
Ethernet remet en question la domination d'InfiniBand
InfiniBand a dominé les réseaux hautes performances aux débuts de l'IA générative grâce à sa vitesse supérieure et sa faible latence. Cependant, Ethernet a réalisé des progrès significatifs, exploitant la rentabilité, l'évolutivité et les avancées technologiques continues pour combler son retard sur les réseaux InfiniBand. Des géants du secteur comme Amazon, Google, Oracle et Meta ont adopté des solutions Ethernet hautes performances, réduisant ainsi l'écart de performance et, dans certains cas, surpassant InfiniBand sur des indicateurs spécifiques. Même NVIDIA, leader historique d'InfiniBand, s'est tourné vers des solutions Ethernet comme Spectrum-X, qui surpasse désormais ses produits Quantum InfiniBand de la série de GPU Blackwell. La sortie du Consortium Ultra EthernetLa spécification Release Candidate 1 de (UEC) marque un moment charnière dans cette évolution, positionnant Ethernet comme un concurrent redoutable dans les réseaux d'IA et le calcul haute performance (HPC).
Spécification UEC 1.0 : redéfinir Ethernet pour l'IA et la concurrence InfiniBand
La spécification Release Candidate 562 de 1 pages de l'UEC introduit une architecture Ethernet améliorée adaptée aux réseaux d'IA à grande échelle et aux clusters HPC.
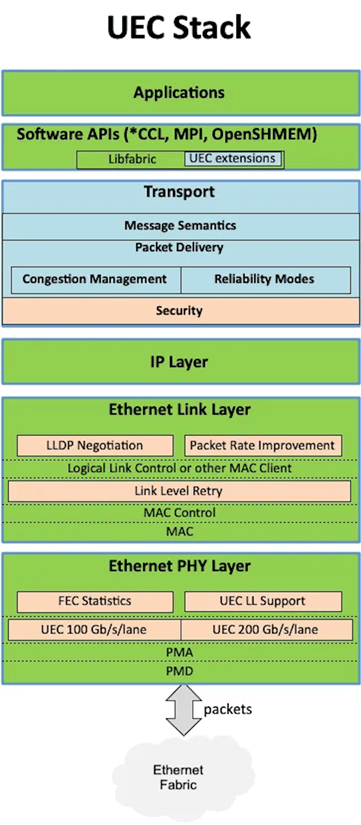
Contrairement à l'Ethernet standard, qui peine à égaler les performances d'InfiniBand sans personnalisation poussée, l'UEC optimise les couches de transport et de contrôle de flux pour offrir des performances de niveau InfiniBand avec une flexibilité et une rentabilité accrues. Le projet UEC vise à fournir des fonctionnalités de couche transport et de couche contrôle de flux pour les cartes d'interface réseau (NIC) et les commutateurs Ethernet, optimisant ainsi l'efficacité opérationnelle des réseaux de centres de données haut débit à grande échelle. La couche transport garantit que les données utilisateur parviennent à destination depuis la source, tout en prenant en charge les exigences modernes de l'IA et des commandes HPC. La couche contrôle de flux, quant à elle, garantit une transmission des données à des débits optimaux, prévient la congestion et assure un réacheminement dynamique en cas de panne de liaison.
Composants de base de l'UEC pour concurrencer InfiniBand
L'UEC, piloté par la Linux Joint Development Foundation (JDF), vise à atteindre une latence aller-retour de 1 à 20 microsecondes, ce qui le rend idéal pour l'entraînement et l'inférence de l'IA, ainsi que pour les réseaux HPC. Ses spécifications imposent que la couche physique du réseau soit conforme aux normes Ethernet, tout en exigeant des commutateurs compatibles avec les fonctionnalités Ethernet modernes.
Open Fabric Interfaces (LibFabric) est un pilier technique essentiel. API largement adoptée, LibFabric standardise l'utilisation des cartes réseau en connectant des bibliothèques réseau hautes performances, telles que NCCL de NVIDIA, RCCL d'AMD et MPI, via des liaisons ou des plugins existants, répondant ainsi aux besoins de communication des clusters de supercalcul IA. L'UEC impose la prise en charge de LibFabric pour les cartes réseau, notamment les commandes d'envoi/réception, RDMA et les opérations atomiques, accélérant ainsi les performances de type InfiniBand.
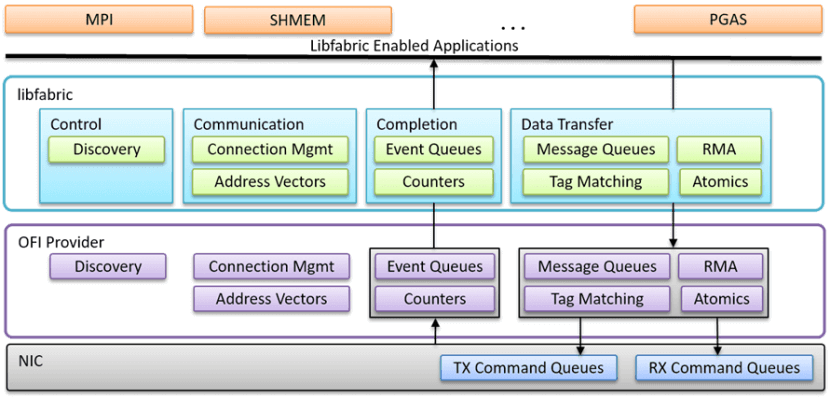
Le projet UEC n'est pas une invention entièrement nouvelle ; il s'appuie sur des normes ouvertes établies pour définir un cadre d'interopérabilité pour ses opérations, en mettant l'accent sur les interactions API sans contrainte avec les processeurs/GPU. UEC exige que toutes les cartes réseau prennent en charge le jeu de commandes LibFabric, y compris les opérations d'envoi, de réception, RDMA et atomiques, permettant ainsi la traduction de la pile de commandes logicielles de LibFabric en jeux d'instructions accélérés matériellement sur la carte réseau.
Le concept de « Job » introduit par LibFabric est affiné dans UEC. Chaque Job représente un ensemble de processus collaboratifs répartis sur plusieurs points de terminaison, isolés via des points de terminaison Fabric (FEP) au sein de la carte réseau. Une même carte réseau peut héberger plusieurs FEP, mais chaque FEP appartient exclusivement à un Job et ne peut communiquer qu'avec les FEP partageant le même identifiant de Job. La création et la terminaison des Jobs sont gérées par un service Fabric de confiance, qui prend également en charge les domaines chiffrés pour une isolation sécurisée du trafic. UEC offre également des mécanismes d'adhésion flexibles pour les scénarios de service nécessitant une participation dynamique.
Ces concepts Job et FEP constituent la base des opérations réseau UEC et sont des composants obligatoires de l'implémentation de la commande LibFabric.
La couche de transport d'UEC fournit des commandes et des données LibFabric aux FEP, en exploitant idéalement Ethernet tout en prenant en charge des couches d'amélioration facultatives.
- Open Fabric Interfaces (LibFabric) : une API standardisée qui s'intègre aux bibliothèques hautes performances telles que NCCL de NVIDIA, RCCL d'AMD et MPI, permettant une communication fluide au sein des clusters de supercalcul IA. UEC impose la prise en charge de LibFabric pour les cartes réseau, notamment les commandes d'envoi/réception, RDMA et les opérations atomiques, accélérant ainsi les performances de type InfiniBand.
- Modèle de tâche et de point de terminaison de fabric (FEP) : l'UEC introduit un concept de tâche, où les processus collaboratifs entre les points de terminaison sont isolés via des FEP au sein des cartes réseau. Cela garantit une communication sécurisée et évolutive, rivalisant avec les protocoles propriétaires d'InfiniBand.
- Architecture multi-rails : la conception du « réseau lourd » d'UEC utilise plusieurs chemins cohérents (par exemple, 8 canaux de 100 Gbit/s pour une interface 800 GbE) pour maximiser la bande passante et la redondance, offrant une évolutivité qui défie Réseaux InfiniBand.
Conception de la couche paquets
S'appuyant sur l'expérience du secteur avec les commutateurs modulaires, l'UEC fragmente les messages LibFabric en paquets plus petits pour un routage flexible, intégrant fiabilité et contrôle de flux directement dans la couche transport. Compte tenu des exigences de latence ultra-faible des centres de données, l'accélération matérielle est essentielle pour la reprise sur erreur et le contrôle de flux afin de garantir une diffusion fluide des données.
La couche paquets introduit des en-têtes supplémentaires, permettant aux cartes réseau et aux commutateurs d'échanger des informations opérationnelles réseau indépendamment des flux de messages. Alors que les commutateurs modulaires gèrent généralement ces tâches via des couches de commutation internes, les cartes réseau UEC génèrent des paquets dotés de capacités de contrôle de flux améliorées, transmis via Ethernet augmenté.
Architecture multi-rails
L'UEC est conçu pour les réseaux « lourds » comportant plusieurs chemins physiquement équidistants et à débit égal, généralement mis en œuvre dans des configurations « multi-rails ». Par exemple, une interface réseau 800 GbE peut comprendre huit voies de 100 Gbit/s, chacune connectée à un commutateur distinct. Chaque commutateur prenant en charge 512 ports de 100 Gbit/s, le système peut accueillir jusqu'à 512 FEP.
Les cartes réseau UEC utilisent un mécanisme d'« entropie » pour répartir les paquets entre les voies via le hachage afin d'équilibrer la charge. L'expéditeur sélectionne les valeurs d'entropie pour répartir les paquets uniformément, maximisant ainsi la bande passante globale. Les applications CPU/GPU ignorent cette complexité et se contentent de mettre les envois en file d'attente via LibFabric, tandis que la carte réseau gère automatiquement la distribution.
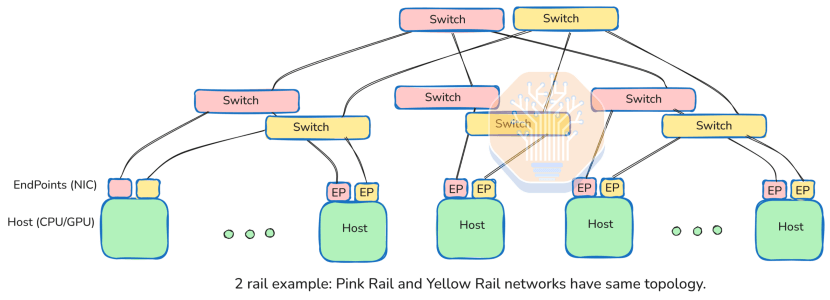
Cette architecture multi-rails permet le fonctionnement en parallèle de plusieurs commutateurs 512 ports avec des topologies identiques, pour un débit global plus élevé. L'innovation d'UEC réside dans la coordination de ces points de terminaison au sein d'une même carte réseau, offrant ainsi aux hôtes une connexion haut débit tout en répartissant le trafic de manière transparente sur les chemins.
Au-delà de l'amélioration de l'évolutivité des clusters et de la simplification du déploiement du réseau, les chemins multiples permettent aux cartes réseau UEC de fournir :
- Récupération ultra-rapide des pertes de paquets
- Contrôle de flux à l'échelle de la microseconde
- Débit stable malgré une planification d'application sous-optimale ou des fluctuations occasionnelles de liaison
UEC-CC : Contrôle de congestion avancé pour rivaliser avec InfiniBand
Le contrôle de congestion d'UEC (UEC-CC) révolutionne les performances des réseaux IA. Avec une précision inférieure à 500 nanosecondes, l'UEC-CC mesure indépendamment les délais aller et retour, ce qui nécessite une synchronisation temporelle absolue entre les cartes réseau. Contrairement à InfiniBand, qui s'appuie sur des mécanismes propriétaires, l'UEC-CC utilise la notification explicite de congestion (ECN) et prend en charge le découpage des paquets pour minimiser les pertes. En éliminant les protocoles obsolètes tels que RoCE, DCQCN et le contrôle de flux prioritaire (PFC), l'UEC-CC garantit des flux de données plus fluides, faisant d'Ethernet un concurrent de poids pour les réseaux à faible latence.
Grâce à des mesures bidirectionnelles, l'UEC-CC peut déterminer avec précision si la congestion provient de l'émetteur ou du récepteur. Lorsque l'UEC-CC est activée, les commutateurs doivent prendre en charge la notification explicite de congestion (ECN). Des variantes ECN modernes sont recommandées : il est notamment recommandé de définir des indicateurs de congestion par classe de trafic et d'effectuer des mesures immédiatement avant la transmission des paquets. Cette approche fournit les informations de congestion les plus récentes et permet une gestion différenciée par classe de trafic.
En cas de congestion extrême, l'UEC-CC prend également en charge le découpage des paquets, en ne conservant que les informations d'en-tête tombstone pour notifier explicitement le récepteur de la perte de paquets. Comparé à la suppression pure et simple des paquets, ce mécanisme déclenche des réponses de correction d'erreur plus rapidement.
Étant donné que les temps d'aller-retour (RTT) des centres de données ne sont que de quelques microsecondes, l'émetteur ne peut transmettre des données que pendant une durée extrêmement courte sans attendre d'accusé de réception. Par conséquent, le processeur frontal (FEP, probablement lié à la logique carte réseau/récepteur) récepteur est responsable du contrôle du débit de transmission.
Le récepteur collecte des informations détaillées sur l'état des flux multivoies et multiclasses de trafic via des indicateurs ECN. Sur cette base, il détermine le nombre de nouveaux crédits de paquets à accorder et informe l'expéditeur via des accusés de réception (ACK) et des commandes spéciales de crédit CP (Packet de contrôle). Cela permet de suspendre l'expéditeur à la microseconde près, évitant ainsi efficacement la perte de paquets.
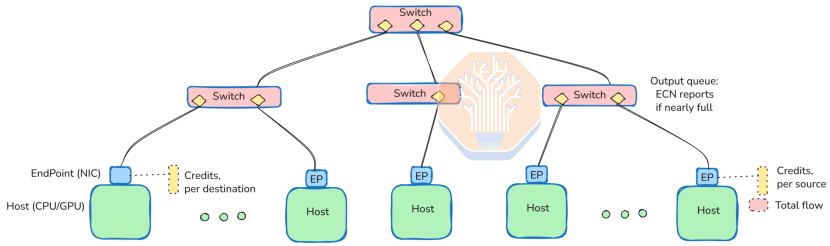
De plus, l'UEC-CC prend en charge l'ajustement dynamique de la « capacité d'entropie » afin de rééquilibrer les chemins de routage, optimisant ainsi les stratégies de diffusion de messages. Il standardise le mécanisme de reporting des taux de correction d'erreurs partielles et de perte de paquets, permettant au système de détecter les liens faibles et de les contourner. En utilisant le routage par hachage basé sur l'entropie à chaque saut, même avec des niveaux d'entropie supérieurs d'un ordre de grandeur au nombre de voies, les liens faibles peuvent être isolés, minimisant ainsi leur impact sur la capacité globale du chemin.
UEC-CC déconseille plusieurs mécanismes de contrôle de flux hérités :
- RoCE et DCQCN : obsolètes car leur incapacité à mettre à jour dynamiquement les stratégies de contrôle de flux en fonction de l'emplacement réel des problèmes de flux dégrade les performances UEC-CC.
- PFC (Contrôle de flux basé sur la priorité) : inutile entre les commutateurs, il peut même bloquer le trafic légitime ; il doit donc être désactivé. Il n'est plus recommandé pour les connexions carte réseau-commutateur en raison de son manque de précision par rapport à l'UEC-CC.
- Contrôle de flux basé sur le crédit : également obsolète car il entre en conflit avec le mécanisme UEC-CC.
Sécurité des transports pour un réseau d'IA sécurisé
La sous-couche de sécurité du transport d'UEC adopte la cryptographie post-quantique (DES) et la dérivation dynamique de clés pour sécuriser les communications des clusters d'IA. Ce cadre de sécurité robuste prend en charge des domaines de chiffrement flexibles, garantissant ainsi la sécurité des échanges de données, même dans des environnements dynamiques, et offrant un niveau de sécurité comparable à celui des réseaux InfiniBand.
La sous-couche de sécurité du transport est un mécanisme de sécurité hautement spécialisé et rigoureusement structuré. Elle s'appuie sur de nombreuses pratiques de sécurité établies tout en intégrant des améliorations adaptatives.
L'UEC recommande l'utilisation d'un algorithme cryptographique post-quantique, DES (Data Encryption Standard), comme méthode de chiffrement, et privilégie les opérations défensives, notamment les règles de rotation des valeurs de nonce. Le domaine de chiffrement peut être un sous-ensemble de FEP au sein d'un Job, et prend également en charge la configuration adaptative du domaine pour les scénarios de service dynamique où les clients rejoignent ou quittent fréquemment le service.
Ce mécanisme utilise un système ingénieux de dérivation de clés. Il permet d'utiliser une clé principale unique pour l'ensemble du domaine, tout en utilisant des clés et des nonces différents pour chaque flux de communication, ce qui ne nécessite qu'un espace table minimal (même pour les jobs contenant des dizaines de milliers de points de terminaison).
Pour garantir la sécurité, le centre de données doit intégrer des composants de confiance :
- Une entité Security Domain Manager chargée de créer et de maintenir le domaine de chiffrement.
- Les cartes réseau sont équipées de modules matériels de confiance pour gérer leur accès aux ports au sein du domaine.
Bien que la vérification des versions de ces composants ne relève pas du champ d'application de la spécification UEC, des normes ouvertes existent pour les implémentations de référence des fournisseurs.
Autres calques
Couche 4 : Couche réseau (couche réseau UE) : traite principalement du mécanisme de découpage des paquets, une mesure facultative de contrôle de congestion utilisée pour réduire la charge utile des données lors d'une surcharge du réseau.
Couche 5 : Couche liaison (UE) : vise à améliorer les performances globales grâce au remplacement des paquets au niveau liaison et aux mécanismes de contrôle de flux entre commutateurs. Cependant, étant donné que l'UEC-CC offre déjà un contrôle de flux très efficace, cette conception apparaît largement redondante dans les environnements présentant des délais aller-retour de l'ordre de la microseconde. Compte tenu notamment de l'abandon du CBFC (Contrôle de flux basé sur les crédits) dans la section UEC-CC, cette fonctionnalité ne semble pas offrir d'avantages significatifs. Elle est facultative et son déploiement à grande échelle est peu probable à l'avenir, mais elle peut complexifier les tests d'interopérabilité.
Couche 6 : Couche physique (couche physique UE) : recommande l'utilisation de plusieurs voies Ethernet 100 Gb, conformément aux normes IEEE 802.3/db/ck/df. Le document précise brièvement qu'il est actuellement impossible de se référer aux normes 200 Gb, car elles n'ont pas encore été officiellement publiées. En revanche, la spécification UALink prend explicitement en charge le 200 Gb, ce qui indique une tendance du secteur dans ce sens. L'UEC devrait également envisager de s'appuyer sur ce point à l'avenir, plutôt que de suivre passivement cette tendance.
UEC vs. UALink et SUE : un paysage concurrentiel pour les alternatives à InfiniBand
Alors que l'UEC cible les réseaux Scale-Out évolutifs pour des milliers de points de terminaison, des concurrents comme UALink et Scale Up Ethernet (SUE) de Broadcom se concentrent sur les réseaux Scale-Up similaires à NVLink de NVIDIA.
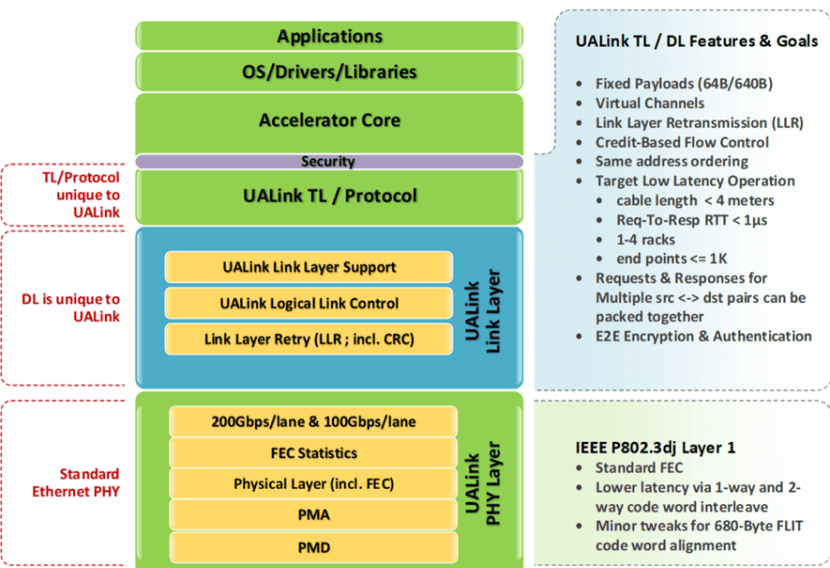
UALink prend en charge jusqu'à 1024 200 points de terminaison avec des liaisons XNUMX GbE, tandis que SUE privilégie les réseaux monorail. Tous deux intègrent des interfaces mappées en mémoire pour un transfert de données efficace, mais l'approche globale d'UEC, incluant la commutation multicouche et le contrôle avancé de la congestion, en fait un concurrent plus sérieux d'InfiniBand pour les clusters d'IA et de HPC à grande échelle.
SUE et UALink mentionnent tous deux explicitement les liaisons 200 GbE dans leurs spécifications, ce qui fait que l'UEC semble légèrement en retard en termes de vitesse.
Similaire à UEC, UALink répartit le trafic sur les rails, mais fournit une définition détaillée de son mécanisme de contrôle de flux basé sur les crédits. En revanche, SUE délègue cet aspect à l'implémentation Ethernet et suggère de s'appuyer sur la coordination du logiciel client. Cela se traduit par une conception de spécification plus claire pour SUE, bien que la différence pratique soit minime. UALink regroupe également plusieurs voies (par exemple, 4×200G) pour améliorer l'efficacité de la transmission, tandis que SUE et UEC considèrent qu'une seule voie 200G est suffisamment rapide. Par conséquent, UALink introduit ici une complexité supplémentaire pour un gain limité.
SUE recommande d'utiliser le PFC ou, de préférence, le contrôle de flux basé sur les crédits (CBFC) pour le contrôle de flux. Dans les environnements de commutation à un seul niveau, cette approche est viable, car le PFC fonctionne bien dans de tels scénarios et le CBFC offre un fonctionnement plus fluide.
UALink fournit des mécanismes de cryptage pour les connexions, tandis que SUE adopte une approche plus rationalisée, déclarant simplement que la fiabilité, l'intégrité des données et le cryptage doivent être fournis par la couche Ethernet.
De plus, SUE délègue les tâches de diffusion de messages et d'équilibrage de charge inter-rails à la couche logicielle des nœuds terminaux. Il s'agit d'un avantage certain pour les entreprises expertes dans le développement de tels logiciels.
UALink et SUE fournissent tous deux une interface mappée en mémoire. Bien qu'aucun des deux ne spécifie l'implémentation exacte du mappage mémoire, tous deux supposent que l'envoi et la réception de messages s'effectuent par lecture et écriture dans des adresses de mémoire virtuelle correspondant à des points de terminaison distants. Cette approche peut théoriquement atteindre une efficacité comparable à celle de NVLink. Cependant, comme ils ne réutilisent pas le format de paquet de NVLink, de nouveaux plugins ou du code de bas niveau doivent encore être développés.
Le « mappage mémoire » est souvent appelé « sémantique mémoire ». Il utilise un vaste espace d'adressage virtuel, attribuant des plages d'adresses uniques à chaque hôte. Cela permet aux processeurs hôtes d'effectuer des opérations mémoire directement à l'aide d'instructions de lecture/écriture. Cependant, ce mécanisme n'inclut pas de sémantique avancée comme la cohérence séquentielle ou la cohérence du cache. Autrement dit, il n'y a pas de surveillance du cache ni de mises à jour intelligentes du cache entre les nœuds du cluster.
Pour tous ces systèmes, y compris l'UEC, les exigences de débit élevé et de faible latence dans les centres de données poussent les terminaux à se rapprocher de la puce hôte, plutôt que de rester des périphériques de bus d'E/S « obsolètes » distants de l'hôte. La tendance actuelle consiste davantage à traiter les terminaux (comme les cartes réseau) comme un cœur supplémentaire au sein d'un système multicœur. Cela simplifie l'envoi de commandes depuis les cœurs de calcul (comme les GPU de streaming ou les CPU traditionnels) et permet aux terminaux d'accéder plus efficacement à la mémoire hôte.
On prévoit que SUE et UALink seront de plus en plus intégrés sous forme de blocs IP au sein de puces hôtes plutôt que de puces autonomes. NVLink a été conçu de cette manière dès le départ, et des puces comme Intel Gaudi 3 ou Microsoft Maia 100 utilisent des approches similaires sur les liaisons Ethernet. Si cela simplifie la conception des blocs IP, cela nécessite également qu'ils restent suffisamment compacts pour minimiser l'espace occupé sur la puce hôte.
En revanche, la complexité de l'UEC réside probablement davantage dans les cartes réseau discrètes. Cependant, il y a de bonnes raisons de penser qu'elle sera progressivement intégrée aux structures de puces hôtes à l'avenir, potentiellement même sous forme de chiplets.
Principaux avantages de l'UEC par rapport à InfiniBand
LibFabric accéléré par le matériel : améliore la compatibilité avec les bibliothèques hautes performances existantes.
- Modèle de travail évolutif : combine un cryptage moderne et une gestion flexible des points de terminaison.
- Contrôle de congestion avancé : UEC-CC surpasse les protocoles traditionnels tels que RoCE et DCQCN.
- Normes ouvertes : prend en charge les plugins CCL, MPI, SHMEM et UD pour une compatibilité avec un écosystème étendu.
- Coût et évolutivité : l'abordabilité et la flexibilité d'Ethernet en font une alternative viable à InfiniBand.
Défis et considérations pour l'adoption de l'UEC
Bien que l'UEC offre des avantages significatifs, des défis subsistent. L'interopérabilité entre les fournisseurs nécessite des tests rigoureux pour garantir des performances constantes, en particulier lorsque des appareils non conformes à l'UEC sont impliqués. L'EFA d'Amazon, bien que basé sur LibFabric, met en évidence des problèmes potentiels de compatibilité des plugins avec l'écosystème NVIDIA. La prise en charge de l'ECN sur les appareils intermédiaires est essentielle pour maintenir des performances de niveau InfiniBand.
L’avenir des réseaux d’IA : l’UEC peut-elle redéfinir les règles ?
À mesure que les modèles d'IA se développent, les performances réseau deviennent un goulot d'étranglement critique. L'approche standard ouverte d'UEC remet en question la domination d'InfiniBand en combinant LibFabric, une architecture multi-rails et un contrôle avancé de la congestion. Son évolutivité, sa sécurité et sa rentabilité en font un choix incontournable pour les futurs réseaux de centres de données IA. Si InfiniBand reste un acteur majeur, les innovations d'UEC pourraient transformer le paysage et orienter le secteur vers des solutions réseau IA ouvertes et standardisées.
La spécification UEC 1.0 marque un tournant dans la bataille entre Ethernet et InfiniBand. En comblant les écarts de performances grâce à l'accélération matérielle, au contrôle de flux avancé et à une sécurité renforcée, UEC positionne Ethernet comme une alternative évolutive et économique pour les réseaux IA et HPC. À mesure que les centres de données évoluent, les normes ouvertes et la flexibilité d'UEC pourraient redéfinir les règles, remettant en cause le monopole d'InfiniBand et ouvrant la voie à une infrastructure IA de nouvelle génération.
Produits associés:
-
 Module émetteur-récepteur optique OSFP 4x50G FR2 PAM400 4nm 4km DOM double Duplex LC SMF Compatible NVIDIA MMS1310X2-NM
$1200.00
Module émetteur-récepteur optique OSFP 4x50G FR2 PAM400 4nm 4km DOM double Duplex LC SMF Compatible NVIDIA MMS1310X2-NM
$1200.00
-
 NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 Module émetteur-récepteur optique SMF
$1199.00
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 Module émetteur-récepteur optique SMF
$1199.00
-
 NVIDIA MMS4X00-NM Compatible 800Gb/s double port OSFP 2x400G PAM4 1310nm 500m DOM double MTP/MPO-12 Module émetteur-récepteur optique SMF
$900.00
NVIDIA MMS4X00-NM Compatible 800Gb/s double port OSFP 2x400G PAM4 1310nm 500m DOM double MTP/MPO-12 Module émetteur-récepteur optique SMF
$900.00
-
 NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 Module émetteur-récepteur optique MMF
$650.00
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 Module émetteur-récepteur optique MMF
$650.00
-
 NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 Module émetteur-récepteur optique MMF
$650.00
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 Module émetteur-récepteur optique MMF
$650.00
-
 NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 avec Module émetteur-récepteur optique FEC
$700.00
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 avec Module émetteur-récepteur optique FEC
$700.00
-
 Module émetteur-récepteur optique 1G QSFP00 VR400 PAM400 112 nm 4 m MTP/MPO-4 OM850 FEC compatible NVIDIA MMA50Z12-NS4
$550.00
Module émetteur-récepteur optique 1G QSFP00 VR400 PAM400 112 nm 4 m MTP/MPO-4 OM850 FEC compatible NVIDIA MMA50Z12-NS4
$550.00
-
 NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Module Émetteur-Récepteur Optique
$700.00
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Module Émetteur-Récepteur Optique
$700.00
-
 NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m sur OM3/50m sur OM4 MTP/MPO-12 Module émetteur-récepteur optique FEC multimode
$550.00
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m sur OM3/50m sur OM4 MTP/MPO-12 Module émetteur-récepteur optique FEC multimode
$550.00
-
 Mellanox MMA1T00-HS Compatible 200G Infiniband HDR QSFP56 SR4 850nm 100m MPO-12 APC OM3/OM4 FEC PAM4 Module émetteur-récepteur optique
$139.00
Mellanox MMA1T00-HS Compatible 200G Infiniband HDR QSFP56 SR4 850nm 100m MPO-12 APC OM3/OM4 FEC PAM4 Module émetteur-récepteur optique
$139.00
-
 Mellanox MMS1W50-HM Compatible 200G InfiniBand HDR QSFP56 FR4 PAM4 CWDM4 2km LC SMF FEC Module Émetteur-Récepteur Optique
$650.00
Mellanox MMS1W50-HM Compatible 200G InfiniBand HDR QSFP56 FR4 PAM4 CWDM4 2km LC SMF FEC Module Émetteur-Récepteur Optique
$650.00
-
 Module émetteur-récepteur Mellanox MMA1B00-E100 Compatible 100G InfiniBand EDR QSFP28 SR4 850nm 100m MTP/MPO MMF DDM
$40.00
Module émetteur-récepteur Mellanox MMA1B00-E100 Compatible 100G InfiniBand EDR QSFP28 SR4 850nm 100m MTP/MPO MMF DDM
$40.00
-
 OSFP-800G-PC50CM 0.5m (1.6ft) 800G Twin-port 2x400G OSFP à 2x400G OSFP InfiniBand NDR Passive Direct Attach Copper Cable
$105.00
OSFP-800G-PC50CM 0.5m (1.6ft) 800G Twin-port 2x400G OSFP à 2x400G OSFP InfiniBand NDR Passive Direct Attach Copper Cable
$105.00
-
 OSFP-800G-AC3M 3m (10ft) 800G Twin-port 2x400G OSFP à 2x400G OSFP InfiniBand NDR Câble Cuivre Actif
$600.00
OSFP-800G-AC3M 3m (10ft) 800G Twin-port 2x400G OSFP à 2x400G OSFP InfiniBand NDR Câble Cuivre Actif
$600.00