
In the era of large AI models, training AI models with a single GPU has long become history. How to interconnect hundreds or thousands of GPUs to form a supercomputing system that looks like one GPU has become a hot topic in the industry!
NVIDIA DGX SuperPOD is the next-generation data center artificial intelligence (AI) architecture. It is designed to deliver the levels of computing performance required for advanced computing challenges in AI model training, inference, high-performance computing (HPC), and hybrid applications to improve predictive performance and shorten time to solution. Let’s learn about the GPU interconnection architecture solution of NVIDIA’s three generations of products: H100→GH200→GB200.
Building a SuperPod with 256 GPUs based on H100
In the case of DGX A100, the eight GPUs on each node are interconnected via NVLink and NVSwitch, and different servers are directly interconnected using a 200Gbps IB HDR network (Note: the network between servers can use either an IB network or a RoCE network).
In the case of DGX H100, NVIDIA extends the NVLink within the server to between servers and adds an NVLink-network Switch. NVSwitch is responsible for switching within the server, while NVLink-network Switch is responsible for switching between servers. A SuperPod (i.e. a supercomputing system) consisting of 256 H100 GPUs can be built based on NVSwitch and NVLink-network Switch. The Reduce bandwidth of 256 GPU cards can still reach 450 GB/s, which is exactly the same as the Reduce bandwidth of 8 GPU cards in a single server.
However, the SuperPod of DGX H100 also has certain problems. There are only 72 NVLink connections across DGX H100 nodes, and the SuperPod system is not a non-convergent network. As shown in the figure below, in the DGX H100 system, four NVSwitches reserve 72 NVLink connections for connecting to other DGX H100 systems through the NVLink-network Switch. The total bidirectional bandwidth of the 72 NVLink connections is 3.6TB/s, while the total bidirectional bandwidth of 8 H100s is 7.2TB/s. Therefore, there is convergence at the NVSwitch in the SuperPod system.
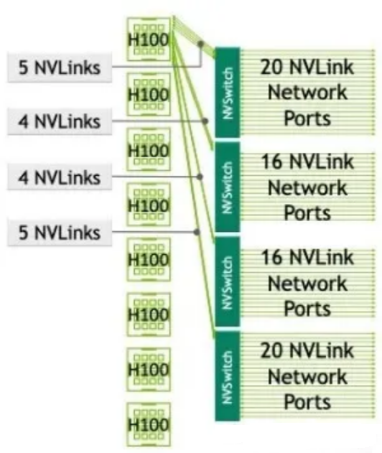
SuperPod with 256 GPUs based on H100
Building a 256 GPU SuperPod based on GH200 and GH200 NVL32
In 2023, NVIDIA announced that the generative AI engine DGX GH200 has entered mass production. GH200 is a combination of H200 GPU (the main difference between H200 and H100 lies in memory size and bandwidth performance) and Grace CPU. One Grace CPU corresponds to one H200 GPU. In addition to the NVLink4.0 connection between GPUs, GH200 also uses NVLink4.0 connection between GPUs and CPUs.
GH200 improves computing power through the 900GB/s ultra-large network bandwidth capability of NVLink 4.0. Copper wire solutions may be used inside the server, but optical fiber connections may be used between servers. For a single cluster of 256 GH200 chips, one GH200 on the computing side corresponds to nine 800Gbps (each 800Gbps corresponds to 100GB/s, two NVLink 4.0 links) optical transceiver. The difference between GH200 SuperPod and DGX H100 SuperPod is that GH200 uses NVLink-network Switch for interconnection within a single node and between nodes. DGX GH200 adopts a two-level Fat-tree structure, consisting of 8 GH200s and 3 first-level NVLink-network Switches (each NVSwitch Tray contains 2 NVSwitch chips and has 128 ports) to form a single server. 32 single servers are fully interconnected via 36 second-level NVLink-network Switches to form a SuperPod of 256 GH200s (note that there are 36 second-level NVLink-network Switches to ensure no convergence).
GH200 NVL32 is a rack-level cluster. A single GH200 NVL32 has 32 GH200 GPUs and 9 NVSwitch Trays (18 NVSwitch3.0 chips). If a GH200 NVL32 super node with 256 GPUs is formed, 36 NVLink-network switches between the first-level servers are required.
Building a SuperPod with 576 GPU based on GB200 NVL72
Unlike GH200, a GB200 consists of 1 Grace CPU and 2 Blackwell GPUs (Note: the computing power of a single GPU is not completely equivalent to B200). The GB200 Compute Tray is designed based on NVIDIA MGX. One Compute Tray contains 2 GB200s, that is, 2 Grace CPUs and 4 GPUs. A GB200 NVL72 node contains 18 GB200 Compute Trays, i.e. 36 Grace CPUs, 72 GPUs, and 9 NVLink-network Switch Trays (each Blackwell GPU has 18 NVLinks, and each 4th generation NVLink-network Switch Tray contains 144 NVLink Ports, so 9 (72*18/144=9) NVLink-network Switch Trays are required to achieve full interconnection).
According to NVIDIA’s official promotion, eight GB200 NVL72s form a SuperPod, thus forming a supernode consisting of 576 GPUs. However, through analysis, we can see that the 9 NVLink-network Switch Trays in the GB200 NVL72 cabinet are all used to connect 72 GB200s. There are no additional NVLink interfaces for expansion to form a larger-scale two-layer switching cluster. From the official pictures of NVIDIA, the SuperPod of 576 GPUs is mostly interconnected through the Scale-Out RDMA network rather than the Scale-Up NVLink network. If we need to support a SuperPod with 576 GPUs through NVLink interconnection, we need to configure 18 NVSwitches for every 72 GB200s, which will not fit in a single cabinet.
In addition, NVIDIA officially stated that NVL72 has a single-cabinet version and a dual-cabinet version, and each Compute Tray of the dual-cabinet has only one GB200 subsystem. In this case, it is possible to use the dual-cabinet version to support a SuperPod of 576 GPUs through NVLink interconnection and each dual-cabinet of this dual-cabinet version has 72 GB200s and 18 NVLink-network Switch Trays, which can meet the deployment needs of a two-layer cluster. As shown in the following figure:
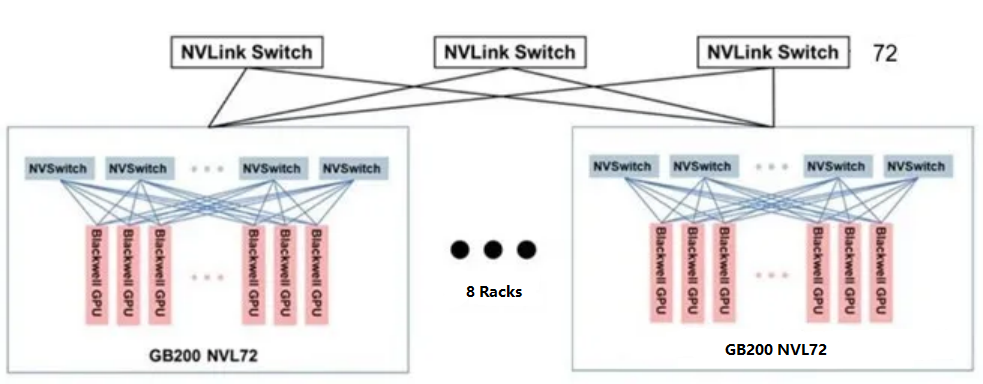
SuperPod with 576 GPUs based on GB200
It is similar to the previous generation of 256 H200 fully interconnected structures, except that the number of devices in the first and second levels is different, requiring two levels of NVLink-network Switch interconnection: half of the ports in the first level connect 576 Blackwell GPUs, so 576*18/(144/2) =144 NVLink-network Switches are required, and each NVL72 has 18 NVLink-network Switch Trays. All second-level ports are connected to the first-level NVLink-network Switch Ports, so 144*72/144=72 NVSwitches are required.