History and Standards
InfiniBand, developed in the late 1990s, was designed for high-speed, low-latency interconnects in HPC environments. It operates under standards set by the InfiniBand Trade Association (IBTA), with modern versions like HDR and NDR supporting speeds up to 400 Gbps. Ethernet, dating back to the 1970s, is governed by the IEEE 802.3 standards and has evolved from 10 Mbps to 400 Gbps and beyond, making it a flexible choice for diverse applications. Understanding their historical context and standards helps clarify their roles in modern networking.
What is the InfiniBand Network?
The InfiniBand architecture brings fabric consolidation to the data center Storage networking can concurrently run with clustering, communication and management fabrics over the same infrastructure, preserving the behavior of multiple fabrics.
InfiniBand is an open standard network interconnection technology with high bandwidth, low delay and high reliability. This technology is defined by IBTA (InfiniBand trade alliance). This technology is widely used in the field of supercomputer cluster. At the same time, with the rise of artificial intelligence, it is also the preferred network interconnection technology for GPU server.
High Speed Interconnection (HSI) has become the key to the development of high performance computers as the computing power of the Central Processing Unit (CPU) is increasing at a very fast pace. HSI is a new technology proposed to improve the performance of the Peripheral Component Interface (PCI). After years of development, HSIs supporting High Performance Computing (HPC) are now mainly Gigabit Ethernet and InfiniBand, of which InfiniBand is the fastest growing HSI. InfiniBand is a high-performance, low-latency technology developed under the supervision of the InfiniBand Trade Association (IBTA).
IBTA was founded in 1999 as a merger of two industry organizations, Future I/O Developers Forum and NGI/O Forum. It works under the leadership of a planning and operating committee consisting of HP, IBM, Intel, Mellanox, Oracle, QLogic, Dell, Bull, and others. IBTA specializes in product compliance and interoperability testing, and its members have been working to advance the establishment and updating of the InfiniBand specification.
The InfiniBand standard supports single data rate (SDR) signaling at a basic rate of 2.5Gbits/sec per lane to allow raw data rate of 10Gbits/sec over 4X cables (the most common InfiniBand cable type used). Double data rate (DDR) and quad data rate (QDR) signaling permit single lanes to be scaled up to 5Gbits/sec and 10Gbits/sec per lane, respectively, for a potential maximum data rate of 40Gbits/sec over 4X and 120Gbits/sec over 12X cables.
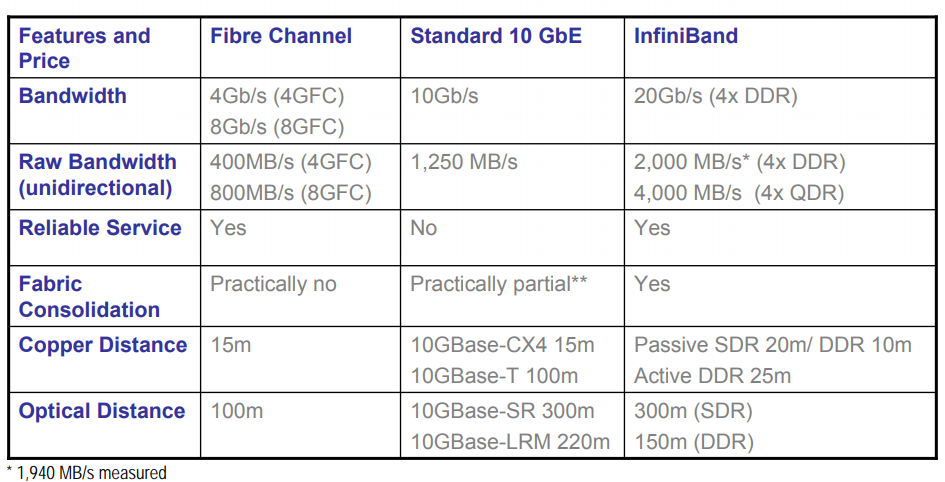
Comparison of networking technologies
At present, the latest InfiniBand product is the HDR produced by Mellanox, which can provide end-to-end bandwidth of up to 200gbps for the network, bring unparalleled network experience for high-performance computing, artificial intelligence, and other fields, and maximize the computing potential in the cluster.
As a computer cluster interconnection technology, InfiniBand has significant advantages over Ethernet/Fibre Channel and the obsolete Omni-Path technology, and is the primary recommended network communication technology by the InfiniBand Trade Association (IBTA). Since 2014, most of the TOP500 supercomputers have adopted InfiniBand networking technology. In recent years, AI/Big Data-related applications have also adopted IB networks on a large scale to achieve high-performance cluster deployments, with 62% of the Top100 supercomputing centers using InfiniBand technology (June 2022 data).
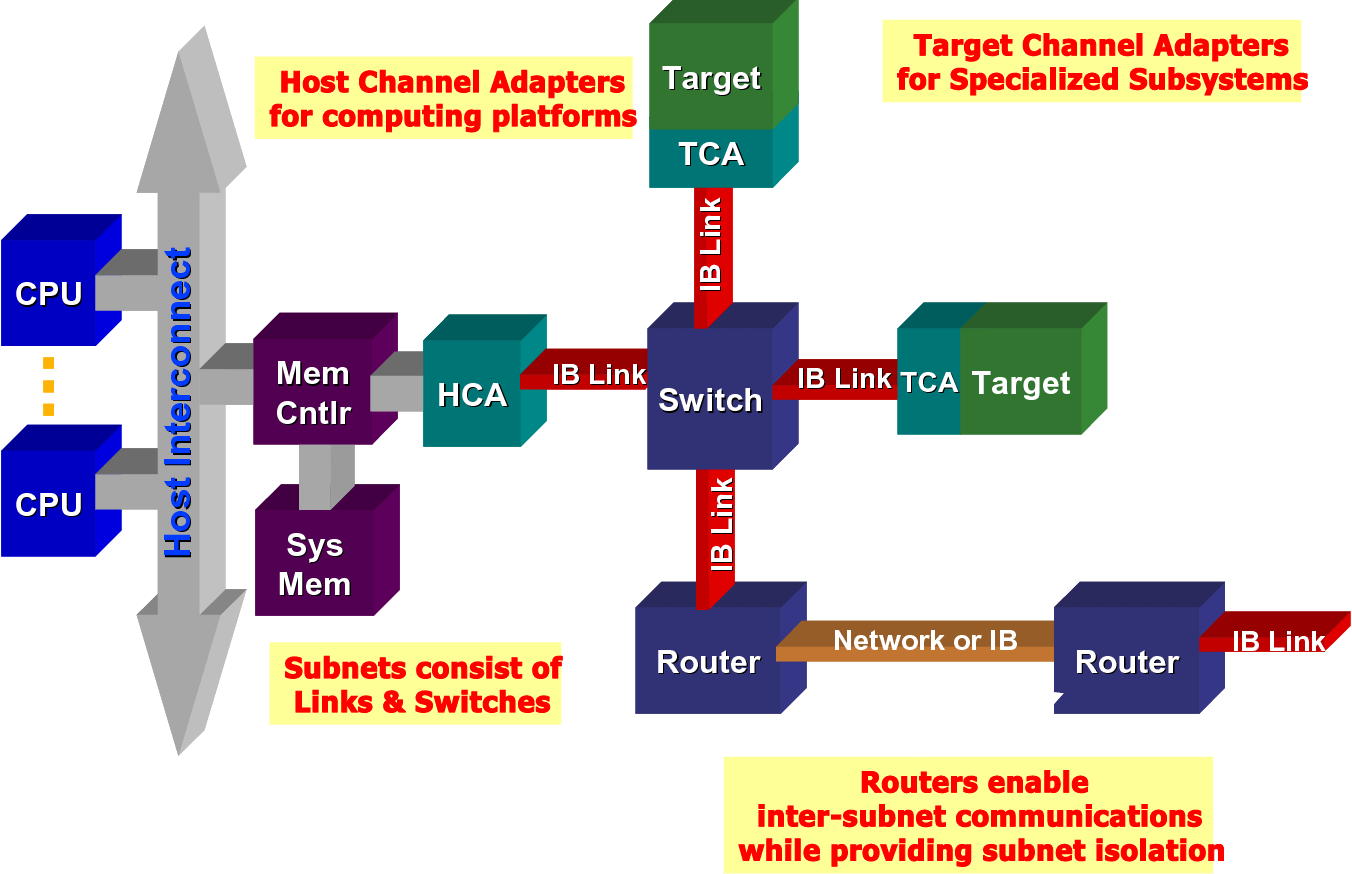
InfiniBand Overview
InfiniBand is a communication link for data flow between processors and I/O devices, supporting up to 64,000 addressable devices. InfiniBand Architecture (IBA) is an industry standard specification that defines a point-to-point switched input/output framework for interconnecting servers, communications infrastructure, storage devices, and embedded systems.
InfiniBand is ideal for connecting multiple data streams (clustering, communication, storage, management) in a single connection, with thousands of interconnected nodes, due to its pervasive, low latency, high bandwidth, and low management cost. The smallest complete IBA unit is a subnet, and multiple subnets are connected by routers to form a large IBA network.
InfiniBand systems consist of channel adapters, switches, routers, cables, and connectors. The CA is divided into a Host Channel Adapter (HCA) and a Target Channel Adapter (TCA). IBA switches are similar in principle to other standard network switches, but must meet the high performance and low cost requirements of InfiniBand. An HCA is a device point through which an IB end node, such as a server or storage device, connects to an IB network. TCAs are a special form of channel adapters, mostly used in embedded environments such as storage devices.
The InfiniBand architecture is shown in the figure.
What’s 200G InfiniBand HDR?
InfiniBand supports SDR/DDR/QDR/FDR/EDR transmission to increase link bandwidth. Recently, Mellanox released 200G InfiniBand supporting HDR. Mellanox recently released 200G InfiniBand with HDR support. Mellanox 200Gb/s HDR InfiniBand networks support ultra-low latency, high data throughput, and intelligent network compute acceleration engines. Users can use standard Mellanox software drivers on the cloud, just as they would in a Bare Metal environment. With support for RDMA verbs, all InfiniBand-based MPI software such as Mellanox HPC-X, MVAPICH2, Platform MPI, Intel MPI, and more can be used.
In addition, users can also take advantage of the hardware offload feature of MPI cluster communication for additional performance gains, which also improves the efficiency of business applications. 200G InfiniBand has a wide range of applications, including in-network computing acceleration engines, HDR InfiniBand adapters, HDR InfiniBand Quantum switches and 200G cabling.

InfiniBand applications
As for the 200G InfiniBand cabling, the final piece of the Mellanox 200Gbs solution is its line of LinkX cables. Mellanox offers direct-attach 200G copper cables reaching up to 3 meters and 2 x 100G splitter breakout cables to enable HDR100 links, as well as 200G active optical cables that reach up to 100 meters. All LinkX cables in the 200Gb/s line come in standard QSFP56 packages.
What are the Advantages of InfiniBand Network?
- Serial High Bandwidth Links
– SDR: 10Gb/s
– DDR: 20Gb/s
– QDR: 40Gb/s
– FDR: 56Gb/s
– EDR: 100Gb/s
– HDR: 200Gb/s
- Ultra-low latency
– Under 1 us application to application
- Reliable, lossless, self-managing fabric
– Link level flow control
– Congestion control to prevent HOL blocking
- Full CPU Offload
– Hardware-Based Reliable Transport Protocol
– Kernel Bypass (User level applications get direct access to hardware)
- Memory exposed to remote node access – RDMA-read and RDMA-write
– Atomic operations
- Quality Of Service
– Independent I/O channels at the adapter level
– Virtual Lanes at the link level
- Cluster Scalability/flexibility
– Up to 48K nodes in subnet, up to 2^128 in network
– Parallel routes between end nodes
– Multiple cluster topologies possible
- Simplified Cluster Management
– Centralized route manager
– In-band diagnostics and upgrades
What is an Ethernet Network?
Ethernet refers to the baseband LAN specification standard created by Xerox company and jointly developed by Xerox, Intel, and DEC company. The general Ethernet standard was issued on September 30, 1980. It is the most general communication protocol standard adopted by the existing LAN. It transmits and receives data through cables. Ethernet network is used to create local area networks and connect multiple computers or other devices such as printers, scanners, and so on. In a wired network, this is done with the help of fiber optic cables, while in a wireless network, it is done through wireless network technology. The main types of Ethernet networks are Fast Ethernet, Gigabit Ethernet, 10-Gigabit Ethernet and Switch Ethernet.
At present, the IEEE 802.3 Standard Organization organized by IEEE has issued Ethernet interface standards of 100GE, 200GE, and 400GE. Ethernet network is the transmission technology with the highest rate at present.
InfiniBand vs Ethernet: What’s the Difference?
As interconnection technologies, InfiniBand and Ethernet have their own characteristics and differences. They are developing and evolving in their different application fields, and have become two indispensable Interconnection Technologies in our network world.
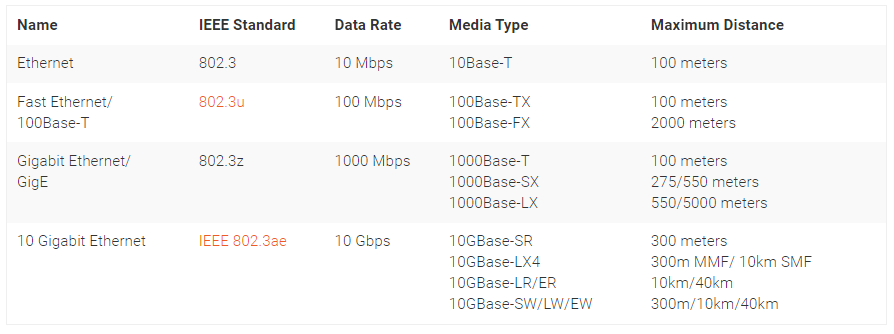
Types of Ethernet Networks
In terms of the Ethernet network, along with the IP technology, they constitute the cornerstone of the whole Internet building in the world. All people and intelligent devices rely on Ethernet to realize the interconnection of all things, which is related to the original intention of its design to achieve better compatibility. It can make different systems better interconnected, which makes Ethernet have very strong adaptability since its birth. After decades of development, it has become the standard of the Internet.
In terms of the InfiniBand network, it is an interconnection standard to solve the data transmission bottleneck in high-performance computing scenarios. It has been positioned as a high-end application since its formulation. Interconnection is not the main contradiction, and high-performance communication is the main entry point. Infiniband is a newer type of connection that was recently released. The great thing about it is the speed that users are provided with. While the speed for your connection will ultimately depend on what wire you choose, the speeds for them can go up to 40Gbps or evermore.
Therefore, compared with Ethernet technology, InfiniBand is inherently different from Ethernet due to different positioning, mainly in bandwidth, delay, network reliability and networking mode. InfiniBand directly creates a private and protected channel between nodes through switches to transmit data and messages without CPU participating in remote direct memory access (RDMA). One end of the adapter is connected to the CPU through the PCI Express interface, and the other end is connected to the InfiniBand subnet through the InfiniBand network port. Compared with other network communication protocols, this provides obvious advantages, including higher bandwidth, lower latency and enhanced scalability.
Technical Comparison of InfiniBand and Ethernet
Basic Architecture and Topology
InfiniBand uses a switched fabric architecture, enabling point-to-point connections with minimal latency. Its topology, often a fat-tree or torus, is optimized for HPC and AI clusters, supporting remote direct memory access (RDMA) for efficient data transfer. Ethernet, built on a layered architecture (e.g., TCP/IP), supports diverse topologies like star or mesh, making it adaptable but potentially less efficient for AI-specific tasks. InfiniBand’s streamlined design gives it an edge in latency-sensitive environments, while Ethernet’s flexibility suits broader applications.
Key Technical Specifications
InfiniBand leverages protocols like RDMA over Converged Ethernet (RoCE) and supports both copper and fiber cabling, with high-bandwidth options like NDR (400 Gbps). Ethernet, with standards like 100GbE and 400GbE, supports similar cabling but relies on TCP/IP or UDP for data transfer, which can introduce overhead. InfiniBand’s hardware, such as host channel adapters (HCAs), is optimized for specific workloads, while Ethernet’s switches and NICs are more generalized, impacting performance in niche scenarios.
Latency and Speed Comparisons
InfiniBand excels in latency, often achieving sub-microsecond delays, critical for AI training where GPUs or TPUs exchange massive datasets. Ethernet, while fast (e.g., 100GbE with ~1-2 µs latency), typically lags due to protocol overhead. Speed-wise, both technologies offer comparable headline rates (e.g., 400 Gbps), but InfiniBand’s RDMA and congestion management ensure more consistent performance under heavy AI workloads.
Bandwidth and Data Transfer Rates
InfiniBand’s high bandwidth (up to 400 Gbps per port in NDR) supports the massive data transfer needs of AI model training and large-scale simulations. Ethernet matches these rates in high-end configurations but may face bottlenecks in congested networks due to its reliance on TCP/IP. For data centers handling petabytes of data, InfiniBand’s predictable throughput is a key advantage.
Scalability in Expanding Networks
InfiniBand scales efficiently in large clusters, with its fabric architecture minimizing latency as nodes increase. Its native support for partitioning and quality of service (QoS) ensures performance in complex AI environments. Ethernet scales well in enterprise settings but may require advanced configurations (e.g., spine-leaf architectures) to match InfiniBand’s efficiency in HPC or AI clusters.
Performance and Scalability
For AI workloads, InfiniBand’s low latency and high bandwidth provide superior performance, particularly for distributed training across GPU clusters. Ethernet performs well in general-purpose data centers but may struggle with the extreme demands of AI model synchronization. Both technologies scale, but InfiniBand’s design is better suited for massive, tightly coupled networks, while Ethernet excels in heterogeneous environments.
Application Scenarios and Use Cases
InfiniBand dominates in data center and cloud deployments for AI, HPC, and big data analytics, powering systems like NVIDIA’s DGX platforms. It’s also prevalent in scientific and research institutions, supporting simulations in physics or genomics. Ethernet is preferred in enterprise data centers, cloud providers like AWS, and applications requiring broad compatibility, such as web hosting or storage networks. For AI-specific needs, InfiniBand’s performance edge makes it the go-to choice.
InfiniBand vs Omni-Path: Advantages of InfiniBand over Omni-Path
Although NVIDIA has launched the InfiniBand 400G NDR solution, some customers are still using 100G solution. For 100G high-performance networks, there are two common solutions, Omni-Path and InfiniBand, which have the same rate and similar performance, but the network structure is vastly different. For example, for a 400-node cluster, InfiniBand requires only 15 NVIDIA Quantum 8000 series switches and 200 200G branch cables, and 200 200G direct cables, while Omni-Path requires 24 switches and 876 100G direct cables (384 nodes). InfiniBand is very advantageous in the early equipment cost and later operation and maintenance cost, and the overall power consumption is much lower than Omni-Path, which is more environmentally friendly.
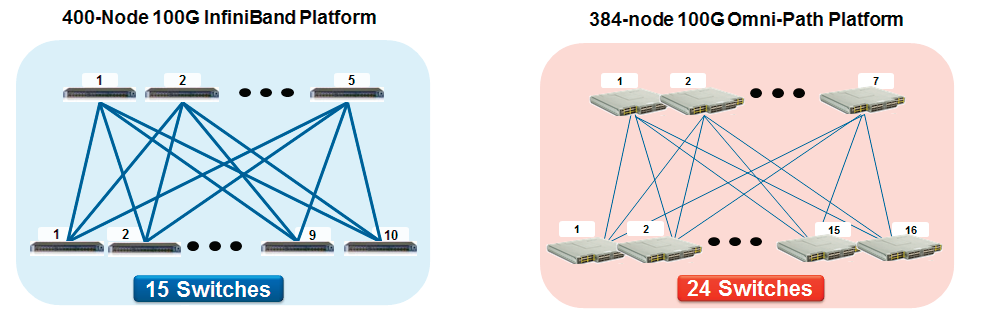
InfiniBand HDR Product Introduction
EDR is being phased out of the market in terms of client demand, the NDR rate is too high and only head customers are trying to use it. HDR is widely used with the flexibility of HDR 100G and HDR 200G.
HDR Switch
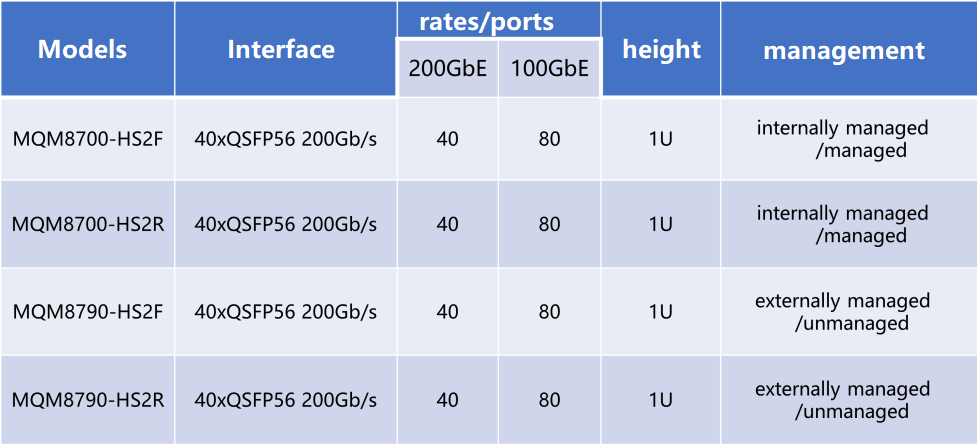
There are two types of HDR switches. One is HDR CS8500. A 29U switch provides a maximum of 800 HDR 200Gb/s ports, and each 200 GB port can be split into 2X100G to support 1600 HDR100 100Gb/s ports.
The other type is the QM8000 series. The 1U panel has 40 200G QSFP56 ports, which can be split into 80 HDR 100G ports at most for connecting 100G HDR network cards. At the same time, each port also supports EDR and directly connects with the network card of EDR. It should be noted that the 200G HDR port can only be slowed down to 100G and connected to the EDR network adapter, and cannot be split into 2X100G to connect two EDR network adapters.

There are two options for the 200G HDR switch: QM8700 and QM8790. The only difference between the two models is the management mode. The QM8700 provides the control interface for out-of-band management, while the QM8790 requires the NVIDIA Unified Fabric Manager (UFM®) platform for management.

For QM8700 and QM8790, there are two airflow options for each model of the switch. One of them is 8790-HS2F for P2C airflow (front and rear airflow). The fan module is marked in blue. If you do not recognize the markings, you can also identify them by floating your hand over the air inlet and outlet of the switch.
8790-HS2R is the red mark on the C2P airflow (rear front duct) fan module. Here P2C and C2P P means Power power, C means Cable (line interface), P2C (Power to Cable), C2P (Cable to Power) here the reference system is Power power side for the front, Cable line interface side for the rear.
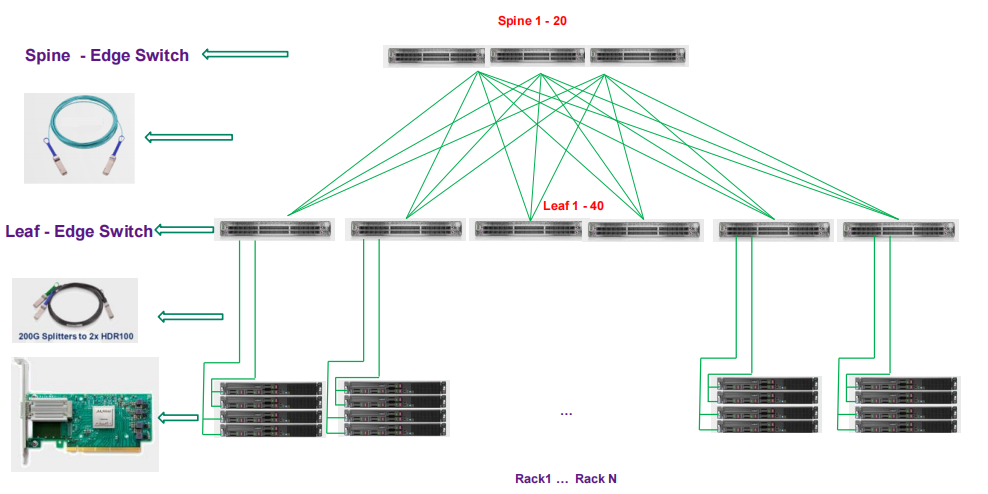
The QM8700 and QM8790 are generally used in two ways in practice, one is to interconnect with 200G HDR NICs by directly using 200G to 200G AOC/DAC; the other common use is to interconnect with 100G HDR NICs by using 200G to 2X100G cables, in which one physical 200G (4X50G) QSFP56 port of the switch is split into 2 virtual 100G (2X50G) ports. 4X50G) QSFP56 port of the switch is split into two virtual 100G (2X50G) ports, and after the split, the symbol of the port is changed from x/y to x/Y/z, where “x/Y” indicates the previous symbol of the port before the split, and “z” denotes the number of the resulting single-lane port (1,2), and then each sub-physical port is treated as a single port.
HDR Network Adapter
HDR network adapters are much more diverse than switches. The HDR100 network adapter supports a transmission rate of 100G. The two HDR100 ports can be connected to the HDR switch through 200G to 2x100G cables. Unlike the 100G EDR network card, the 100G port of the HDR100 network card supports both 4X25G NRZ and 2X50G PAM4 transmission. The HDR NIC supports a 200G transmission rate and can be connected to the switch through a 200G direct cable. In addition to the two interface rates, you can select single-port, dual-port, and PCIe network adapters of each rate based on service requirements. The common InfiniBand HDR network adapter models provided by FiberMall are as follows:
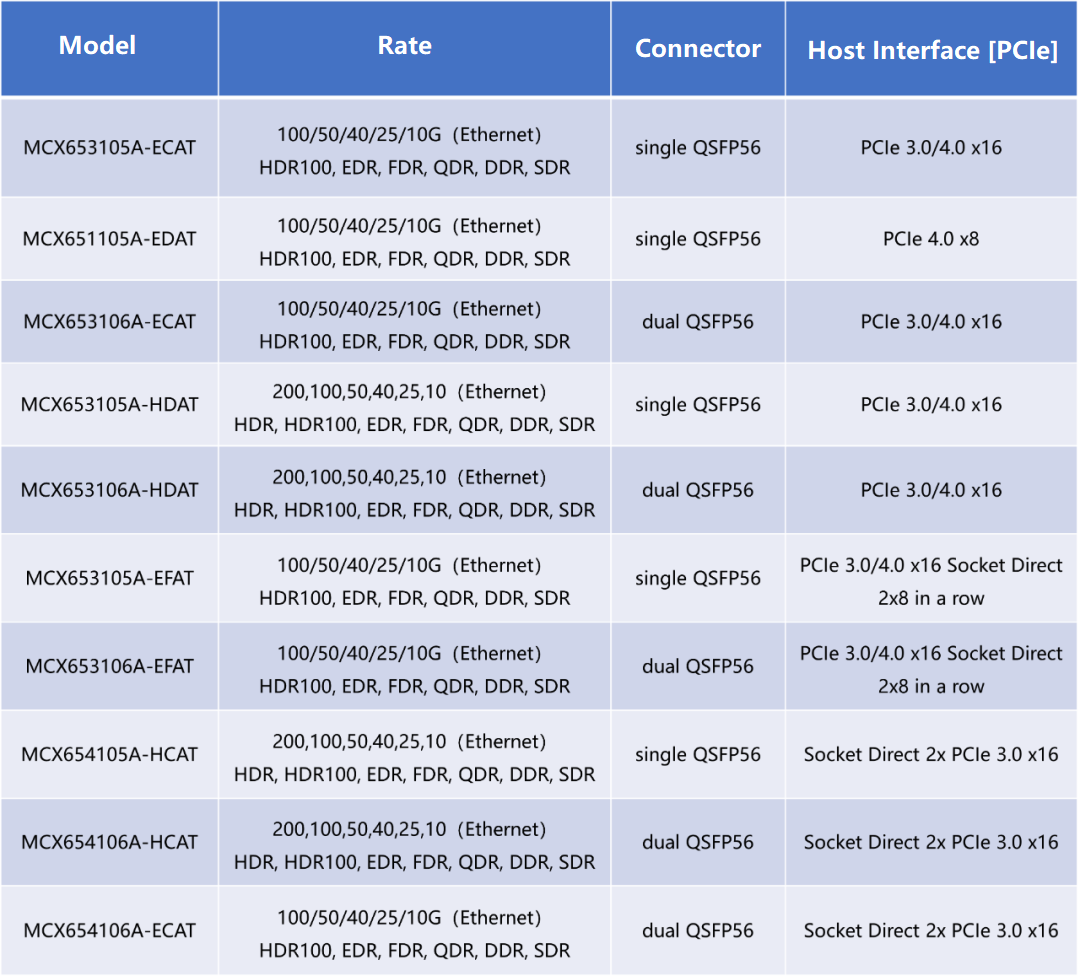
The InfiniBand network architecture is simple, but the solution selection is varied. 100G rate has both 100G EDR solution and 100G HDR solution; 200 rate also has HDR and 200G NDR two options. The network adapters, connectors, and switches used in different solutions are quite different.
InfiniBand Packets and Data Transfer
A packet is the basic unit of InfiniBand data transmission. In order for information to propagate efficiently in an InfiniBand network, the information is split by the channel adapter into a number of packets. A complete IBA packet consists of Local Route Header, Global Route Header, Base Transport Header, Extended Transport Header, Payload (PYLD), Invariant CRC (ICRC) and Variant CRC (VCRC) fields, as shown in the figure below.
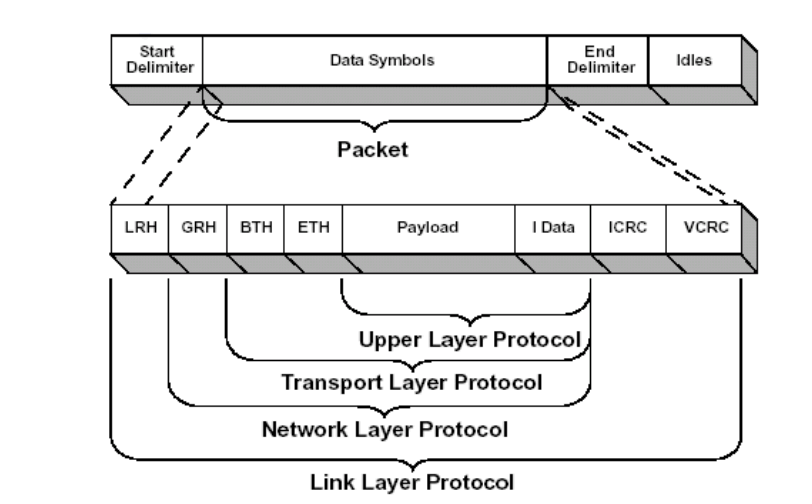
LRH: 8 bytes, used by the switch to determine the local source and destination ports when forwarding packets and to regulate the class of service and virtual lane (VL) for packet transmission.
GRH: 40 bytes, used to route packets between subnets and ensure proper transmission of packets between subnets. It is specified by the Link Next Header (LNH) field in the LRH, using the IPv6 header specification defined in RFC 2460.
BTH: 12 bytes, specifying the destination Queue Pair (QP), indication opcode, packet serial number and segmentation.
ETH: 4-28 bytes, providing reliable datagram service. Payload (PYLD): 0-4096 bytes, the end-to-end application data being sent.
ICRC: 4 bytes, encapsulates the data that remains unchanged in the packet as it is sent from the source address to the destination address.
VCRC: 2 bytes, encapsulates the variable IBA and raw (raw) packets during the link.
VCRC can be reconfigured in the fabric.
InfiniBand Layered Architecture
According to the definition of IBTA, the InfiniBand architecture consists of physical layer, link layer, network layer and transport layer, and its layered architecture is shown in the figure.
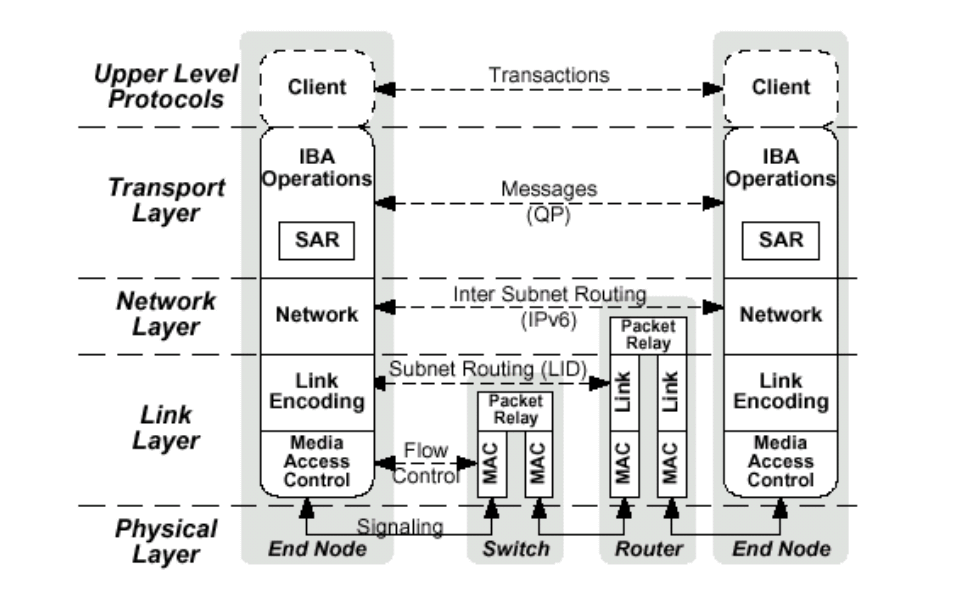
Physical layer: The physical layer serves the link layer and provides the logical interface between these two layers. The physical layer consists of modules such as port signal connectors, physical connections (electrical and optical), hardware management, power management, and coding lines, whose main roles are to:
(1) Establishing physical connections;
(2) Notifying the link layer whether a physical connection is valid;
(3) Monitoring the status of the physical connection, passing control signals and data to the link layer when the physical connection is valid, and transmitting the control and data information coming from the link layer.
Link layer: The link layer is responsible for handling the sending and receiving of link data in packets, providing services such as addressing, buffering, flow control, error detection and data exchange. Quality of service (QoS) is mainly reflected by this layer. The state machine is used to define the logical operations of the link layer as externally accessible operations, and does not specify internal operations.
Network layer: The network layer is responsible for routing packets between IBA subnets, including unicast and multicast operations. The network layer does not specify multiprotocol routing (e.g., IBA routing over non-IBA types), nor does it specify how the original packets are routed between IBA subnets.
Transport layer: Each IBA data contains a transport header. The transport header contains the information required by the end node to perform the specified operation. By manipulating QP, the IBA channel adapter communication clients at the transport layer form a “send” work queue and a “receive” work queue.
The Switching Mechanism of InfiniBand
The Switched Fabric used in InfiniBand is a switch-based point-to-point interconnection architecture geared toward system fault tolerance and scalability.
IBA switches are the basic routing building blocks for internal subnet routing (inter-subnet routing functionality is provided by IBA routers). The interconnection of switches is accomplished by relaying packets between links.
InfiniBand switches implement functions such as Subnet Manager Agent (SMA), Performance Manager Agent (PMA) and Baseboard Manager Agent (BMA). SMA provides an interface for subnet managers to obtain record and table data inside the switch via subnet management packets, implementing functions such as message notification, Service Level (SL) to Virtual Lane (VL) mapping, VL arbitration, multicast forwarding, and vendor characteristics. PMA provides an interface for performance managers to monitor performance information such as data throughput and error accumulation of the switch.BMA provides a communication channel between the baseboard manager and the bottom shelf manager.
The main functions of data forwarding in InfiniBand switches are:
(1) Selecting the output port: Based on the Destination Local Identifier (DLID) of the packet, the switch finds out the port number of the output port from the forwarding table.
(2) Select output VL: SL and VL are supported, and the switch determines the VL of the output port used by packets of different priority levels based on the SL-VL mapping table.
(3) Data flow control: A credit-based link-level flow control mechanism is used.
(4) Support unicast, multicast and broadcast: The switch can convert multicast packets or broadcast packets into multiple unicast packets for exchange.
(5) Partitioning: Only hosts in the same partition can communicate with each other. Each partition has a unique partition key, and the switch checks whether the DLID of the packet is within the partition corresponding to the key.
(6) Error checking: including inconsistency error checking, encoding error checking, framing error checking, packet length checking, packet header version checking, service level validity checking, flow control compliance and maximum transmission unit checking.
(7) VL arbitration: Support subnet VL (including management VL15 and data VL). The switch uses VL arbitration to ensure that high-priority packets are better served.
At present, the main manufacturers of InfiniBand switches are Mallanox, QLogic, Cisco, IBM, etc.
For hosts, the client side of the transport layer is a Verbs software layer, where the client passes buffers or commands to and from these queues, and the hardware passes buffer data to and from them. When QP is established, it incorporates one of four IBA transport service types (reliable connection, reliable self-addressing information, unreliable self-addressing information, unreliable connection) or a non-IBA protocol encapsulated service. The transport service describes how the reliability and QP transport data works and what is transmitted.
As an NVIDIA Elite level partner, FiberMall can provide complete InfiniBand solutions according to different customers’ needs, and our senior technical engineers have rich experience in InfiniBand high-performance network solution design and project implementation services and can provide optimal solutions according to different application scenarios. We can provide QM8700/QM8790 switch, HDR NIC, AOC/DAC/optical module portfolio solutions to achieve super performance and scalability, and improve ROI for HPC, AI, and other applications with lower cost and excellent performance.
Cost and Operational Considerations
InfiniBand vs. Ethernet Cost
InfiniBand’s initial investment is higher due to specialized hardware (e.g., HCAs, InfiniBand switches) and licensing costs. Ethernet benefits from widespread adoption, with lower-cost switches and NICs. However, for large-scale AI deployments, InfiniBand’s performance gains can offset upfront costs by reducing training times. Long-term costs depend on scale, with Ethernet often being more economical for smaller setups.
Maintenance and Operating Expenses
InfiniBand requires specialized expertise for configuration and maintenance, increasing operational costs. Ethernet’s familiarity among IT staff reduces training needs, but complex Ethernet setups (e.g., for RDMA over Ethernet) may still demand expertise. Both require regular maintenance, such as cable inspections and firmware updates, but InfiniBand’s proprietary nature can complicate troubleshooting.
Power Consumption and Efficiency Gains
InfiniBand’s optimized design often results in lower power consumption per unit of data transferred, especially in high-throughput scenarios. Ethernet’s power usage varies by equipment, but high-end switches can consume more energy under heavy loads. For data centers prioritizing sustainability, InfiniBand’s efficiency is a compelling factor.
Choosing the Right Technology
Best Ways to Optimize Infrastructure for AI Workloads
To optimize AI infrastructure, align the interconnect with workload demands. InfiniBand suits GPU-intensive tasks like deep learning, where low latency is critical. Ethernet is ideal for mixed workloads or environments requiring integration with existing networks. Key strategies include using RDMA (for both technologies), optimizing topology, and ensuring high-quality cabling.
AI Infrastructure: Cloud vs. Edge vs. On-Premises
In cloud environments, Ethernet dominates due to its standardization and compatibility with hyperscale providers. On-premises AI clusters often leverage InfiniBand for performance-critical tasks. Edge environments favor Ethernet for its flexibility and lower cost, though InfiniBand is emerging in edge HPC. Hybrid setups may combine both, using Ethernet for external connectivity and InfiniBand for internal clusters.
Choosing the Right Technology for Your AI Networking Needs
Selecting between InfiniBand and Ethernet depends on:
- Performance Needs: InfiniBand for low-latency, high-throughput AI tasks; Ethernet for general-purpose networking.
- Budget: Ethernet for cost-sensitive deployments; InfiniBand for performance-driven projects.
- Scale: InfiniBand for large AI clusters; Ethernet for smaller or mixed environments.
- Expertise: Ethernet if staff are familiar with TCP/IP; InfiniBand if specialized skills are available.
Frequently Asked Questions
Is Ethernet Better Than InfiniBand?
Ethernet is better for general-purpose, cost-sensitive, or broadly compatible networks. InfiniBand excels in AI, HPC, and latency-critical applications due to its performance advantages.
Is InfiniBand Copper or Fiber?
InfiniBand supports both copper (for short distances, e.g., 5-10 meters) and fiber (for longer distances, up to kilometers), depending on the deployment.
Is InfiniBand Owned by NVIDIA?
InfiniBand is an open standard managed by the IBTA. NVIDIA develops InfiniBand hardware (e.g., ConnectX adapters) but does not own the technology.
How Fast Is InfiniBand?
Modern InfiniBand (e.g., NDR) reaches 400 Gbps per port, with sub-microsecond latency, making it one of the fastest interconnects available.
Why Is InfiniBand So Fast?
InfiniBand’s speed stems from its switched fabric architecture, RDMA support, and optimized protocols, minimizing overhead and maximizing throughput.
Who Uses InfiniBand?
InfiniBand is used by HPC centers, AI research labs (e.g., Meta AI, Google DeepMind), cloud providers, and scientific institutions for high-performance tasks.
How Do I Optimize My Network for AI Workloads?
Use InfiniBand for GPU clusters, optimize topology (e.g., fat-tree), ensure high-quality cabling, and leverage RDMA for low-latency data transfers.
Related Products:
-
 NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$700.00
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$700.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA MMA1Z00-NS400 Compatible 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$550.00
-
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA(Mellanox) MMA1T00-VS Compatible 200G Ethernet QSFP56 SR4 PAM4 850nm 100m MTP/MPO APC OM3 FEC Optical Transceiver Module
$139.00
-
NVIDIA(Mellanox) MMS1W50-HM Compatible 200G InfiniBand HDR QSFP56 FR4 PAM4 CWDM4 2km LC SMF FEC Optical Transceiver Module
$650.00
-
NVIDIA MCP7Y00-N003-FLT Compatible 3m (10ft) 800G Twin-port OSFP to 2x400G Flat Top OSFP InfiniBand NDR Breakout DAC
$260.00
-
NVIDIA MCA7J60-N005 Compatible 5m (16ft) 800G Twin-port OSFP to 2x400G OSFP InfiniBand NDR Breakout Active Copper Cable
$850.00
-
NVIDIA MCA7J65-N005 Compatible 5m (16ft) 800G Twin-port OSFP to 2x400G QSFP112 InfiniBand NDR Breakout Active Copper Cable
$850.00
-
NVIDIA(Mellanox) MCP1650-H002E26 Compatible 2m (7ft) Infiniband HDR 200G QSFP56 to QSFP56 PAM4 Passive Direct Attach Copper Twinax Cable
$65.00
-
NVIDIA(Mellanox) MFS1S00-H005E Compatible 5m (16ft) 200G HDR QSFP56 to QSFP56 Active Optical Cable
$355.00
-
NVIDIA(Mellanox) MFS1S00-H015E Compatible 15m (49ft) 200G HDR QSFP56 to QSFP56 Active Optical Cable
$375.00