
Alors que l'intelligence artificielle (IA) stimule la croissance exponentielle des volumes de données et de la complexité des modèles, le calcul distribué exploite les nœuds interconnectés pour accélérer les processus d'apprentissage. Les commutateurs de centres de données jouent un rôle essentiel pour garantir la livraison rapide des messages entre les nœuds, en particulier dans les centres de données à grande échelle où la latence de queue est essentielle pour gérer des charges de travail compétitives. De plus, l'évolutivité et la capacité à gérer de nombreux nœuds sont essentielles pour entraîner de grands modèles d'IA et traiter des ensembles de données volumineux, ce qui rend les commutateurs de centres de données indispensables à une connectivité réseau et une transmission de données efficaces. Selon IDC, le marché mondial des commutateurs a atteint 308 milliards de dollars en 2022, soit une croissance de 17 % en glissement annuel, avec un taux de croissance annuel composé (TCAC) prévu de 4.6 % entre 2022 et 2027. En Chine, le marché des commutateurs était évalué à 59.1 milliards de dollars, en croissance de 9.5 %, avec un TCAC prévu de 7 à 9 % au cours des cinq prochaines années, dépassant la croissance mondiale.
Principales classifications des commutateurs de centre de données
Les commutateurs de centre de données peuvent être classés selon divers critères, notamment les scénarios d'application, les couches réseau, les types de gestion, les modèles de réseau OSI, les débits de ports et les structures physiques. Ces classifications incluent :
- Par scénario d'application : commutateurs de campus, commutateurs de centre de données
- Par couche réseau : commutateurs d'accès, commutateurs d'agrégation, commutateurs principaux
- Par type de gestion : commutateurs non gérés, commutateurs gérés par le Web, commutateurs entièrement gérés
- Par modèle de réseau OSI : commutateurs de couche 2, commutateurs de couche 3
- Par vitesse de port : commutateurs Fast Ethernet, commutateurs Gigabit Ethernet, commutateurs 10 Gigabit, commutateurs multi-débits
- Par structure physique : commutateurs fixes (boîte), commutateurs modulaires (châssis)
Puces de commutation et indicateurs de performance clés
Les commutateurs Ethernet pour centres de données sont composés de composants critiques tels que des puces, des circuits imprimés, des modules optiques, des connecteurs, des composants passifs, des boîtiers, des alimentations et des ventilateurs. Les composants principaux incluent les puces et les processeurs de commutation Ethernet, ainsi que des éléments supplémentaires tels que les PHY et les CPLD/FPGA. La puce de commutation Ethernet, spécialement conçue pour l'optimisation du réseau, gère le traitement des données et la transmission des paquets, grâce à des chemins logiques complexes garantissant une gestion robuste des données. Le processeur gère les connexions et les interactions avec les protocoles, tandis que le PHY traite les données de la couche physique.
Les performances des commutateurs de centre de données dépendent de paramètres clés tels que la bande passante du fond de panier, le taux de transfert de paquets, la capacité de commutation, la vitesse et la densité des ports. La bande passante du fond de panier indique la capacité de débit de données d'un commutateur, une valeur élevée indiquant de meilleures performances sous fortes charges. Pour un transfert non bloquant, la bande passante du fond de panier doit être au moins égale à la capacité de commutation (calculée comme le nombre de ports × la vitesse des ports × 2 en mode full duplex). Les commutateurs haut de gamme sans fond de panier s'appuient sur les taux de transfert de paquets. Des vitesses de port plus élevées indiquent des capacités de traitement supérieures pour les scénarios à fort trafic, tandis qu'une densité de ports plus élevée permet des mises à l'échelle réseau plus importantes en connectant davantage d'appareils.
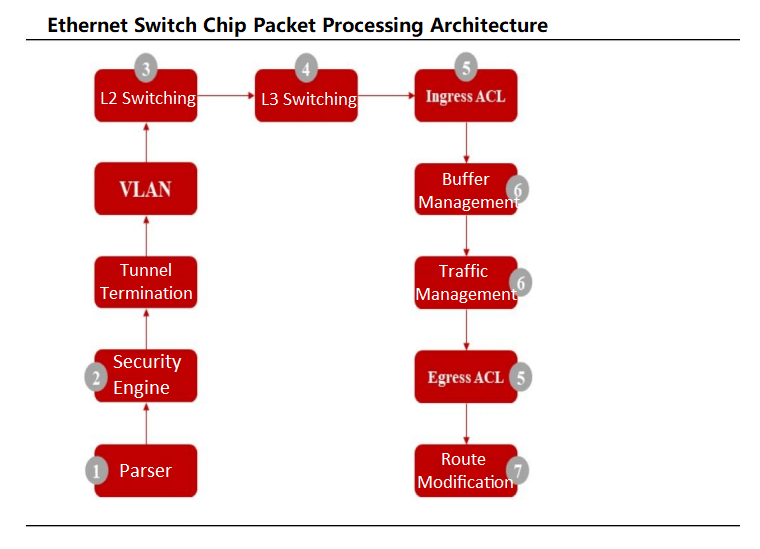
Les puces de commutation Ethernet fonctionnent comme des ASIC spécialisés pour les commutateurs de centres de données, intégrant souvent des contrôleurs MAC et des puces PHY. Les paquets de données entrent par des ports physiques, où l'analyseur de la puce analyse les champs pour classer les flux. Après les contrôles de sécurité, les paquets sont commutés en couche 2 ou en couche 3, le classificateur de flux les dirigeant vers des files d'attente prioritaires selon les normes 802.1P ou DSCP. Les ordonnanceurs gèrent ensuite la priorisation des files d'attente à l'aide d'algorithmes comme Weighted Round Robin (WRR) avant la transmission des paquets.

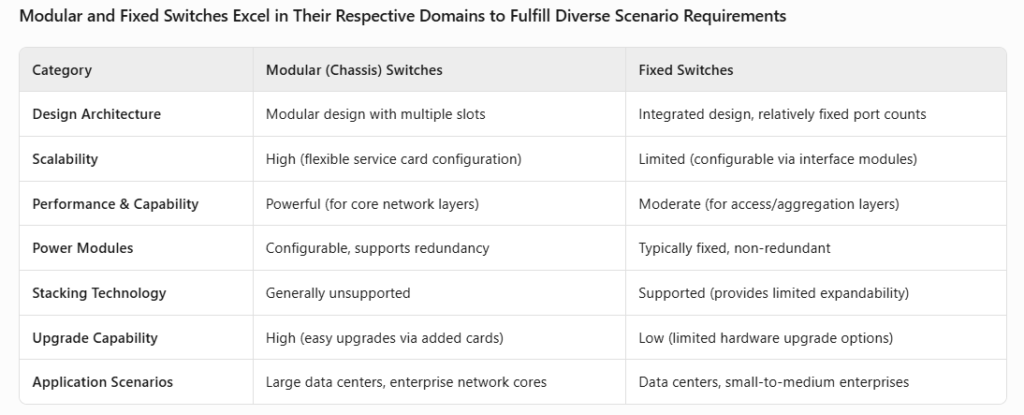
Physiquement, les commutateurs de centre de données sont soit basés sur châssis, soit fixes. Les commutateurs de châssis présentent une conception modulaire avec des emplacements pour les modules d'interface, de contrôle et de commutation, offrant une flexibilité et une évolutivité élevées. Les commutateurs fixes ont des conceptions intégrées avec des configurations de ports fixes, bien que certains prennent en charge des interfaces modulaires. Les principales différences résident dans l'architecture interne et les scénarios d'application (utilisation de la couche OSI).
Évolution et avancées technologiques des commutateurs de centres de données
De l'OEO à l'OOO : commutateurs tout optique pour les charges de travail d'IA
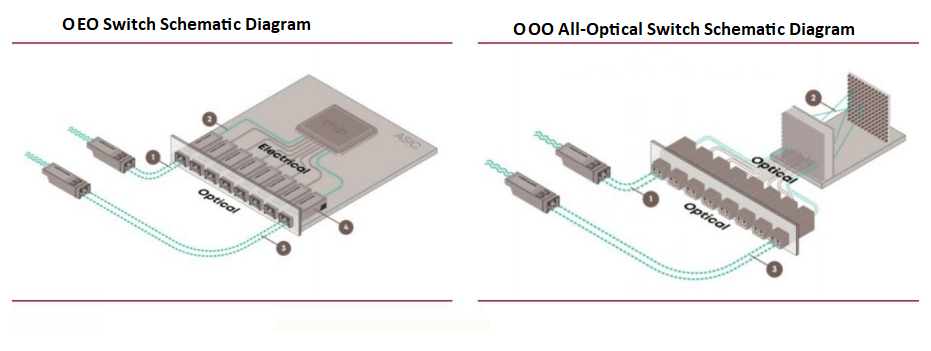
Les commutateurs de centre de données actuels, basés sur des puces ASIC, fonctionnent comme des commutateurs de paquets optiques-électriques-optiques (OEO), s'appuyant sur des puces ASIC pour la transmission des paquets principaux. Ces commutateurs nécessitent des conversions optiques-électriques pour la transmission du signal. Cependant, des commutateurs tout optiques (OOO) émergent pour répondre aux exigences de calcul pilotées par l'IA, réduisant ainsi la charge de conversion et améliorant l'efficacité.
Un dirigeant de NVIDIA rejoint Lightmatter pour faire progresser la commutation tout optique
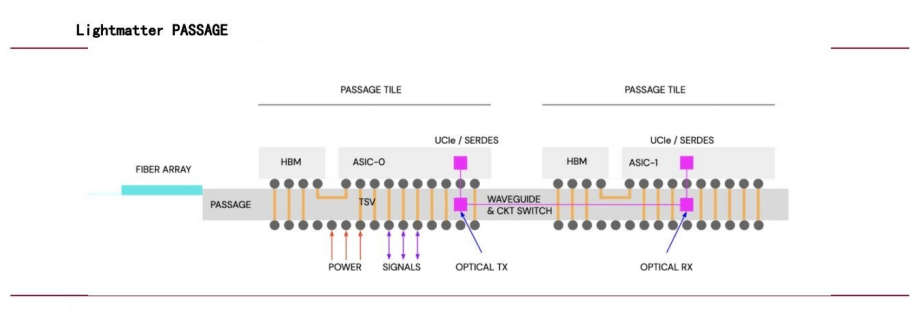
En juillet 2024, Simona Jankowski, vice-présidente de NVIDIA, a rejoint Lightmatter au poste de directrice financière, confirmant ainsi l'importance accordée par l'entreprise aux interconnexions optiques. Valorisée à 4.4 milliards de dollars, la technologie Passage de Lightmatter exploite la photonique pour les interconnexions de puces. Elle utilise des guides d'ondes plutôt que des fibres optiques pour assurer une transmission de données parallèle à haut débit pour divers cœurs de calcul, améliorant ainsi considérablement les performances des réseaux d'IA.
Déploiement à grande échelle des commutateurs OCS par Google
Les réseaux de centres de données de Google privilégient les réseaux définis par logiciel (SDN), la topologie Clos et les puces de commutation standard. La topologie Clos, une architecture multi-étages non bloquante construite à partir de puces Radix plus petites, prend en charge les réseaux évolutifs essentiels aux charges de travail d'IA.
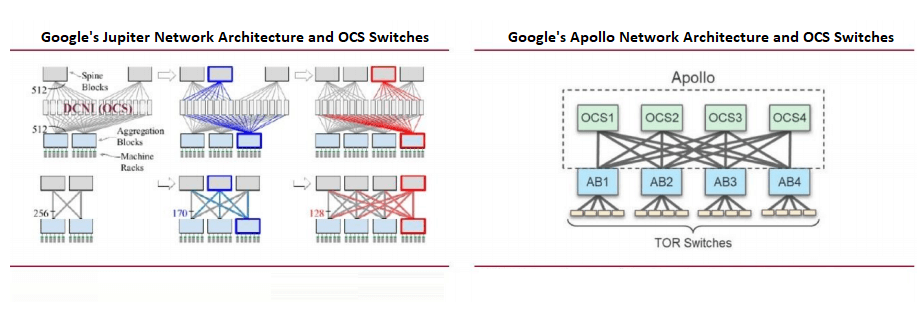
Google a été le pionnier de l'utilisation à grande échelle des commutateurs de circuits optiques (OCS) dans son architecture Jupiter, intégrant des OCS basés sur des MEMS pour réduire les conversions optique-électrique. Lors de l'OFC 2023, Google a présenté son projet Apollo, qui remplace les commutateurs de paquets Ethernet (EPS) de la couche dorsale par des OCS pour une efficacité accrue.
Technologies et normes clés pour les commutateurs de centres de données
- RDMA : permettre une communication à faible latence et à haut débit
L'accès direct à la mémoire à distance (RDMA) permet une communication réseau à haut débit et à faible latence en contournant l'intervention du système d'exploitation. Contrairement au protocole TCP/IP traditionnel, qui nécessite de multiples copies de données gourmandes en ressources processeur, le RDMA transfère directement les données entre les mémoires des ordinateurs. Dans les commutateurs de centres de données, le RDMA est implémenté via InfiniBand et RoCE (RDMA sur Ethernet convergé), avec InfiniBand et RoCEv2 étant les solutions dominantes pour les centres de données IA (AIDC).
- InfiniBand : Conçu pour le calcul haute performance (HPC) et les centres de données, InfiniBand offre une bande passante élevée, une faible latence, une qualité de service (QoS) et une évolutivité optimale. Son architecture canalisée, sa prise en charge RDMA et sa conception en réseau commuté en font la solution idéale pour les applications gourmandes en données. Cependant, son coût élevé limite son adoption aux environnements HPC spécialisés.
Comparaison d'InfiniBand et de RoCE
| Catégorie | InfiniBand | RoCE |
| Philosophie de conception | Conçu avec RDMA à l'esprit, redéfinissant les couches de liaison physique et de réseau | Implémente RDMA sur Ethernet (RoCEv1 : couche de liaison ; RoCEv2 : couche de transport) |
| Technologie clé | – Protocole et architecture réseau InfiniBand – Interface de programmation des verbes | – Implémentation basée sur UDP/IP – Déchargement matériel (RoCEv2) pour réduire l'utilisation du processeur – Routage IP pour l’évolutivité |
| Avantages | – Bande passante plus élevée et latence plus faible – Contrôle de flux basé sur le crédit garantissant la stabilité des données | - Rentable – Compatible avec Ethernet standard – Prend en charge le déploiement à grande échelle |
| Inconvénients | – Évolutivité limitée – Nécessite des cartes réseau et des commutateurs spécialisés | – Des défis de mise en œuvre subsistent – Nécessite des cartes réseau compatibles RoCE |
| Coût | Supérieur (cartes réseau/commutateurs IB dédiés ; les coûts de câblage dépassent ceux d'Ethernet) | Inférieur (utilise des commutateurs Ethernet standard ; économique) |
| Cas d'utilisation | HPC, traitement parallèle à grande échelle, formation à l'IA | Communication interne du centre de données, fournisseurs de services cloud |
| Principaux fournisseurs | NVIDIA (fournisseur principal) | Prise en charge multi-fournisseurs (par exemple, Huawei, H3C, Inspur, Ruijie en Chine) |
- RoCE : RoCEv2, basé sur la couche UDP d'Ethernet, introduit les protocoles IP pour l'évolutivité et utilise le déchargement matériel pour réduire l'utilisation du processeur. Bien que légèrement moins performant qu'InfiniBand, RoCEv2 est économique, ce qui le rend idéal pour les communications des centres de données et les services cloud.
RDMA réduit la latence de communication entre cartes
Dans l'entraînement de l'IA distribuée, la réduction de la latence de communication inter-cartes est essentielle pour améliorer les taux d'accélération. Le temps de calcul total inclut le calcul sur une seule carte et la communication inter-cartes, le RDMA (via InfiniBand ou RoCEv2) minimisant la latence en contournant les piles de protocoles du noyau. Les tests en laboratoire montrent que le RDMA réduit la latence de bout en bout de 50 µs (TCP/IP) à 5 µs (RoCEv2) ou 2 µs (InfiniBand) dans les scénarios à saut unique.
Ethernet vs. InfiniBand : atouts et tendances
- InfiniBand contre RoCEv2InfiniBand prend en charge les clusters GPU à grande échelle (jusqu'à 10,000 2 cartes) avec une dégradation minimale des performances et une latence inférieure à celle de RoCEv70, mais son coût est plus élevé, NVIDIA dominant plus de 2 % du marché. RoCEv3 offre une compatibilité plus étendue et des coûts réduits, prenant en charge les réseaux RDMA et Ethernet traditionnels, avec des fournisseurs comme HXNUMXC et Huawei en tête du marché.
- L'essor d'Ethernet : selon le groupe Dell'Oro, les dépenses en commutateurs pour les réseaux back-end d'IA dépasseront les 100 milliards de dollars entre 2025 et 2029. Ethernet gagne du terrain dans les clusters d'IA à grande échelle, avec des déploiements comme Colossus de xAI qui l'adoptent. D'ici 2027, Ethernet devrait dépasser InfiniBand en termes de parts de marché.
- NVIDIA lance Ethernet : en juillet 2023, l'Ultra Ethernet Consortium (UEC), composé d'AMD, Arista, Broadcom, Cisco, Meta et Microsoft, a été créé pour développer des solutions de réseau IA basées sur Ethernet. NVIDIA l'a rejoint en juillet 2024, avec sa plateforme Spectrum-X qui multiplie par 1.6 les performances des réseaux IA par rapport à l'Ethernet traditionnel. NVIDIA prévoit des mises à jour annuelles de Spectrum-X pour améliorer encore les performances Ethernet IA.
Produits associés:
-
 Module émetteur-récepteur optique QSFP-DD-400G-SR8 400G QSFP-DD SR8 PAM4 850nm 100m MTP / MPO OM3 FEC
$149.00
Module émetteur-récepteur optique QSFP-DD-400G-SR8 400G QSFP-DD SR8 PAM4 850nm 100m MTP / MPO OM3 FEC
$149.00
-
 Module émetteur-récepteur optique QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310nm 500m MTP / MPO SMF FEC
$400.00
Module émetteur-récepteur optique QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310nm 500m MTP / MPO SMF FEC
$400.00
-
 Module émetteur-récepteur optique QSFP-DD-400G-SR4 QSFP-DD 400G SR4 PAM4 850nm 100m MTP/MPO-12 OM4 FEC
$450.00
Module émetteur-récepteur optique QSFP-DD-400G-SR4 QSFP-DD 400G SR4 PAM4 850nm 100m MTP/MPO-12 OM4 FEC
$450.00
-
 Module émetteur-récepteur optique QSFP-DD-400G-FR4 400G QSFP-DD FR4 PAM4 CWDM4 2 km LC SMF FEC
$500.00
Module émetteur-récepteur optique QSFP-DD-400G-FR4 400G QSFP-DD FR4 PAM4 CWDM4 2 km LC SMF FEC
$500.00
-
 Module émetteur-récepteur optique QSFP-DD-400G-XDR4 400G QSFP-DD XDR4 PAM4 1310nm 2km MTP/MPO-12 SMF FEC
$580.00
Module émetteur-récepteur optique QSFP-DD-400G-XDR4 400G QSFP-DD XDR4 PAM4 1310nm 2km MTP/MPO-12 SMF FEC
$580.00
-
 Module émetteur-récepteur optique QSFP-DD-400G-LR4 400G QSFP-DD LR4 PAM4 CWDM4 10 km LC SMF FEC
$600.00
Module émetteur-récepteur optique QSFP-DD-400G-LR4 400G QSFP-DD LR4 PAM4 CWDM4 10 km LC SMF FEC
$600.00
-
 QDD-4X100G-FR-Si QSFP-DD 4x100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS3.0 Module émetteur-récepteur optique photonique en silicium
$650.00
QDD-4X100G-FR-Si QSFP-DD 4x100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS3.0 Module émetteur-récepteur optique photonique en silicium
$650.00
-
 QDD-4X100G-FR-4Si QSFP-DD 4x100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS4.0 Module émetteur-récepteur optique photonique en silicium
$750.00
QDD-4X100G-FR-4Si QSFP-DD 4x100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS4.0 Module émetteur-récepteur optique photonique en silicium
$750.00
-
 QSFP-DD-400G-SR4.2 400Gb/s QSFP-DD SR4 BiDi PAM4 850nm/910nm 100m/150m OM4/OM5 MMF MPO-12 FEC Module émetteur-récepteur optique
$900.00
QSFP-DD-400G-SR4.2 400Gb/s QSFP-DD SR4 BiDi PAM4 850nm/910nm 100m/150m OM4/OM5 MMF MPO-12 FEC Module émetteur-récepteur optique
$900.00
-
 Arista Q112-400G-SR4 Compatible 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC Module émetteur-récepteur optique
$450.00
Arista Q112-400G-SR4 Compatible 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC Module émetteur-récepteur optique
$450.00
-
 Cisco Q112-400G-DR4 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 avec Module émetteur-récepteur optique FEC
$650.00
Cisco Q112-400G-DR4 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 avec Module émetteur-récepteur optique FEC
$650.00
-
 OSFP-800G-DR8D-FLT 800G-DR8 OSFP Plat Top PAM4 1310nm 500m DOM Double MTP/MPO-12 SMF Module Émetteur-Récepteur Optique
$1199.00
OSFP-800G-DR8D-FLT 800G-DR8 OSFP Plat Top PAM4 1310nm 500m DOM Double MTP/MPO-12 SMF Module Émetteur-Récepteur Optique
$1199.00
-
 OSFP-800G-SR8D-FLT OSFP 8x100G SR8 Plat Top PAM4 850nm 100m DOM Double MPO-12 MMF Module Émetteur-Récepteur Optique
$650.00
OSFP-800G-SR8D-FLT OSFP 8x100G SR8 Plat Top PAM4 850nm 100m DOM Double MPO-12 MMF Module Émetteur-Récepteur Optique
$650.00
-
 OSFP-800G-SR8D OSFP 8x100G SR8 PAM4 850nm 100m DOM double module émetteur-récepteur optique MPO-12 MMF
$650.00
OSFP-800G-SR8D OSFP 8x100G SR8 PAM4 850nm 100m DOM double module émetteur-récepteur optique MPO-12 MMF
$650.00
-
 OSFP-800G-DR8D 800G-DR8 OSFP PAM4 1310nm 500m DOM Module émetteur-récepteur optique double MTP/MPO-12 SMF
$850.00
OSFP-800G-DR8D 800G-DR8 OSFP PAM4 1310nm 500m DOM Module émetteur-récepteur optique double MTP/MPO-12 SMF
$850.00
-
 OSFP-800G-2FR4L OSFP 2x400G FR4 PAM4 1310nm 2km DOM double duplex LC SMF Module émetteur-récepteur optique
$1200.00
OSFP-800G-2FR4L OSFP 2x400G FR4 PAM4 1310nm 2km DOM double duplex LC SMF Module émetteur-récepteur optique
$1200.00