
In den letzten Jahren hat der globale Aufstieg der künstlichen Intelligenz (KI) in der Gesellschaft große Aufmerksamkeit erregt. Ein häufig diskutierter Punkt im Zusammenhang mit KI ist das Konzept der Rechencluster – neben Algorithmen und Daten eine der drei Grundsäulen der KI. Diese Rechencluster dienen als primäre Quelle der Rechenleistung, vergleichbar mit einem riesigen Kraftwerk, das die KI-Revolution kontinuierlich antreibt.

Doch was genau macht einen KI-Compute-Cluster aus? Warum sind sie in der Lage, eine so immense Rechenleistung zu erbringen? Wie sieht ihre interne Architektur aus und welche Schlüsseltechnologien sind beteiligt?
Was sind KI-Rechencluster?
Wie der Name schon sagt, ist ein KI-Rechencluster ein System, das die für die Ausführung von KI-Aufgaben erforderlichen Rechenressourcen bereitstellt. Ein „Cluster“ bezeichnet eine Gruppe unabhängiger Geräte, die über Hochgeschwindigkeitsnetzwerke verbunden sind und als einheitliches System fungieren.
Per Definition ist ein KI-Rechencluster ein verteiltes Computersystem, das durch die Verbindung zahlreicher Hochleistungs-Rechenknoten (wie GPU- oder TPU-Server) über Hochgeschwindigkeitsnetzwerke gebildet wird.
KI-Workloads lassen sich grundsätzlich in zwei Hauptkategorien unterteilen: Training und Inferenz. Trainingsaufgaben sind in der Regel rechenintensiver und komplexer und erfordern erhebliche Rechenressourcen. Inferenzaufgaben hingegen sind relativ einfach und weniger anspruchsvoll.
Beide Prozesse basieren stark auf Matrixoperationen – einschließlich Faltungen und Tensormultiplikationen –, die sich natürlich für die Parallelisierung eignen. Daher sind parallele Rechenchips wie GPUs, NPUs und TPUs für die KI-Verarbeitung unverzichtbar geworden. Zusammengefasst werden diese als KI-Chips bezeichnet.
KI-Chips sind die grundlegenden Einheiten der KI-Berechnung. Ein einzelner Chip kann jedoch nicht unabhängig arbeiten; er muss in eine Leiterplatte integriert werden. Je nach Anwendung:
Sie sind in Motherboards von Mobiltelefonen eingebettet oder in SoCs integriert und ermöglichen die Bereitstellung mobiler KI-Funktionen.
In Modulen für IoT-Geräte installiert, ermöglichen sie Edge Intelligence für Geräte wie autonome Fahrzeuge, Roboterarme und Überwachungskameras.
Integriert in Basisstationen, Router und Gateways ermöglichen sie Edge-Side-KI-Computing, das aufgrund von Größen- und Leistungsbeschränkungen normalerweise auf Inferenz beschränkt ist.
Für anspruchsvollere Trainingsaufgaben müssen Systeme mehrere KI-Chips unterstützen. Dies wird durch den Bau von KI-Rechenplatinen und die Installation mehrerer davon in einem einzigen Server erreicht. Dadurch wird ein Standardserver effektiv in einen KI-Server umgewandelt.

Normalerweise enthält ein KI-Server acht Rechenkarten, manche Modelle unterstützen jedoch bis zu zwanzig Karten. Aufgrund der Wärmeableitung und der Leistungsbeschränkungen ist eine weitere Erweiterung jedoch unpraktisch.
Mit dieser Konfiguration erhöht sich die Rechenleistung deutlich – der Server kann problemlos Inferenzen verarbeiten und sogar kleinere Trainingsaufgaben durchführen. Ein Beispiel ist das DeepSeek-Modell, dessen Architektur und Algorithmen optimiert wurden, um den Rechenaufwand deutlich zu reduzieren. Daher bieten viele Anbieter mittlerweile integrierte „All-in-One“-Racks an – bestehend aus KI-Servern, Speicher und Stromversorgung –, die den privaten Einsatz von DeepSeek-Modellen für Unternehmenskunden unterstützen.
Dennoch ist die Rechenleistung dieser Systeme begrenzt. Das Training extrem großer Modelle – mit Dutzenden oder Hunderten von Milliarden Parametern – erfordert weitaus mehr Ressourcen. Dies führt zur Entwicklung großer KI-Rechencluster, die eine noch größere Anzahl von KI-Chips umfassen.
Begriffe wie „10K-Scale“ oder „100K-Scale“ beziehen sich auf Cluster mit 10,000 oder 100,000 KI-Rechnerboards. Um dies zu erreichen, werden zwei grundlegende Strategien eingesetzt: Scale Up (Hinzufügen leistungsfähigerer Hardware) und Scale Out (Erweitern der Anzahl der miteinander verbundenen Systeme).
Was ist Scale-Up?
In der Computerterminologie bezieht sich „Skalierung“ auf die Erweiterung von Systemressourcen. Dieses Konzept ist insbesondere denjenigen vertraut, die Erfahrung mit Cloud Computing haben.
Beim Scale-Up, auch als vertikale Skalierung bezeichnet, werden die Ressourcen eines einzelnen Knotens erhöht, beispielsweise durch Hinzufügen von mehr Rechenleistung, Speicher oder KI-Beschleunigerkarten zu einem Server.
Scale Out oder horizontale Skalierung bedeutet, ein System durch Hinzufügen weiterer Knoten zu erweitern – also mehrere Server oder Geräte über ein Netzwerk zu verbinden.
Im Cloud Computing erstrecken sich die Konzepte auch auf Scale Down (Reduzierung der Ressourcen eines Knotens) und Scale In (Reduzierung der Anzahl der Knoten).
Wir haben bereits erläutert, dass das Einfügen weiterer KI-Beschleunigerkarten in einen Server eine Form der Skalierung darstellt, bei der jeder Server als einzelner Knoten fungiert. Durch die Verbindung mehrerer Server über Hochgeschwindigkeitsnetzwerke erreichen wir eine Skalierung nach außen.
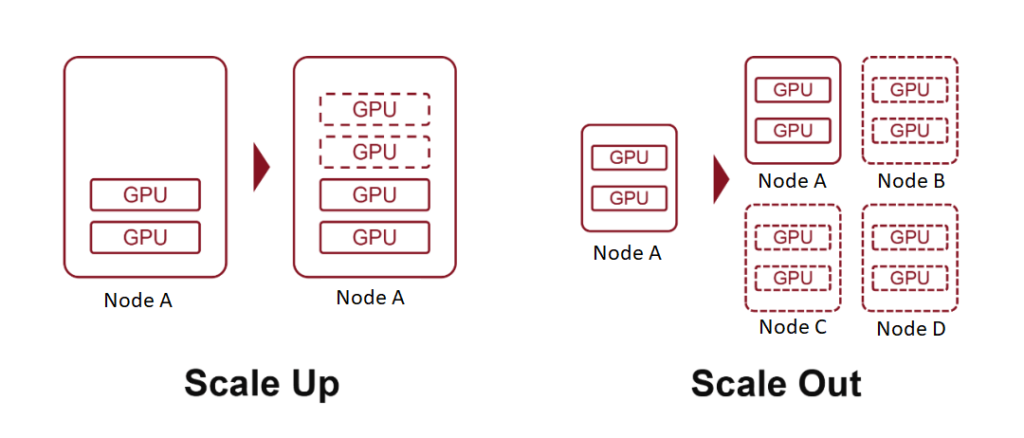
Der Hauptunterschied zwischen diesen beiden liegt in der Kommunikationsbandbreite zwischen KI-Chips:
Beim Scale Up handelt es sich um interne Knotenverbindungen, die eine höhere Geschwindigkeit, geringere Latenz und eine stärkere Leistung bieten.
Historisch gesehen basierte die interne Kommunikation innerhalb von Computern auf PCIe – einem Protokoll, das Ende des 20. Jahrhunderts während des Aufstiegs des Personal Computing entwickelt wurde. Obwohl PCIe mehrere Upgrades erfahren hat, verlief seine Entwicklung langsam und für moderne KI-Workloads unzureichend.
Um diese Einschränkungen zu überwinden, führte NVIDIA 2014 sein proprietäres NVLINK-Busprotokoll ein, das eine Punkt-zu-Punkt-Kommunikation zwischen GPUs ermöglicht. NVLINK bietet im Vergleich zu PCIe eine deutlich höhere Geschwindigkeit und wesentlich geringere Latenz.
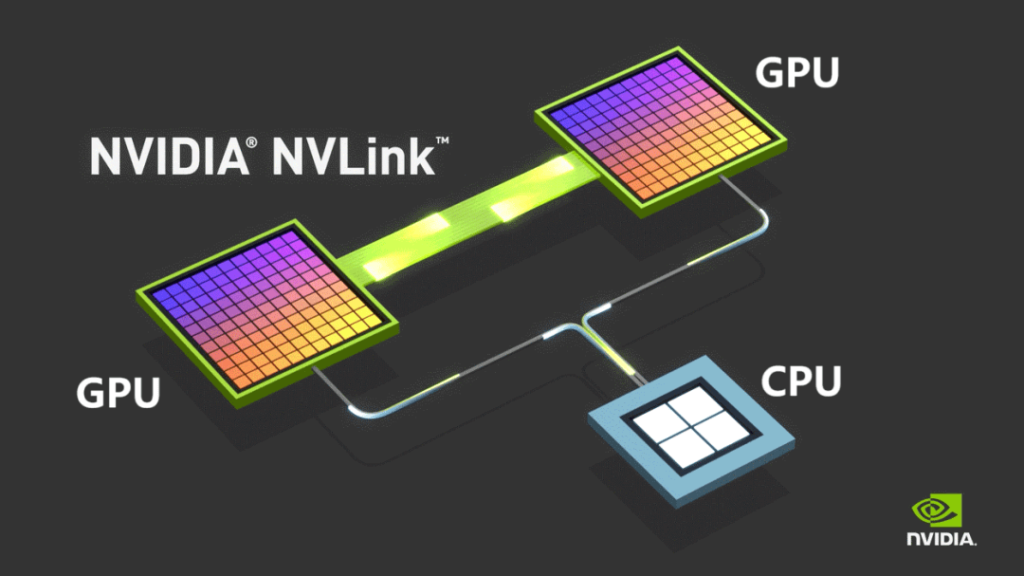
Ursprünglich nur für die Kommunikation innerhalb von Maschinen verwendet, brachte NVIDIA 2022 NVSwitch auf den Markt – einen unabhängigen Switching-Chip, der eine schnelle GPU-Konnektivität zwischen Servern ermöglicht. Diese Innovation definierte das Konzept eines Knotens neu und ermöglichte die Zusammenarbeit mehrerer Server und Netzwerkgeräte innerhalb einer High Bandwidth Domain (HBD).
NVIDIA bezeichnet solche Systeme, bei denen mehr als 16 GPUs mit ultrahoher Bandbreite miteinander verbunden sind, als Superknoten.
Im Laufe der Zeit wurde NVLINK in die fünfte Generation weiterentwickelt. Jede GPU unterstützt nun bis zu 18 NVLINK-Verbindungen, und die Gesamtbandbreite der Blackwell-GPU hat 1800 GB/s erreicht und übertrifft damit PCIe Gen6 deutlich.
Im März 2024 stellte NVIDIA das NVL72 vor, ein flüssigkeitsgekühltes Gehäuse mit 36 Grace-CPUs und 72 Blackwell-GPUs. Es liefert bis zu 720 PFLOPS Trainingsleistung bzw. 1440 PFLOPS Inferenzleistung und festigt damit NVIDIAs Führungsposition im KI-Computing-Ökosystem – angetrieben von der beliebten GPU-Hardware und dem CUDA-Software-Stack.

Mit der zunehmenden Verbreitung von KI entwickelten zahlreiche andere Unternehmen ihre eigenen KI-Chips. Aufgrund der proprietären Natur von NVLINK mussten diese Unternehmen alternative Rechencluster-Architekturen entwickeln.
AMD, ein großer Konkurrent, hat UA LINK eingeführt.
Inländische Akteure in China – wie Tencent, Alibaba und China Mobile – führten offene Initiativen wie ETH-X, ALS und OISA an.
Ein weiterer bemerkenswerter Fortschritt ist das UB-Protokoll (Unified Bus) von Huawei, eine proprietäre Technologie, die zur Unterstützung des Ascend-KI-Chip-Ökosystems entwickelt wurde. Huawei-Chips, wie der Ascend 910C, haben sich in den letzten Jahren erheblich weiterentwickelt.
Im April 2025 brachte Huawei den CloudMatrix384-Superknoten auf den Markt, der 384 Ascend 910C KI-Beschleunigerkarten integriert und eine dichte BF300-Rechenleistung von bis zu 16 PFLOPS erreicht – fast doppelt so viel wie das GB200 NVL72-System von NVIDIA.
CloudMatrix384 nutzt die UB-Technologie und besteht aus drei unterschiedlichen Netzwerkebenen:
- UB-Flugzeug
- RDMA-Ebene (Remote Direct Memory Access)
- VPC-Ebene (Virtual Private Cloud)
Diese komplementären Ebenen ermöglichen eine außergewöhnliche Kommunikation zwischen den Karten und steigern die Gesamtrechenleistung innerhalb des Superknotens erheblich.
Aus Platzgründen werden wir die technischen Details dieser Flugzeuge in einer späteren Diskussion separat untersuchen.
Ein letzter Hinweis: Als Reaktion auf den wachsenden Druck durch offene Standards hat NVIDIA kürzlich seine NVLink Fusion-Initiative angekündigt und bietet acht globalen Partnern Zugriff auf seine NVLink-Technologie. Ziel ist es, ihnen den Aufbau maßgeschneiderter KI-Systeme über Multi-Chip-Verbindungen zu ermöglichen. Medienberichten zufolge sind wichtige NVLink-Komponenten jedoch weiterhin proprietär, was darauf hindeutet, dass NVIDIA in Bezug auf seine Offenheit noch etwas zurückhaltend ist.
Was ist Scale-Out?
Scale-Out bezeichnet die horizontale Erweiterung von Computersystemen und ähnelt stark herkömmlichen Datenkommunikationsnetzwerken. Technologien, die üblicherweise zur Verbindung konventioneller Server verwendet werden – wie Fat-Tree-Architektur, Spine-Leaf-Netzwerktopologie, TCP/IP-Protokolle und Ethernet – bilden die Grundlage der Scale-Out-Infrastruktur.
Weiterentwicklung für KI-Anforderungen
Angesichts der wachsenden Anforderungen von KI-Workloads mussten traditionelle Netzwerktechnologien erheblich verbessert werden, um die Leistungskriterien zu erfüllen. Derzeit sind die beiden dominierenden Netzwerktechnologien für Scale-Out:
- InfiniBand (IB)
- RoCEv2 (RDMA über Converged Ethernet Version 2)
Beide basieren auf dem RDMA-Protokoll (Remote Direct Memory Access) und bieten im Vergleich zum herkömmlichen Ethernet höhere Datenübertragungsraten, geringere Latenz und bessere Lastausgleichsfunktionen.
InfiniBand vs. RoCEv2
- InfiniBand wurde ursprünglich als Ersatz für PCIe für Verbindungszwecke entwickelt. Obwohl die Akzeptanz im Laufe der Zeit schwankte, wurde es schließlich durch die Übernahme von Mellanox von NVIDIA erworben. Heute ist IB Eigentum von NVIDIA und spielt eine Schlüsselrolle in deren Recheninfrastruktur. Es bietet zwar hervorragende Leistung, ist aber auch teuer.
- RoCEv2 hingegen ist ein offener Standard, der entwickelt wurde, um der Marktdominanz von IB entgegenzuwirken. Er verbindet RDMA mit herkömmlichem Ethernet, bietet Kosteneffizienz und verringert die Leistungslücke zu InfiniBand kontinuierlich.
Im Gegensatz zu den fragmentierten Standards, die bei Scale-Up-Implementierungen zu beobachten sind, ist Scale-Out unter RoCEv2 weitgehend vereinheitlicht, da der Schwerpunkt eher auf der Kompatibilität zwischen Knoten als auf einer engen Kopplung mit Produkten auf Chipebene liegt.
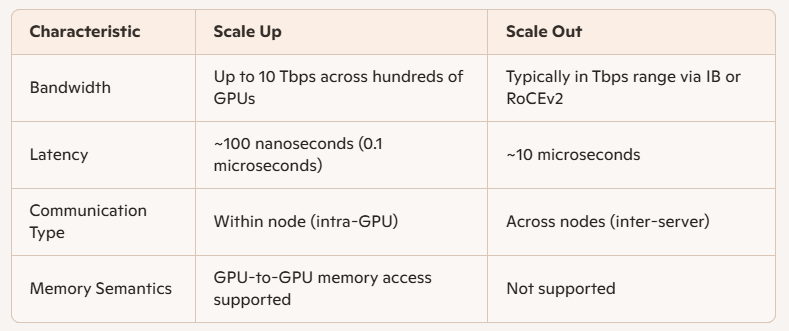
Leistungsunterschiede: Scale-Up vs. Scale-Out
Die wichtigsten technischen Unterschiede zwischen Scale Up und Scale Out liegen in Bandbreite und Latenz:

Anwendung im KI-Training
Das KI-Training umfasst mehrere Formen paralleler Berechnungen:
- TP (Tensor-Parallelität)
- EP (Expertenparallelität)
- PP (Pipeline-Parallelität)
- DP (Datenparallelität)
Allgemein:
- PP und DP erfordern geringere Kommunikationslasten und werden über Scale Out abgewickelt.
- TP und EP, die einen umfangreicheren Datenaustausch erfordern, werden am besten durch Scale Up innerhalb von Superknoten unterstützt.
Vorteile der Skalierung im Netzwerkdesign
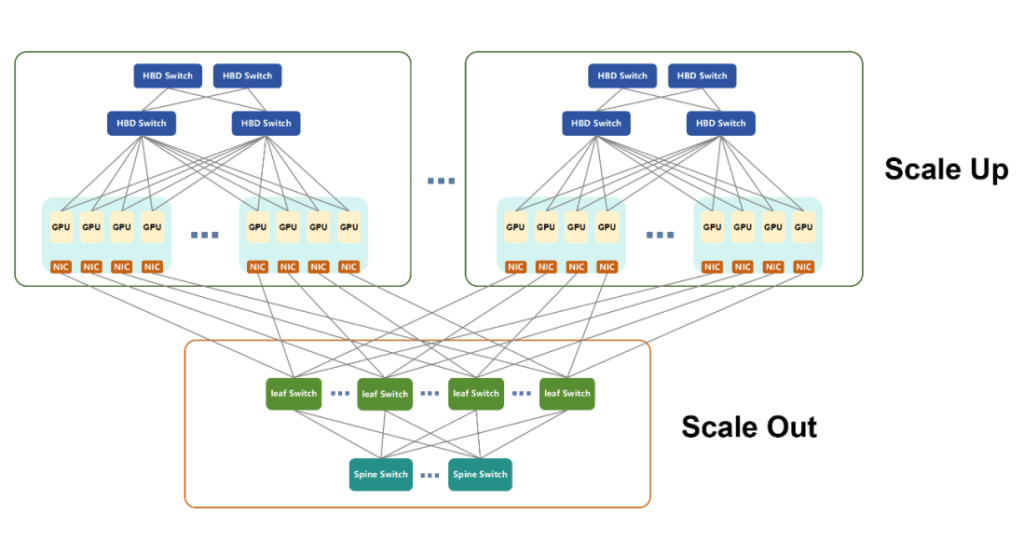
Supernodes basieren auf der Scale-Up-Architektur und sind über interne Hochgeschwindigkeitsbusse miteinander verbunden. Sie bieten effiziente Unterstützung für paralleles Rechnen, GPU-Parameteraustausch und Datensynchronisierung. Sie ermöglichen außerdem den direkten Speicherzugriff zwischen GPUs, eine Funktion, die Scale-Out fehlt.
Aus Sicht der Bereitstellung und Wartung:
- Größere High Bandwidth Domains (HBDs) vereinfachen das Scale-Out-Netzwerk.
- Vorintegrierte Scale-Up-Systeme reduzieren die Komplexität, verkürzen die Bereitstellungszeit und erleichtern den langfristigen Betrieb.
Allerdings ist eine unbegrenzte Skalierung aufgrund von Kostenbeschränkungen nicht möglich. Die optimale Skalierung hängt von den jeweiligen Nutzungsszenarien ab.
Eine gemeinsame Zukunft?
Letztendlich stellen Scale-Up und Scale-Out einen Kompromiss zwischen Leistung und Kosten dar. Mit der Weiterentwicklung der Technologie dürfte die Grenze zwischen beiden verschwimmen. Neue offene Scale-Up-Standards wie ETH-X, basierend auf Ethernet, bieten vielversprechende Leistungskennzahlen:
- Switch-Chip-Kapazität: Bis zu 51.2 Tbps
- SerDes-Geschwindigkeit: Bis zu 112 Gbit/s
- Latenz: Nur 200 Nanosekunden
Da Scale Out auch Ethernet nutzt, deutet diese Konvergenz auf eine einheitliche Architektur hin, bei der ein einziger Standard beiden Erweiterungsmodellen in zukünftigen Computer-Ökosystemen zugrunde liegen könnte.
Trends in der Entwicklung von KI-Rechenclustern
Da der Bereich der künstlichen Intelligenz (KI) immer weiter wächst, entwickeln sich KI-Rechencluster entlang mehrerer wichtiger Entwicklungspfade:
Geografische Verteilung der physischen Infrastruktur
KI-Cluster skalieren zunehmend auf Konfigurationen mit Zehntausenden oder sogar Hunderttausenden von KI-Karten. Zum Beispiel:
- Das NVL72-Rack von NVIDIA integriert 72 Chips.
- Der CM384 von Huawei setzt 384 Chips auf 16 Racks ein.
Für den Aufbau eines 100,000-Karten-Clusters mit Huaweis CM384-Architektur wären 432 CM384-Einheiten erforderlich – das entspricht 165,888 Chips und 6,912 Racks. Ein solcher Umfang übersteigt die physische und elektrische Kapazität eines einzelnen Rechenzentrums bei weitem.
Daher erforscht die Branche aktiv verteilte Rechenzentrumsimplementierungen, die als einheitlicher KI-Rechencluster fungieren können. Diese Architekturen basieren stark auf fortschrittlichen optischen DCI-Kommunikationstechnologien (Data Center Interconnect), die eine Übertragung über große Entfernungen, mit hoher Bandbreite und geringer Latenz unterstützen müssen. Innovationen wie Hohlkern-Glasfasern werden voraussichtlich schneller Verbreitung finden.
Anpassung der Knotenarchitektur
Der traditionelle Ansatz zum Aufbau von KI-Clustern konzentrierte sich oft auf die Maximierung der Anzahl von KI-Chips. Allerdings wird zunehmend Wert auf ein tiefgreifendes Architekturdesign gelegt, das über die bloße Menge hinausgeht.
Zu den neuen Trends gehört die Bündelung von Rechenressourcen – wie GPUs, NPUs, CPUs, Arbeitsspeicher und Speicher – um hochgradig anpassungsfähige Cluster zu erstellen, die auf die Anforderungen groß angelegter KI-Modelle zugeschnitten sind, einschließlich Architekturen wie Mixture of Experts (MoE).
Kurz gesagt: Die Lieferung nackter Chips reicht nicht mehr aus. Um optimale Leistung und Effizienz zu gewährleisten, sind zunehmend maßgeschneiderte, szenariospezifische Designs erforderlich.
Intelligenter Betrieb und Wartung
Das Training großer KI-Modelle ist bekanntermaßen fehleranfällig. Fehler können innerhalb weniger Stunden auftreten. Jeder Fehler erfordert ein erneutes Training, verlängert die Entwicklungszeit und erhöht die Betriebskosten.
Um diese Risiken zu minimieren, legen Unternehmen Wert auf die Zuverlässigkeit und Stabilität ihrer Systeme und integrieren intelligente Betriebs- und Wartungstools. Diese Systeme bieten folgende Vorteile:
- Mögliche Fehler vorhersagen
- Identifizieren Sie suboptimale oder sich verschlechternde Hardware
- Aktivieren Sie den proaktiven Komponentenaustausch
Solche Ansätze reduzieren die Fehlerraten und Ausfallzeiten erheblich, stärken dadurch die Clusterstabilität und verbessern effektiv die Gesamtrechenleistung.
Energieeffizienz und Nachhaltigkeit
KI-Berechnungen erfordern einen enormen Energieverbrauch, was führende Anbieter dazu veranlasst, Strategien zur Reduzierung des Stromverbrauchs und zur stärkeren Nutzung erneuerbarer Energiequellen zu entwickeln.
Dieser Vorstoß für grüne Computercluster steht im Einklang mit umfassenderen Nachhaltigkeitsinitiativen wie Chinas Strategie „East Data, West Compute“, die darauf abzielt, die Energiezuteilung zu optimieren und die langfristige ökologische Entwicklung der KI-Infrastruktur zu fördern.
Ähnliche Produkte:
-
 QSFP-DD-400G-SR8 400G QSFP-DD SR8 PAM4 850 nm 100 m optisches MTP / MPO OM3 FEC-Transceiver-Modul
$149.00
QSFP-DD-400G-SR8 400G QSFP-DD SR8 PAM4 850 nm 100 m optisches MTP / MPO OM3 FEC-Transceiver-Modul
$149.00
-
 QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310 nm 500 m MTP / MPO SMF FEC Optisches Transceiver-Modul
$400.00
QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310 nm 500 m MTP / MPO SMF FEC Optisches Transceiver-Modul
$400.00
-
 QSFP-DD-400G-SR4 QSFP-DD 400G SR4 PAM4 850 nm 100 m MTP/MPO-12 OM4 FEC Optisches Transceiver-Modul
$450.00
QSFP-DD-400G-SR4 QSFP-DD 400G SR4 PAM4 850 nm 100 m MTP/MPO-12 OM4 FEC Optisches Transceiver-Modul
$450.00
-
 QSFP-DD-400G-FR4 400G QSFP-DD FR4 PAM4 CWDM4 2 km LC SMF FEC Optisches Transceiver-Modul
$500.00
QSFP-DD-400G-FR4 400G QSFP-DD FR4 PAM4 CWDM4 2 km LC SMF FEC Optisches Transceiver-Modul
$500.00
-
 QSFP-DD-400G-XDR4 400G QSFP-DD XDR4 PAM4 1310nm 2km MTP/MPO-12 SMF FEC Optisches Transceiver-Modul
$580.00
QSFP-DD-400G-XDR4 400G QSFP-DD XDR4 PAM4 1310nm 2km MTP/MPO-12 SMF FEC Optisches Transceiver-Modul
$580.00
-
 QSFP-DD-400G-LR4 400G QSFP-DD LR4 PAM4 CWDM4 10 km LC SMF FEC Optisches Transceiver-Modul
$600.00
QSFP-DD-400G-LR4 400G QSFP-DD LR4 PAM4 CWDM4 10 km LC SMF FEC Optisches Transceiver-Modul
$600.00
-
 QDD-4X100G-FR-Si QSFP-DD 4 x100G FR PAM4 1310 nm 2 km MTP/MPO-12 SMF FEC CMIS3.0 Optisches Transceivermodul für Siliziumphotonik
$650.00
QDD-4X100G-FR-Si QSFP-DD 4 x100G FR PAM4 1310 nm 2 km MTP/MPO-12 SMF FEC CMIS3.0 Optisches Transceivermodul für Siliziumphotonik
$650.00
-
 QDD-4X100G-FR-4Si QSFP-DD 4 x 100G FR PAM4 1310 nm 2 km MTP/MPO-12 SMF FEC CMIS4.0 Optisches Transceivermodul für Siliziumphotonik
$750.00
QDD-4X100G-FR-4Si QSFP-DD 4 x 100G FR PAM4 1310 nm 2 km MTP/MPO-12 SMF FEC CMIS4.0 Optisches Transceivermodul für Siliziumphotonik
$750.00
-
 QSFP-DD-400G-SR4.2 400 Gbit/s QSFP-DD SR4 BiDi PAM4 850 nm/910 nm 100 m/150 m OM4/OM5 MMF MPO-12 FEC Optisches Transceiver-Modul
$900.00
QSFP-DD-400G-SR4.2 400 Gbit/s QSFP-DD SR4 BiDi PAM4 850 nm/910 nm 100 m/150 m OM4/OM5 MMF MPO-12 FEC Optisches Transceiver-Modul
$900.00
-
 Arista Q112-400G-SR4 kompatibles 400G QSFP112 SR4 PAM4 850 nm 100 m MTP/MPO-12 OM3 FEC optisches Transceiver-Modul
$450.00
Arista Q112-400G-SR4 kompatibles 400G QSFP112 SR4 PAM4 850 nm 100 m MTP/MPO-12 OM3 FEC optisches Transceiver-Modul
$450.00
-
 Cisco Q112-400G-DR4-kompatibles 400G NDR QSFP112 DR4 PAM4 1310 nm 500 m MPO-12 mit optischem FEC-Transceiver-Modul
$650.00
Cisco Q112-400G-DR4-kompatibles 400G NDR QSFP112 DR4 PAM4 1310 nm 500 m MPO-12 mit optischem FEC-Transceiver-Modul
$650.00
-
 OSFP-800G-DR8D-FLT 800G-DR8 OSFP Flat Top PAM4 1310 nm 500 m DOM Dual MTP/MPO-12 SMF Optisches Transceiver-Modul
$1199.00
OSFP-800G-DR8D-FLT 800G-DR8 OSFP Flat Top PAM4 1310 nm 500 m DOM Dual MTP/MPO-12 SMF Optisches Transceiver-Modul
$1199.00
-
 OSFP-800G-SR8D-FLT OSFP 8x100G SR8 Flat Top PAM4 850 nm 100 m DOM Dual MPO-12 MMF optisches Transceiver-Modul
$650.00
OSFP-800G-SR8D-FLT OSFP 8x100G SR8 Flat Top PAM4 850 nm 100 m DOM Dual MPO-12 MMF optisches Transceiver-Modul
$650.00
-
 OSFP-800G-SR8D OSFP 8x100G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optisches Transceiver-Modul
$650.00
OSFP-800G-SR8D OSFP 8x100G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optisches Transceiver-Modul
$650.00
-
 OSFP-800G-DR8D 800G-DR8 OSFP PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optisches Transceiver-Modul
$850.00
OSFP-800G-DR8D 800G-DR8 OSFP PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optisches Transceiver-Modul
$850.00
-
 OSFP-800G-2FR4L OSFP 2x400G FR4 PAM4 1310 nm 2 km DOM Dual Duplex LC SMF Optisches Transceiver-Modul
$1200.00
OSFP-800G-2FR4L OSFP 2x400G FR4 PAM4 1310 nm 2 km DOM Dual Duplex LC SMF Optisches Transceiver-Modul
$1200.00