
A medida que la inteligencia artificial (IA) impulsa el crecimiento exponencial del volumen de datos y la complejidad de los modelos, la computación distribuida aprovecha los nodos interconectados para acelerar los procesos de entrenamiento. Los conmutadores de centros de datos desempeñan un papel fundamental para garantizar la entrega oportuna de mensajes entre nodos, especialmente en centros de datos a gran escala, donde la latencia de cola es crucial para gestionar cargas de trabajo competitivas. Además, la escalabilidad y la capacidad de gestionar numerosos nodos son esenciales para entrenar grandes modelos de IA y procesar conjuntos de datos masivos, lo que hace que los conmutadores de centros de datos sean indispensables para una conectividad de red y una transmisión de datos eficientes. Según IDC, el mercado mundial de conmutadores alcanzó los 308 2022 millones de dólares en 17, lo que refleja un crecimiento interanual del 4.6 %, con una tasa de crecimiento anual compuesta (TCAC) proyectada del 2022 % entre 2027 y 59.1. En China, el mercado de conmutadores se valoró en 9.5 7 millones de dólares, con un crecimiento del 9 %, con una TCAC prevista del XNUMX % al XNUMX % durante los próximos cinco años, superando el crecimiento mundial.
Clasificaciones principales de los conmutadores de centros de datos
Los switches de centros de datos se pueden clasificar según diversos criterios, como escenarios de aplicación, capas de red, tipos de gestión, modelos de red OSI, velocidades de puerto y estructuras físicas. Las clasificaciones incluyen:
- Por escenario de aplicación: conmutadores de campus, conmutadores de centros de datos
- Por capa de red: conmutadores de acceso, conmutadores de agregación, conmutadores de núcleo
- Por tipo de gestión: conmutadores no administrados, conmutadores administrados web, conmutadores completamente administrados
- Según el modelo de red OSI: conmutadores de capa 2, conmutadores de capa 3
- Por velocidad de puerto: conmutadores Fast Ethernet, conmutadores Gigabit Ethernet, conmutadores de 10 Gigabits, conmutadores multivelocidad
- Por estructura física: conmutadores fijos (caja), conmutadores modulares (chasis)
Chips de conmutación y métricas clave de rendimiento
Los conmutadores Ethernet para centros de datos incluyen componentes críticos como chips, placas de circuito impreso (PCB), módulos ópticos, conectores, componentes pasivos, carcasas, fuentes de alimentación y ventiladores. Los componentes principales incluyen chips de conmutador Ethernet y CPU, con elementos adicionales como capas físicas (PHY) y CPLD/FPGA. El chip de conmutador Ethernet, diseñado específicamente para la optimización de la red, gestiona el procesamiento de datos y el reenvío de paquetes, con rutas lógicas complejas para garantizar un manejo robusto de los datos. La CPU gestiona los inicios de sesión y las interacciones de protocolo, mientras que la capa física (PHY) procesa los datos de la capa física.
El rendimiento de los switches de centros de datos depende de métricas clave como el ancho de banda de la placa base, la tasa de reenvío de paquetes, la capacidad de conmutación, la velocidad de los puertos y la densidad de puertos. El ancho de banda de la placa base indica la capacidad de transferencia de datos de un switch; valores más altos indican un mejor rendimiento con cargas pesadas. Para el reenvío sin bloqueos, el ancho de banda de la placa base debe ser al menos igual a la capacidad de conmutación (calculada como número de puertos × velocidad de puerto × 2 en modo dúplex completo). Los switches de gama alta sin placa base dependen de las tasas de reenvío de paquetes. Una mayor velocidad de puerto indica una capacidad de procesamiento superior para escenarios de alto tráfico, mientras que una mayor densidad de puertos permite escalar redes más grandes al conectar más dispositivos.
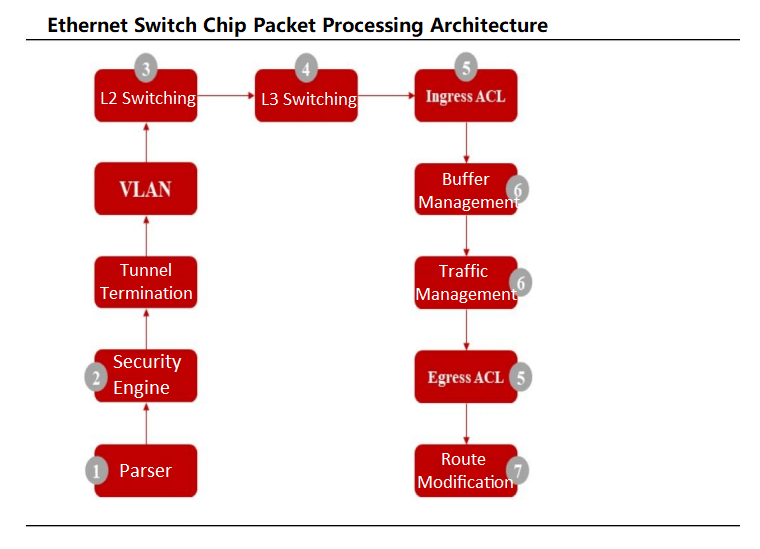
Los chips de conmutación Ethernet funcionan como ASIC especializados para conmutadores de centros de datos, a menudo integrando controladores MAC y chips PHY. Los paquetes de datos ingresan a través de puertos físicos, donde el analizador del chip analiza los campos para la clasificación del flujo. Tras las comprobaciones de seguridad, los paquetes se someten a conmutación de capa 2 o enrutamiento de capa 3, donde el clasificador de flujo los dirige a colas priorizadas según los estándares 802.1P o DSCP. Los programadores gestionan la priorización de las colas mediante algoritmos como Weighted Round Robin (WRR) antes de transmitir los paquetes.

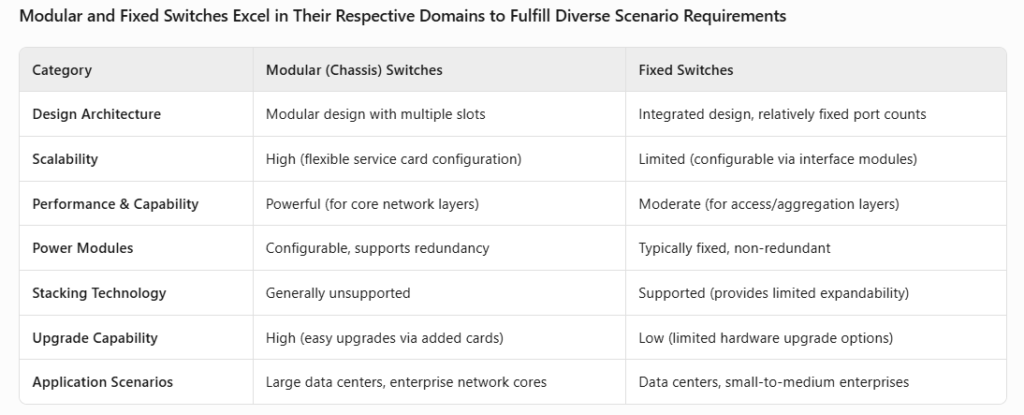
Físicamente, los switches de centros de datos pueden ser de chasis o fijos. Los switches de chasis presentan un diseño modular con ranuras para módulos de interfaz, control y conmutación, lo que ofrece alta flexibilidad y escalabilidad. Los switches fijos tienen diseños integrados con configuraciones de puertos fijos, aunque algunos admiten interfaces modulares. Las principales diferencias radican en la arquitectura interna y los escenarios de aplicación (uso de la capa OSI).
Evolución y avances tecnológicos en los conmutadores de centros de datos
De OEO a OOO: conmutadores totalmente ópticos para cargas de trabajo de IA
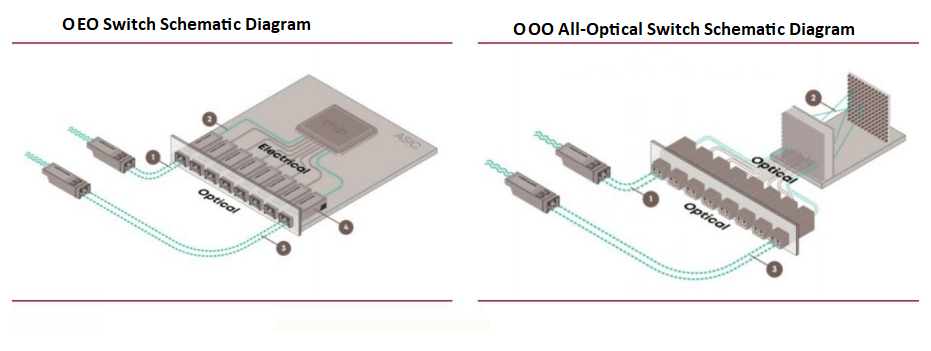
Los conmutadores actuales para centros de datos, basados en chips ASIC, funcionan como conmutadores de circuitos de paquetes ópticos a eléctricos a ópticos (OEO), que dependen de chips ASIC para el reenvío de paquetes principales. Estos conmutadores requieren conversiones óptico-eléctricas para la transmisión de señales. Sin embargo, están surgiendo conmutadores totalmente ópticos (OOO) para satisfacer las demandas computacionales impulsadas por la IA, reduciendo la sobrecarga de conversión y mejorando la eficiencia.
Un ejecutivo de NVIDIA se une a Lightmatter para impulsar la conmutación totalmente óptica
En julio de 2024, Simona Jankowski, vicepresidenta de NVIDIA, se incorporó a Lightmatter como directora financiera, lo que reflejó el enfoque de la compañía en las interconexiones ópticas. Con un valor de 4.4 millones de dólares, la tecnología Passage de Lightmatter aprovecha la fotónica para la interconexión de chips, utilizando guías de ondas en lugar de fibra óptica para ofrecer transmisión de datos paralela de alto ancho de banda para diversos núcleos de computación, lo que mejora significativamente el rendimiento de la red de IA.
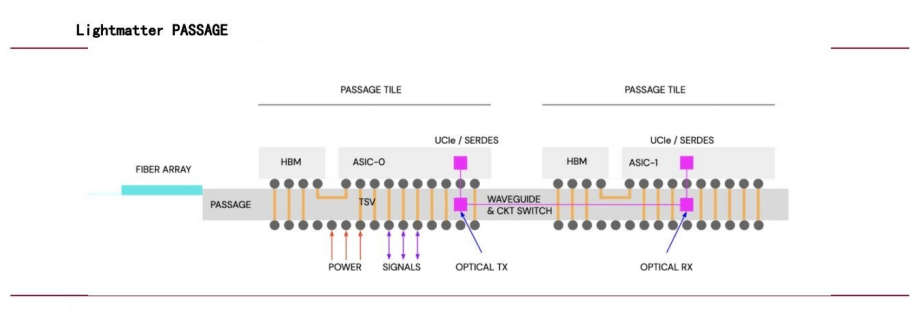
Implementación a gran escala de conmutadores OCS de Google
Las redes de centros de datos de Google priorizan las redes definidas por software (SDN), la topología Clos y los chips de conmutación de consumo. La topología Clos, una arquitectura multietapa sin bloqueos construida con chips de radix más pequeños, admite redes escalables esenciales para las cargas de trabajo de IA.
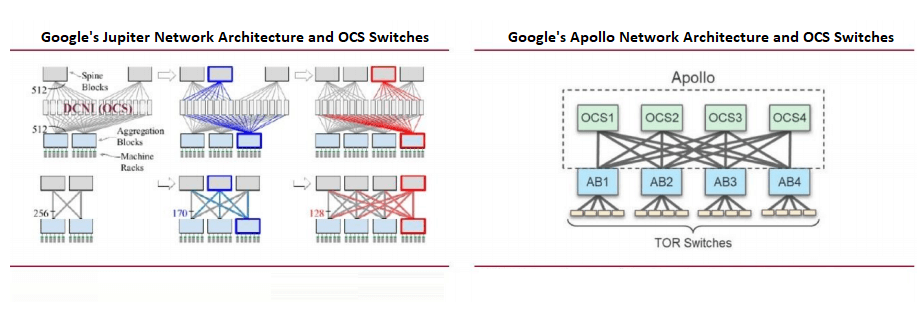
Google fue pionero en el uso a gran escala de conmutadores de circuitos ópticos (OCS) en su arquitectura Jupiter, integrando OCS basados en MEMS para reducir las conversiones ópticas a eléctricas. En OFC 2023, Google presentó su proyecto Apollo, que reemplaza los conmutadores de paquetes Ethernet (EPS) de la capa espinal con OCS para una mayor eficiencia.
Tecnologías y estándares clave para conmutadores de centros de datos
- RDMA: Habilitación de comunicaciones de baja latencia y alto rendimiento
El Acceso Directo a Memoria Remota (RDMA) permite una comunicación de red de alto rendimiento y baja latencia al evitar la intervención del sistema operativo. A diferencia del protocolo TCP/IP tradicional, que requiere múltiples copias de datos con un uso intensivo de la CPU, RDMA transfiere datos directamente entre las memorias de los ordenadores. En los conmutadores de centros de datos, RDMA se implementa mediante InfiniBand y RoCE (RDMA sobre Ethernet Convergente), con InfiniBand y RoCEv2 son las soluciones dominantes para los centros de datos de IA (AIDC).
- InfiniBand: Diseñado para computación de alto rendimiento (HPC) y centros de datos, InfiniBand ofrece alto ancho de banda, baja latencia, calidad de servicio (QoS) y escalabilidad. Su arquitectura canalizada, compatibilidad con RDMA y diseño de red conmutada lo hacen ideal para aplicaciones con uso intensivo de datos. Sin embargo, su alto costo limita su adopción en entornos HPC especializados.
Comparación de InfiniBand y RoCE
| categoría | InfiniBand | RoCE |
| Filosofía del diseño | Diseñado con RDMA en mente, redefiniendo las capas de enlace físico y de red | Implementa RDMA sobre Ethernet (RoCEv1: capa de enlace; RoCEv2: capa de transporte) |
| Tecnología clave | – Protocolo y arquitectura de red InfiniBand – Interfaz de programación de verbos | – Implementación basada en UDP/IP – Descarga de hardware (RoCEv2) para reducir la utilización de la CPU – Enrutamiento IP para escalabilidad |
| Ventajas | – Mayor ancho de banda y menor latencia – Control de flujo basado en créditos que garantiza la estabilidad de los datos | - Económico – Compatible con Ethernet estándar – Admite implementaciones a gran escala |
| Desventajas | – Escalabilidad limitada – Requiere NIC y conmutadores especializados | – Siguen existiendo desafíos de implementación – Requiere NIC compatibles con RoCE |
| Costo | Superior (NIC/conmutadores IB dedicados; los costos de cableado superan a los de Ethernet) | Inferior (utiliza conmutadores Ethernet estándar; económico) |
| Casos de uso | HPC, procesamiento paralelo a gran escala, entrenamiento de IA | Comunicación interna del centro de datos, proveedores de servicios en la nube |
| Proveedores principales | NVIDIA (proveedor principal) | Soporte de múltiples proveedores (por ejemplo, Huawei, H3C, Inspur, Ruijie en China) |
- RoCE: RoCEv2, basado en la capa UDP de Ethernet, introduce protocolos IP para mayor escalabilidad y utiliza la descarga de hardware para reducir el uso de la CPU. Si bien su rendimiento es ligeramente inferior al de InfiniBand, RoCEv2 es rentable, lo que lo hace ideal para comunicaciones de centros de datos y servicios en la nube.
RDMA reduce la latencia de comunicación entre tarjetas
En el entrenamiento distribuido de IA, reducir la latencia de la comunicación entre tarjetas es crucial para mejorar las tasas de aceleración. El tiempo total de cómputo incluye el cómputo con una sola tarjeta y la comunicación entre tarjetas, y RDMA (vía InfiniBand o RoCEv2) minimiza la latencia al omitir las pilas de protocolos del kernel. Las pruebas de laboratorio demuestran que RDMA reduce la latencia de extremo a extremo de 50 µs (TCP/IP) a 5 µs (RoCEv2) o 2 µs (InfiniBand) en escenarios de un solo salto.
Ethernet vs. InfiniBand: Fortalezas y tendencias
- InfiniBand frente a RoCEv2InfiniBand admite clústeres de GPU a gran escala (hasta 10,000 2 tarjetas) con una degradación mínima del rendimiento y una latencia menor que RoCEv70, pero tiene un coste mayor, ya que NVIDIA domina más del 2 % del mercado. RoCEv3 ofrece mayor compatibilidad y costes más bajos, compatible con RDMA y redes Ethernet tradicionales, con proveedores como HXNUMXC y Huawei a la cabeza del mercado.
- El creciente impulso de Ethernet: Según Dell'Oro Group, la inversión en switches para redes backend de IA superará los 100 2025 millones de dólares entre 2029 y 2027. Ethernet está ganando terreno en clústeres de IA a gran escala, con implementaciones como Colossus de xAI que lo adoptan. Para XNUMX, se espera que Ethernet supere a InfiniBand en cuota de mercado.
- Impulso Ethernet de NVIDIA: En julio de 2023, se formó el Consorcio Ultra Ethernet (UEC), que incluye a AMD, Arista, Broadcom, Cisco, Meta y Microsoft, para desarrollar soluciones de redes de IA basadas en Ethernet. NVIDIA se unió en julio de 2024, con su plataforma Spectrum-X, que multiplicó por 1.6 el rendimiento de la red de IA en comparación con Ethernet tradicional. NVIDIA planea actualizaciones anuales de Spectrum-X para mejorar aún más el rendimiento de Ethernet para IA.
Productos relacionados:
-
 Módulo transceptor óptico QSFP-DD-400G-SR8 400G QSFP-DD SR8 PAM4 850nm 100m MTP / MPO OM3 FEC
$149.00
Módulo transceptor óptico QSFP-DD-400G-SR8 400G QSFP-DD SR8 PAM4 850nm 100m MTP / MPO OM3 FEC
$149.00
-
 QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310nm 500m MTP / MPO SMF FEC Módulo transceptor óptico
$400.00
QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310nm 500m MTP / MPO SMF FEC Módulo transceptor óptico
$400.00
-
 QSFP-DD-400G-SR4 QSFP-DD 400G SR4 PAM4 850nm 100m MTP/MPO-12 OM4 FEC Módulo transceptor óptico
$450.00
QSFP-DD-400G-SR4 QSFP-DD 400G SR4 PAM4 850nm 100m MTP/MPO-12 OM4 FEC Módulo transceptor óptico
$450.00
-
 Módulo transceptor óptico QSFP-DD-400G-FR4 400G QSFP-DD FR4 PAM4 CWDM4 2km LC SMF FEC
$500.00
Módulo transceptor óptico QSFP-DD-400G-FR4 400G QSFP-DD FR4 PAM4 CWDM4 2km LC SMF FEC
$500.00
-
 QSFP-DD-400G-XDR4 400G QSFP-DD XDR4 PAM4 1310nm 2km MTP / MPO-12 SMF Módulo transceptor óptico FEC
$580.00
QSFP-DD-400G-XDR4 400G QSFP-DD XDR4 PAM4 1310nm 2km MTP / MPO-12 SMF Módulo transceptor óptico FEC
$580.00
-
 Módulo transceptor óptico QSFP-DD-400G-LR4 400G QSFP-DD LR4 PAM4 CWDM4 10km LC SMF FEC
$600.00
Módulo transceptor óptico QSFP-DD-400G-LR4 400G QSFP-DD LR4 PAM4 CWDM4 10km LC SMF FEC
$600.00
-
 QDD-4X100G-FR-Si QSFP-DD 4 x100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS3.0 Módulo transceptor óptico de fotónica de silicio
$650.00
QDD-4X100G-FR-Si QSFP-DD 4 x100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS3.0 Módulo transceptor óptico de fotónica de silicio
$650.00
-
 QDD-4X100G-FR-4Si QSFP-DD 4 x 100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS4.0 Módulo transceptor óptico de fotónica de silicio
$750.00
QDD-4X100G-FR-4Si QSFP-DD 4 x 100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS4.0 Módulo transceptor óptico de fotónica de silicio
$750.00
-
 QSFP-DD-400G-SR4.2 400 Gb/s QSFP-DD SR4 BiDi PAM4 850nm/910nm 100m/150m OM4/OM5 MMF MPO-12 Módulo transceptor óptico FEC
$900.00
QSFP-DD-400G-SR4.2 400 Gb/s QSFP-DD SR4 BiDi PAM4 850nm/910nm 100m/150m OM4/OM5 MMF MPO-12 Módulo transceptor óptico FEC
$900.00
-
 Arista Q112-400G-SR4 Compatible 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC Módulo transceptor óptico
$450.00
Arista Q112-400G-SR4 Compatible 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC Módulo transceptor óptico
$450.00
-
 Cisco Q112-400G-DR4 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 con módulo transceptor óptico FEC
$650.00
Cisco Q112-400G-DR4 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 con módulo transceptor óptico FEC
$650.00
-
 OSFP-800G-DR8D-FLT 800G-DR8 OSFP Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 Módulo transceptor óptico SMF
$1199.00
OSFP-800G-DR8D-FLT 800G-DR8 OSFP Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 Módulo transceptor óptico SMF
$1199.00
-
 OSFP-800G-SR8D-FLT OSFP 8x100G SR8 Flat Top PAM4 850nm 100m DOM Dual MPO-12 MMF Módulo transceptor óptico
$650.00
OSFP-800G-SR8D-FLT OSFP 8x100G SR8 Flat Top PAM4 850nm 100m DOM Dual MPO-12 MMF Módulo transceptor óptico
$650.00
-
 OSFP-800G-SR8D OSFP 8x100G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Módulo transceptor óptico
$650.00
OSFP-800G-SR8D OSFP 8x100G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Módulo transceptor óptico
$650.00
-
 OSFP-800G-DR8D 800G-DR8 OSFP PAM4 1310nm 500m DOM Dual MTP/MPO-12 Módulo transceptor óptico SMF
$850.00
OSFP-800G-DR8D 800G-DR8 OSFP PAM4 1310nm 500m DOM Dual MTP/MPO-12 Módulo transceptor óptico SMF
$850.00
-
 OSFP-800G-2FR4L OSFP 2x400G FR4 PAM4 1310nm 2km DOM Módulo transceptor óptico dúplex LC SMF
$1200.00
OSFP-800G-2FR4L OSFP 2x400G FR4 PAM4 1310nm 2km DOM Módulo transceptor óptico dúplex LC SMF
$1200.00