
With the AI boom triggered by ChatGPT, GPUs have become the cornerstone of AI big model training platforms, and can even be said to be the decisive arithmetic base. To answer the question of why GPU is needed for AI training, it is essential to understand the primary technologies in artificial intelligence (AI) and deep learning.
Artificial Intelligence and Deep Learning
Artificial Intelligence is a discipline with a long history. Since the 1950s, it has been explored in various technological directions, experiencing several peaks and troughs. Artificial Intelligence’s early days gave rise to a somewhat unsuccessful genre known as “Artificial Neural Networks.” The concept behind this technology was that the human brain’s intelligence is unparalleled, and to achieve advanced artificial intelligence, mimicking the human brain is the key. The human brain consists of billions of neurons interconnected to form a vast and intricate neural network. A baby’s brain is like a blank slate that, through postnatal learning, can achieve high levels of intelligence.
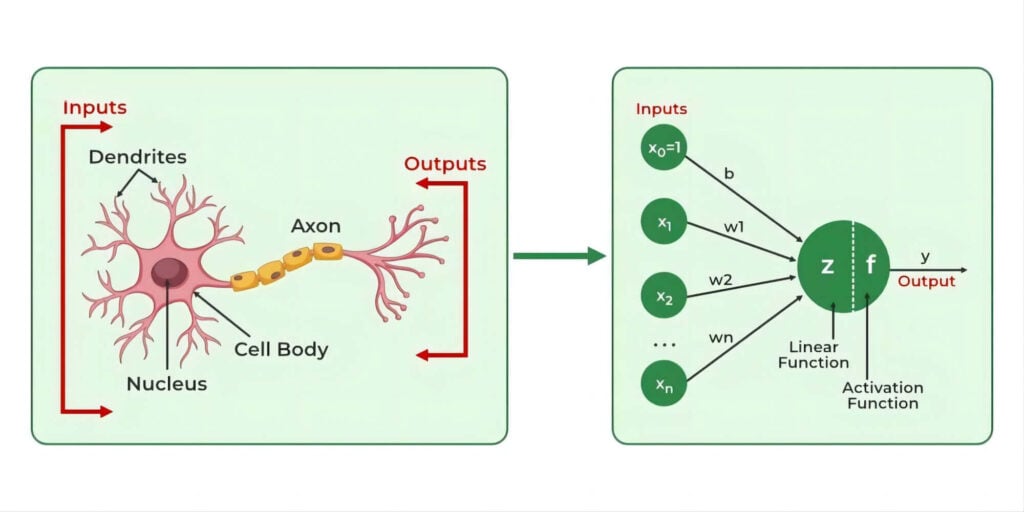
Artificial neuron models were devised to draw inspiration from the human brain’s neurons. In the artificial neurons on the right side of the diagram, adjusting the weight of each input and processing it through the neuron yields the corresponding output. Each weight in this context is referred to as a parameter.
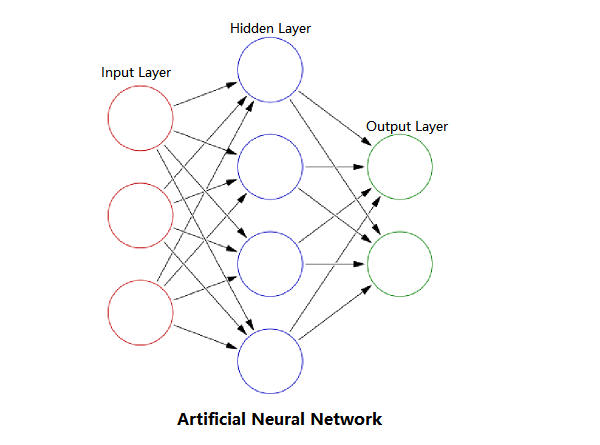
Connecting multiple neurons like this to form a network results in an artificial neural network. Artificial neural networks typically consist of an input layer, several hidden layers in between, and an output layer.
Such artificial neural networks are akin to a baby’s brain – empty and in need of substantial data feeding to learn comprehensively to acquire knowledge for practical problem-solving. This process is known as “deep learning” and falls under the subset of “machine learning.”

In the commonly used “supervised learning” approach, the data fed to the AI must contain both the problem and the answer. For example, if the goal is to train the AI to detect whether a picture contains a cat, we need to provide the AI with many images labeled as containing a cat, along with the defining features of cats. The AI will then use these examples to learn the patterns and characteristics of cats.
The learning process begins with the AI analyzing a given image using its initial set of parameters. It then compares its conclusion to the correct answer and adjusts the parameter weights accordingly. This iterative process continues until the AI’s output closely matches the correct answer.
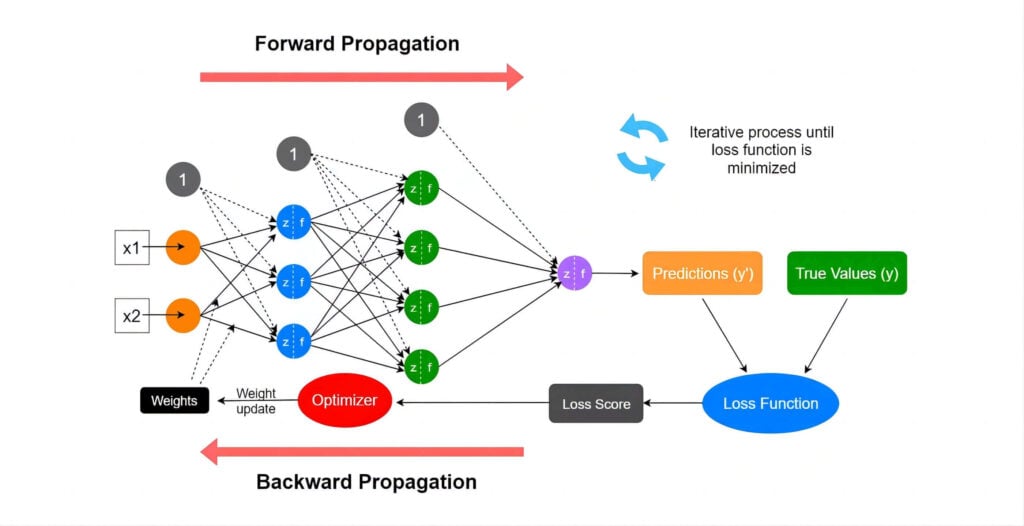
This learning process is called training. Generally, providing the AI with a large amount of data with known correct answers will result in better training outcomes. Once we are satisfied with the training, we can test the AI’s performance on unknown problems. If the AI can accurately find the answers, we consider the training successful, and the AI has demonstrated good “generalization” capabilities”.
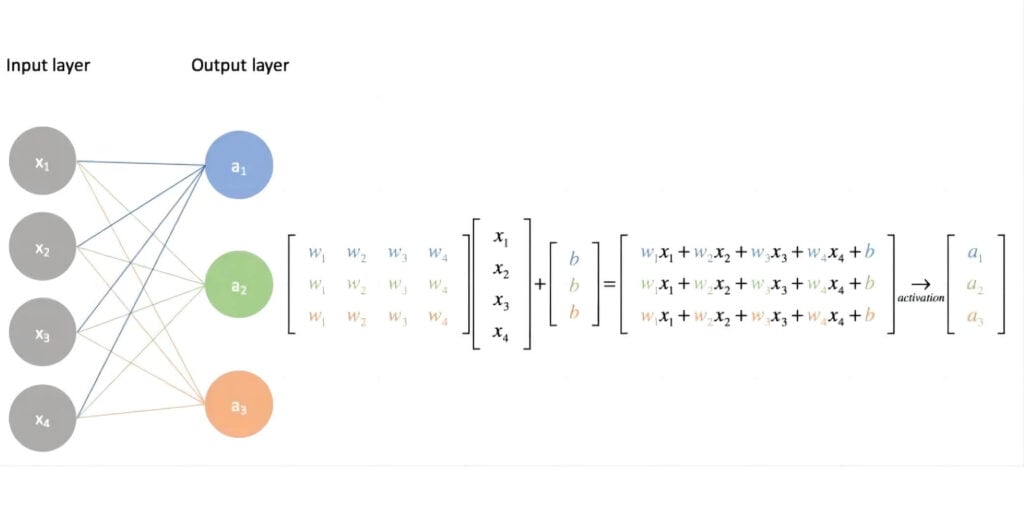
As shown in the diagram, the transfer of parameter weights from one layer of the neural network to the next is essentially matrix multiplication and addition. The larger the scale of the neural network parameters, the more extensive the matrix computations required during training.
The most advanced deep-learning neural networks can have hundreds of millions to trillions of parameters, and they require vast amounts of training data to achieve high accuracy. This means they must process an enormous number of input samples through forward and backward propagation. Since neural networks are built from a large number of identical neurons, these computations are inherently highly parallel. Given the massive computational demands, should we use a CPU or a GPU?
CPU vs. GPU
The CPU (Central Processing Unit) is the brain of the computer, the core of the core. It primarily consists of an Arithmetic Logic Unit (ALU) for performing computations and a Control Unit (CU) for managing the flow of data and instructions.
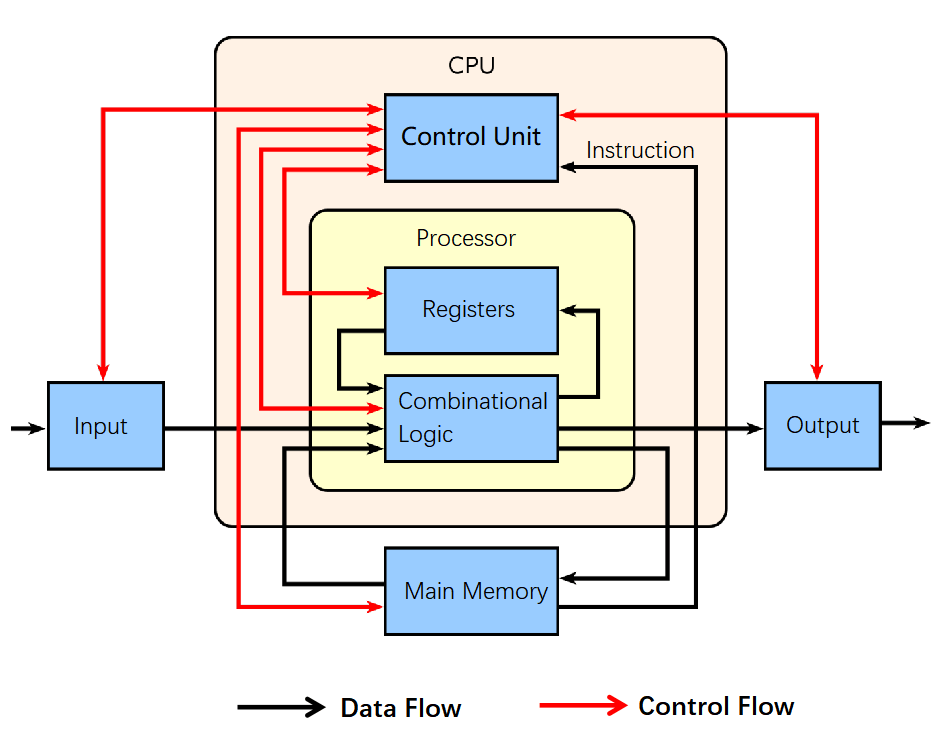
When data arrives, it is first stored in memory. The Control Unit then retrieves the relevant data from memory and passes it to the ALU for processing. After the computation is complete, the result is stored back in memory.
In the early days, a CPU had a single set of ALU, CU, and cache, and could only process one task at a time. To handle multiple tasks, the CPU would have to queue them and execute them sequentially, sharing the resources.
Later, multiple sets of ALU, CU, and cache were integrated onto a single chip, creating a multi-core CPU. Multi-core CPUs have true parallel processing capabilities.
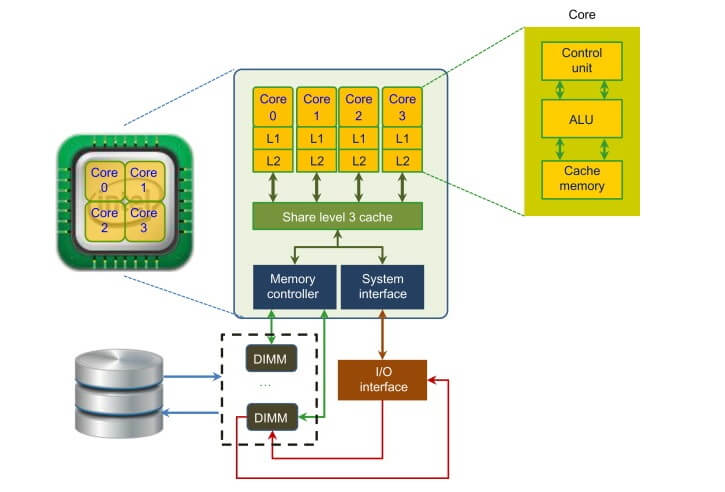
Typically, modern CPUs have anywhere from a few to dozens of cores. When smartphones were first becoming widespread, manufacturers heavily emphasized the core count, leading to a “core war” in the smartphone market. However, this core count race eventually plateaued, and chip manufacturers focused on optimizing the core performance.
Why don’t CPUs integrate even more cores? This is because the CPU is a general-purpose processor. Its tasks are highly complex, requiring it to handle various types of data computations and respond to human-computer interactions. The complex task management and scheduling necessitate more sophisticated control units and larger caches to maintain low latency when switching between tasks. As the number of cores increases, the communication overhead between the cores also rises, which can degrade the performance of individual cores. Additionally, having more cores can increase power consumption, and if the workload is not evenly distributed, the overall performance may not improve, and could even decrease.
GPU, Parallel Computing Expert
Let’s delve into the realm of GPU. The GPU, also known as the Graphics Processing Unit, was originally designed to alleviate the burden on the CPU, accelerating the rendering of three-dimensional graphics, commonly used in computer graphics cards. Image processing is essentially a form of intensive parallel computing focused on matrices. As depicted in the diagram below, the image on the left is composed of numerous pixels and can be naturally represented as a matrix on the right.

The term “GPU” gained popularity in 1999 with Nvidia’s release of the GeForce256, a product that simultaneously processes each pixel point, performing mathematically intensive parallel computations such as graphic transformations, lighting, and triangle clipping for image rendering.
The proficiency of GPUs in handling intensive parallel computing stems from their architectural differences compared to CPUs. CPUs have fewer cores, with each core possessing ample cache and robust computational capabilities, along with hardware support for numerous acceleration branch predictions and even more complex logical judgments, making them suitable for handling intricate tasks.
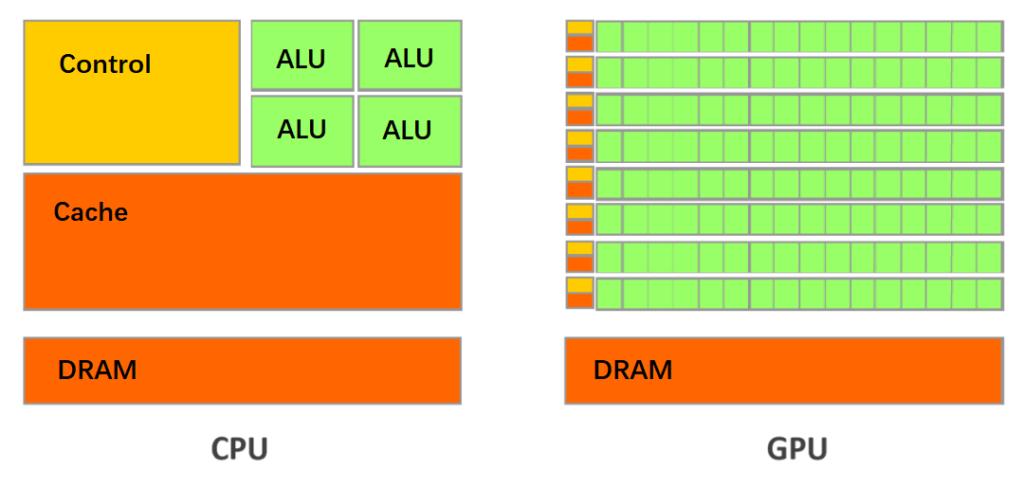
In contrast, GPUs are more straightforward and brute-force; each core has limited computational power and cache size, relying on increasing core counts to enhance overall performance. With a higher number of cores, GPUs can multitask efficiently by processing a large volume of simple parallel computing tasks.
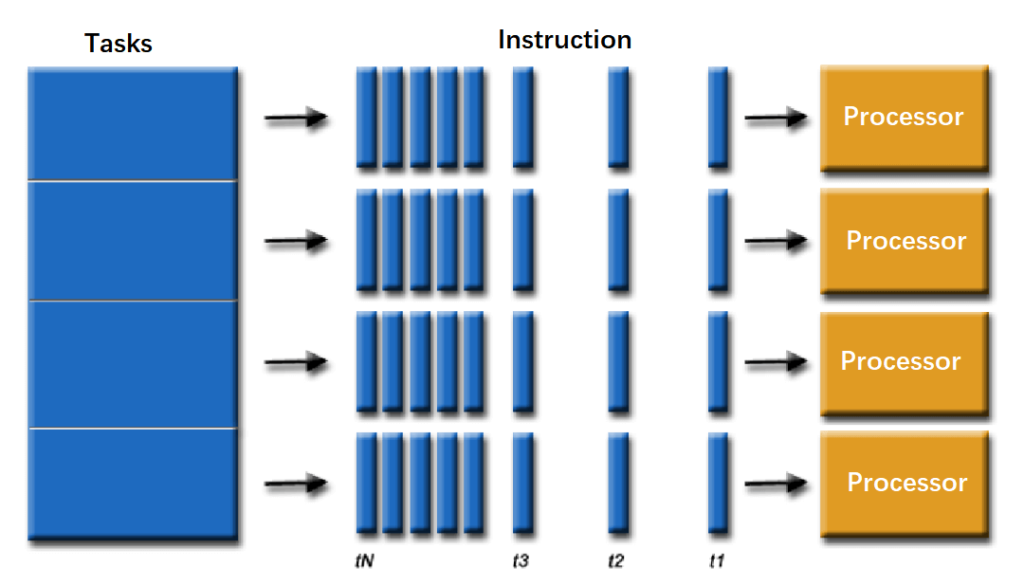
Over time, GPUs have evolved to become more versatile and programmable, extending their functionality beyond image display rendering to accelerate high-performance computing, deep learning, and other workloads. Seizing the opportunity presented by the surge in demand for parallel computing driven by artificial intelligence, GPUs have transitioned from their previous peripheral role to take center stage, becoming highly sought after. The term “GPU” has transformed into GPGPU, denoting General-Purpose GPU. Leveraging the inherent parallelism of AI training onto GPUs significantly boosts speed compared to training solely using CPUs, making them the preferred platform for training large-scale, complex neural network-based systems. The parallel nature of inference operations aligns well with execution on GPUs. Hence, the computational power provided by GPUs as the primary force is referred to as “intelligent computing.”
Related Products:
-
 OSFP-XD-1.6T-4FR2 1.6T OSFP-XD 4xFR2 PAM4 1291/1311nm 2km SN SMF Optical Transceiver Module
$15000.00
OSFP-XD-1.6T-4FR2 1.6T OSFP-XD 4xFR2 PAM4 1291/1311nm 2km SN SMF Optical Transceiver Module
$15000.00
-
OSFP-XD-1.6T-2FR4 1.6T OSFP-XD 2xFR4 PAM4 2x CWDM4 2km Dual Duplex LC SMF Optical Transceiver Module
$20000.00
-
OSFP-XD-1.6T-DR8 1.6T OSFP-XD DR8 PAM4 1311nm 2km MPO-16 SMF Optical Transceiver Module
$12000.00
-
NVIDIA MMS4X50-NM Compatible OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF Optical Transceiver Module
$1200.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$700.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA MMA1Z00-NS400 Compatible 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$550.00
-
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00











