
Da Künstliche Intelligenz (KI) das exponentielle Wachstum von Datenvolumen und Modellkomplexität vorantreibt, nutzt verteiltes Rechnen vernetzte Knoten, um Trainingsprozesse zu beschleunigen. Rechenzentrums-Switches spielen eine zentrale Rolle bei der Gewährleistung einer zeitnahen Nachrichtenübermittlung zwischen Knoten, insbesondere in großen Rechenzentren, in denen die Latenzzeit für die Bewältigung wettbewerbsfähiger Workloads entscheidend ist. Darüber hinaus sind Skalierbarkeit und die Fähigkeit, zahlreiche Knoten zu verwalten, für das Training großer KI-Modelle und die Verarbeitung riesiger Datensätze unerlässlich, was Rechenzentrums-Switches für eine effiziente Netzwerkkonnektivität und Datenübertragung unverzichtbar macht. Laut IDC erreichte der globale Switch-Markt im Jahr 308 2022 Milliarden US-Dollar, was einem Wachstum von 17 % gegenüber dem Vorjahr entspricht, mit einer prognostizierten durchschnittlichen jährlichen Wachstumsrate (CAGR) von 4.6 % von 2022 bis 2027. In China wurde der Switch-Markt auf 59.1 Milliarden US-Dollar geschätzt, was einem Wachstum von 9.5 % entspricht, mit einer erwarteten CAGR von 7–9 % in den nächsten fünf Jahren, womit er das globale Wachstum übertrifft.
Hauptklassifizierungen von Rechenzentrums-Switches
Rechenzentrums-Switches können anhand verschiedener Kriterien kategorisiert werden, darunter Anwendungsszenarien, Netzwerkschichten, Verwaltungstypen, OSI-Netzwerkmodelle, Portgeschwindigkeiten und physische Strukturen. Zu den Klassifizierungen gehören:
- Nach Anwendungsszenario: Campus-Switches, Rechenzentrums-Switches
- Nach Netzwerkschicht: Zugriffs-Switches, Aggregations-Switches, Core-Switches
- Nach Verwaltungstyp: Nicht verwaltete Switches, webverwaltete Switches, vollständig verwaltete Switches
- Nach OSI-Netzwerkmodell: Layer-2-Switches, Layer-3-Switches
- Nach Portgeschwindigkeit: Fast Ethernet-Switches, Gigabit Ethernet-Switches, 10-Gigabit-Switches, Multi-Rate-Switches
- Nach physikalischer Struktur: Feste (Box-)Switches, modulare (Chassis-)Switches
Switch-Chips und wichtige Leistungskennzahlen
Ethernet-Rechenzentrums-Switches bestehen aus kritischen Komponenten wie Chips, Leiterplatten, optischen Modulen, Steckverbindern, passiven Komponenten, Gehäusen, Netzteilen und Lüftern. Zu den Kernkomponenten zählen Ethernet-Switch-Chips und CPUs sowie zusätzliche Elemente wie PHYs und CPLD/FPGAs. Der speziell für die Netzwerkoptimierung entwickelte Ethernet-Switch-Chip übernimmt die Datenverarbeitung und Paketweiterleitung und verfügt über komplexe Logikpfade, um eine robuste Datenverarbeitung zu gewährleisten. Die CPU verwaltet Anmeldungen und Protokollinteraktionen, während der PHY die Daten der physischen Schicht verarbeitet.
Die Leistung von Rechenzentrums-Switches hängt von wichtigen Kennzahlen wie Backplane-Bandbreite, Paketweiterleitungsrate, Switching-Kapazität, Portgeschwindigkeit und Portdichte ab. Die Backplane-Bandbreite gibt die Datendurchsatzkapazität eines Switches an, wobei höhere Werte eine bessere Leistung unter hoher Last bedeuten. Für eine blockierungsfreie Weiterleitung muss die Backplane-Bandbreite mindestens der Switching-Kapazität entsprechen (berechnet als Portanzahl × Portgeschwindigkeit × 2 im Vollduplex-Modus). High-End-Switches ohne Backplane-Design basieren auf Paketweiterleitungsraten. Höhere Portgeschwindigkeiten weisen auf eine bessere Verarbeitungskapazität in Szenarien mit hohem Datenverkehr hin, während eine höhere Portdichte größere Netzwerke durch den Anschluss weiterer Geräte unterstützt.
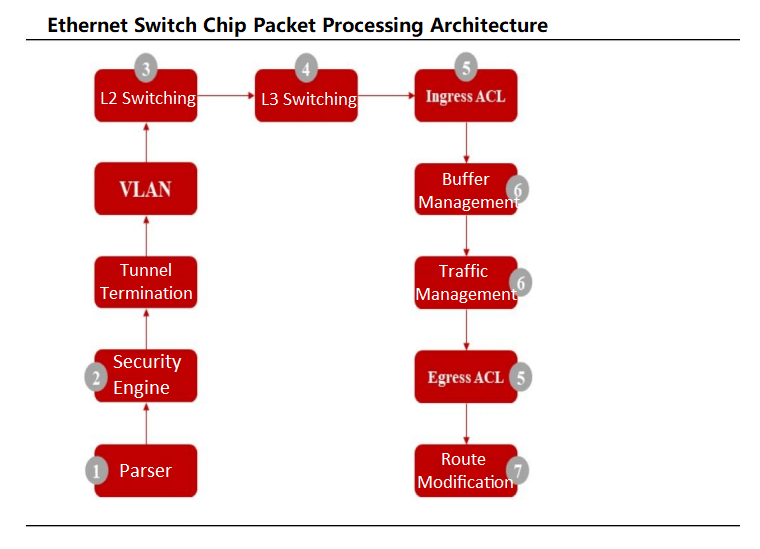
Ethernet-Switch-Chips fungieren als spezialisierte ASICs für Rechenzentrums-Switches und integrieren häufig MAC-Controller und PHY-Chips. Datenpakete gelangen über physische Ports, wo der Parser des Chips die Felder zur Flussklassifizierung analysiert. Nach Sicherheitsprüfungen werden die Pakete Layer-2-Switching oder Layer-3-Routing unterzogen. Der Flussklassifizierer leitet die Pakete in priorisierte Warteschlangen nach 802.1P- oder DSCP-Standards. Scheduler verwalten dann die Warteschlangenpriorisierung mithilfe von Algorithmen wie Weighted Round Robin (WRR), bevor die Pakete übertragen werden.

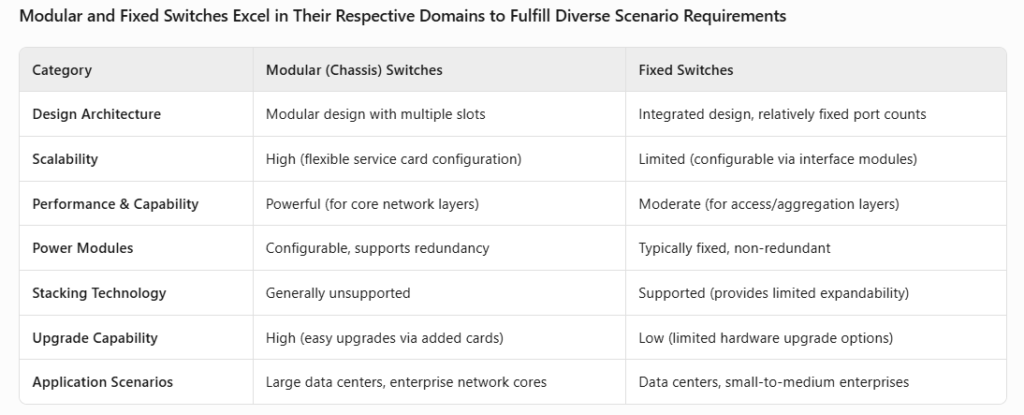
Physisch gesehen sind Rechenzentrums-Switches entweder gehäusebasiert oder fest installiert. Chassis-Switches zeichnen sich durch ein modulares Design mit Steckplätzen für Schnittstellen-, Steuerungs- und Switching-Module aus und bieten so hohe Flexibilität und Skalierbarkeit. Fest installierte Switches verfügen über integrierte Designs mit festen Portkonfigurationen, einige unterstützen jedoch auch modulare Schnittstellen. Die Hauptunterschiede liegen in der internen Architektur und den Anwendungsszenarien (OSI-Layer-Nutzung).
Entwicklung und technologische Fortschritte bei Rechenzentrums-Switches
Von OEO zu OOO: Volloptische Switches für KI-Workloads
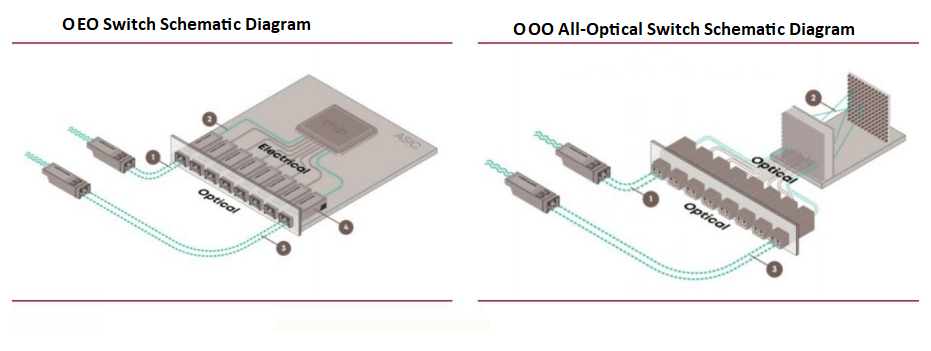
Aktuelle Rechenzentrums-Switches, die auf ASIC-Chips basieren, arbeiten als optisch-elektrisch-optische (OEO) Paketschaltungsschalter und nutzen ASIC-Chips für die zentrale Paketweiterleitung. Diese Switches benötigen optisch-elektrische Konvertierungen für die Signalübertragung. Es entstehen jedoch zunehmend rein optische (OOO) Switches, um den KI-gesteuerten Rechenanforderungen gerecht zu werden, den Konvertierungsaufwand zu reduzieren und die Effizienz zu steigern.
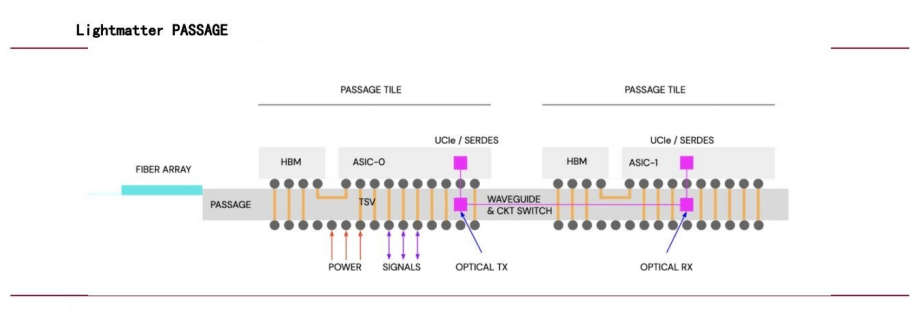
NVIDIA-Führungskraft wechselt zu Lightmatter, um rein optisches Switching voranzutreiben
Im Juli 2024 wechselte NVIDIA-Vizepräsidentin Simona Jankowski als CFO zu Lightmatter und verdeutlichte damit den Fokus des Unternehmens auf optische Verbindungen. Die mit 4.4 Milliarden US-Dollar bewertete Passage-Technologie von Lightmatter nutzt Photonik für Chipverbindungen und verwendet Wellenleiter anstelle von Glasfasern, um eine bandbreitenstarke, parallele Datenübertragung für verschiedene Rechenkerne zu ermöglichen und so die Leistung von KI-Netzwerken deutlich zu steigern.
Googles großflächiger Einsatz von OCS-Switches
Die Rechenzentrumsnetzwerke von Google basieren auf Software-Defined Networking (SDN), Clos-Topologie und Standard-Switch-Chips. Die Clos-Topologie, eine blockierungsfreie mehrstufige Architektur aus kleineren Radix-Chips, unterstützt skalierbare Netzwerke, die für KI-Workloads entscheidend sind.
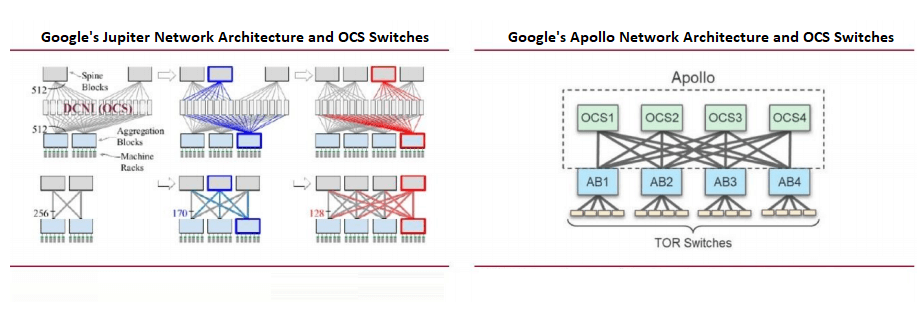
Google war Vorreiter bei der großflächigen Nutzung von Optical Circuit Switches (OCS) in seiner Jupiter-Architektur und integrierte MEMS-basierte OCS, um die optisch-elektrische Konvertierung zu reduzieren. Auf der OFC 2023 stellte Google sein Apollo-Projekt vor, bei dem die Ethernet Packet Switches (EPS) der Spine-Schicht durch OCS ersetzt wurden, um die Effizienz zu steigern.
Schlüsseltechnologien und Standards für Rechenzentrums-Switches
- RDMA: Ermöglicht Kommunikation mit geringer Latenz und hohem Durchsatz
Remote Direct Memory Access (RDMA) ermöglicht Netzwerkkommunikation mit hohem Durchsatz und geringer Latenz ohne Betriebssystemeinbindung. Im Gegensatz zu herkömmlichem TCP/IP, das mehrere CPU-intensive Datenkopien erfordert, überträgt RDMA Daten direkt zwischen Computerspeichern. In Rechenzentrums-Switches wird RDMA über InfiniBand und RoCE (RDMA over Converged Ethernet) implementiert. InfiniBand und RoCEv2 sind die dominierenden Lösungen für KI-Rechenzentren (AIDCs).
- InfiniBand: InfiniBand wurde für High-Performance-Computing (HPC) und Rechenzentren entwickelt und bietet hohe Bandbreite, geringe Latenz, Quality of Service (QoS) und Skalierbarkeit. Seine kanalisierte Architektur, RDMA-Unterstützung und das Switched-Network-Design machen es ideal für datenintensive Anwendungen. Die hohen Kosten beschränken jedoch den Einsatz auf spezialisierte HPC-Umgebungen.
Vergleich von InfiniBand und RoCE
| Kategorie | InfiniBand | RoCE |
| Design-Philosophie | Entwickelt mit RDMA im Hinterkopf, definiert physische Verbindungs- und Netzwerkschichten neu | Implementiert RDMA über Ethernet (RoCEv1: Verbindungsschicht; RoCEv2: Transportschicht) |
| Schlüsseltechnologie | – InfiniBand-Netzwerkprotokoll und -Architektur – Verben-Programmierschnittstelle | – UDP/IP-basierte Implementierung – Hardware-Offload (RoCEv2) zur Reduzierung der CPU-Auslastung – IP-Routing für Skalierbarkeit |
| Vorteile | – Höhere Bandbreite und geringere Latenz – Kreditbasierte Flusskontrolle zur Gewährleistung der Datenstabilität | - Kosteneffizient – Kompatibel mit Standard-Ethernet – Unterstützt den Einsatz im großen Maßstab |
| Nachteile | – Begrenzte Skalierbarkeit – Erfordert spezielle Netzwerkkarten und Switches | – Herausforderungen bei der Umsetzung bleiben bestehen – Erfordert RoCE-fähige NICs |
| Kosten | Höher (dedizierte IB-NICs/Switches; die Verkabelungskosten übersteigen die von Ethernet) | Niedriger (nutzt Standard-Ethernet-Switches; budgetfreundlich) |
| Anwendungsfälle | HPC, groß angelegte Parallelverarbeitung, KI-Training | Interne Kommunikation im Rechenzentrum, Cloud-Service-Anbieter |
| Hauptlieferanten | NVIDIA (Hauptlieferant) | Unterstützung mehrerer Anbieter (z. B. Huawei, H3C, Inspur, Ruijie in China) |
- RoCE: RoCEv2 basiert auf der UDP-Schicht von Ethernet, führt IP-Protokolle für Skalierbarkeit ein und nutzt Hardware-Offloading, um die CPU-Auslastung zu reduzieren. RoCEv2 ist zwar etwas weniger leistungsfähig als InfiniBand, aber kostengünstig und eignet sich daher für die Rechenzentrumskommunikation und Cloud-Dienste.
RDMA reduziert die Kommunikationslatenz zwischen Karten
Beim verteilten KI-Training ist die Reduzierung der Kommunikationslatenz zwischen Karten entscheidend für die Verbesserung der Beschleunigungsverhältnisse. Die Gesamtrechenzeit umfasst die Berechnung einzelner Karten und die Kommunikation zwischen Karten. RDMA (über InfiniBand oder RoCEv2) minimiert die Latenz durch Umgehung von Kernel-Protokollstapeln. Labortests zeigen, dass RDMA die End-to-End-Latenz in Single-Hop-Szenarien von 50 µs (TCP/IP) auf 5 µs (RoCEv2) bzw. 2 µs (InfiniBand) reduziert.
Ethernet vs. InfiniBand: Stärken und Trends
- InfiniBand vs. RoCEv2: InfiniBand unterstützt große GPU-Cluster (bis zu 10,000 Karten) mit minimalen Leistungseinbußen und geringerer Latenz als RoCEv2, ist aber teurer, da NVIDIA über 70 % des Marktes dominiert. RoCEv2 bietet breitere Kompatibilität und geringere Kosten und unterstützt sowohl RDMA als auch traditionelle Ethernet-Netzwerke. Anbieter wie H3C und Huawei sind marktführend.
- Ethernet gewinnt an Bedeutung: Laut Dell'Oro Group werden die Switch-Ausgaben für KI-Backend-Netzwerke zwischen 100 und 2025 2029 Milliarden US-Dollar übersteigen. Ethernet gewinnt in großen KI-Clustern an Bedeutung, wobei Implementierungen wie Colossus von xAI Ethernet nutzen. Bis 2027 wird Ethernet voraussichtlich InfiniBand im Marktanteil überholen.
- NVIDIAs Ethernet-Offensive: Im Juli 2023 wurde das Ultra Ethernet Consortium (UEC), dem AMD, Arista, Broadcom, Cisco, Meta und Microsoft angehören, gegründet, um Ethernet-basierte KI-Netzwerklösungen zu entwickeln. NVIDIA trat im Juli 2024 bei und steigerte mit seiner Spectrum-X-Plattform die KI-Netzwerkleistung im Vergleich zu herkömmlichem Ethernet um das 1.6-Fache. NVIDIA plant jährliche Spectrum-X-Updates, um die KI-Ethernet-Leistung weiter zu verbessern.
Ähnliche Produkte:
-
 QSFP-DD-400G-SR8 400G QSFP-DD SR8 PAM4 850 nm 100 m optisches MTP / MPO OM3 FEC-Transceiver-Modul
$149.00
QSFP-DD-400G-SR8 400G QSFP-DD SR8 PAM4 850 nm 100 m optisches MTP / MPO OM3 FEC-Transceiver-Modul
$149.00
-
 QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310 nm 500 m MTP / MPO SMF FEC Optisches Transceiver-Modul
$400.00
QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310 nm 500 m MTP / MPO SMF FEC Optisches Transceiver-Modul
$400.00
-
 QSFP-DD-400G-SR4 QSFP-DD 400G SR4 PAM4 850 nm 100 m MTP/MPO-12 OM4 FEC Optisches Transceiver-Modul
$450.00
QSFP-DD-400G-SR4 QSFP-DD 400G SR4 PAM4 850 nm 100 m MTP/MPO-12 OM4 FEC Optisches Transceiver-Modul
$450.00
-
 QSFP-DD-400G-FR4 400G QSFP-DD FR4 PAM4 CWDM4 2 km LC SMF FEC Optisches Transceiver-Modul
$500.00
QSFP-DD-400G-FR4 400G QSFP-DD FR4 PAM4 CWDM4 2 km LC SMF FEC Optisches Transceiver-Modul
$500.00
-
 QSFP-DD-400G-XDR4 400G QSFP-DD XDR4 PAM4 1310nm 2km MTP/MPO-12 SMF FEC Optisches Transceiver-Modul
$580.00
QSFP-DD-400G-XDR4 400G QSFP-DD XDR4 PAM4 1310nm 2km MTP/MPO-12 SMF FEC Optisches Transceiver-Modul
$580.00
-
 QSFP-DD-400G-LR4 400G QSFP-DD LR4 PAM4 CWDM4 10 km LC SMF FEC Optisches Transceiver-Modul
$600.00
QSFP-DD-400G-LR4 400G QSFP-DD LR4 PAM4 CWDM4 10 km LC SMF FEC Optisches Transceiver-Modul
$600.00
-
 QDD-4X100G-FR-Si QSFP-DD 4 x100G FR PAM4 1310 nm 2 km MTP/MPO-12 SMF FEC CMIS3.0 Optisches Transceivermodul für Siliziumphotonik
$650.00
QDD-4X100G-FR-Si QSFP-DD 4 x100G FR PAM4 1310 nm 2 km MTP/MPO-12 SMF FEC CMIS3.0 Optisches Transceivermodul für Siliziumphotonik
$650.00
-
 QDD-4X100G-FR-4Si QSFP-DD 4 x 100G FR PAM4 1310 nm 2 km MTP/MPO-12 SMF FEC CMIS4.0 Optisches Transceivermodul für Siliziumphotonik
$750.00
QDD-4X100G-FR-4Si QSFP-DD 4 x 100G FR PAM4 1310 nm 2 km MTP/MPO-12 SMF FEC CMIS4.0 Optisches Transceivermodul für Siliziumphotonik
$750.00
-
 QSFP-DD-400G-SR4.2 400 Gbit/s QSFP-DD SR4 BiDi PAM4 850 nm/910 nm 100 m/150 m OM4/OM5 MMF MPO-12 FEC Optisches Transceiver-Modul
$900.00
QSFP-DD-400G-SR4.2 400 Gbit/s QSFP-DD SR4 BiDi PAM4 850 nm/910 nm 100 m/150 m OM4/OM5 MMF MPO-12 FEC Optisches Transceiver-Modul
$900.00
-
 Arista Q112-400G-SR4 kompatibles 400G QSFP112 SR4 PAM4 850 nm 100 m MTP/MPO-12 OM3 FEC optisches Transceiver-Modul
$450.00
Arista Q112-400G-SR4 kompatibles 400G QSFP112 SR4 PAM4 850 nm 100 m MTP/MPO-12 OM3 FEC optisches Transceiver-Modul
$450.00
-
 Cisco Q112-400G-DR4-kompatibles 400G NDR QSFP112 DR4 PAM4 1310 nm 500 m MPO-12 mit optischem FEC-Transceiver-Modul
$650.00
Cisco Q112-400G-DR4-kompatibles 400G NDR QSFP112 DR4 PAM4 1310 nm 500 m MPO-12 mit optischem FEC-Transceiver-Modul
$650.00
-
 OSFP-800G-DR8D-FLT 800G-DR8 OSFP Flat Top PAM4 1310 nm 500 m DOM Dual MTP/MPO-12 SMF Optisches Transceiver-Modul
$1199.00
OSFP-800G-DR8D-FLT 800G-DR8 OSFP Flat Top PAM4 1310 nm 500 m DOM Dual MTP/MPO-12 SMF Optisches Transceiver-Modul
$1199.00
-
 OSFP-800G-SR8D-FLT OSFP 8x100G SR8 Flat Top PAM4 850 nm 100 m DOM Dual MPO-12 MMF optisches Transceiver-Modul
$650.00
OSFP-800G-SR8D-FLT OSFP 8x100G SR8 Flat Top PAM4 850 nm 100 m DOM Dual MPO-12 MMF optisches Transceiver-Modul
$650.00
-
 OSFP-800G-SR8D OSFP 8x100G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optisches Transceiver-Modul
$650.00
OSFP-800G-SR8D OSFP 8x100G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optisches Transceiver-Modul
$650.00
-
 OSFP-800G-DR8D 800G-DR8 OSFP PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optisches Transceiver-Modul
$850.00
OSFP-800G-DR8D 800G-DR8 OSFP PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optisches Transceiver-Modul
$850.00
-
 OSFP-800G-2FR4L OSFP 2x400G FR4 PAM4 1310 nm 2 km DOM Dual Duplex LC SMF Optisches Transceiver-Modul
$1200.00
OSFP-800G-2FR4L OSFP 2x400G FR4 PAM4 1310 nm 2 km DOM Dual Duplex LC SMF Optisches Transceiver-Modul
$1200.00