
High-performance computing is a dynamic field, with Nvidia NVLink representing one of the most important GPU scalability and speed breakthroughs. Here, we will explain exactly what Nvidia NVLink is about, including everything from its architecture to benefits and use cases. Whether you’re into gaming or an AI engineer — knowing this technology may significantly enhance your system’s power. In this article, I will cover some technicalities behind it, compare them against traditional interconnects, and give tips on how we can best tap into their potential. By reading through till the end of my guide, I promise that not only will you gain insights into optimizing workflows driven by GPUs but also achieve unmatched computational efficiency through NVSwitches alongside other links provided by NVLink!
What is Nvidia NVLink and How Does it Enhance GPU Communication?

Understanding NVLink Technology
Nvidia NVLink was made so that GPUs could communicate easily. This means that it can help them talk to CPUs, other high-performance computing elements, or each other. Traditional PCIe connections are often slower than NVLink, which has a lot more bandwidth and much lower latency, allowing several GPUs to act as one big team. All of this results in synchronized processing with better data transfer rates, something very useful when working on deep learning, complex data analytics, or scientific simulations, among other data-intensive applications. With the help of NVLink, systems become more scalable and powerful, hence enabling them to handle heavier workloads and reduce computation time significantly.
In the era of artificial intelligence (AI), high-performance computing (HPC), and data-intensive applications, NVIDIA NVLink is revolutionizing high-speed interconnects for GPUs and CPUs. As a high-bandwidth, low-latency communication protocol, NVLink enables seamless data transfer between processors, unlocking unprecedented performance for AI training, scientific simulations, and enterprise workloads. This comprehensive guide explores what NVLink is, how it works, its benefits, and its applications, providing IT professionals and data center architects with insights to optimize their infrastructure. Whether you’re building an AI supercomputer or scaling a data center, understanding NVLink is key to achieving next-level performance.
NVLink vs PCIe: A Comparative Analysis
In relation to bandwidth, latency, and scalability, there are some major differences between NVLink and PCIe, where the former uses a new generation of NVSwitch chips. Each link of NVLink provides 300 GB/s bandwidth, which is significantly higher than the maximum 64 GB/s provided by PCIe 4.0. This huge leap in bandwidth allows for faster data transfer between GPUs, hence reducing processing time for data-intensive workloads. Moreover, compared to PCIe, NVLink has lower latency, which decreases the waiting period for communication among connected parts. Regarding scalability, NVLink wins again because its design allows multiple graphics cards (GPUs) to function as one system with seamless communication between them. This is very useful in large-scale computing applications where efficiency and speed matter most. Still, being the most commonly used interconnection standard, PCI Express performs less than NVidia’s proprietary high-speed interconnect, making it more suitable for HPC environments overall.
Evolution of NVLink: From NVLink 1.0 to NVLink 4.0
Throughout the years, NVLink has developed faster interconnects and more effective computation. When it was introduced in 2016, NVLink 1.0 featured an 80GB/s bandwidth that immediately made it the new standard for GPU communication. NVLink 2.0 came out with Volta in 2017 and doubled the previous iteration’s bandwidth to 150GB/s while adding cache coherence support, which helps achieve better memory utilization efficiency. Accompanying Ampere’s release in 2020, NVLink 3.0 raised this number again by increasing the maximum theoretical transfer rate up to around six times as much – now with a peak potential transfer rate of about +400% compared to its predecessor (NV Link4). Finally arriving within Nvidia’s Hopper architecture during late(s) year(s), this most current version boasts over nine-hundred+ GBps per link along with being power efficient due to an upgraded error correction feature set, which also includes improved power savings mechanisms, these changes have continually built upon one another so that each new generation extends beyond what can be done before allowing for much more complex data-heavy applications while significantly enhancing performance greatly required in advance computing tasks.
How do you use NVLink on your server for optimal GPU performance?
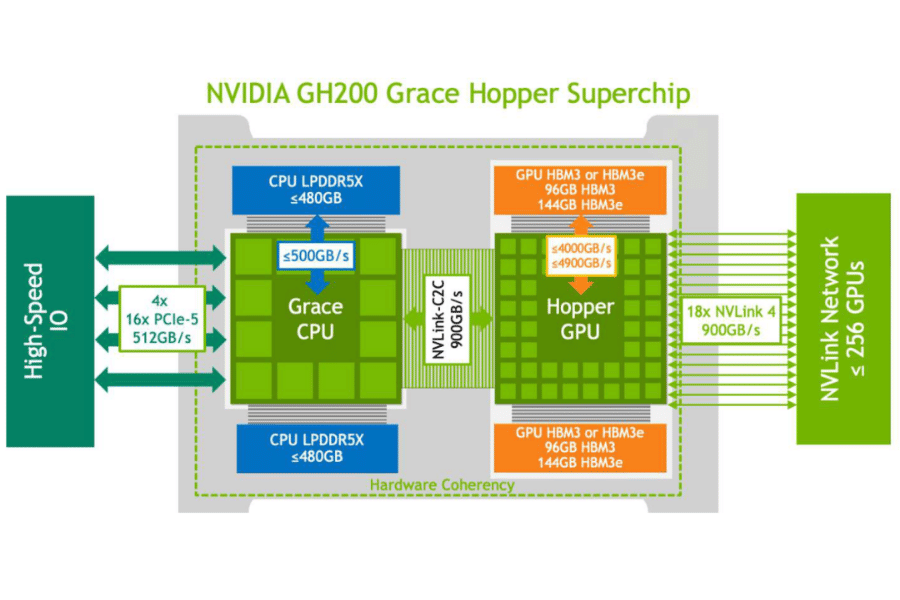
Setting Up NVLink in Your Server
For the best GPU performance on your server, do the following to establish NVLink:
- Check Compatibility: Make sure that your server and GPUs support NVLink. Go through the technical specifications and compatibility lists given by Nvidia for your particular server configuration or graphic card model.
- Install NVLink Bridges: Every pair of compatible graphics cards needs an NVLink bridge between them; therefore, they need to be fixed tightly onto their respective connectors while ensuring good contact so that there can be maximum communication bandwidth.
- Configure BIOS Settings: During booting access UEFI/BIOS settings of the server then enable any feature associated with NV Link if available such as above 4G decoding which might be required by motherboard used in your servers.
- Install Nvidia Drivers: Visit the official website, where you can download the latest drivers for appropriate operating systems and then install them correctly. This should not be ignored because correct drivers are necessary to enable NVlink functionality.
- Check Over The Status Of Nvlink: After installation, one should look at Nvidia-smi or similar management tools to confirm if everything has been set up correctly. For instance, on Linux-based systems, one can simply run the Nvidia-semi link -s command to see the speeds and topology of links.
- Optimize Software Settings: Set computational software up for use with nvlinks. Frequently, this entails optimizing settings that allow full utilization of multi-GPU workloads over the high-bandwidth interconnects these devices offer.
By doing this, you will have successfully configured links within your server. This makes it possible for GPUs to perform heavy-duty computations quickly due to increased data transfer rates across them.
Using NVLink Bridge for Multiple GPUs
When using multiple GPUs through NVLink bridges, the biggest benefit is much faster data transfer speeds between the GPUs compared to standard PCIe lanes. NVLink enables direct GPU-to-GPU communication at lower latency, which is necessary for high-performance deep learning systems and complex simulations.
- Check the compatibility of your GPUs: Make sure that your graphics cards support NVLink. This information should be available from Nvidia’s technical specifications or the manufacturer’s website.
- Install an NVLink Bridge: You will need one bridge per pair of compatible graphics cards. Securely attach the NVLink bridge to its corresponding connectors on both GPUs, ensuring that it fits tightly enough to stay in place during operation but not so tight as to cause damage.
- Configure Software: After installing everything, you must install relevant Nvidia drivers onto your system so that they can recognize and work with those links. Access this functionality through Nvidia’s management tools (Nvidia-semi), where you should see active connections under “NVLink.”
- Optimize Application Performance: Adjust computational software settings to exploit the bandwidth provided by NVLinks fully. In many cases, this simply means specifying certain application parameters that would allow them to fully exploit what NVLinks have to offer, i.e., faster data sharing between multiple GPUs connected via Nvidia link.
Following these steps, you can ensure maximum efficiency when running data-intensive tasks across multiple GPUs linked together using NVIDIA’s proprietary technology, ‘NVLink.’
Role of NvSwitch Chip in NVLink Network
The NvSwitch chip is an integral part of the NVLink network, improving GPU clusters’ scalability and performance. The NvSwitch works as a rapid interconnect that allows many GPUs to communicate among themselves efficiently within one server or across various servers. Several NVLink connections can be supported by each NvSwitch chip, hence achieving high bandwidths for data transfer between low-latency GPU links. Such kind of power is necessary when dealing with heavy computations like AI training, scientific simulations, or data analytics, which need multi-GPU settings where there should not be any interruptions in the data flow, and all resources must be used optimally. Businesses can attain great scalability and system performance through the utilization of this chip, thereby making it an essential component of modern HPC environments.
What are the Latest Innovations in Nvidia NVLink Technology?

Fourth-Generation NVLink: Features and Benefits
The fourth generation of NVLink technology achieves significant improvements in communication between graphics processing units (GPUs) by providing them with a wider range of interconnectivity options, faster bandwidth, and better efficiency than their predecessors. This latest type can reach up to 600 GB/s, which is a tremendous upliftment in terms of data transfer rates, therefore making applications that need high computational power to perform better. It also supports more links per GPU than any other version of NVLink before it, making the entire network robust enough for complex configurations involving multiple scalable GPUs. This includes, among others, error correction enhancements that guarantee integrity as well as fault tolerance mechanisms during high-speed transfers, thereby qualifying it as the most suitable solution for AI, deep learning, or HPC environments where reliability matters most. Such breakthroughs facilitate quicker communication between CPUs and GPUs, leading to decreased congestion points as well as significantly faster speeds when dealing with heavy-duty data tasks.
NVIDIA NVLink delivers unmatched performance for GPU and CPU interconnects, offering several key advantages:
- Ultra-High Bandwidth: NVLink provides up to 900 GB/s (NVLink 4.0), enabling rapid data transfers for AI and HPC workloads.
- Low Latency: Sub-microsecond communication ensures real-time processing for time-sensitive applications.
- Scalability: NVLink with NVSwitch supports massive multi-GPU systems, ideal for supercomputers like NVIDIA DGX H100.
- Improved Efficiency: Cache coherency and direct memory access reduce CPU overhead, boosting system performance.
- Energy Efficiency: Higher bandwidth per link reduces the number of connections needed, lowering power consumption.
- Seamless Integration: NVLink is optimized for NVIDIA GPUs and CPUs, ensuring plug-and-play compatibility in supported systems.
- Future-Proofing: Supports emerging AI and HPC workloads, preparing systems for next-gen applications.
These benefits make NVLink a game-changer for organizations building high-performance computing environments.
NVLink Integration in NVIDIA A100 and H100 GPUs
The incorporation of NVLink into NVIDIA A100 and H100 GPUs is a huge step towards interconnectivity and computing power. In A100, NVLink provides 600 GB/s per GPU of combined bandwidth, which leads to ultra-fast communication through the use of NVLink links required for large-scale AI and deep learning workloads. It makes it possible for several A100 GPUs to work together by sharing information smoothly, thus increasing system-wide efficiency.
Additionally, H100 GPUs introduce higher-performance NVLink connectors that offer wider bandwidths per connection. With this feature, H100 can split the GPU into multiple instances simultaneously handling different kinds of tasks, making them useful in data centers where there is a need for flexibility as well as resource optimization, which leads to improved performance coupled with cost-effectiveness.
Another advantage brought about by these two models is their ability to correct errors and tolerate faults better than before thanks to NVSwitch chips and switches involved in achieving higher data speeds across various parts of a computer system. This feature alone makes them ideal for use in mission-critical areas such as scientific research, artificial intelligence or even high-performance computing where quick sharing of information is key.
How Does NVLink Improve High-Speed Data Transfer?

NVLink as a High-Speed Interconnect: How it Works
NVLink is a proprietary NVIDIA interconnect that uses a high-speed, serial-based communication protocol to connect GPUs and CPUs. It operates as a point-to-point link, allowing direct data transfer between processors without relying on slower system buses like PCIe. Here’s how NVLink functions:
- High-Speed Links: Each NVLink connection consists of multiple lanes (e.g., 8 lanes in NVLink 3.0), each delivering up to 50 GB/s bidirectional bandwidth.
- Cache Coherency: NVLink supports NVIDIA’s NVSHMEM, enabling shared memory access across GPUs, reducing data copying and improving efficiency.
- Scalable Architecture: Supports topologies like NVSwitch, which connects multiple GPUs in a fabric, enabling systems like NVIDIA DGX A100 to scale to hundreds of GPUs.
- Integration with Systems: NVLink is integrated into NVIDIA GPUs (e.g., A100, H100) and Grace CPUs, with switches like NVIDIA NVLink Switch extending connectivity.
By bypassing traditional bottlenecks, NVLink accelerates data-intensive workloads, making it a cornerstone of modern AI and HPC systems.
NVLink serves as a high-speed linkage between processors by allowing for direct GPU-to-GPU communication with minimal delays. Mainly, traditional PCIe connections create data bottlenecks in applications that require vast amounts of information; this is what NVLink solves through its much larger bandwidths. Each NVLink connection boasts up to 25 GB/s worth of bandwidth, which can be aggregated to levels way beyond those offered by standard PCIe connections, thus underpinning the fact that it is fast and efficient.
The scalability of multi-GPU setups is made possible by the mesh networking design used at the core of NVLink as well as its protocol. This architecture permits easy transfer of data among different GPUs, thereby enabling them to share tasks more effectively via links provided by NVLinks. One important feature of these links is their ability to support coherent memory across many graphics card units, treating such memories as if they were one pool. Such an approach towards sharing resources makes it easier for programs working with large volumes of information to locate and process required bits faster than any other method, thus greatly benefiting areas like AI or scientific simulations.
Moreover, fault tolerance plus error correction capabilities built into every aspect of operation help maintain integrity while transferring data at very high speeds in NVLink. Hence, this technology becomes necessary not only for supercomputers but also for enterprise-level computing environments where speed must be combined with reliability without compromise being allowed either way. By increasing data rates and decreasing waiting periods during processing stages, tasks are performed quicker than ever before, resulting in significant performance improvements, especially when dealing with complex computations.
NVLink Network vs Traditional Interconnect Technologies
Comparing NVLink to traditional interconnect technologies like PCIe, there are several key differences. One of these is that it has much greater bandwidth – up to 25 GB/s per link, in contrast with PCIe 4.0’s maximum of 16 GB/s per lane in a 16-lane configuration. This higher bandwidth means faster data transfer rates and, thus, less latency when dealing with large amounts of data.
Additionally, while PCIe operates through point-to-point connections, NVLink uses a mesh networking architecture which allows for more flexible and scalable multi-GPU setups; this lets GPUs directly communicate with one another without having to go via the CPU. As a result, workload sharing and resource utilization become more efficient – especially useful for heavy-duty applications such as scientific simulations or machine learning.
Another area where NVLink outperforms its competitors is memory coherency: It treats the memories of multiple GPUs as one pool, thereby streamlining access to information while greatly increasing performance speed, unlike standard PCIe, which treats memory as separate for each GPU.
Last but not least importantly so because reliability matters too much now than ever before, even within these high-performing environments where accuracy must be precise due to time constraints, i.e., error correction codes were created. Therefore, they can detect errors during transmission, making sure that none occurs throughout any communication channel, even if it means slowing down everything else around. Just ensure all things work well together forever till end times, amen! In short, I think NVLink wins over regular old, boring, slowpoke PCI Express because it’s faster and more remarkable.
Understanding NVSwitch and its Impact on NVLink Performance
To improve the scalability and efficiency of NVLink, NVSwitch was developed as a fully connected switch with high bandwidth. When several GPUs are brought into the system, they can communicate directly through this switch without any hiccups, thereby maximizing each GPU’s computational power. It is also known that integrating it solves bottlenecks that are common in traditional multi-GPU configurations.
According to the NVSwitch design, each GPU connects through multiple links to aggregate more bandwidth, reducing latency. In such an interconnection scheme, data can move from one Graphics Processing Unit (GPU) card to another without passing through the CPU, just like in NVLink, but on a larger scale.
Additionally, NVSwitch supports advanced memory-sharing capabilities. This feature expands the shared memory pool concept of NVLink and enables better resource utilization through single address space awareness among Graphics cards when processing tasks jointly at higher speeds, thus making them faster, too.
When dealing with massive amounts of information within lightning-fast speeds over wide area networks used for supercomputing, this product ensures fault tolerance and error correction mechanisms are in place throughout the entire network so that no corrupt or incomplete files are transferred during the transfer process because it works at such great heights where even small errors can lead catastrophic failures. Therefore, any HPC system that uses it can handle much heavier workloads, thus becoming an essential component for state-of-the-art machine learning and AI applications.
Why Choose NVLink for Your GPU-Powered Applications?
NVLink is deployed in high-performance environments where speed and scalability are critical. Key applications include:
- Artificial Intelligence and Machine Learning: NVLink accelerates AI training by enabling fast data sharing between GPUs in systems like NVIDIA DGX A100.
- High-Performance Computing (HPC): Supports complex simulations in fields like physics, genomics, and climate modeling with low-latency interconnects.
- Data Analytics: NVLink enhances real-time analytics by reducing data transfer bottlenecks in GPU-accelerated databases.
- Scientific Research: Powers supercomputers (e.g., NVIDIA Selene) for large-scale computational research.
- Enterprise AI Workloads: Enables efficient scaling of AI inference and training in enterprise data centers.
These use cases highlight NVLink’s role in powering cutting-edge computational workloads.

Advantages of NVLink in AI and Machine Learning
NVLink has several critical benefits for AI and machine learning:
- More Bandwidth: NVLink provides much greater bandwidth than traditional PCIe connections. This allows GPUs to communicate faster, which is important for data-intensive AI workloads involving quick data swapping.
- Reduced Latency: NVLink considerably lowers latency by enabling direct communication between GPUs. This is especially useful when training models across multiple GPUs because big models need to be synchronized within a limited time.
- Unified Memory Architecture: With NVLink, unified memory address space is supported so that different GPUs can effortlessly share memory. This improves memory utilization, making it more efficient in dealing with large datasets and complex models.
These improvements ensure the performance, efficiency, and scalability of AI and machine learning applications are enhanced through NVLink utilization; this also means that computational resources will be used optimally.
Performance Improvements with NVLink in HPC Workloads
NVLink improves high-performance computing (HPC) workloads by increasing data transfer speed and scalability. In common HPC configurations, there can be a bottleneck in computation efficiency due to data transfer between multiple GPUs or between CPUs and GPUs. NVLink solves this problem through improved GPU-to-GPU and CPU-to-GPU communication with higher bandwidths and lower latencies.
- Faster Data Relocation: NVLink provides Bidirectional bandwidths of up to 300 GB/s, which is much faster than the best possible PCIe rate. This ensures the quick movement of data necessary for the prompt execution of complex scientific simulations and large-scale computations.
- Architecture that can be Scaled: The scalability of HPC systems is enhanced when NVLink creates a mesh interconnecting several GPUs. This means that more Graphics Processing Units can be incorporated into the system as computational requirements increase without suffering a significant decrease in performance.
- Computational Resources and Unified Memory: NVLink supports a unified memory architecture that promotes effective memory sharing among different Graphic Processors. This feature becomes useful, especially in HPC workloads with massive datasets that need large amounts of memory capacity and bandwidth.
Through these features, NVLink makes a huge difference in performance, efficiency, scalability, etc., thus being a vital element during scientific research, complex simulations, or large-scale data analysis for HPC tasks.
NVLink in Real-World Applications: Case Studies
Case Study 1: Weather Forecasting
The use of NVLink in weather forecasting is one of the main areas. The implementation of NVLink by the National Center for Atmospheric Research (NCAR) was done with the aim of improving the speed and accuracy of their climate models. The adoption of NCAR to NVLink-enabled GPUs resulted in a significant increase in computational speed, which allowed them to process complex atmospheric data more quickly than before. What’s more, larger amounts of big data could be handled better thanks to enhanced data throughput together with unified memory architecture provided by NVLink, thus making predictions about weather become much more accurate and timely.
Case Study 2: Genomic Research
NVLink has played a vital role in genomic research and in accelerating genome sequencing and analysis. Corporations like WuXi NextCODE have integrated NVLinks into their HPC frameworks in order to ensure rapid processing of genomic data can take place and save time spent on this particular task. By using NVLinks between GPUs, interconnectivity problems were solved, which led to seamless analysis being carried out on vast genetic datasets. This breakthrough paved the way for personalized medicine, whereby treatment plans are tailored based on quick but precise genetic analysis.
Case Study 3: Artificial Intelligence and Machine Learning
The applications of artificial intelligence (AI) or machine learning(ML) would not be complete without mentioning how extensively they have adopted NVLinks. OpenAI, being a prominent AI research lab, uses this technology so that training large neural networks becomes easier than it used to be before. There is a need for training such models faster, among other things, because there are many things that can only happen if they are able to learn faster also, this involves data sets that may require higher speeds, thus necessitating multiple links instead of single ones; all these improvements are brought about by speeding up GPU-to-GPU communication with respect to time taken during the training period.
These examples highlight different ways in which high-performance computing can benefit from using NVLink. Thus, they prove its effectiveness in improving computational efficiency and scalability as well as enabling faster data transfer rates.
Reference sources
Frequently Asked Questions (FAQs)
Q: What is Nvidia NVLink, and how does it enhance GPU performance?
A: NVLink is a high-speed interconnect protocol developed by Nvidia that allows for faster communication between GPUs within a server. It enhances performance by providing higher bandwidth and lower latency compared to traditional PCIe connections.
Q: How does NVLink technology compare to traditional PCIe switch connections?
A: NVLink offers significantly greater bandwidth and lower latency than traditional PCIe switch connections. This allows for more efficient data transfer and communication between GPUs within a server, leading to improved overall performance.
Q: What is the role of NVSwitch in Nvidia’s NVLink architecture?
A: NVSwitch acts as a physical switch that connects multiple NVLink interfaces, allowing for scalable communication between a larger number of GPUs. This makes it possible, for instance, for systems like the Nvidia DGX to connect up to 256 GPUs within the server using NVSwitch chips and switches.
Q: Can you explain the evolution of NVLink from NVLink 2.0 to the current generation?
A: NVLink has evolved significantly since its introduction. NVLink 2.0 offered improved bandwidth and lower latency over the original NVLink. The new generation of NVLink, which includes NVLink 3.0, provides even greater performance enhancements and supports newer GPUs like the Nvidia H100.
Q: How does the Nvidia H100 leverage NVLink for improved performance?
A: The Nvidia H100 utilizes NVLink connections to achieve faster data transfer rates and lower latency between GPUs within the system. This enables better scalability and efficiency, particularly in data-intensive and AI applications.
Q: What benefits does NVLink offer for NVLink server configurations?
A: In NVLink server configurations, NVLink provides high-speed, low-latency communication between GPUs, leading to greater computational efficiency and performance. This is particularly beneficial for applications requiring intensive parallel processing, such as AI and machine learning.
Q: How do NVLink and NVSwitch technologies work together to benefit multi-GPU setups?
A: NVLink and NVSwitch technologies work together by using NVLink to establish high-speed communication between GPUs and NVSwitch to scale this communication across multiple GPUs in a system. This combination allows for greater scalability and performance in multi-GPU setups like the Nvidia DGX.
Q: What advantages does NVLink 3.0 offer over its predecessors?
A: NVLink 3.0 provides enhanced bandwidth, reduced latency, and better scalability compared to earlier generations of NVLink. This allows for improved performance in demanding applications and greater support for advanced GPU architectures, including those found in the Nvidia A100 and H100.
Q: How has Nvidia integrated NVLink and NVSwitch in their latest products?
A: Nvidia has integrated NVLink and NVSwitch technologies extensively in their latest products, such as the Nvidia DGX systems. These integrations allow the new Nvidia GPUs to utilize high-speed interconnects to maximize performance and efficiency in large-scale computing environments.
Q: What are the practical applications of using NVLink servers with NVSwitches?
A: Practical applications of using NVLink servers with NVSwitches include high-performance computing (HPC), deep learning, AI training, and large-scale data analysis with NVSwitch physical switches. These setups provide the necessary high-speed communication between multiple GPUs required for handling complex and compute-intensive tasks efficiently, leveraging NVLink’s high-speed communication bandwidth and efficiency.
Related Products:
-
 NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA(Mellanox) MMA1T00-HS Compatible 200G Infiniband HDR QSFP56 SR4 850nm 100m MPO-12 APC OM3/OM4 FEC PAM4 Optical Transceiver Module
$139.00
-
NVIDIA MFP7E10-N010 Compatible 10m (33ft) 8 Fibers Low Insertion Loss Female to Female MPO Trunk Cable Polarity B APC to APC LSZH Multimode OM3 50/125
$47.00
-
NVIDIA MCP7Y00-N003-FLT Compatible 3m (10ft) 800G Twin-port OSFP to 2x400G Flat Top OSFP InfiniBand NDR Breakout DAC
$260.00
-
NVIDIA MCP7Y70-H002 Compatible 2m (7ft) 400G Twin-port 2x200G OSFP to 4x100G QSFP56 Passive Breakout Direct Attach Copper Cable
$155.00
-
NVIDIA MCA4J80-N003-FTF Compatible 3m (10ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Active Copper Cable, Flat top on one end and Finned top on other
$600.00
-
NVIDIA MCP7Y10-N002 Compatible 2m (7ft) 800G InfiniBand NDR Twin-port OSFP to 2x400G QSFP112 Breakout DAC
$190.00











