconnexion optique de JD, Chen Cheng, a prononcé un discours d'ouverture sur « L'interconnexion optique dans les réseaux informatiques hautes performances » lors de la réunion.
JD a commencé très tôt dans le domaine des réseaux informatiques hautes performances et a continué à investir massivement dans plusieurs générations de topologies informatiques intelligentes. Les scénarios d'application impliquent des algorithmes de recommandation, un service client intelligent, la vente et la location d'IA, la diffusion en direct de données humaines numériques, et bien plus encore.
La topologie du réseau informatique intelligent est généralement divisée en deux réseaux indépendants : le réseau d'accès/stockage, qui réalise principalement l'interconnexion entre les CPU ; Le second est le réseau informatique, qui effectue principalement la coordination parallèle des données des nœuds GPU. Dans l'ensemble, les exigences des réseaux informatiques intelligents en matière d'interconnexion optique se concentrent principalement sur trois aspects, à savoir une large bande passante, un faible coût et une faible latence.
La relation entre les émetteurs-récepteurs optiques et la large bande passante
En termes de bande passante de liaison de données, la première chose à réaliser est une communication multicanal parallèle entre les GPU. Il convient de prêter attention à la bande passante de la liaison lors de la transmission des données. Dans l'interconnexion interne des nœuds informatiques, la méthode C2C Full mesh peut généralement être utilisée et le débit de connexion peut atteindre des centaines de Go/s.
Si vous souhaitez établir une communication entre différentes exportations GPU, vous devez connecter l'émetteur-récepteur optique à la carte réseau via PCle, puis établir une connexion multiport via l'émetteur-récepteur optique et les réseaux informatiques après la conversion série-parallèle. Par conséquent, de nombreux fabricants préconisent actuellement la forme d'entrée/sortie optique (OIO) pour briser le goulot d'étranglement de l'interconnexion à haut débit, qui est également une tendance de développement actuellement.
En termes d'évolution de l'équipement réseau/de la bande passante des émetteurs-récepteurs optiques, le réseau informatique intelligent actuel déploie principalement des commutateurs Serdes 50G et des émetteurs-récepteurs optiques, et le principal type d'émetteur-récepteur optique est 200G/400G. Lorsque la capacité d'un seul nœud atteint 51.2 T, différents types de topologie seront sélectionnés en fonction des exigences d'évolutivité du réseau. Certains fabricants nord-américains choisiront un OSFP 64x800G, tandis que les fabricants nationaux utiliseront un boîtier QSFP 128 400x112G, avec des chaînes industrielles universelles des deux.
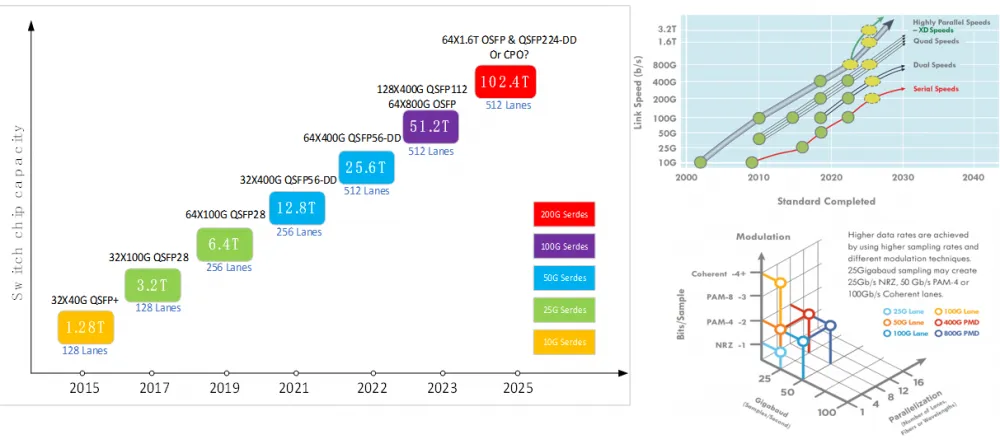
Evolution de la bande passante des équipements réseaux/émetteurs-récepteurs optiques
Si la capacité de commutation monopuce atteint 102.4 T à l'avenir, l'émetteur-récepteur optique enfichable peut toujours prendre en charge les applications d'interconnexion optique haute densité et haute capacité, et 64 × 1.6 T OSFP et QSFP224-DD peuvent être sélectionnés. CPO est également l’une des solutions les plus populaires. Il continue de résoudre les problèmes de fiabilité et résout également les problèmes de maintenabilité pendant la construction et le déploiement.
Comment réduire le coût de l’interconnexion optique ?
En matière de réduction du coût de l’interconnexion optique, la technologie photonique à base de silicium constitue l’une des solutions potentielles de réduction des coûts. La photonique sur silicium n'est pas une toute nouvelle technologie, mais c'est un produit relativement nouveau en termes d'applications pour les centres de données. La chaîne d'approvisionnement actuelle en amont de modules 112G par voie est concentrée dans un petit nombre de fabricants de dispositifs optiques, de sorte que les modules photoniques au silicium peuvent être impliqués pour résoudre le problème de pénurie d'approvisionnement.
En particulier, les émetteurs-récepteurs optiques en silicium peuvent couvrir les besoins de tous les scénarios d'application de centres de données dans un rayon de 2 km. JD effectue donc également la certification correspondante et d'autres travaux. On pense qu’ils pourront être véritablement déployés dans le réseau actuel dans un avenir proche.
Les émetteurs-récepteurs optiques linéaires à entraînement direct LPO/LRO sont également une tendance d'application populaire actuellement. À l'ère du 112G par voie, grâce à la forte capacité de pilotage de l'ASIC, les émetteurs-récepteurs optiques peuvent être simplifiés, c'est-à-dire que la partie DSP ou CDR peut être supprimée, réduisant ainsi la complexité de l'émetteur-récepteur optique pour atteindre l'objectif de réduction des coûts. .
Cependant, il est également confronté à certains défis, tels que des problèmes de compatibilité et d'interopérabilité. Il faut considérer le support des puces ASIC, l'interconnexion entre les différents fabricants, l'interconnexion entre les nouveaux et les anciens modules, etc.
La question de la durabilité évolutive doit également être prise en compte. Par exemple, le 112G peut déjà prendre en charge le LPO, mais s'il évolue vers le 224G, la faisabilité du support du LPO doit être prise en compte.
Problème de faible latence du réseau informatique intelligent
En termes de faible latence, si nous voulons obtenir des garanties informatiques globales coordonnées, le problème de latence du GPU entre les différents nœuds de calcul réduira inévitablement considérablement l'efficacité opérationnelle. Alors, quels facteurs provoquent généralement la latence ?
Premièrement, le réseau GPU était initialement basé sur le protocole InfiniBand (IB), qui contournait le CPU lors de la transmission des données, permettant la communication de données entre les caches GPU entre différents nœuds informatiques, réduisant ainsi considérablement les délais de communication basés sur le protocole.
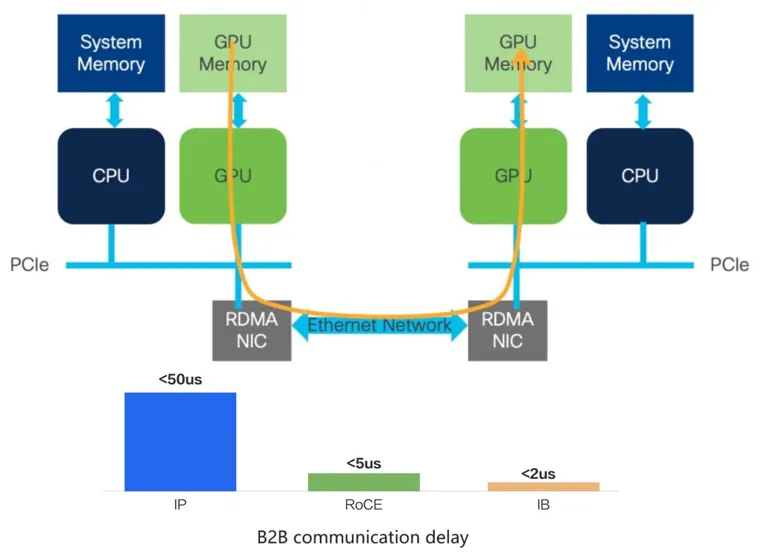
Délai de communication B2B
Le protocole Ethernet traditionnel nécessite que le processeur soit impliqué dans l'ensemble du processus de communication, le délai sera donc plus long. Une solution plus compromettante, à savoir la solution RDMA, est utilisée dans les réseaux informatiques intelligents. Le noyau RDMA peut être encapsulé à l'aide de l'encapsulation du protocole Ethernet, partageant ainsi les fonctionnalités Ethernet pour réduire la latence.
Le second est le délai de liaison. La communication entre les GPU doit passer par l'architecture feuille-épine et effectuer une conversion de signal optique pour réaliser l'interconnexion des données. Par conséquent, divers retards se produiront inévitablement dans diverses liaisons au cours du processus.
Par exemple, dans la latence d'un modèle de prise de décision, l'élément qui peut être optimisé est le retard provoqué par l'unité de récupération de signal dans l'émetteur-récepteur optique. Dans le retard du modèle génératif, le retard est principalement causé par le temps de transmission des données, tandis que le retard causé par la liaison physique ne représente qu'une très faible proportion. Par conséquent, à l'heure actuelle, le retard du système sera plus sensible à l'utilisation de la bande passante et différentes directions de retard doivent être optimisées en fonction de différents modèles.
Enfin, Chen Cheng a conclu que par rapport aux réseaux de communication de données traditionnels, la bande passante des réseaux informatiques intelligents augmentera plus rapidement et que l'interconnexion à faible coût dépend de la prise en charge de nouvelles technologies telles que la photonique sur silicium, LPO/LRO, etc. les modèles ont des exigences différentes en matière de latence et les orientations d'optimisation seront différentes.
Produits associés:
-
 NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 avec Module émetteur-récepteur optique FEC
$700.00
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 avec Module émetteur-récepteur optique FEC
$700.00
-
 NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Module Émetteur-Récepteur Optique
$700.00
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Module Émetteur-Récepteur Optique
$700.00
-
 Module émetteur-récepteur optique 1G QSFP00 VR400 PAM400 112 nm 4 m MTP/MPO-4 OM850 FEC compatible NVIDIA MMA50Z12-NS4
$550.00
Module émetteur-récepteur optique 1G QSFP00 VR400 PAM400 112 nm 4 m MTP/MPO-4 OM850 FEC compatible NVIDIA MMA50Z12-NS4
$550.00
-
 NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m sur OM3/50m sur OM4 MTP/MPO-12 Module émetteur-récepteur optique FEC multimode
$550.00
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m sur OM3/50m sur OM4 MTP/MPO-12 Module émetteur-récepteur optique FEC multimode
$550.00
-
 NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 Module émetteur-récepteur optique SMF
$1199.00
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 Module émetteur-récepteur optique SMF
$1199.00
-
 NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 Module émetteur-récepteur optique MMF
$650.00
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 Module émetteur-récepteur optique MMF
$650.00
-
 NVIDIA MMS4X00-NM Compatible 800Gb/s double port OSFP 2x400G PAM4 1310nm 500m DOM double MTP/MPO-12 Module émetteur-récepteur optique SMF
$900.00
NVIDIA MMS4X00-NM Compatible 800Gb/s double port OSFP 2x400G PAM4 1310nm 500m DOM double MTP/MPO-12 Module émetteur-récepteur optique SMF
$900.00
-
 NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 Module émetteur-récepteur optique MMF
$650.00
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 Module émetteur-récepteur optique MMF
$650.00
-
 NVIDIA MCP4Y10-N002-FLT Compatible 2 m (7 pieds) 800G double port 2x400G OSFP vers 2x400G OSFP InfiniBand NDR DAC passif, dessus plat à une extrémité et dessus plat à l'autre
$300.00
NVIDIA MCP4Y10-N002-FLT Compatible 2 m (7 pieds) 800G double port 2x400G OSFP vers 2x400G OSFP InfiniBand NDR DAC passif, dessus plat à une extrémité et dessus plat à l'autre
$300.00
-
 NVIDIA MCA4J80-N003-FLT Compatible 3 m (10 pieds) 800G double port 2x400G OSFP vers 2x400G OSFP InfiniBand NDR câble en cuivre actif, dessus plat à une extrémité et dessus plat à l'autre
$600.00
NVIDIA MCA4J80-N003-FLT Compatible 3 m (10 pieds) 800G double port 2x400G OSFP vers 2x400G OSFP InfiniBand NDR câble en cuivre actif, dessus plat à une extrémité et dessus plat à l'autre
$600.00