
Ces dernières années, l'essor mondial de l'intelligence artificielle (IA) a suscité une attention croissante au sein de la société. Un sujet de discussion récurrent autour de l'IA est le concept de clusters de calcul, l'un des trois piliers fondamentaux de l'IA, avec les algorithmes et les données. Ces clusters constituent la principale source de puissance de calcul, comparables à une gigantesque centrale électrique alimentant en permanence la révolution de l'IA.

Mais qu'est-ce qui constitue exactement un cluster de calcul d'IA ? Pourquoi sont-ils capables de fournir des performances de calcul aussi impressionnantes ? À quoi ressemble leur architecture interne et quelles technologies clés sont impliquées ?
Que sont les clusters de calcul d’IA ?
Comme son nom l'indique, un cluster de calcul d'IA est un système fournissant les ressources de calcul nécessaires à l'exécution des tâches d'IA. Un « cluster » désigne un ensemble d'appareils indépendants connectés via des réseaux haut débit pour fonctionner comme un système unifié.
Par définition, un cluster de calcul IA est un système informatique distribué formé par l'interconnexion de nombreux nœuds de calcul hautes performances (tels que des serveurs GPU ou TPU) sur des réseaux à haut débit.
Les charges de travail de l'IA peuvent généralement être divisées en deux grandes catégories : l'entraînement et l'inférence. Les tâches d'entraînement sont généralement plus gourmandes en ressources de calcul et complexes, nécessitant des ressources de calcul importantes. Les tâches d'inférence, en revanche, sont relativement légères et moins exigeantes.
Ces deux processus s'appuient fortement sur des opérations matricielles, notamment les convolutions et les multiplications de tenseurs, qui se prêtent naturellement à la parallélisation. Ainsi, les puces de calcul parallèle telles que les GPU, les NPU et les TPU sont devenues essentielles au traitement de l'IA. On les appelle collectivement puces d'IA.
Les puces d'IA sont les unités fondamentales du calcul de l'IA, mais une seule puce ne peut fonctionner indépendamment ; elle doit être intégrée à un circuit imprimé. Selon l'application :
Intégrés dans les cartes mères des téléphones portables ou intégrés dans les SoC, ils alimentent les capacités d'IA mobile.
Installés dans des modules pour appareils IoT, ils permettent l'intelligence périphérique pour des équipements tels que les véhicules autonomes, les bras robotisés et les caméras de surveillance.
Intégrés dans les stations de base, les routeurs et les passerelles, ils fournissent un calcul d'IA de pointe, généralement limité à l'inférence en raison de contraintes de taille et de puissance.
Pour les tâches de formation plus exigeantes, les systèmes doivent prendre en charge plusieurs puces d'IA. Pour ce faire, des cartes de calcul d'IA sont construites et plusieurs d'entre elles sont installées sur un seul serveur, transformant ainsi un serveur standard en serveur d'IA.

En général, un serveur d'IA héberge huit cartes de calcul, bien que certains modèles en prennent en charge jusqu'à vingt. Cependant, en raison des limitations de dissipation thermique et de puissance, toute extension supplémentaire devient impossible.
Grâce à cette configuration, la capacité de calcul augmente considérablement, permettant au serveur de gérer facilement l'inférence et même d'effectuer des tâches d'apprentissage à plus petite échelle. Le modèle DeepSeek, par exemple, a optimisé son architecture et ses algorithmes pour réduire considérablement les besoins de calcul. Par conséquent, de nombreux fournisseurs proposent désormais des racks intégrés « tout-en-un », composés de serveurs d'IA, de stockage et d'alimentations, qui prennent en charge le déploiement privé des modèles DeepSeek pour les entreprises.
Néanmoins, la puissance de calcul de ces configurations reste limitée. L'entraînement de modèles à très grande échelle, comportant des dizaines, voire des centaines de milliards de paramètres, requiert des ressources bien plus importantes. Cela conduit au développement de clusters de calcul d'IA à grande échelle, intégrant un nombre encore plus important de puces d'IA.
Des termes comme « échelle 10 100 » ou « échelle 10,000 100,000 » désignent des clusters comprenant XNUMX XNUMX ou XNUMX XNUMX cartes de calcul d'IA. Pour y parvenir, deux stratégies fondamentales sont employées : le scale-up (ajout de matériel plus puissant) et le scale-out (augmentation du nombre de systèmes interconnectés).
Qu'est-ce que Scale Up ?
En informatique, le terme « échelle » désigne l'expansion des ressources système. Ce concept est particulièrement familier aux personnes expérimentées en cloud computing.
La mise à l'échelle, également connue sous le nom de mise à l'échelle verticale, consiste à augmenter les ressources d'un seul nœud, par exemple en ajoutant plus de puissance de calcul, de mémoire ou de cartes accélératrices d'IA à un serveur.
La mise à l'échelle horizontale, ou scale-out, signifie étendre un système en ajoutant davantage de nœuds, en connectant plusieurs serveurs ou périphériques via un réseau.
Dans le cloud computing, les concepts s'étendent également au Scale Down (réduction des ressources d'un nœud) et au Scale In (réduction du nombre de nœuds).
Nous avons expliqué précédemment que l'intégration de plusieurs cartes accélératrices d'IA dans un serveur constitue une forme de Scale Up, chaque serveur agissant comme un nœud unique. En interconnectant plusieurs serveurs via des réseaux haut débit, nous atteignons le Scale Out.
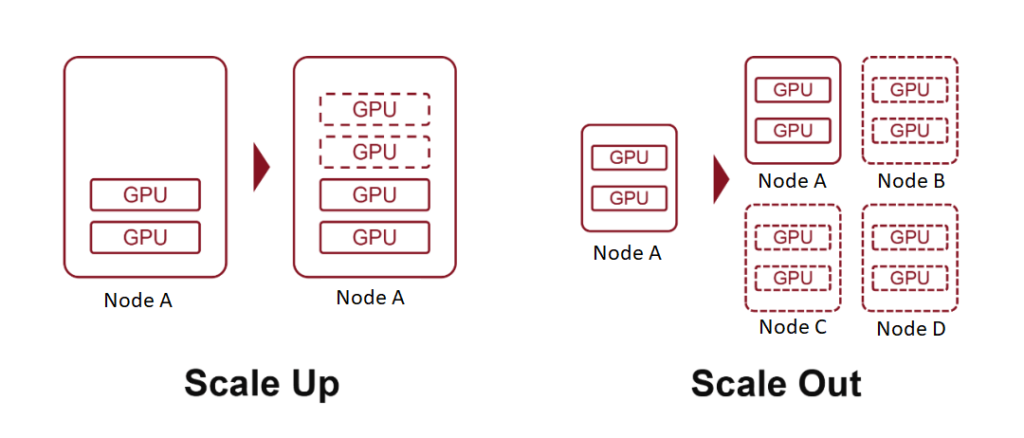
La principale distinction entre ces deux systèmes réside dans la bande passante de communication entre les puces d’IA :
Scale Up implique des connexions de nœuds internes, offrant une vitesse plus élevée, une latence plus faible et des performances plus élevées.
Historiquement, les communications internes des ordinateurs reposaient sur le protocole PCIe, développé à la fin du XXe siècle, lors de l'essor de l'informatique personnelle. Bien que le PCIe ait connu plusieurs mises à niveau, son évolution a été lente et insuffisante pour les charges de travail de l'IA moderne.
Pour surmonter ces limitations, NVIDIA a lancé son protocole de bus propriétaire NVLINK en 2014, permettant une communication point à point entre les GPU. NVLINK offre une vitesse bien supérieure et une latence nettement inférieure à celle du PCIe.
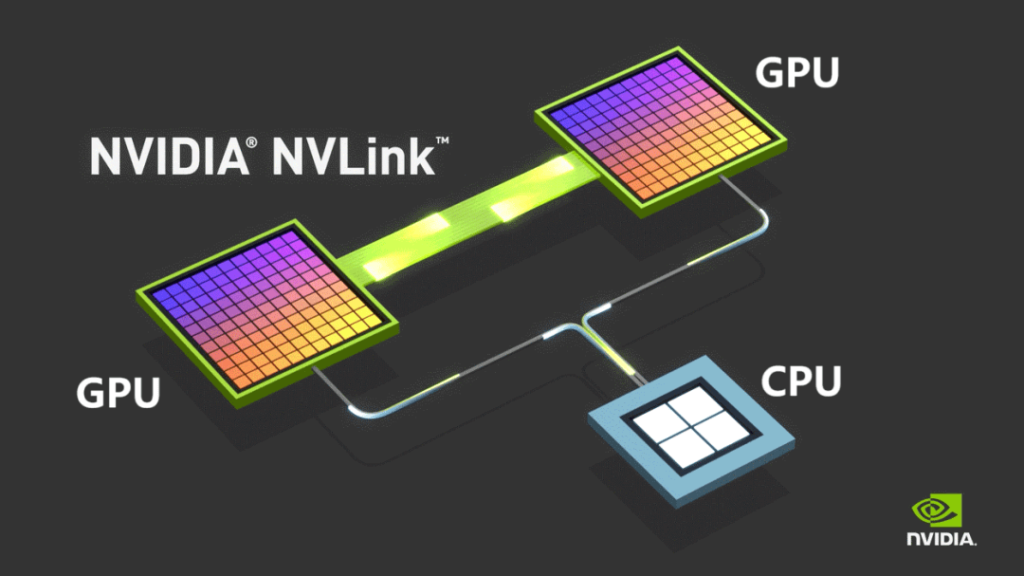
Initialement utilisé uniquement pour la communication intra-machine, NVIDIA a lancé NVSwitch en 2022, une puce de commutation indépendante conçue pour permettre une connectivité GPU haut débit entre serveurs. Cette innovation a redéfini le concept de nœud, permettant à plusieurs serveurs et périphériques réseau de fonctionner collectivement au sein d'un domaine à large bande passante (HBD).
NVIDIA qualifie de supernœuds ces systèmes, où plus de 16 GPU sont interconnectés avec une bande passante ultra-élevée.
Au fil du temps, NVLINK a évolué vers sa cinquième génération. Chaque GPU prend désormais en charge jusqu'à 18 connexions NVLINK, et la bande passante totale du GPU Blackwell atteint 1800 6 Go/s, dépassant largement celle du PCIe GenXNUMX.
En mars 2024, NVIDIA a dévoilé le NVL72, un boîtier refroidi par liquide intégrant 36 processeurs Grace et 72 GPU Blackwell. Il offre jusqu'à 720 PFLOPS de performances d'entraînement ou 1440 XNUMX PFLOPS d'inférence, consolidant ainsi le leadership de NVIDIA dans l'écosystème informatique de l'IA, grâce à son matériel GPU populaire et à la pile logicielle CUDA.

Avec l'adoption croissante de l'IA, de nombreuses autres entreprises ont développé leurs propres puces d'IA. En raison du caractère propriétaire de NVLINK, ces entreprises ont dû concevoir des architectures de clusters de calcul alternatives.
AMD, un concurrent majeur, a introduit UA LINK.
Les acteurs nationaux en Chine, tels que Tencent, Alibaba et China Mobile, ont été les fers de lance d’initiatives ouvertes comme ETH-X, ALS et OISA.
Une autre avancée notable est le protocole UB (Unified Bus) de Huawei, une technologie propriétaire développée pour soutenir l'écosystème de puces d'IA Ascend. Les puces Huawei, comme l'Ascend 910C, ont considérablement évolué ces dernières années.
En avril 2025, Huawei a lancé le supernœud CloudMatrix384, intégrant 384 cartes accélératrices d'IA Ascend 910C et atteignant jusqu'à 300 PFLOPS de performances de calcul BF16 denses, soit près du double de celles du système GB200 NVL72 de NVIDIA.
CloudMatrix384 exploite la technologie UB et se compose de trois plans réseau distincts :
- Avion UB
- Plan RDMA (accès direct à la mémoire à distance)
- Plan VPC (Virtual Private Cloud)
Ces plans complémentaires permettent une communication inter-cartes exceptionnelle et améliorent considérablement la puissance de calcul globale au sein du supernœud.
En raison de contraintes d'espace, nous explorerons les détails techniques de ces avions séparément dans une discussion ultérieure.
Un dernier point : en réponse à la pression croissante exercée par les normes ouvertes, NVIDIA a récemment annoncé son initiative NVLink Fusion, offrant l'accès à sa technologie NVLink à huit partenaires internationaux. Cette initiative vise à les aider à créer des systèmes d'IA personnalisés grâce à l'interconnectivité multipuce. Cependant, selon certains médias, les composants clés de NVLink restent propriétaires, ce qui suggère que NVIDIA reste encore quelque peu réservé quant à son ouverture.
Qu'est-ce que le Scale Out ?
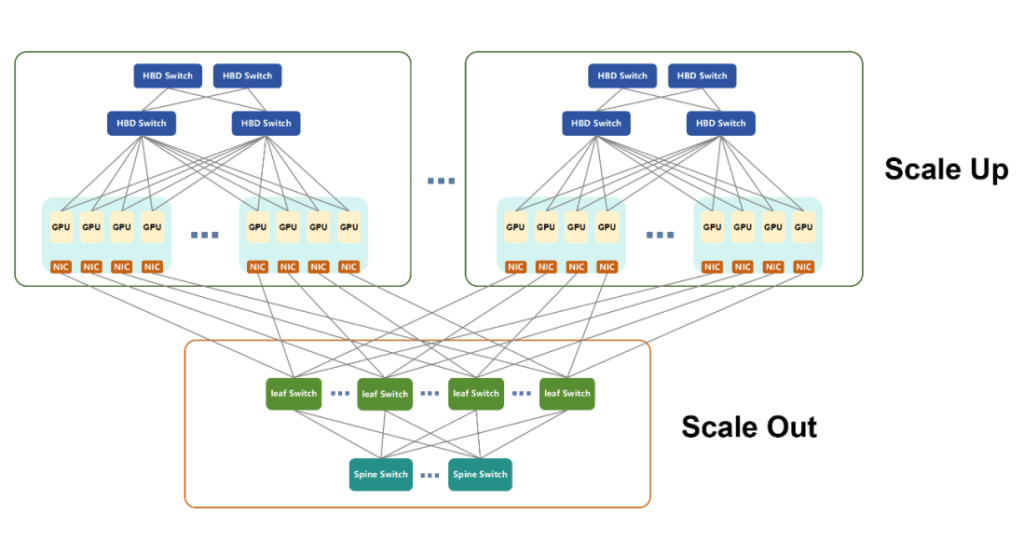
Le Scale Out désigne l'expansion horizontale des systèmes informatiques et s'apparente fortement aux réseaux de communication de données traditionnels. Les technologies couramment utilisées pour connecter des serveurs conventionnels, telles que l'architecture Fat Tree, la topologie réseau Spine-Leaf, les protocoles TCP/IP et Ethernet, constituent le fondement de l'infrastructure Scale Out.
Évolution pour répondre aux exigences de l'IA
Face aux exigences croissantes des charges de travail d'IA, les technologies réseau traditionnelles ont nécessité des améliorations substantielles pour répondre aux critères de performance. Actuellement, les deux technologies réseau dominantes pour le Scale Out sont :
- InfiniBand (IB)
- RoCEv2 (RDMA sur Ethernet convergé version 2)
Les deux sont basés sur le protocole RDMA (Remote Direct Memory Access), offrant des taux de transfert de données plus élevés, une latence plus faible et des capacités d'équilibrage de charge supérieures par rapport à l'Ethernet traditionnel.
InfiniBand contre RoCEv2
- InfiniBand a été initialement conçu pour remplacer le PCIe à des fins d'interconnexion. Bien que son adoption ait fluctué au fil du temps, il a finalement été acquis par NVIDIA lors du rachat de Mellanox. Aujourd'hui, IB est la propriété de NVIDIA et joue un rôle clé dans son infrastructure de calcul. Malgré ses excellentes performances, son prix est élevé.
- RoCEv2, quant à lui, est une norme ouverte développée pour contrebalancer la domination d'IB sur le marché. Elle fusionne le RDMA avec l'Ethernet conventionnel, offrant ainsi une meilleure rentabilité et réduisant progressivement l'écart de performance avec InfiniBand.
Contrairement aux normes fragmentées observées dans les implémentations Scale Up, Scale Out est largement unifié sous RoCEv2, en raison de l'accent mis sur la compatibilité inter-nœuds, plutôt que sur un couplage étroit avec les produits au niveau de la puce.
Différences de performances : évolutivité verticale et horizontale
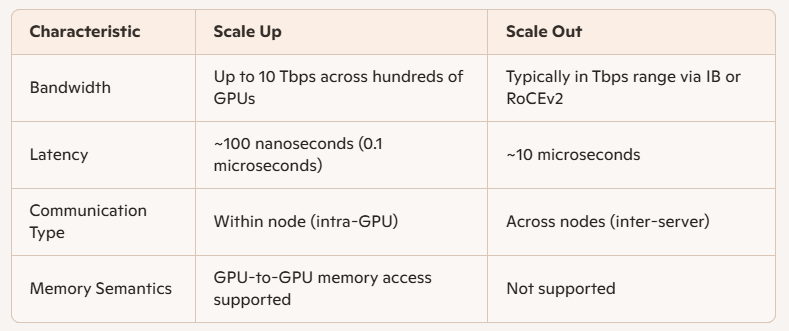
Les principales différences techniques entre Scale Up et Scale Out résident dans la bande passante et la latence :

Application à la formation en IA
La formation de l’IA implique plusieurs formes de calcul parallèle :
- TP (Parallélisme Tensoriel)
- EP (Parallélisme Expert)
- PP (Parallélisme de pipeline)
- DP (parallélisme des données)
Généralement:
- PP et DP impliquent des charges de communication plus petites et sont gérés via Scale Out.
- TP et EP, qui nécessitent un échange de données plus important, sont mieux pris en charge par Scale Up au sein des supernœuds.
Avantages de la mise à l'échelle dans la conception de réseaux
Les supernœuds, basés sur l'architecture Scale Up, sont connectés via des bus internes à haut débit et offrent un support efficace pour le calcul parallèle, l'échange de paramètres GPU et la synchronisation des données. Ils permettent également un accès direct à la mémoire entre les GPU, une fonctionnalité absente de l'architecture Scale Out.
Du point de vue du déploiement et de la maintenance :
- Les domaines à bande passante élevée (HBD) plus grands simplifient le réseau Scale Out.
- Les systèmes Scale Up pré-intégrés réduisent la complexité, raccourcissent le temps de déploiement et facilitent les opérations à long terme.
Cependant, le Scale Up ne peut pas s'étendre à l'infini en raison de contraintes de coût. L'échelle optimale dépend de scénarios d'utilisation spécifiques.
Un avenir unifié ?
En fin de compte, le Scale Up et le Scale Out représentent un compromis entre performance et coût. Avec l'évolution technologique, la frontière entre les deux devrait s'estomper. Les normes ouvertes de Scale Up émergentes, comme ETH-X, basées sur Ethernet, offrent des indicateurs de performance prometteurs :
- Capacité de la puce de commutation : jusqu'à 51.2 Tbps
- Vitesse SerDes : jusqu'à 112 Gbit/s
- Latence : aussi faible que 200 nanosecondes
Étant donné que Scale Out utilise également Ethernet, cette convergence laisse entrevoir une architecture unifiée, où une norme unique pourrait sous-tendre les deux modèles d’expansion dans les futurs écosystèmes informatiques.
Tendances dans le développement des clusters de calcul d'IA
Alors que le domaine de l'intelligence artificielle (IA) continue de se développer, les clusters de calcul d'IA évoluent selon plusieurs trajectoires clés :
Répartition géographique des infrastructures physiques
Les clusters d'IA évoluent vers des configurations contenant des dizaines, voire des centaines de milliers de cartes IA. Par exemple :
- Le rack NVL72 de NVIDIA intègre 72 puces.
- Le CM384 de Huawei déploie 384 puces sur 16 racks.
Pour construire un cluster de 100,000 384 cartes utilisant l'architecture CM432 de Huawei, il faudrait 384 unités CM165,888, soit 6,912 XNUMX puces et XNUMX XNUMX racks. Une telle envergure dépasse largement la capacité physique et électrique d'un seul centre de données.
Par conséquent, le secteur explore activement les déploiements de centres de données distribués pouvant fonctionner comme un cluster de calcul d'IA unifié. Ces architectures s'appuient fortement sur des technologies avancées de communication optique d'interconnexion de centres de données (DCI), qui doivent prendre en charge les transmissions longue distance, à haut débit et à faible latence. L'adoption d'innovations telles que la fibre optique à cœur creux devrait s'accélérer.
Personnalisation de l'architecture des nœuds
L'approche traditionnelle de création de clusters d'IA était souvent axée sur la maximisation du nombre de puces. Cependant, l'accent est de plus en plus mis sur une conception architecturale approfondie, au-delà du simple volume.
Les tendances émergentes incluent la mise en commun de ressources informatiques (GPU, NPU, CPU, mémoire et stockage) pour créer des clusters hautement adaptables adaptés aux exigences des modèles d'IA à grande échelle, y compris des architectures comme Mixture of Experts (MoE).
En bref, fournir des puces nues ne suffit plus. Des conceptions sur mesure, adaptées à chaque scénario, sont de plus en plus nécessaires pour garantir des performances et une efficacité optimales.
Opérations et maintenance intelligentes
L'entraînement de modèles d'IA à grande échelle est notoirement sujet aux erreurs, des pannes pouvant survenir en quelques heures seulement. Chaque panne nécessite un nouvel entraînement, ce qui allonge les délais de développement et augmente les coûts opérationnels.
Pour atténuer ces risques, les organisations privilégient la fiabilité et la stabilité de leurs systèmes en intégrant des outils d'exploitation et de maintenance intelligents. Ces systèmes peuvent :
- Prédire les défauts potentiels
- Identifier le matériel sous-optimal ou en détérioration
- Activer le remplacement proactif des composants
De telles approches réduisent considérablement les taux de défaillance et les temps d’arrêt, renforçant ainsi la stabilité du cluster et améliorant efficacement la production informatique globale.
Efficacité énergétique et durabilité
Le calcul de l’IA exige une consommation d’énergie massive, ce qui incite les principaux fournisseurs à explorer des stratégies pour réduire la consommation d’énergie et accroître la dépendance aux sources d’énergie renouvelables.
Cette volonté de créer des clusters de calcul vert s'inscrit dans le cadre d'initiatives de développement durable plus larges, telles que la stratégie chinoise « Données de l'Est, Calcul de l'Ouest », qui vise à optimiser l'allocation d'énergie et à promouvoir le développement écologique à long terme de l'infrastructure de l'IA.
Produits associés:
-
 Module émetteur-récepteur optique QSFP-DD-400G-SR8 400G QSFP-DD SR8 PAM4 850nm 100m MTP / MPO OM3 FEC
$149.00
Module émetteur-récepteur optique QSFP-DD-400G-SR8 400G QSFP-DD SR8 PAM4 850nm 100m MTP / MPO OM3 FEC
$149.00
-
 Module émetteur-récepteur optique QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310nm 500m MTP / MPO SMF FEC
$400.00
Module émetteur-récepteur optique QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310nm 500m MTP / MPO SMF FEC
$400.00
-
 Module émetteur-récepteur optique QSFP-DD-400G-SR4 QSFP-DD 400G SR4 PAM4 850nm 100m MTP/MPO-12 OM4 FEC
$450.00
Module émetteur-récepteur optique QSFP-DD-400G-SR4 QSFP-DD 400G SR4 PAM4 850nm 100m MTP/MPO-12 OM4 FEC
$450.00
-
 Module émetteur-récepteur optique QSFP-DD-400G-FR4 400G QSFP-DD FR4 PAM4 CWDM4 2 km LC SMF FEC
$500.00
Module émetteur-récepteur optique QSFP-DD-400G-FR4 400G QSFP-DD FR4 PAM4 CWDM4 2 km LC SMF FEC
$500.00
-
 Module émetteur-récepteur optique QSFP-DD-400G-XDR4 400G QSFP-DD XDR4 PAM4 1310nm 2km MTP/MPO-12 SMF FEC
$580.00
Module émetteur-récepteur optique QSFP-DD-400G-XDR4 400G QSFP-DD XDR4 PAM4 1310nm 2km MTP/MPO-12 SMF FEC
$580.00
-
 Module émetteur-récepteur optique QSFP-DD-400G-LR4 400G QSFP-DD LR4 PAM4 CWDM4 10 km LC SMF FEC
$600.00
Module émetteur-récepteur optique QSFP-DD-400G-LR4 400G QSFP-DD LR4 PAM4 CWDM4 10 km LC SMF FEC
$600.00
-
 QDD-4X100G-FR-Si QSFP-DD 4x100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS3.0 Module émetteur-récepteur optique photonique en silicium
$650.00
QDD-4X100G-FR-Si QSFP-DD 4x100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS3.0 Module émetteur-récepteur optique photonique en silicium
$650.00
-
 QDD-4X100G-FR-4Si QSFP-DD 4x100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS4.0 Module émetteur-récepteur optique photonique en silicium
$750.00
QDD-4X100G-FR-4Si QSFP-DD 4x100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS4.0 Module émetteur-récepteur optique photonique en silicium
$750.00
-
 QSFP-DD-400G-SR4.2 400Gb/s QSFP-DD SR4 BiDi PAM4 850nm/910nm 100m/150m OM4/OM5 MMF MPO-12 FEC Module émetteur-récepteur optique
$900.00
QSFP-DD-400G-SR4.2 400Gb/s QSFP-DD SR4 BiDi PAM4 850nm/910nm 100m/150m OM4/OM5 MMF MPO-12 FEC Module émetteur-récepteur optique
$900.00
-
 Arista Q112-400G-SR4 Compatible 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC Module émetteur-récepteur optique
$450.00
Arista Q112-400G-SR4 Compatible 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC Module émetteur-récepteur optique
$450.00
-
 Cisco Q112-400G-DR4 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 avec Module émetteur-récepteur optique FEC
$650.00
Cisco Q112-400G-DR4 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 avec Module émetteur-récepteur optique FEC
$650.00
-
 OSFP-800G-DR8D-FLT 800G-DR8 OSFP Plat Top PAM4 1310nm 500m DOM Double MTP/MPO-12 SMF Module Émetteur-Récepteur Optique
$1199.00
OSFP-800G-DR8D-FLT 800G-DR8 OSFP Plat Top PAM4 1310nm 500m DOM Double MTP/MPO-12 SMF Module Émetteur-Récepteur Optique
$1199.00
-
 OSFP-800G-SR8D-FLT OSFP 8x100G SR8 Plat Top PAM4 850nm 100m DOM Double MPO-12 MMF Module Émetteur-Récepteur Optique
$650.00
OSFP-800G-SR8D-FLT OSFP 8x100G SR8 Plat Top PAM4 850nm 100m DOM Double MPO-12 MMF Module Émetteur-Récepteur Optique
$650.00
-
 OSFP-800G-SR8D OSFP 8x100G SR8 PAM4 850nm 100m DOM double module émetteur-récepteur optique MPO-12 MMF
$650.00
OSFP-800G-SR8D OSFP 8x100G SR8 PAM4 850nm 100m DOM double module émetteur-récepteur optique MPO-12 MMF
$650.00
-
 OSFP-800G-DR8D 800G-DR8 OSFP PAM4 1310nm 500m DOM Module émetteur-récepteur optique double MTP/MPO-12 SMF
$850.00
OSFP-800G-DR8D 800G-DR8 OSFP PAM4 1310nm 500m DOM Module émetteur-récepteur optique double MTP/MPO-12 SMF
$850.00
-
 OSFP-800G-2FR4L OSFP 2x400G FR4 PAM4 1310nm 2km DOM double duplex LC SMF Module émetteur-récepteur optique
$1200.00
OSFP-800G-2FR4L OSFP 2x400G FR4 PAM4 1310nm 2km DOM double duplex LC SMF Module émetteur-récepteur optique
$1200.00