
On May 23, the fourth session of the 2024 China High-Quality Development Forum, jointly organized by CIOE (China International Optoelectronic Expo) and C114 Communications Network, was successfully held on the theme of “AI Era: New Trends in Data Center Optical Interconnection Technology”. JD Optical Interconnection Architect Chen Cheng shared a keynote speech on “Optical Interconnection in High-Performance Computing Networks” at the meeting.
JD started early in the field of high-performance computing networks and has continued to invest heavily in multiple generations of intelligent computing topologies. Application scenarios involve recommendation algorithms, intelligent customer service, AI sales and leasing, digital human live streaming, and more.
The intelligent computing network topology is generally divided into two independent networks: the access/storage network, which mainly realizes the interconnection between CPUs; The second is the computing network, which mainly performs parallel coordination of GPU node data. Overall, the requirements of intelligent computing networks for optical interconnection are mainly concentrated in three aspects, namely large bandwidth, low cost and low latency.
The Relationship between Optical Transceivers and Large Bandwidth
In terms of data link bandwidth, the first thing to achieve is parallel multi-channel communication between GPUs. Attention should be paid to the link bandwidth during data transmission. In the internal interconnection of computing nodes, the C2C Full mesh method can generally be used, and the connection rate can reach hundreds of GB/s.
If you want to achieve communication between different GPU exports, you need to connect the optical transceiver to the network card through PCle, and then achieve cross-port connection through optical transceiver and computing networks after serial-to-parallel conversion. Therefore, many manufacturers are currently advocating the form of optical input/output (OIO) to break through the bottleneck of high-speed interconnection, which is also a development trend currently.
In terms of the evolution of network equipment/ optical transceiver bandwidth, the current intelligent computing network mainly deploys 50G Serdes switches and optical transceivers, and the main optical transceiver type is 200G/400G. When the capacity of a single node reaches 51.2T, different topology types will be selected based on the requirements for network scalability. Some North American manufacturers will choose 64x800G OSFP, while domestic manufacturers will use 128x400G QSFP 112 packaging, with universal industrial chains of the two.
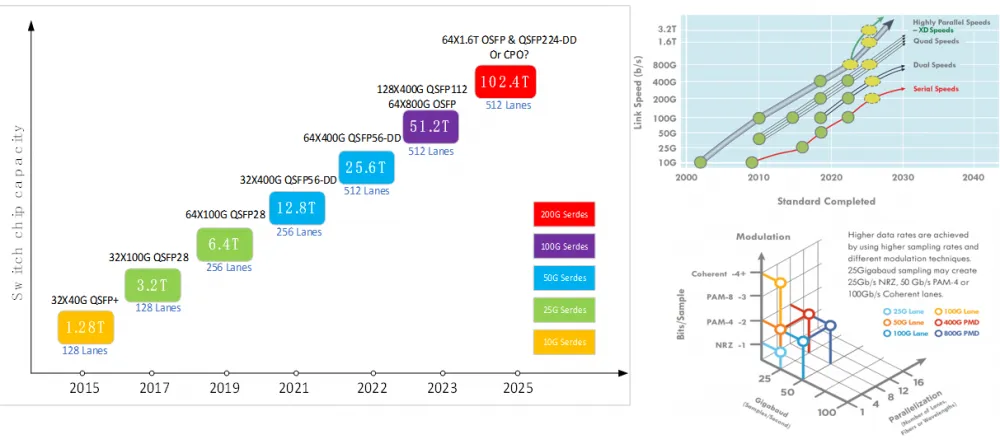
Network equipment/ optical transceiver bandwidth evolution
If the single-chip switching capacity reaches 102.4T in the future, pluggable optical transceiver can still support high-density and high-capacity optical interconnection applications, and 64×1.6T OSFP and QSFP224-DD can be selected. CPO is also one of the popular solutions. It continues to solve reliability issues and also solves maintainability issues during construction and deployment.
How to Reduce the Cost of Optical Interconnection?
In the issue of reducing the cost of optical interconnection, silicon-based photonics technology is one of the potential cost-reduction solutions. Silicon photonics is not a brand new technology, but it is a relatively new product in terms of data center applications. The current upstream supply chain of 112G per lane modules is concentrated in a small number of optical device manufacturers, so silicon photonics modules can be involved to solve the supply shortage problem.
In particular, silicon optical transceivers can cover the needs of all data center application scenarios within 2km, so JD is also carrying out corresponding certification and other work. It is believed that they can be truly deployed in the current network in the near future.
Linear direct-drive optical transceivers LPO/LRO are also popular application trend currently. In the 112G per lane era, with the help of the strong driving capability of ASIC, optical transceivers can be simplified, that is, the DSP or CDR part can be removed, thereby reducing the complexity of optical transceiver to achieve the purpose of reducing costs.
However, it also faces some challenges, such as compatibility and interoperability issues. It is necessary to consider the support of ASIC chips, the interconnection between different manufacturers, the interconnection between new and old modules, and so on.
The issue of evolutionary sustainability also needs to be considered. For example, 112G can already support LPO, but if it develops to 224G, the feasibility of LPO support must be considered.
Low Latency Problem of Intelligent Computing Network
In terms of low latency, if we want to achieve overall coordinated computing guarantees, the GPU latency problem between different computing nodes will inevitably greatly reduce the operating efficiency. So what factors usually cause latency?
First, the GPU network was initially based on the InfiniBand (IB) protocol, which bypassed the CPU in data transmission, enabling data communication between GPU caches between different computing nodes, greatly reducing protocol-based communication delays.
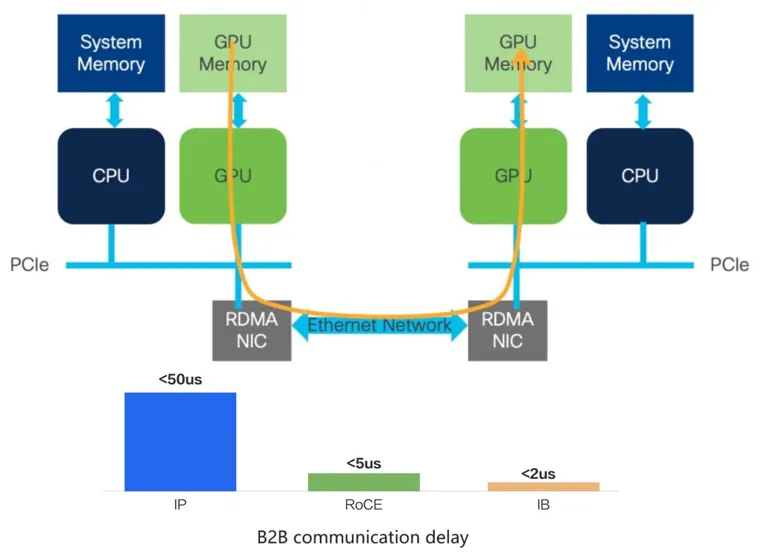
B2B Communication Delay
The traditional Ethernet-based protocol requires the CPU to be involved in the entire communication process, so the delay will be longer. A more compromise solution, namely the RDMA solution, is used in intelligent computing networks. The RDMA kernel can be encapsulated by using the Ethernet protocol encapsulation, thereby sharing Ethernet facilities to reduce latency.
The second is link delay. The communication between GPUs must go through the leaf-spine architecture and perform optical signal conversion to achieve data interconnection, therefore, various delays will inevitably happen in various links during the process.
For example, in latency of a decision-making model, the item that can be optimized is the delay caused by the signal recovery unit in optical transceiver. In the delay of the generative model, the delay is mainly caused by data transmission time, while the delay caused by the physical link only accounts for a very small proportion. Therefore, at this time, system delay will be more sensitive to bandwidth utilization, and different directions of delay should be optimized according to different models.
Finally, Chen Cheng concluded that compared with traditional data communication networks, the bandwidth of intelligent computing networks will grow faster, and low-cost interconnection depends on the support of new technologies such as silicon photonics, LPO/LRO, etc. In addition, different models have different requirements for latency, and the directions for optimization will be different.
Related Products:
-
 NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$800.00
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$800.00
-
 NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$800.00
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$800.00
-
 NVIDIA MMA1Z00-NS400 Compatible 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC Optical Transceiver Module
$650.00
NVIDIA MMA1Z00-NS400 Compatible 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC Optical Transceiver Module
$650.00
-
 NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$650.00
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$650.00
-
 NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1200.00
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1200.00
-
 NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$850.00
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$850.00
-
 NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1100.00
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1100.00
-
 NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$750.00
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$750.00
-
 NVIDIA MCP4Y10-N002-FLT Compatible 2m (7ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Passive DAC, Flat top on one end and Flat top on the other
$300.00
NVIDIA MCP4Y10-N002-FLT Compatible 2m (7ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Passive DAC, Flat top on one end and Flat top on the other
$300.00
-
 NVIDIA MCA4J80-N003-FLT Compatible 3m (10ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Active Copper Cable, Flat top on one end and Flat top on the other
$600.00
NVIDIA MCA4J80-N003-FLT Compatible 3m (10ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Active Copper Cable, Flat top on one end and Flat top on the other
$600.00