
En los últimos años, el auge global de la inteligencia artificial (IA) ha captado la atención de toda la sociedad. Un tema recurrente de debate en torno a la IA es el concepto de clústeres de cómputo, uno de los tres pilares fundamentales de la IA, junto con los algoritmos y los datos. Estos clústeres de cómputo sirven como la principal fuente de potencia computacional, como una gigantesca central eléctrica que impulsa continuamente la revolución de la IA.

Pero ¿qué constituye exactamente un clúster de cómputo de IA? ¿Por qué son capaces de ofrecer un rendimiento computacional tan elevado? ¿Cómo es su arquitectura interna y qué tecnologías clave intervienen?
¿Qué son los clústeres de computación de IA?
Como su nombre indica, un clúster de cómputo de IA es un sistema que proporciona los recursos computacionales necesarios para realizar tareas de IA. Un «clúster» se refiere a un grupo de dispositivos independientes conectados mediante redes de alta velocidad para funcionar como un sistema unificado.
Por definición, un clúster de computación de IA es un sistema de computación distribuida formado mediante la interconexión de numerosos nodos de computación de alto rendimiento (como servidores GPU o TPU) a través de redes de alta velocidad.
Las cargas de trabajo de IA se dividen generalmente en dos categorías principales: entrenamiento e inferencia. Las tareas de entrenamiento suelen ser más intensivas en computación y complejas, y requieren recursos computacionales considerables. Las tareas de inferencia, en cambio, son relativamente ligeras y menos exigentes.
Ambos procesos dependen en gran medida de operaciones matriciales, como convoluciones y multiplicaciones de tensores, que se prestan naturalmente a la paralelización. Por lo tanto, los chips de computación paralela, como las GPU, las NPU y las TPU, se han vuelto esenciales para el procesamiento de IA. En conjunto, se les conoce como chips de IA.
Los chips de IA son las unidades fundamentales de la computación de IA, pero un solo chip no puede funcionar de forma independiente; debe estar integrado en una placa de circuito. Según la aplicación:
Integrados en placas base de teléfonos móviles o en SoC, potencian las capacidades de inteligencia artificial móvil.
Instalados en módulos para dispositivos IoT, permiten inteligencia de borde para equipos como vehículos autónomos, brazos robóticos y cámaras de vigilancia.
Integrados en estaciones base, enrutadores y puertas de enlace, brindan computación de IA en el borde, generalmente limitada a la inferencia debido a restricciones de tamaño y energía.
Para tareas de entrenamiento más exigentes, los sistemas deben ser compatibles con múltiples chips de IA. Esto se logra construyendo placas de cómputo de IA e instalando varias en un solo servidor, transformando así un servidor estándar en un servidor de IA.

Normalmente, un servidor de IA alberga ocho tarjetas de cómputo, aunque algunos modelos admiten hasta veinte. Sin embargo, debido a la disipación de calor y las limitaciones de energía, una mayor expansión resulta impráctica.
Con esta configuración, la capacidad computacional aumenta significativamente, lo que permite al servidor gestionar fácilmente la inferencia e incluso realizar tareas de entrenamiento a menor escala. Un ejemplo es el modelo DeepSeek, que ha optimizado su arquitectura y algoritmos para reducir significativamente la demanda computacional. En consecuencia, muchos proveedores ofrecen ahora racks integrados "todo en uno" (que incluyen servidores de IA, almacenamiento y fuentes de alimentación) que permiten la implementación privada de modelos DeepSeek para clientes empresariales.
Sin embargo, la potencia computacional de estas configuraciones sigue siendo limitada. El entrenamiento de modelos a gran escala (con decenas o cientos de miles de millones de parámetros) exige recursos mucho mayores. Esto lleva al desarrollo de clústeres de computación de IA a gran escala, que incorporan un número aún mayor de chips de IA.
Términos como "escala 10K" o "escala 100K" se refieren a clústeres compuestos por 10,000 100,000 o XNUMX XNUMX placas de cómputo de IA. Para lograrlo, se emplean dos estrategias fundamentales: escalamiento vertical (añadir hardware más potente) y escalamiento horizontal (ampliar el número de sistemas interconectados).
¿Qué es Scale Up?
En terminología informática, «escalar» se refiere a la expansión de los recursos del sistema. Este concepto resulta especialmente familiar para quienes tienen experiencia en computación en la nube.
El escalamiento vertical, también conocido como escalamiento ascendente, implica aumentar los recursos de un solo nodo, por ejemplo, agregando más potencia informática, memoria o tarjetas aceleradoras de IA a un servidor.
Escalamiento horizontal, o escalamiento horizontal, significa expandir un sistema agregando más nodos, conectando múltiples servidores o dispositivos a través de una red.
En la computación en la nube, los conceptos también se extienden a Scale Down (reduciendo los recursos de un nodo) y Scale In (reduciendo el número de nodos).
Anteriormente, explicamos cómo insertar más tarjetas aceleradoras de IA en un servidor es una forma de escalamiento vertical, donde cada servidor actúa como un único nodo. Al interconectar varios servidores mediante redes de alta velocidad, logramos el escalamiento horizontal.

La principal distinción entre estos dos radica en el ancho de banda de comunicación entre los chips de IA:
Scale Up implica conexiones de nodos internos, lo que ofrece mayor velocidad, menor latencia y mayor rendimiento.
Históricamente, las comunicaciones internas de las computadoras dependían de PCIe, un protocolo desarrollado a finales del siglo XX durante el auge de la informática personal. Si bien PCIe ha experimentado varias actualizaciones, su evolución ha sido lenta e insuficiente para las cargas de trabajo de la IA moderna.
Para superar estas limitaciones, NVIDIA introdujo su protocolo de bus NVLINK en 2014, que permite la comunicación punto a punto entre GPU. NVLINK ofrece una velocidad mucho mayor y una latencia considerablemente menor en comparación con PCIe.
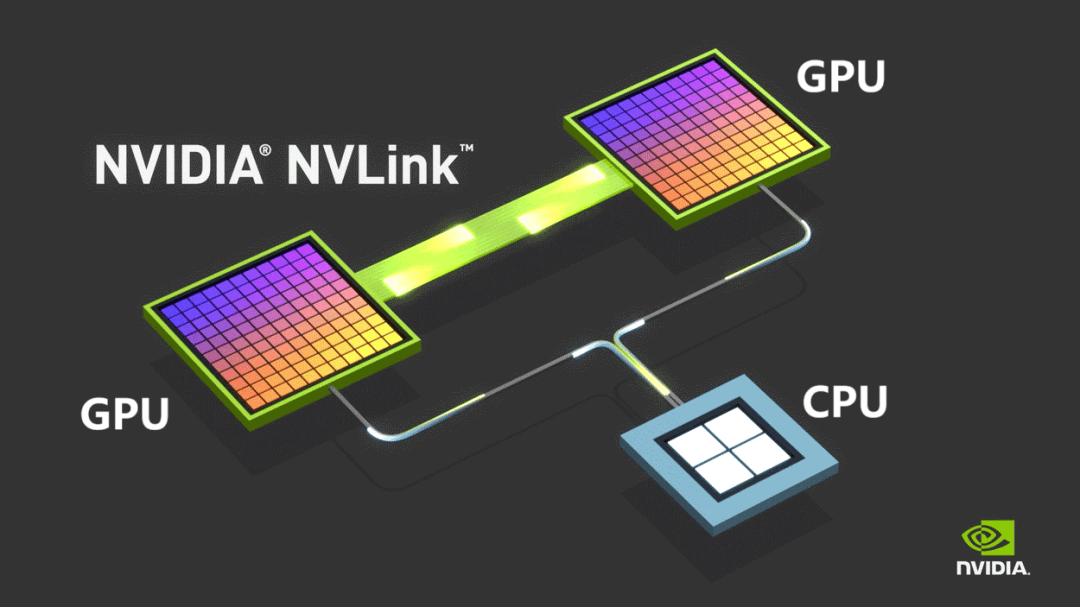
Inicialmente utilizado únicamente para la comunicación entre máquinas, NVIDIA lanzó NVSwitch en 2022: un chip de conmutación independiente diseñado para permitir la conectividad de GPU de alta velocidad entre servidores. Esta innovación redefinió el concepto de nodo, permitiendo que varios servidores y dispositivos de red trabajen conjuntamente dentro de un dominio de alto ancho de banda (HBD).
NVIDIA denomina supernodos a estos sistemas en los que más de 16 GPU están interconectadas con un ancho de banda ultraalto.
Con el tiempo, NVLINK ha avanzado hasta su quinta generación. Cada GPU ahora admite hasta 18 conexiones NVLINK, y el ancho de banda total de la GPU Blackwell ha alcanzado los 1800 GB/s, superando ampliamente a PCIe Gen6.
En marzo de 2024, NVIDIA presentó el NVL72, un gabinete refrigerado por líquido que integra 36 CPU Grace y 72 GPU Blackwell. Ofrece hasta 720 PFLOPS de rendimiento de entrenamiento o 1440 PFLOPS de rendimiento de inferencia, consolidando aún más el liderazgo de NVIDIA en el ecosistema de computación de IA, gracias a su popular hardware de GPU y la pila de software CUDA.

A medida que se expandió la adopción de la IA, muchas otras empresas desarrollaron sus propios chips de IA. Debido a la naturaleza propietaria de NVLINK, estas empresas tuvieron que diseñar arquitecturas alternativas de clústeres de cómputo.
AMD, un importante competidor, presentó UA LINK.
Los actores nacionales en China, como Tencent, Alibaba y China Mobile, encabezaron iniciativas abiertas como ETH-X, ALS y OISA.
Otro avance notable es el protocolo UB (Bus Unificado) de Huawei, una tecnología propia desarrollada para el ecosistema de chips de IA de Ascend. Los chips de Huawei, como el Ascend 910C, han evolucionado considerablemente en los últimos años.
En abril de 2025, Huawei lanzó el supernodo CloudMatrix384, que integra 384 tarjetas aceleradoras de inteligencia artificial Ascend 910C y logra hasta 300 PFLOPS de rendimiento computacional BF16 denso, casi el doble que el sistema GB200 NVL72 de NVIDIA.
CloudMatrix384 aprovecha la tecnología UB y consta de tres planos de red distintos:
- Avión UB
- Plano RDMA (Acceso directo a memoria remota)
- Plano VPC (Nube privada virtual)
Estos planos complementarios permiten una comunicación entre tarjetas excepcional y mejoran significativamente la potencia computacional general dentro del supernodo.
Debido a limitaciones de espacio, exploraremos los detalles técnicos de estos aviones por separado en una discusión futura.
Una nota final: En respuesta a la creciente presión de los estándares abiertos, NVIDIA anunció recientemente su iniciativa NVLink Fusion, que ofrece acceso a su tecnología NVLink a ocho socios globales. Esta iniciativa busca ayudarles a construir sistemas de IA personalizados mediante la interconectividad multichip. Sin embargo, según algunos medios, los componentes clave de NVLink siguen siendo propietarios, lo que sugiere que NVIDIA aún mantiene cierta reserva en cuanto a su apertura.
¿Qué es Scale Out?
El escalamiento horizontal se refiere a la expansión horizontal de los sistemas informáticos y se asemeja mucho a las redes tradicionales de comunicación de datos. Las tecnologías comúnmente utilizadas para conectar servidores convencionales, como la arquitectura de árbol grueso, la topología de red de hoja espinosa, los protocolos TCP/IP y Ethernet, constituyen la base fundamental de la infraestructura de escalamiento horizontal.
Evolucionando para las demandas de la IA
Con la creciente demanda de cargas de trabajo de IA, las tecnologías de red tradicionales han requerido mejoras sustanciales para cumplir con los criterios de rendimiento. Actualmente, las dos tecnologías de red dominantes para la escalabilidad horizontal son:
- InfiniBand (IB)
- RoCEv2 (RDMA sobre Ethernet convergente versión 2)
Ambos se basan en el protocolo RDMA (Acceso directo a memoria remota), que proporciona mayores velocidades de transferencia de datos, menor latencia y capacidades de equilibrio de carga superiores en comparación con Ethernet tradicional.
InfiniBand frente a RoCEv2
- InfiniBand se diseñó originalmente para reemplazar PCIe en la interconexión. Aunque su adopción fluctuó con el tiempo, finalmente fue adquirida por NVIDIA mediante la compra de Mellanox. Actualmente, IB es propiedad de NVIDIA y desempeña un papel clave en su infraestructura informática. Si bien ofrece un rendimiento excelente, su precio es elevado.
- RoCEv2, por otro lado, es un estándar abierto desarrollado para contrarrestar el dominio del mercado de IB. Fusiona RDMA con Ethernet convencional, ofreciendo rentabilidad y reduciendo progresivamente la brecha de rendimiento con InfiniBand.
A diferencia de los estándares fragmentados que se observan en las implementaciones de Scale Up, Scale Out está en gran medida unificado bajo RoCEv2, debido a su énfasis en la compatibilidad entre nodos, en lugar de un acoplamiento estrecho con productos a nivel de chip.
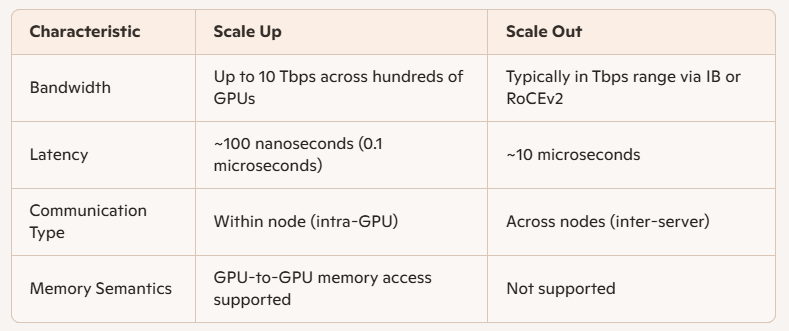
Diferencias de rendimiento: escalamiento vertical vs. escalamiento horizontal
Las principales diferencias técnicas entre Scale Up y Scale Out radican en el ancho de banda y la latencia:

Aplicación en el entrenamiento de IA
El entrenamiento de IA implica múltiples formas de computación paralela:
- TP (Paralelismo tensorial)
- EP (Paralelismo Experto)
- PP (Paralelismo de tuberías)
- DP (Paralelismo de datos)
Generalmente:
- PP y DP implican cargas de comunicación más pequeñas y se manejan mediante Scale Out.
- TP y EP, que requieren un intercambio de datos más pesado, se respaldan mejor con Scale Up dentro de supernodos.
Ventajas de la ampliación en el diseño de redes
Los supernodos, basados en la arquitectura Scale Up, se conectan mediante buses internos de alta velocidad y ofrecen un soporte eficiente para computación paralela, intercambio de parámetros de GPU y sincronización de datos. También permiten el acceso directo a memoria entre GPU, una capacidad de la que carece Scale Out.
Desde el punto de vista de implementación y mantenimiento:
- Los dominios de alto ancho de banda (HBD) más grandes simplifican la red de escalabilidad horizontal.
- Los sistemas Scale Up preintegrados reducen la complejidad, acortan el tiempo de implementación y facilitan las operaciones a largo plazo.
Sin embargo, Scale Up no puede expandirse infinitamente debido a limitaciones de costos. La escala óptima depende de escenarios de uso específicos.

¿Un futuro unificado?
En definitiva, la escalabilidad vertical y horizontal representan un equilibrio entre rendimiento y coste. A medida que la tecnología evoluciona, se prevé que la frontera entre ambos se difumine. Los estándares abiertos emergentes de escalabilidad vertical, como ETH-X, basados en Ethernet, ofrecen métricas de rendimiento prometedoras:
- Capacidad del chip de conmutación: hasta 51.2 Tbps
- Velocidad SerDes: hasta 112 Gbps
- Latencia: Tan baja como 200 nanosegundos
Dado que Scale Out también utiliza Ethernet, esta convergencia apunta a una arquitectura unificada, donde un único estándar puede sustentar ambos modelos de expansión en futuros ecosistemas informáticos.
Tendencias en el desarrollo de clústeres de computación de IA
A medida que el campo de la inteligencia artificial (IA) continúa expandiéndose, los clústeres de computación de IA están evolucionando a lo largo de varias trayectorias clave:
Distribución geográfica de la infraestructura física
Los clústeres de IA están escalando hacia configuraciones que contienen decenas o incluso cientos de miles de tarjetas de IA. Por ejemplo:
- El rack NVL72 de NVIDIA integra 72 chips.
- El CM384 de Huawei implementa 384 chips en 16 racks.
Para construir un clúster de 100,000 384 tarjetas con la arquitectura CM432 de Huawei se necesitarían 384 unidades CM165,888, lo que equivale a 6,912 XNUMX chips y XNUMX racks. Esta escala supera con creces la capacidad física y eléctrica de un solo centro de datos.
Como resultado, la industria está explorando activamente implementaciones de centros de datos distribuidos que puedan operar como un clúster de computación de IA unificado. Estas arquitecturas se basan en gran medida en tecnologías avanzadas de comunicación óptica de interconexión de centros de datos (DCI), que deben soportar transmisiones de larga distancia, gran ancho de banda y baja latencia. Se espera que innovaciones como la fibra óptica de núcleo hueco se aceleren en su adopción.
Personalización de la arquitectura de nodos
El enfoque tradicional para construir clústeres de IA solía centrarse en maximizar la cantidad de chips de IA. Sin embargo, cada vez se hace más hincapié en un diseño arquitectónico profundo, más allá del volumen.
Las tendencias emergentes incluyen la agrupación de recursos computacionales (como GPU, NPU, CPU, memoria y almacenamiento) para crear clústeres altamente adaptables adaptados a los requisitos de los modelos de IA a gran escala, incluidas arquitecturas como Mixture of Experts (MoE).
En resumen, entregar chips desnudos ya no es suficiente. Cada vez son más necesarios diseños a medida y específicos para cada escenario a fin de garantizar un rendimiento y una eficiencia óptimos.
Operaciones y mantenimiento inteligentes
El entrenamiento de modelos de IA a gran escala es notoriamente propenso a errores, que pueden ocurrir en cuestión de horas. Cada fallo requiere reentrenamiento, lo que prolonga los plazos de desarrollo y aumenta los costes operativos.
Para mitigar estos riesgos, las organizaciones priorizan la fiabilidad y la estabilidad del sistema mediante la incorporación de herramientas inteligentes de operación y mantenimiento. Estos sistemas pueden:
- Predecir posibles fallos
- Identificar hardware subóptimo o deteriorado
- Habilitar el reemplazo proactivo de componentes
Estos enfoques reducen significativamente las tasas de fallos y el tiempo de inactividad, lo que refuerza la estabilidad del clúster y mejora de manera efectiva la producción computacional general.
Eficiencia Energética y Sostenibilidad
La computación con IA exige un consumo masivo de energía, lo que impulsa a los principales proveedores a explorar estrategias para reducir el uso de energía y aumentar la dependencia de fuentes de energía renovables.
Este impulso a los clústeres de computación verde se alinea con iniciativas de sostenibilidad más amplias, como la estrategia “Datos del este, computación del oeste” de China, que apunta a optimizar la asignación de energía y promover el desarrollo ecológico a largo plazo de la infraestructura de IA.
Productos relacionados:
-
 Módulo transceptor óptico QSFP-DD-400G-SR8 400G QSFP-DD SR8 PAM4 850nm 100m MTP / MPO OM3 FEC
$149.00
Módulo transceptor óptico QSFP-DD-400G-SR8 400G QSFP-DD SR8 PAM4 850nm 100m MTP / MPO OM3 FEC
$149.00
-
 QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310nm 500m MTP / MPO SMF FEC Módulo transceptor óptico
$400.00
QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310nm 500m MTP / MPO SMF FEC Módulo transceptor óptico
$400.00
-
 QSFP-DD-400G-SR4 QSFP-DD 400G SR4 PAM4 850nm 100m MTP/MPO-12 OM4 FEC Módulo transceptor óptico
$450.00
QSFP-DD-400G-SR4 QSFP-DD 400G SR4 PAM4 850nm 100m MTP/MPO-12 OM4 FEC Módulo transceptor óptico
$450.00
-
 Módulo transceptor óptico QSFP-DD-400G-FR4 400G QSFP-DD FR4 PAM4 CWDM4 2km LC SMF FEC
$500.00
Módulo transceptor óptico QSFP-DD-400G-FR4 400G QSFP-DD FR4 PAM4 CWDM4 2km LC SMF FEC
$500.00
-
 QSFP-DD-400G-XDR4 400G QSFP-DD XDR4 PAM4 1310nm 2km MTP / MPO-12 SMF Módulo transceptor óptico FEC
$580.00
QSFP-DD-400G-XDR4 400G QSFP-DD XDR4 PAM4 1310nm 2km MTP / MPO-12 SMF Módulo transceptor óptico FEC
$580.00
-
 Módulo transceptor óptico QSFP-DD-400G-LR4 400G QSFP-DD LR4 PAM4 CWDM4 10km LC SMF FEC
$600.00
Módulo transceptor óptico QSFP-DD-400G-LR4 400G QSFP-DD LR4 PAM4 CWDM4 10km LC SMF FEC
$600.00
-
 QDD-4X100G-FR-Si QSFP-DD 4 x100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS3.0 Módulo transceptor óptico de fotónica de silicio
$650.00
QDD-4X100G-FR-Si QSFP-DD 4 x100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS3.0 Módulo transceptor óptico de fotónica de silicio
$650.00
-
 QDD-4X100G-FR-4Si QSFP-DD 4 x 100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS4.0 Módulo transceptor óptico de fotónica de silicio
$750.00
QDD-4X100G-FR-4Si QSFP-DD 4 x 100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS4.0 Módulo transceptor óptico de fotónica de silicio
$750.00
-
 QSFP-DD-400G-SR4.2 400 Gb/s QSFP-DD SR4 BiDi PAM4 850nm/910nm 100m/150m OM4/OM5 MMF MPO-12 Módulo transceptor óptico FEC
$900.00
QSFP-DD-400G-SR4.2 400 Gb/s QSFP-DD SR4 BiDi PAM4 850nm/910nm 100m/150m OM4/OM5 MMF MPO-12 Módulo transceptor óptico FEC
$900.00
-
 Arista Q112-400G-SR4 Compatible 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC Módulo transceptor óptico
$450.00
Arista Q112-400G-SR4 Compatible 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC Módulo transceptor óptico
$450.00
-
 Cisco Q112-400G-DR4 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 con módulo transceptor óptico FEC
$650.00
Cisco Q112-400G-DR4 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 con módulo transceptor óptico FEC
$650.00
-
 OSFP-800G-DR8D-FLT 800G-DR8 OSFP Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 Módulo transceptor óptico SMF
$1199.00
OSFP-800G-DR8D-FLT 800G-DR8 OSFP Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 Módulo transceptor óptico SMF
$1199.00
-
 OSFP-800G-SR8D-FLT OSFP 8x100G SR8 Flat Top PAM4 850nm 100m DOM Dual MPO-12 MMF Módulo transceptor óptico
$650.00
OSFP-800G-SR8D-FLT OSFP 8x100G SR8 Flat Top PAM4 850nm 100m DOM Dual MPO-12 MMF Módulo transceptor óptico
$650.00
-
 OSFP-800G-SR8D OSFP 8x100G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Módulo transceptor óptico
$650.00
OSFP-800G-SR8D OSFP 8x100G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Módulo transceptor óptico
$650.00
-
 OSFP-800G-DR8D 800G-DR8 OSFP PAM4 1310nm 500m DOM Dual MTP/MPO-12 Módulo transceptor óptico SMF
$850.00
OSFP-800G-DR8D 800G-DR8 OSFP PAM4 1310nm 500m DOM Dual MTP/MPO-12 Módulo transceptor óptico SMF
$850.00
-
 OSFP-800G-2FR4L OSFP 2x400G FR4 PAM4 1310nm 2km DOM Módulo transceptor óptico dúplex LC SMF
$1200.00
OSFP-800G-2FR4L OSFP 2x400G FR4 PAM4 1310nm 2km DOM Módulo transceptor óptico dúplex LC SMF
$1200.00