
El “Super Bowl” de la industria de la IA ha comenzado y la estrella de hoy es Jensen Huang.
Emprendedores tecnológicos, desarrolladores, científicos, inversores, clientes de NVIDIA, socios y medios de comunicación de todo el mundo han acudido en masa a la pequeña ciudad de San José para ver al hombre de la chaqueta de cuero negra.
La conferencia magistral de Huang en el GTC 2025 comenzó a las 10:00 a. m., hora local, del 18 de marzo, pero a las 6:00 a. m., Abraham Gomez, fundador de Doges AI, ya había reservado el segundo lugar en la fila del SAP Center, con la esperanza de conseguir un asiento en primera fila. A las 8:00 a. m., la fila afuera se extendía más de un kilómetro.
Bill, director ejecutivo de la startup de generación musical Wondera, se sentó en primera fila con su propia chaqueta de cuero negra "como homenaje a Jensen". Si bien el público se mostró entusiasta, Huang adoptó un tono más moderado en comparación con la energía estelar del año pasado. Esta vez, su objetivo fue reafirmar la estrategia de NVIDIA, enfatizando repetidamente la "escalada" a lo largo de su discurso.
El año pasado, Huang declaró que «el futuro es generativo»; este año, afirmó que «la IA se encuentra en un punto de inflexión». Su discurso inaugural se centró en tres anuncios clave:
1. La GPU Blackwell entra en plena producción
“La demanda es increíble, y con razón: la IA se encuentra en un punto de inflexión”, afirmó Huang. Destacó la creciente necesidad de potencia de cálculo impulsada por sistemas de inferencia de IA y cargas de trabajo de entrenamiento de agentes.
2. Blackwell NVLink 72 con software Dynamo AI
La nueva plataforma ofrece un rendimiento de fábrica de IA 40 veces superior al de NVIDIA Hopper. «A medida que escalamos la IA, la inferencia dominará las cargas de trabajo durante la próxima década», explicó Huang. Al presentar Blackwell Ultra, retomó un dicho clásico: «Cuanto más compras, más ahorras. De hecho, aún mejor: cuanto más compras, más ganas».
3. Hoja de ruta anual de NVIDIA para la infraestructura de IA
La empresa describió tres pilares de infraestructura de IA: nube, empresa y robótica.
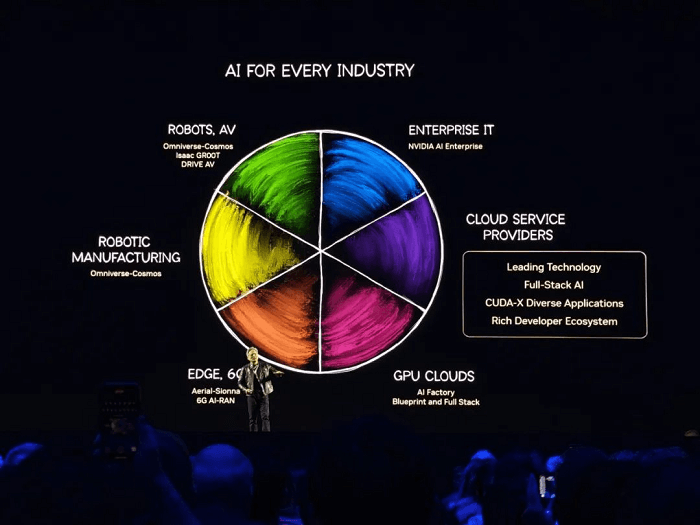
Huang también presentó dos nuevas GPU: la Blackwell Ultra GB300 (una Blackwell mejorada) y la arquitectura Vera Rubin de próxima generación con Rubin Ultra.
NVIDIA ha presentado dos nuevas GPU: la Blackwell Ultra GB300, una versión mejorada de la Blackwell del año pasado, y una arquitectura de chip completamente nueva llamada Vera Rubin, junto con Rubin Ultra.
La creencia inquebrantable de Jensen Huang en la Ley de Escalamiento tiene sus raíces en los avances logrados a través de varias generaciones de arquitecturas de chips.
Su discurso de apertura se centró principalmente en “Computación extrema para inferencia de IA a gran escala”.
En la inferencia de IA, escalar desde usuarios individuales hasta implementaciones a gran escala requiere encontrar el equilibrio óptimo entre rendimiento y rentabilidad. Los sistemas no solo deben garantizar respuestas rápidas a los usuarios, sino también maximizar el rendimiento general (tokens por segundo) mediante la mejora de las capacidades del hardware (p. ej., FLOPS, ancho de banda HBM) y la optimización del software (p. ej., arquitectura, algoritmos), lo que, en última instancia, libera el valor económico de la inferencia a gran escala.
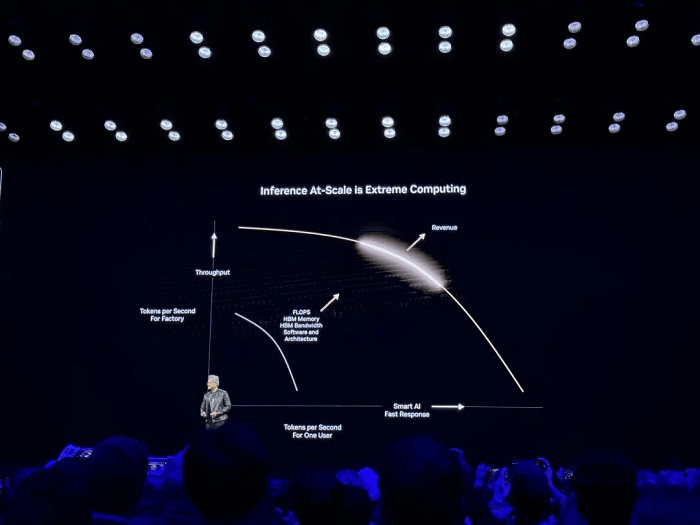
Al abordar las preocupaciones sobre la desaceleración de la Ley de Escalamiento, Jensen Huang expresó un punto de vista opuesto, afirmando que “los métodos y tecnologías de expansión emergentes están acelerando la mejora de la IA a un ritmo sin precedentes”.
Enfrentando una presión considerable, Huang parecía visiblemente tenso durante la transmisión en vivo, bebiendo agua con frecuencia durante los descansos y sonando ligeramente ronco al final de su presentación.
A medida que el mercado de la IA pasa del "entrenamiento" a la "inferencia", competidores como AMD, Intel, Google y Amazon están introduciendo chips de inferencia especializados para reducir la dependencia de NVIDIA. Mientras tanto, startups como Cerebras, Groq y Tenstorrent están acelerando el desarrollo de aceleradores de IA, y empresas como DeepSeek buscan minimizar la dependencia de las costosas GPU optimizando sus modelos. Estas dinámicas contribuyen a los desafíos que enfrenta Huang. Si bien NVIDIA domina más del 90% del mercado de entrenamiento, Huang está decidido a no ceder el mercado de la inferencia ante la creciente competencia. El banner de entrada al evento decía con audacia: "El futuro de la IA empieza aquí".

Los aspectos más destacados de la conferencia magistral de Jensen Huang, según lo resumió in situ “FiberMall”, incluyen:
El mundo ha malinterpretado la ley de escala
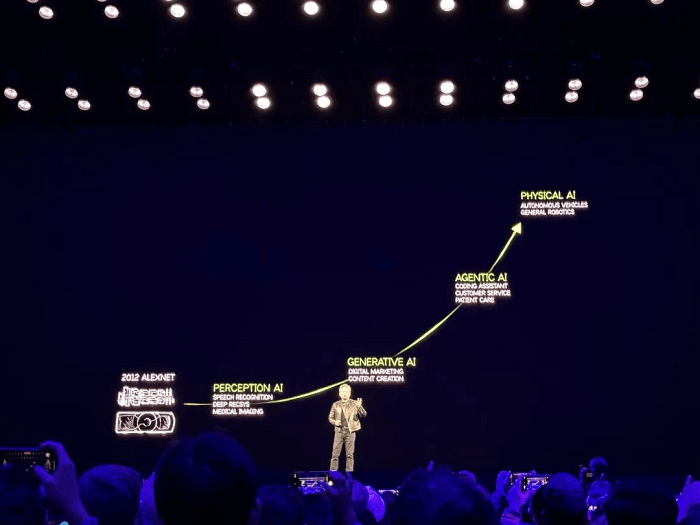
La IA ha representado una oportunidad transformadora para NVIDIA durante la última década, y Huang confía plenamente en su potencial. En esta GTC, revisó dos diapositivas de su presentación principal en el CES de enero:
La primera diapositiva describió las etapas del desarrollo de la IA: IA de percepción, IA generativa, IA agencial e IA física.
La segunda diapositiva describe las tres fases de la Ley de Escala: Escalamiento previo al entrenamiento, Escalamiento posterior al entrenamiento y Escalamiento en tiempo de prueba (Pensamiento a largo plazo).
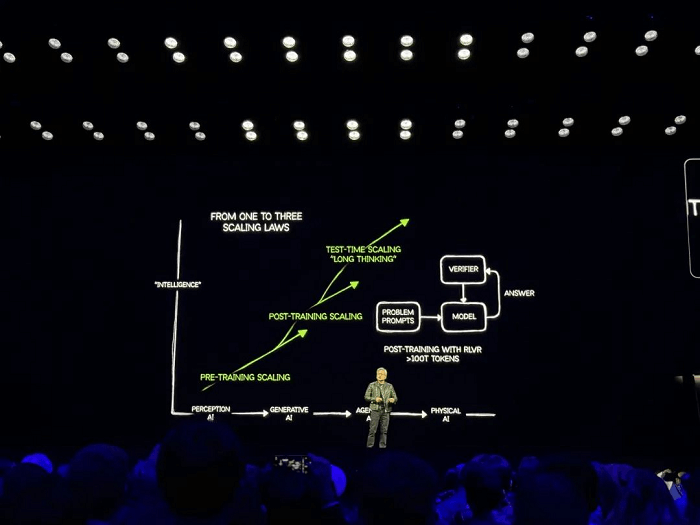
Huang ofreció una perspectiva que contrasta marcadamente con la opinión general, afirmando que las preocupaciones sobre la desaceleración de la Ley de Escala son infundadas. En su opinión, los métodos y tecnologías de expansión emergentes están impulsando el progreso de la IA a un ritmo sin precedentes.
Como firme defensor de la Ley de Escalabilidad, la convicción de Huang se basa en que los avances globales en IA están estrechamente vinculados al negocio de GPU de NVIDIA. A continuación, describió la evolución de la IA, capaz de razonar paso a paso, destacando el papel de la inferencia y el aprendizaje por refuerzo en el impulso de las demandas computacionales. A medida que la IA alcanza un punto de inflexión, los proveedores de servicios en la nube demandan cada vez más GPU, y Huang estima que el valor de la construcción de centros de datos alcanzará el billón de dólares.
Huang explicó que las bibliotecas de aceleración de GPU y los microservicios NVIDIA CUDA-X ya están disponibles en casi todas las industrias. En su visión, cada empresa operará dos fábricas en el futuro: una para producir bienes y otra para generar IA.

La IA se está expandiendo a diversos campos a nivel mundial, como la robótica, los vehículos autónomos, las fábricas y las redes inalámbricas. Jensen Huang destacó que una de las primeras aplicaciones de la IA fue en los vehículos autónomos, afirmando: «Las tecnologías que hemos desarrollado las utilizan casi todas las empresas de vehículos autónomos», tanto en centros de datos como en la industria automotriz.
Jensen anunció un hito significativo en la conducción autónoma: General Motors, el mayor fabricante de automóviles de Estados Unidos, está adoptando la IA, la simulación y la computación acelerada de NVIDIA para desarrollar sus vehículos, fábricas y robots de próxima generación. También presentó NVIDIA Halos, un sistema de seguridad integrado que combina las soluciones de seguridad de hardware y software de NVIDIA para automoción con la investigación de vanguardia en IA para la seguridad de los vehículos autónomos.

En cuanto a los centros de datos y la inferencia, Huang comentó que NVIDIA Blackwell ha entrado en producción a gran escala, presentando sistemas de numerosos socios del sector. Complacido con el potencial de Blackwell, explicó cómo permite una escalabilidad extrema: «Nuestro objetivo es abordar un desafío crítico, y esto es lo que llamamos inferencia».
Huang enfatizó que la inferencia implica la generación de tokens, un proceso esencial para las empresas. Estas fábricas de IA que generan tokens deben construirse con una eficiencia y un rendimiento excepcionales. Con los modelos de inferencia más recientes, capaces de resolver problemas cada vez más complejos, la demanda de tokens seguirá aumentando.
Para acelerar aún más la inferencia a gran escala, Huang anunció NVIDIA Dynamo, una plataforma de software de código abierto diseñada para optimizar y escalar modelos de inferencia en fábricas de IA. Al describirla como "esencialmente el sistema operativo para fábricas de IA", subrayó su potencial transformador.
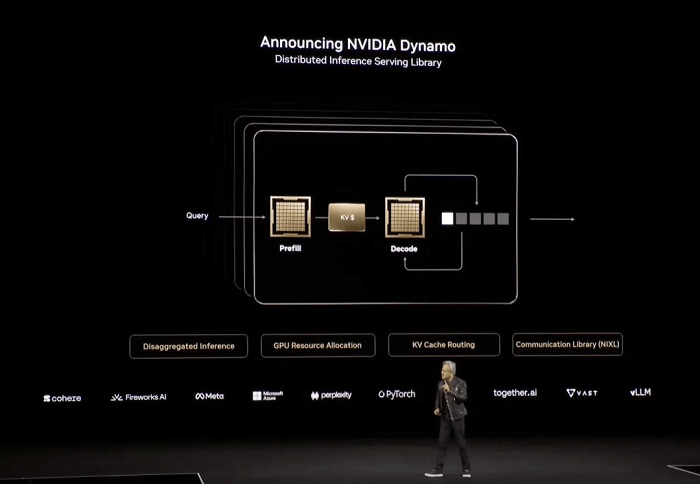
“Compra más, ahorra más, gana más”
NVIDIA también reveló dos nuevas GPU: la Blackwell Ultra GB300, una versión mejorada de la Blackwell del año pasado, y las arquitecturas de chip de próxima generación Vera Rubin y Rubin Ultra.
Blackwell Ultra GB300 estará disponible en la segunda mitad de este año.
Está previsto que Vera Rubin sea estrenada en la segunda mitad del próximo año.
Se espera que Rubin Ultra esté disponible a finales de 2027.
Además, Huang presentó la hoja de ruta para los próximos chips. La arquitectura para la generación posterior a Rubin se ha denominado Feynman y se prevé que esté disponible en 2028. El nombre probablemente rinde homenaje al renombrado físico teórico Richard Feynman.
Continuando con la tradición de NVIDIA, cada arquitectura de GPU lleva el nombre de científicos destacados: Blackwell en honor al estadístico David Harold Blackwell, y Rubin en honor a Vera Rubin, la astrofísica pionera que confirmó la existencia de la materia oscura.
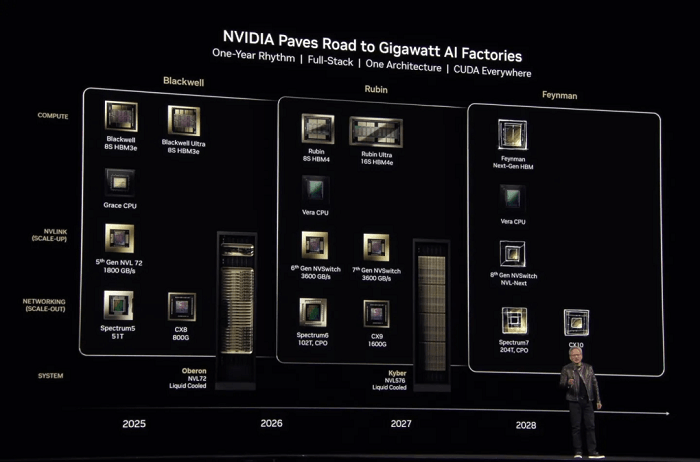
Durante la última década, NVIDIA ha lanzado 13 generaciones de arquitecturas de GPU, con un promedio de más de una nueva generación al año. Estas incluyen nombres icónicos como Tesla, Fermi, Kepler, Maxwell, Pascal, Turing, Ampere, Hopper y, más recientemente, Rubin. El compromiso de Huang con la Ley de Escalado ha sido un motor impulsor de estas innovaciones.
En cuanto al rendimiento, Blackwell Ultra ofrece mejoras sustanciales en comparación con Blackwell, incluyendo un aumento en la capacidad de memoria HBM3e de 192 GB a 288 GB. NVIDIA también ha comparado Blackwell Ultra con el chip H100 lanzado en 2022, destacando su capacidad para ofrecer un rendimiento de inferencia FP1.5 4 veces superior. Esto se traduce en una ventaja significativa: un clúster NVL72 con el modelo DeepSeek-R1 671B puede proporcionar respuestas interactivas en 10 segundos, en comparación con los 1.5 minutos del H100. Blackwell Ultra procesa 1,000 tokens por segundo, 10 veces más que el H100.

NVIDIA también ofrecerá el sistema de un solo rack GB300 NVL72, que incluye:
1.1 exaflops de FP4,
20 TB de memoria HBM,
40 TB de “memoria rápida”,
130 TB/s de ancho de banda NVLink y
14.4 TB/s de velocidad de red.
Reconociendo el impresionante rendimiento de Blackwell Ultra, Huang bromeó sobre su preocupación de que los clientes pudieran dejar de comprar el H100. Con humor, se describió a sí mismo como el "principal destructor de ingresos", admitiendo que, en casos limitados, los chips Hopper son "buenos", pero que tales situaciones son poco frecuentes. Concluyó con su frase clásica: "Compra más, ahorra más. Es incluso mejor que eso. Ahora, cuanto más compras, más ganas".
La arquitectura Rubin representa un avance revolucionario para NVIDIA. Jensen Huang enfatizó: «Básicamente, todo, excepto el rack, es completamente nuevo».
Rendimiento FP4 mejorado: Las GPU Rubin alcanzan 50 petaflops, superando los 20 petaflops de Blackwell. Rubin Ultra consta de un solo chip con dos GPU Rubin interconectadas, lo que proporciona 100 petaflops de rendimiento FP4 (el doble que Rubin) y casi cuadruplica la memoria, alcanzando 1 TB.
NVL576 Rubin Ultra Rack: ofrece 15 exaflops de inferencia FP4 y 5 exaflops de entrenamiento FP8, con un rendimiento 14 veces mayor que los racks Blackwell Ultra.

Huang también explicó la integración de la tecnología fotónica para escalar sistemas, incorporándola a los conmutadores de red fotónica de silicio Spectrum-X y Quantum-X de NVIDIA. Estas innovaciones combinan la comunicación electrónica y óptica, lo que permite a las fábricas de IA interconectar millones de GPU en diferentes ubicaciones, a la vez que reducen el consumo de energía y los costos.

Los conmutadores son excepcionalmente eficientes, logrando 3.5 veces más eficiencia energética, 63 veces más integridad de la señal, 10 veces más resiliencia de la red y una implementación más rápida en comparación con los métodos tradicionales.
Computadoras para la era de la IA
Más allá de los chips en la nube y los centros de datos, NVIDIA lanzó supercomputadoras de IA de escritorio basadas en la plataforma NVIDIA Grace Blackwell. Diseñadas para desarrolladores, investigadores, científicos de datos y estudiantes de IA, estas supercomputadoras permiten la creación de prototipos, el ajuste fino y la inferencia de modelos de gran tamaño a nivel de escritorio.

Los productos clave incluyen:
Supercomputadoras DGX: cuentan con la plataforma NVIDIA Grace Blackwell para capacidades de implementación local o en la nube inigualables.
Estación DGX: Una estación de trabajo de alto rendimiento equipada con Blackwell Ultra.

Serie de Inferencia Llama Nemotron: Una familia de modelos de IA de código abierto que ofrece razonamiento, codificación y toma de decisiones mejorados en varios pasos. Las mejoras de NVIDIA aumentan la precisión en un 20 %, quintuplican la velocidad de inferencia y optimizan los costos operativos. Empresas líderes como Microsoft, SAP y Accenture se están asociando con NVIDIA para desarrollar nuevos modelos de inferencia.
La era de la robótica de propósito general
Jensen Huang declaró que los robots serán la próxima industria de 10 billones de dólares, abordando así la escasez mundial de mano de obra, que se prevé alcance los 50 millones de trabajadores para finales de siglo. NVIDIA presentó Isaac GR00T N1, el primer modelo de inferencia y base de habilidades humanoides, abierto y totalmente personalizable, junto con un nuevo marco de generación de datos y aprendizaje robótico. Esto sienta las bases para la próxima frontera de la IA.
Además, NVIDIA lanzó el Modelo Fundacional Cosmos para el desarrollo de IA física. Este modelo abierto y personalizable otorga a los desarrolladores un control sin precedentes sobre la generación de mundos, creando conjuntos de datos vastos y sistemáticamente infinitos mediante la integración con Omniverse.
Huang también presentó Newton, un motor de física de código abierto para simulación robótica, codesarrollado con Google DeepMind y Disney Research. En un momento memorable, un robot en miniatura llamado "Blue", que ya había aparecido en el GTC del año pasado, volvió a aparecer en el escenario, deleitando al público.

La trayectoria continua de NVIDIA se ha centrado en encontrar aplicaciones para sus GPU, desde los avances en IA con AlexNet hace más de una década hasta el enfoque actual en la robótica y la IA física. ¿Darán frutos las aspiraciones de NVIDIA para la próxima década? El tiempo lo dirá.
Productos relacionados:
-
 NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m en OM3/50m en OM4 MTP/MPO-12 Módulo transceptor óptico FEC multimodo
$550.00
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m en OM3/50m en OM4 MTP/MPO-12 Módulo transceptor óptico FEC multimodo
$550.00
-
 NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Módulo transceptor óptico
$700.00
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Módulo transceptor óptico
$700.00
-
 Módulo transceptor óptico MTP/MPO-1 OM00 FEC compatible con NVIDIA MMA400Z400-NS112, 4 G, QSFP4, VR850, PAM50, 12 nm, 4 m
$550.00
Módulo transceptor óptico MTP/MPO-1 OM00 FEC compatible con NVIDIA MMA400Z400-NS112, 4 G, QSFP4, VR850, PAM50, 12 nm, 4 m
$550.00
-
 NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 con módulo transceptor óptico FEC
$700.00
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 con módulo transceptor óptico FEC
$700.00
-
 NVIDIA MMA4Z00-NS Compatible 800 Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Módulo transceptor óptico
$650.00
NVIDIA MMA4Z00-NS Compatible 800 Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Módulo transceptor óptico
$650.00
-
 NVIDIA MMA4Z00-NS-FLT Compatible 800 Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Módulo transceptor óptico
$650.00
NVIDIA MMA4Z00-NS-FLT Compatible 800 Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Módulo transceptor óptico
$650.00
-
 NVIDIA MMS4X00-NM Compatible 800 Gb/s Puerto doble OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 Módulo transceptor óptico SMF
$900.00
NVIDIA MMS4X00-NM Compatible 800 Gb/s Puerto doble OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 Módulo transceptor óptico SMF
$900.00
-
 NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Módulo transceptor óptico
$1199.00
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Módulo transceptor óptico
$1199.00
-
 Módulo transceptor óptico OSFP 4x50G FR2 PAM400 4nm 4km DOM Dual Duplex LC SMF compatible con NVIDIA MMS1310X2-NM
$1200.00
Módulo transceptor óptico OSFP 4x50G FR2 PAM400 4nm 4km DOM Dual Duplex LC SMF compatible con NVIDIA MMS1310X2-NM
$1200.00
-
 NVIDIA MCP7Y00-N001 Compatible 1 m (3 pies) 800 Gb OSFP de doble puerto a 2x400G OSFP InfiniBand NDR Breakout Cable de cobre de conexión directa
$160.00
NVIDIA MCP7Y00-N001 Compatible 1 m (3 pies) 800 Gb OSFP de doble puerto a 2x400G OSFP InfiniBand NDR Breakout Cable de cobre de conexión directa
$160.00
-
 NVIDIA MCA7J60-N004 Compatible 4m (13ft) 800G Twin-port OSFP a 2x400G OSFP InfiniBand NDR Breakout Cable de cobre activo
$800.00
NVIDIA MCA7J60-N004 Compatible 4m (13ft) 800G Twin-port OSFP a 2x400G OSFP InfiniBand NDR Breakout Cable de cobre activo
$800.00
-
 NVIDIA MCP7Y10-N001 Compatible con 1m (3 pies) 800G InfiniBand NDR OSFP de doble puerto a DAC de ruptura 2x400G QSFP112
$155.00
NVIDIA MCP7Y10-N001 Compatible con 1m (3 pies) 800G InfiniBand NDR OSFP de doble puerto a DAC de ruptura 2x400G QSFP112
$155.00
-
 NVIDIA MCP7Y50-N001 Compatible 1 m (3 pies) 800G InfiniBand NDR Twin-port OSFP a 4x200G OSFP Breakout DAC
$255.00
NVIDIA MCP7Y50-N001 Compatible 1 m (3 pies) 800G InfiniBand NDR Twin-port OSFP a 4x200G OSFP Breakout DAC
$255.00
-
 NVIDIA MCA7J70-N004 Compatible 4 m (13 pies) 800G InfiniBand NDR Twin-port OSFP a 4x200G OSFP Breakout ACC
$1100.00
NVIDIA MCA7J70-N004 Compatible 4 m (13 pies) 800G InfiniBand NDR Twin-port OSFP a 4x200G OSFP Breakout ACC
$1100.00
-
 NVIDIA MCA4J80-N003 Compatible 800G Doble puerto 2x400G OSFP a 2x400G OSFP InfiniBand NDR Cable de cobre activo
$600.00
NVIDIA MCA4J80-N003 Compatible 800G Doble puerto 2x400G OSFP a 2x400G OSFP InfiniBand NDR Cable de cobre activo
$600.00
-
 NVIDIA MCP4Y10-N002-FLT Compatible con 2 m (7 pies) 800 G de doble puerto 2 x 400 G OSFP a 2 x 400 G OSFP InfiniBand NDR DAC pasivo, parte superior plana en un extremo y parte superior plana en el otro
$300.00
NVIDIA MCP4Y10-N002-FLT Compatible con 2 m (7 pies) 800 G de doble puerto 2 x 400 G OSFP a 2 x 400 G OSFP InfiniBand NDR DAC pasivo, parte superior plana en un extremo y parte superior plana en el otro
$300.00
-
 NVIDIA MCP4Y10-N00A Compatible 0.5 m (1.6 pies) 800G Puerto doble 2x400G OSFP a 2x400G OSFP InfiniBand NDR Pasivo Cable de cobre de conexión directa
$105.00
NVIDIA MCP4Y10-N00A Compatible 0.5 m (1.6 pies) 800G Puerto doble 2x400G OSFP a 2x400G OSFP InfiniBand NDR Pasivo Cable de cobre de conexión directa
$105.00
-
 Cable de cobre activo InfiniBand NDR de 4 m (80 pies) compatible con NVIDIA MCA003J3-N10-FLT de doble puerto 800x2G OSFP a 400x2G OSFP, parte superior plana en un extremo y parte superior plana en el otro
$600.00
Cable de cobre activo InfiniBand NDR de 4 m (80 pies) compatible con NVIDIA MCA003J3-N10-FLT de doble puerto 800x2G OSFP a 400x2G OSFP, parte superior plana en un extremo y parte superior plana en el otro
$600.00