
The effective computational power of a cluster can be broken down into GPU utilization and the cluster’s linear speedup. GPU utilization is influenced by factors such as chip architecture, process technology, memory, I/O bottlenecks, inter-card interconnect bandwidth, topology, and power consumption. On the other hand, ‘cluster linear speedup’ depends on node communication capabilities, parallel training frameworks, and resource scheduling.
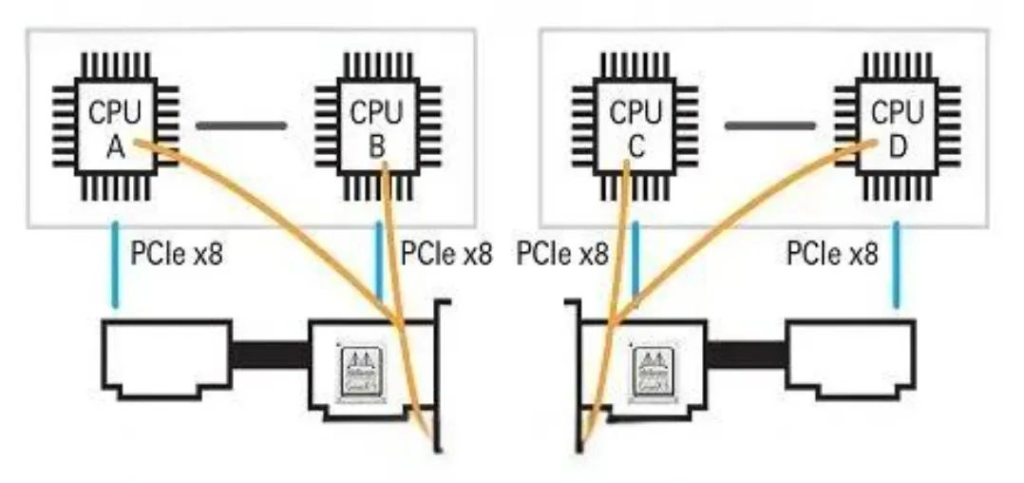
Designing an efficient cluster networking solution is crucial to achieve low latency, high bandwidth, and unblocked inter-node communication. This reduces communication overhead between multiple machines and GPUs, ultimately improving the effective GPU compute time (GPU compute time / overall training time). Based on the ‘White Paper on Network Evolution for AI Large Models’ by China Mobile Research Institute, AI large models pose new requirements for network infrastructure:
- Ultra-Large-Scale Networking: AI super-large models with parameter counts reaching billions to trillions demand extremely high computational power. Consequently, this necessitates a large amount of hardware and scalable network capacity. According to the ‘White Paper on Novel Intelligent Computing Technologies for Ultra-Thousand-Card Clusters,’ achieving optimal computational efficiency, data processing capabilities, hardware-level interconnection for thousands of cards, and network availability becomes a critical topic for AI computing centers.
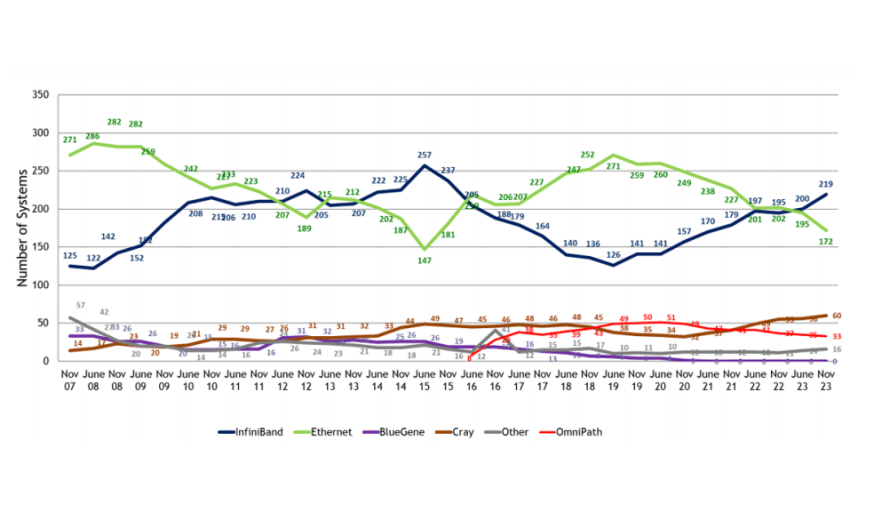
- Ultra-High Bandwidth Requirements: In multi-GPU clusters, both intra-server and inter-server communication are inevitable. Intra-server communication involves All Reduce collective communication data generated by model parallelism, reaching hundreds of gigabytes. Thus, the intra-GPU communication bandwidth and method significantly impact end-to-end flow completion time. Inter-server communication, in modes like pipeline parallelism, data parallelism, and tensor parallelism, also reaches similar data volumes. Complex collective communication patterns simultaneously involve many-to-one and one-to-many communication. Therefore, high-speed interconnects between GPUs are essential for single-port bandwidth, available inter-node links, and overall network bandwidth.
- Ultra-Low Latency: Data communication latency consists of static and dynamic components. Static latency depends on forwarding chip capabilities and transmission distance. When network topology and communication data volume are fixed, this part of the latency remains relatively constant. Dynamic latency includes switch internal queuing delay and packet loss retransmission delay, typically caused by network congestion, packet loss, and jitter.
- Ultra-High Stability and Automated Deployment: With a significant increase in the number of cards, network stability becomes the ‘weakest link’ in cluster networks. Network failures and performance fluctuations impact both inter-node connectivity and resource utilization.
RDMA (Remote Direct Memory Access) can reduce end-to-end communication latency between multiple machines and GPUs. In traditional networks, data transfer involves several steps: first, copying data from the source system’s kernel to the network stack, then transmitting it over the network. Finally, at the receiving end, multiple steps copy the data back to the target system’s kernel. RDMA bypasses the operating system kernel, allowing one host to directly access another host’s memory. Currently, the main RDMA technologies are InfiniBand and RoCEv2 (RDMA over Converged Ethernet).
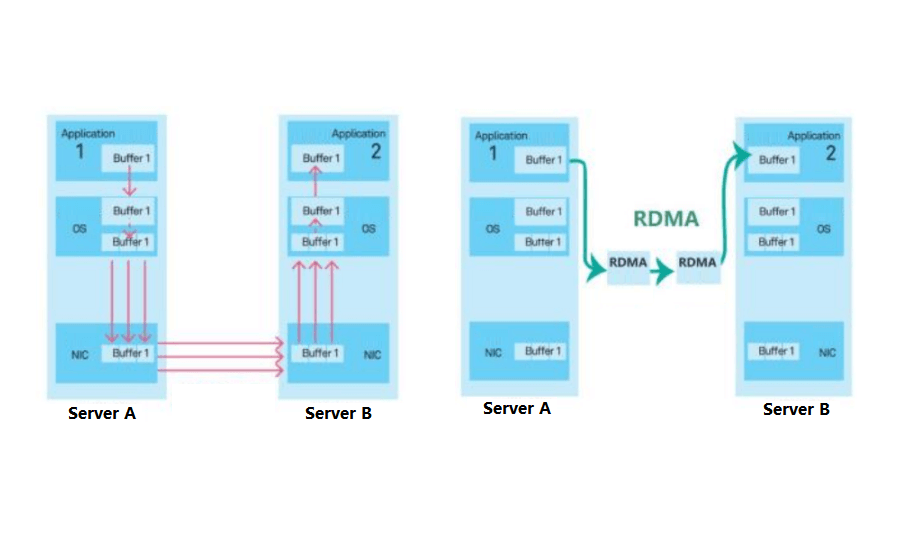
InfiniBand (IB) and RDMA over Converged Ethernet (RoCE) are two prominent network technologies. IB excels in low latency and high bandwidth, while Ethernet offers openness and cost-effectiveness. RoCE, being widely adopted and mature, serves as a cornerstone for interconnecting different systems with good compatibility. It also benefits from multiple vendors, resulting in cost advantages.
In contrast, IB is specialized for high-bandwidth, low-latency, and reliable network interconnects, commonly used in HPC clusters. However, due to limited vendor support, its deployment cost is higher than RoCE.
RoCE is a solid choice, while InfiniBand stands out as an exceptional solution. Notably, in supercomputing clusters, IB remains a popular and efficient interconnect. Nevertheless, considering cost and openness, many cloud computing companies opt for open-source Ethernet switches over proprietary IB solutions. According to Brian Barrett, a senior engineer at AWS, dedicated IB networks can be like isolated islands in the vast ocean of flexible resource allocation and sharing within cloud data centers.
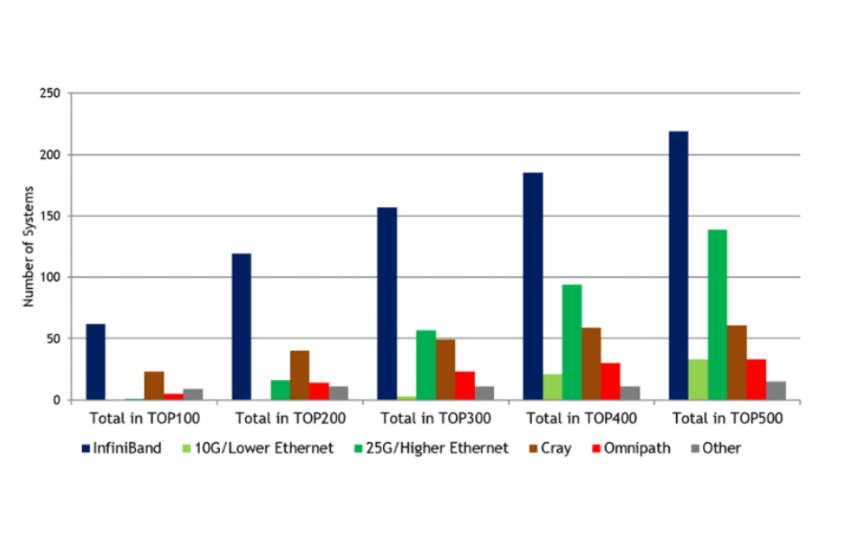
Additionally, the Ultra Ethernet Consortium (UEC) was established on July 19, 2023, under the Linux Foundation’s leadership. Comprising cloud providers (such as MATA and Microsoft), network equipment manufacturers (including Broadcom, Cisco, and HP), and semiconductor companies (AMD and Intel), UEC aims to provide an open, interoperable, high-performance communication stack based on Ethernet. This initiative supports the growing network demands of AI and HPC.
InfiniBand, with its early adoption of RDMA, offers native advantages such as low latency, high bandwidth, and reliability. In 2015, InfiniBand’s share in the TOP500 supercomputer list exceeded 50%, making it the preferred internal connection technology for supercomputers.
Currently, the primary supplier for InfiniBand (IB) architecture is Nvidia’s Mellanox. The InfiniBand Trade Association (IBTA) was initially established by leading companies such as Intel, Microsoft, SUN, IBM, Compaq, and HP. In May 1999, Mellanox was founded in Israel by former employees from Intel and Galileo Technology. In 2001, they launched their first IB product. However, in 2002, Intel and Microsoft, the original giants in the IB camp, withdrew.
In 2010, Mellanox merged with Voltaire, leaving Mellanox and QLogic as the main IB suppliers. In 2012, Intel re-entered the IB camp by acquiring QLogic’s IB networking business for $125 million. Shortly after, Intel also purchased the “Gemini” XT and “Aries” XC supercomputing interconnect business from Cray for $140 million. They later developed the new Omni-Path interconnect technology based on IB and Aries.
In 2013, Mellanox continued to expand by acquiring Kotura, a silicon photonics technology company, and IPtronics, a parallel optical interconnect chip manufacturer. By 2015, Mellanox held an 80% market share in the global InfiniBand market. In 2019, Nvidia successfully acquired Mellanox, outbidding competitors Intel and Microsoft with a $6.9 billion deal.
Now, let’s take a look at Nvidia’s latest generation GB200 product:
- Internal Configuration of a Rack:
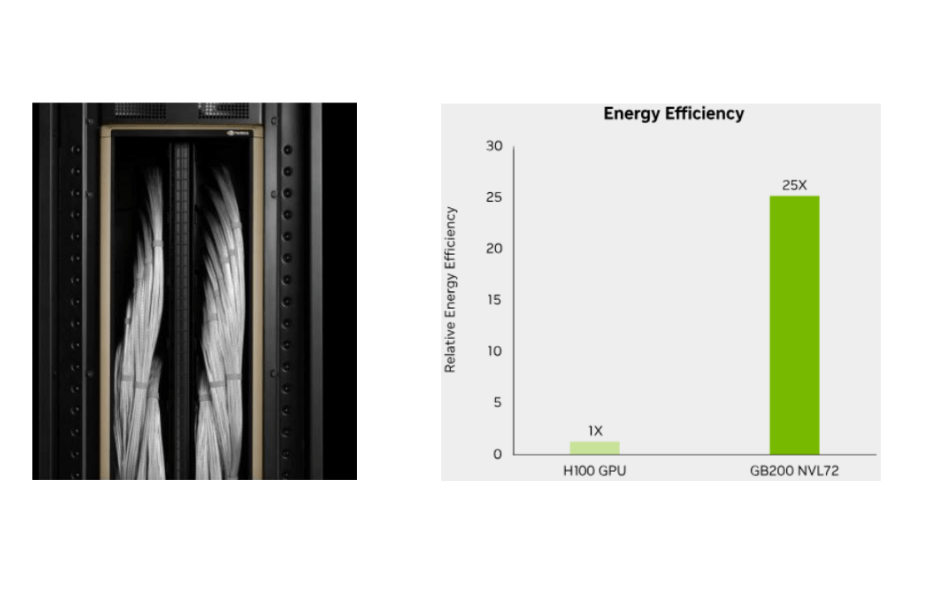
Each rack contains 18 Compute trays (10 on top, 8 on the bottom) and 9 Switch trays.
Copper Cable Cartridges connect Compute trays and Switch trays within the rack.
Utilizing a liquid-cooling system, the GB200 achieves 25 times the performance compared to the H100’s air-cooled infrastructure at the same power consumption.
Compute Tray Components:
Each individual Compute tray includes:
2 GB200 Grace Blackwell Superchips
4 ConnectX-800G InfiniBand Supernics
1 BlueField-3 Data Processing Unit (DPU).
GB200 Grace Blackwell Superchip:
The GB200 Grace Blackwell Superchip comprises two Blackwell GPUs and one Grace CPU.
Each individual Blackwell GPU is twice the size of the previous Hopper GPU architecture.
However, its AI performance (FP4) is five times that of Hopper.
Specifically, a single Blackwell GPU achieves approximately 20 petaFLOPS of AI performance (FP8).
It features 8x 24GB HBM3e memory with an impressive 8TB/s memory bandwidth.
The GB200 has 18 NVLink ports, connecting to 18 NVLink switch chips, achieving bidirectional communication at 1.8TB/s.
ConnectX-800G InfiniBand Supernic:
The ConnectX-800G InfiniBand Supernic enables end-to-end 800Gb/s network connections and performance isolation.
It is designed specifically for efficient management of multi-tenant AI clouds.
Leveraging PCIe 6.0, it provides 800Gb/s data throughput.
The ConnectX-8 Supernic supports both single-port OSFP 224 and dual-port QSFP112 connectors.
Additionally, it facilitates NVIDIA Socket Direct with 16-channel auxiliary card expansion.
Bluefield-3 DPU:
The Bluefield-3 DPU connects via 400Gb/s Ethernet or NDR 400Gb/s InfiniBand networks.
It offloads, accelerates, and isolates software-defined networking, storage, security, and management functions.
As a result, it significantly enhances data center performance, efficiency, and security.

Each Switch tray contains two NVLink switch chips.
Each individual switch chip supports four interfaces, with a single interface achieving a 1.8TB/s transfer rate.
A Switch tray provides a total of 144 NVLink ports (100GB), resulting in 14.4TB/s overall bandwidth.
With nine Switch trays, you can fully connect 72 Blackwell GPUs, each with 18 NVLink ports (totaling 1296 NVLink ports).

For internal cabinet connections:
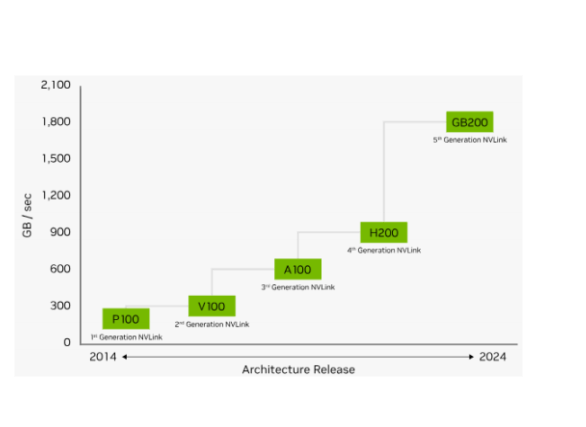
Compute trays and Switch trays are linked via fifth-generation NVLink.
The bidirectional bandwidth of fifth-generation NVLink is 1.8TB/s, twice that of the previous generation and over 14 times PCIe Gen5 bandwidth.
This 1.8TB/s GPU-to-GPU communication enables GPU expansion in AI and high-performance computing.
Within the Compute tray, Superchip internal GPUs and CPUs are connected via NVLink Chip-to-Chip communication (bidirectional bandwidth of 900GB/s).
Intra-Cabinet Connections (Within a Single Rack):
For configurations with up to 72 GPUs, the recommended solution within a single rack is to use copper cables (NVLink). The GB200’s improved chip density and efficient liquid cooling allow for more GPUs to be deployed in a smaller space, making copper cables a cost-effective choice for intra-cabinet connections. However, long-distance transmission losses remain a concern for future iterations.
When the number of GPUs exceeds 72, a single-layer network is insufficient. Upgrading to a higher-layer network structure is necessary. Two options are available: single NVLink and InfiniBand (IB) networking.
Single NVLink Configuration:
When connecting more than 72 but fewer than 576 GPUs, consider using an all-NVLink cluster architecture. The GPU-to-optical module ratio is 1:9.
For scalability beyond a single rack, a recommended approach is the dual-rack NVL72 configuration. Each rack contains 18 Compute Trays and 9 Switch Trays. Notably, in the dual-rack version, each Compute Tray features only one Grace Blackwell Superchip (2 Blackwell GPUs + 1 Grace CPU). The content of the Switch Tray remains consistent across both single and dual-rack versions.
With 36 Blackwell GPUs fully connected to 18 NVSwitch chips (totaling 648 ports), a 576-GPU cluster spans 16 dual-row cabinets. This results in a cumulative requirement of 10,368 ports, with a single-direction speed of 50GB/s (bidirectional 100GB/s). Assuming L1 to L2 network layers use 1.6T optical modules (200GB/s), we need 5,184 1.6T optical modules. The GPU-to-optical module ratio is 1:9.
InfiniBand (IB) Configuration:
When the desired GPU count exceeds 72, consider IB networking. Using the latest NVIDIA Quantum-X800 Q3400 switch, the number of ports determines the maximum GPU capacity for different network layers.
Compared to the NVIDIA Quantum-2 QM9700 with only 64 400G ports, the Quantum-X800 Q3400 offers 144 800G ports, allowing for a maximum of (144^2)/2 = 10,368 interconnected GPUs.
According to SemiAnalysis predictions, the GPU-to-1.6T optical module ratio is approximately 2.5 for a 2-layer network and around 3.5 for a 3-layer network.
Related Products:
-
 NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA(Mellanox) MMA1T00-HS Compatible 200G Infiniband HDR QSFP56 SR4 850nm 100m MPO-12 APC OM3/OM4 FEC PAM4 Optical Transceiver Module
$139.00
-
NVIDIA MCA7J60-N004 Compatible 4m (13ft) 800G Twin-port OSFP to 2x400G OSFP InfiniBand NDR Breakout Active Copper Cable
$800.00
-
NVIDIA MCP7Y60-H01A Compatible 1.5m (5ft) 400G OSFP to 2x200G QSFP56 Passive Direct Attach Cable
$116.00
-
NVIDIA(Mellanox) MCP1600-E00AE30 Compatible 0.5m InfiniBand EDR 100G QSFP28 to QSFP28 Copper Direct Attach Cable
$25.00
-
NVIDIA NVIDIA(Mellanox) MCX653106A-ECAT-SP ConnectX-6 InfiniBand/VPI Adapter Card, HDR100/EDR/100G, Dual-Port QSFP56, PCIe3.0/4.0 x16, Tall Bracket
$828.00
-
NVIDIA NVIDIA(Mellanox) MCX653105A-ECAT-SP ConnectX-6 InfiniBand/VPI Adapter Card, HDR100/EDR/100G, Single-Port QSFP56, PCIe3.0/4.0 x16, Tall bracket
$965.00











