
The arithmetic network is to solve the problem of supplying arithmetic power, and several key technologies of arithmetic power, including Remote Direct Data Access (RDMA), are closely related to network performance indicators.
RDMA is the abbreviation of Remote Direct Memory Access, which is created to solve the delay of data processing on the server side in network transmission.
RDMA transfers data directly into a computer’s storage area over the network, moving data quickly from one system to remote system memory without any impact on the operating system, so that there is no need to use many computing processing functions. It eliminates the overhead of external memory replication and context switching, thus freeing up memory bandwidth and CPU cycles for improved application system performance.
DMA in the Traditional Sense
Direct Memory Access (DMA) is a mode of operation in which I/O exchange is performed entirely by hardware. In this mode, the DMA controller takes over complete control of the bus from the CPU, and data exchange takes place directly between memory and IO devices without going through the CPU. The DMA controller sends address and control signals to the memory, modifies the address, counts the number of transferred words, and reports the end of the transfer operation to the CPU in an interrupt.
The purpose of using the DMA method is to reduce the CPU overhead during large data transfers by using a dedicated DMA controller (DMAC) to generate access addresses and control the access process. The advantages are that the operations are implemented by hardware circuitry, the transfer speed is fast, the CPU does not interfere, but only participates during initialization and termination, and the CPU works in parallel with the peripheral devices for high efficiency.
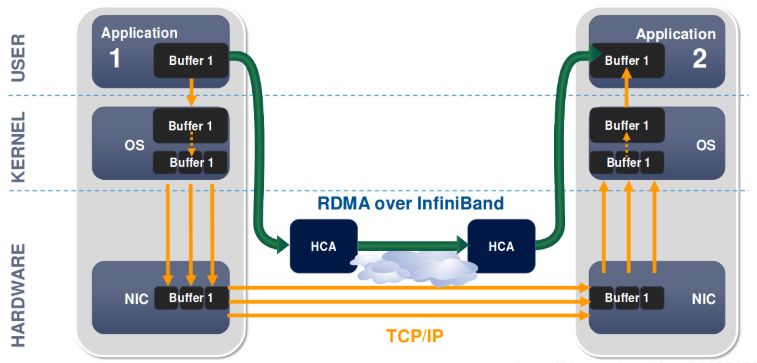
Working Principle of RDMA
Ordinary NICs integrate hardware check support and software improvements to reduce the number of copies of sent data, but not the number of copies of received data, which takes up a large number of CPU computation cycles.
The working process of a normal NIC
- The data sender needs to copy the data from the user space Buffer to the socket Buffer in the kernel space.
- The data sender has to add packet headers in kernel space for data encapsulation.
- The data is copied from the socket buffer in kernel space to the NIC buffer for network transmission.
- The data receiver receives the packet sent from the remote machine and copies the packet from the NIC Buffer to the Socket Buffer in kernel space.
- After a series of multi-layer network protocols to parse the packets, the parsed data is copied from the kernel space Socket Buffer to the user space Buffer.
- At this point, the system context switch is performed and the user application is invoked.
The received packets are first cached on the system, where they are processed and the corresponding data is assigned to a TCP connection. The receiving system then associates the unsolicited TCP data with the corresponding application and copies the data from the system buffer to the destination storage address. Thus, network speed constraints emerge: the increasing intensity of application communication and the heavy task of the host CPU in processing data between the kernel and application memory require the system to continuously add host CPU resources, configure efficient software, and enhance system load management.
The key to the problem is to eliminate unnecessary and frequent data transfers in the host CPU and to reduce inter-system message latency.
RDMA is the direct transfer of information into the computer’s storage over the network, moving data quickly from one system to remote system memory without any impact on the operating system so that not much of the computer’s processing power is used. It eliminates external memory copying and text-swapping operations, thus freeing up bus space and CPU cycles for improved application performance. The common practice requires the system to analyze and tag incoming information before storing it in the correct area.
The working process of RDMA
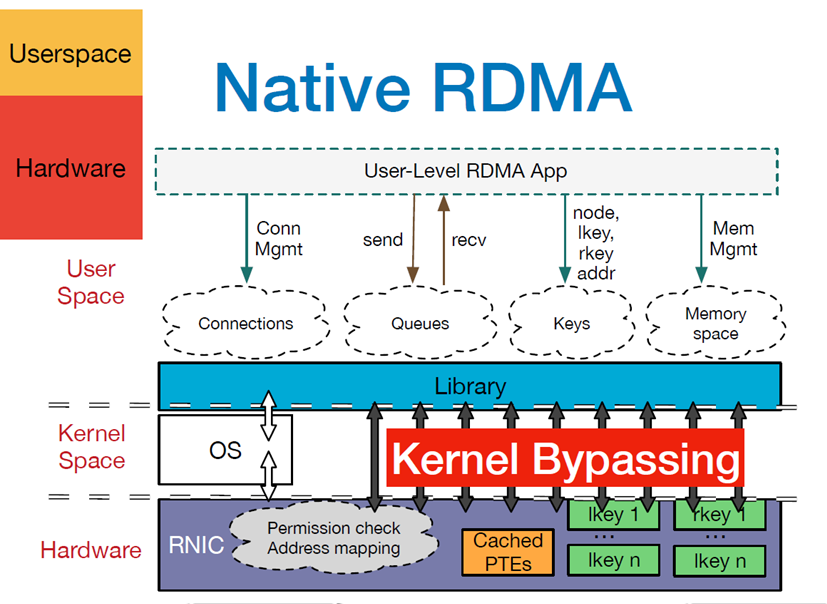
- When an application performs an RDMA read or write request, it does not perform any data replication. Without any kernel memory involvement, the RDMA request is sent from the application running in user space to the local NIC ( NIC=Network Interface Card).
- The NIC reads the contents of the buffer and transmits them over the network to the remote NIC.
- The RDMA information transmitted over the network contains the target virtual address, the memory key and the data itself. Request completion can either be handled entirely in user space (by polling the user-level completion alignment) or through kernel memory if the application sleeps until the request completes. RDMA operations allow the application to read data from or write data to the memory of a remote application.
- The target NIC acknowledges the memory key and writes the data directly to the application cache. The remote virtual memory address used for the operation is contained in the RDMA information.
Zero-copy Technology in RDMA
Zero-copy networking technology enables the NIC to transfer data directly to and from application memory, thus eliminating the need to copy data between application memory and kernel memory. Kernel memory bypass allows applications to send commands to the NIC without executing kernel memory calls. Without any kernel memory involvement, RDMA requests are sent from user space to the local NIC and over the network to the remote NIC, which reduces the number of environment switches between kernel memory space and user space when processing network transfer streams.
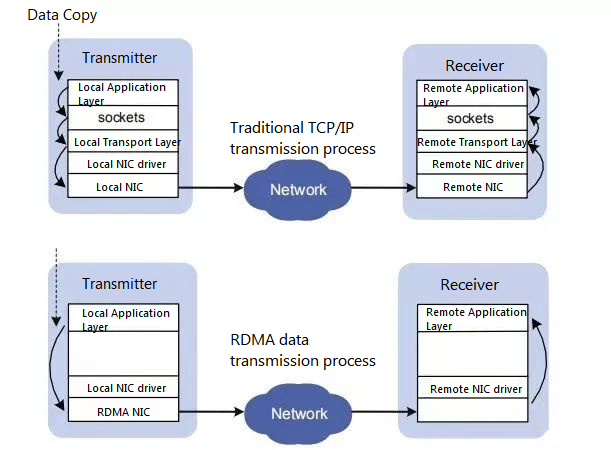
On the left side, we can see the traditional TCP/IP protocol and the communication process performed by a normal NIC. Obviously, when the application layer wants to get the data message from the NIC, it needs to go through two buffers and the normal TCP/IP protocol stack, where the soft interrupt is responsible for reading the data message from the first receive queue buffer, then copying it to MSGBuff, and finally the application layer reads the data message to the user state through a system call. On the other hand, the right side is a zero-copy process using RDMA with the following rules.
1) RDMA and its LLP (Lower Layer Protocol) can be implemented on the NIC called RNIC (RNIC is RDMA Network Interface Card).
2) The two implementations mentioned in 1) both go through the following steps: the data sent and received is cached into a marked memory space, and then this memory space is directly mapped to the application space according to the rules negotiated between the two parties of LLP and RDMA, thus reducing at least two memory copies in the traditional implementation method, i.e. achieving zero-copy. The thin line indicates the direction of data flow, in fact, the marker cache is mapped directly to the user cache space via RDMA.
Composition of RDMA
RDMA is implemented by three protocols, RDMA, DDP, and MPA, which constitute the iWARP protocol family and are used to ensure interoperability of high-speed networks. The DDP should encapsulate the RDMA messages into DDP packets and forward them to the lower Marker-based, Protocol-data-unit-Aligned (MPA) layer, which inserts the identifier, length and CRC checks into the DDP packets to form the MPA data segment. The IP layer adds the necessary network routing data to the packet.
Data Operation Methods
The RDMA protocol provides seven types of control operations for the remote direct data buffer. Each RDMA control operation, except for the remote buffer read operation, generates only one corresponding RDMA message.
- Send: The Send operation uses the Send message to send the data from the sender application directly to a buffer that has not been explicitly declared by the data receiver application. Therefore, the Send message uses the DDP untagged buffer data transfer model to transfer the upper application message to the meta-tagged queued buffer of the receiving application.
- Send with Invalidate: Add a Stag to Send. Once the message is cached in the peer application buffer specified by the Stag, and the message arrival notification is communicated to the receiver application, the receiver application does not allow the sender application to access the buffer until the receiver application re-declares the buffer available for the sender application to continue using.
- Send with Solicited Event (Send with SE): This message is used to send the sender application’s data directly to the untagged queued buffer of the data receiver application, with all the features of Send and added feedback to the message.
- Send with Solicited Event and Invalidate (Send with SE and Invalidate): The action corresponding to this message is to send the data of the sender application directly to the buffer not yet explicitly declared by the data receiver application, which has all the functions of Send with SE and adds feedback to the message. It has all the features of Send with SE and adds feedback to the message.
- Remote Direct Memory Access Write: Corresponds to the RDMA write operation and is used to pass the data from the sender application to the buffer declared by the receiver application. In this operation, the receiver application should have allocated a marked application receive buffer in advance and allow the sender application to perform the buffer write directly. At the same time, the sender application also gets the information about the location, size and corresponding Stag of the said buffer in the declaration. The sender application then initiates an RDMA write operation, which uses the DDP’s tagged buffer data transfer model to transfer the sender application’s message directly to the tagged buffer declared by the receiver application.
- Remote Direct Memory Access Read: Corresponds to the RDMA read operation, which passes the data from the marked application buffer on the opposite side (corresponding to the data source) to the marked application buffer on the local side (corresponding to the data receiver). The upper layer application of the data source first needs to allocate the tagged application buffer in advance and allow direct read operations on the contents of this buffer. At the same time, the upper layer application of the data source has to pass the information such as location, size and corresponding Stag of the data source buffer to be declared to the local upper layer application. After getting the above declaration, the upper application of the data receiver allocates the corresponding tagged application buffer and starts reading data from the other side.
- Terminate: The terminate operation uses a Terminate message to notify the local application of the error message that occurred to terminate the current data direct cache operation. The Terminate operation uses DDP’s meta-tagged buffer model to pass Terminate to the untagged buffer on the other side.
Applications of RDMA
RDMA has the advantage of using traditional network hardware to build the Internet using TCP/IP and Ethernet standards and will be used to connect small servers into a cluster that can handle the large databases that today’s high-end servers with more than a dozen processors can handle. When you put RDMA, TOE, and 10GB Ethernet together, it’s a pretty impressive technology.
TOE (TCP Offloading Engine, TCP/IP protocol processing from the CPU to the NIC)
During the host’s communication over the network, the CPU needs to spend a lot of resources on packet processing of multi-layer network protocols, including data replication, protocol processing, and interrupt processing. TOE technology frees the CPU from these operations and shifts the above-mentioned work of the host processor to the NIC. TOE technology requires a specific NIC that supports Offloading, which is capable of encapsulating packets of multi-layer network protocols. While ordinary NICs trigger an interrupt for each packet, TOE NICs allow each application to complete a full data processing process before triggering an interrupt, significantly reducing the server’s response burden to interrupts.
The TOE NIC performs protocol processing within the NIC as it receives data. Therefore, it does not have to copy the data to the kernel space buffer, but directly to the user space buffer. This “zero-copy” approach avoids unnecessary back-and-forth data copying between the NIC and the server.
RDMA is quickly becoming a fundamental feature of high-speed clusters and server area networks. InfiniBand networks and virtual interface architecture-based networks support RDMA, while RDMA over TCP/IP for use with transport offload engine network cards is currently under development. Protocols that support high performance using RDMA include Sockets Direct Protocol, SCSI RDMA Protocol (SRP), and Direct Access File System (DAFS). Communication libraries that use RDMA include Direct Access Provider Library (DAPL), Message Passing Interface (MPI), and Virtual Interface Provider Library (VIPL). Clusters running distributed applications are one of the areas where RDMA can excel, as it can provide higher performance and better scalability compared to other early RDMA applications with the same number of nodes when used with DAPL or VIPL and database software running on the cluster. Additionally, RDMA technology is rapidly becoming a fundamental feature of high-speed cluster systems and storage area networks, where iWARP/RDMA is a basic building block. iWARP (Internet Wide Area RDMA Protocol) is an RDMA technology based on the TCP/IP protocol, which implements RDMA technology on top of the existing TCP/IP protocol stack by adding a layer of DDP on top of TCP. It supports the use of RDMA technology on standard Ethernet infrastructure without requiring lossless Ethernet transmission supported by switches, but servers must use network cards that support iWARP. However, its performance is slightly worse due to the influence of TCP. Additionally, iSER, an iSCSI extension for RDMA, makes full use of RDMA capabilities. Early RDMA applications include remote file server access through DAFS and storage device access through SRP. RDMA is quickly becoming a fundamental feature of high-speed clusters and server area networks.
Applications in NAS and SAN
Traditional direct-attached storage (DAS) is a server-centric storage structure with limitations such as capacity constraints, limited connection distances, and difficulties in sharing and management. It cannot meet the application needs of the network era. The arrival of the network era has brought about tremendous changes in storage technology. Network-attached storage (NAS) and storage area networks (SAN) can provide rich, fast, and convenient storage resources for application systems on the network while also enabling shared storage resources and centralized management, becoming an ideal storage management and application model today. However, NAS structures have some difficult-to-solve problems, such as limited transfer capacity, limited scalability, limited backup capabilities, and ineffective support for database services. DAFS integrates the advantages of RDMA and NAS storage capabilities, with all read and write operations directly executed by the RDMA driver, thereby reducing the system load caused by network file protocols. In the future, NAS storage systems will adopt DAFS technology to improve system performance and compete strongly with SAN storage systems in terms of performance and price.
Infiniband
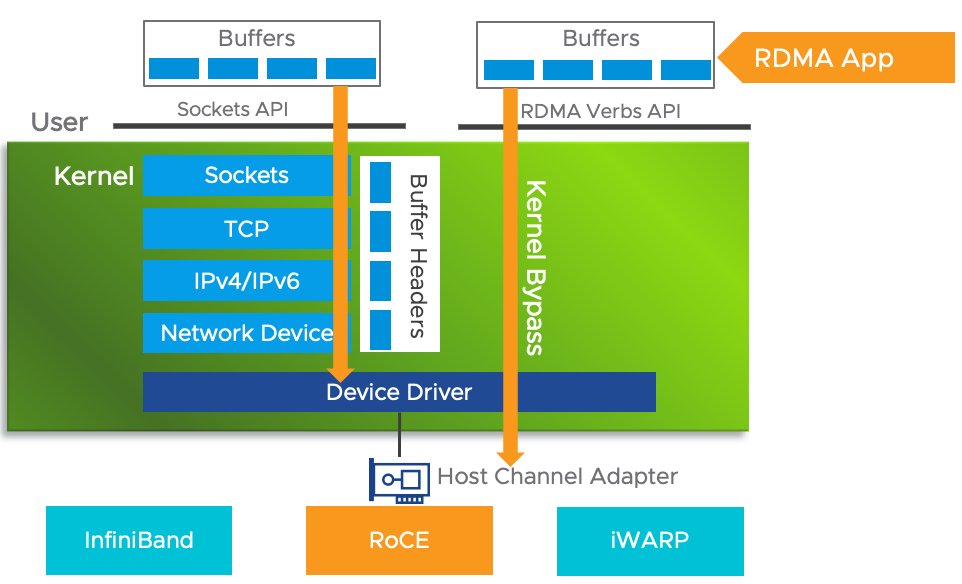
InfiniBand’s four major advantages are based on standard protocols, 10 GB/s performance, RDMA, and transport offload. Its advantage lies in the high-speed transmission of RDMA and transport offload engines. InfiniBand networks and virtual interface architecture-based networks support the use of RDMA, while RDMA over TCP/IP with transport offload engine NICs supports InfiniBand servers. Host channel adapters (HCA) convert protocols to the server’s internal PCI-X or PCI-Express bus, and HCAs with RDMA functionality is sometimes called kernel bypass. InfiniBand (IB) is an RDMA technology based on the InfiniBand architecture that requires dedicated IB network cards and IB switches. In terms of performance, InfiniBand networks are clearly the best, but network card and switch prices are also very high.
RoCE, or RDMA over Ethernet, is an RDMA technology based on Ethernet and was also proposed by the IBTA. RoCE supports the use of RDMA technology on standard Ethernet infrastructure but requires switch support for lossless Ethernet transmission, and network cards must be special NICs that support RoCE.
As technology continues to evolve, mainstream RDMA technologies can be divided into two camps: IB technology and IBoE, or IB over Ethernet, which supports Ethernet-based RDMA technologies. RoCE and iWARP belong to this technology. IBoE, or IB over Ethernet, can be propagated on Ethernet and used with Ethernet switches, while the IB protocol requires dedicated hardware and routers.
With the continuous development of computing power networks, DMA technology originally used for single-machine or local-area applications will be applied to larger-scale spaces and become a key technology in computing power networks.

Related Products:
-
 Intel® 82599EN SR1 Single Port 10 Gigabit SFP+ PCI Express x8 Ethernet Network Interface Card PCIe v2.0
$115.00
Intel® 82599EN SR1 Single Port 10 Gigabit SFP+ PCI Express x8 Ethernet Network Interface Card PCIe v2.0
$115.00
-
Intel® 82599ES SR2 Dual Port 10 Gigabit SFP+ PCI Express x8 Ethernet Network Interface Card PCIe v2.0
$159.00
-
Intel® X710-BM2 DA2 Dual Port 10 Gigabit SFP+ PCI Express x8 Ethernet Network Interface Card PCIe v3.0
$179.00
-
Intel® XL710-BM1 DA4 Quad Port 10 Gigabit SFP+ PCI Express x8 Ethernet Network Interface Card PCIe v3.0
$309.00
-
NVIDIA NVIDIA(Mellanox) MCX621102AN-ADAT SmartNIC ConnectX®-6 Dx Ethernet Network Interface Card, 1/10/25GbE Dual-Port SFP28, Gen 4.0 x8, Tall&Short Bracket
$315.00
-
NVIDIA(Mellanox) MCX631102AN-ADAT SmartNIC ConnectX®-6 Lx Ethernet Network Interface Card, 1/10/25GbE Dual-Port SFP28, Gen 4.0 x8, Tall&Short Bracket
$385.00
-
Intel® E810-XXVDA4 25G Ethernet Network Adapter PCI Express v4.0 x16 Quad-port SFP28
$495.00
-
Intel® E810-XXVDA2 25G Ethernet Network Adapter PCI Express v4.0 X8 Dual-port SFP28
$209.00
-
Intel® XL710-BM1 QDA1 Single Port 40 Gigabit QSFP+ PCI Express x8 Ethernet Network Interface Card PCIe v3.0
$309.00
-
Intel® XL710 QDA2 Dual Port 40 Gigabit QSFP+ PCI Express x8 Ethernet Network Interface Card PCIe v3.0
$359.00
-
NVIDIA NVIDIA(Mellanox) MCX653105A-ECAT-SP ConnectX-6 InfiniBand/VPI Adapter Card, HDR100/EDR/100G, Single-Port QSFP56, PCIe3.0/4.0 x16, Tall bracket
$965.00
-
NVIDIA NVIDIA(Mellanox) MCX653106A-ECAT-SP ConnectX-6 InfiniBand/VPI Adapter Card, HDR100/EDR/100G, Dual-Port QSFP56, PCIe3.0/4.0 x16, Tall Bracket
$828.00
-
Intel® E810-CQDA2 100G Ethernet Network Adapter PCIe v4.0 x16 Dual port QSFP28
$589.00
-
Intel® E810-CQDA1 100G Ethernet Network Adapter PCIe v4.0 x16 Single port QSFP28
$409.00
-
NVIDIA NVIDIA(Mellanox) MCX653105A-HDAT-SP ConnectX-6 InfiniBand/VPI Adapter Card, HDR/200GbE, Single-Port QSFP56, PCIe3.0/4.0 x16, Tall Bracket
$1400.00
-
NVIDIA NVIDIA(Mellanox) MCX653106A-HDAT-SP ConnectX-6 InfiniBand/VPI Adapter Card, HDR/200GbE, Dual-Port QSFP56, PCIe3.0/4.0 x16, Tall Bracket
$1600.00















