
In modern computing architecture, from chips to processors to data centers, each level involves different interconnection technologies. These technologies not only ensure the fast and secure transmission of data, but also provide strong support for emerging computing needs. This article mainly introduces different levels of network interconnection technology and reveals how it works in the current computing architecture. The whole article can be divided into three parts: system-on-chip Soc interconnection, processor interconnection and data center interconnection.
Soc Interconnection
Innovation in interconnect begins at the most basic level: the system on a chip. Whether located in the chip or on the package, advanced interconnection means data moves faster and performance scales more easily.
- PIPE (Peripheral Component Interconnect Express Physical Layer Protocol)
PIPE is the physical layer protocol of PCIe (Peripheral Component Interconnect Express). PCIe is a universal computer bus standard used to connect hardware devices inside a computer, such as graphics cards, solid-state drives, etc. The physical layer protocol defines the electrical characteristics and signal transmission methods to ensure that data can be transmitted correctly between hardware devices. PCIe supports the connection of devices with various performance requirements by providing different data transfer rates and interfaces.
- LPIF (Logical PHY Interface)
LPIF is an interface standard for high-speed interconnection between processors, between processors and accelerators, and between chips and chips (die-to-die). LPIF is designed to provide a flexible and scalable way to support different data transmission needs and allow communication between devices at different frequencies. It supports multiple protocols including PCIe 6.0, CXL 3.0 and UPI 3.0.
- CPI (CXL Cache-Mem Protocol Interface)
CPI is a component of Compute Express Link (CXL), a communication protocol specifically designed to handle cache and memory. CXL is an open, high-speed interconnect technology designed to connect CPUs, GPUs, and other accelerators, enabling high-speed data transmission and resource sharing between them. As part of CXL, CPI defines the interface standard between cache and memory to support efficient data exchange and consistency protocols.
- UFI (Universal Flash Storage Interface)
UFI is a universal flash storage interface standard that allows different storage devices to communicate and transfer data in a unified way. The UFI standard is designed to improve the compatibility and performance of storage devices, allowing the devices to work quickly and efficiently.
- UCIe (Universal Chiplet Interconnect Express)
UCIe is an emerging open industry standard interconnection technology specifically designed for chiplet-to-chiplet connections. UCIe supports multiple protocols, including standard PCIe and CXL, as well as general Streaming protocols or custom protocols. Its goal is to adopt a standard physical layer and link layer to standardize the inter-die communication protocol, but keep the upper layer protocol flexible. The emergence of UCIe technology is to meet the challenges brought by the slowdown of Moore’s Law. It builds large systems by packaging and integrating multiple Chiplet to reduce costs and improve efficiency.
Processor Interconnection
Moving data between different compute engines, memory, I/O, and other peripherals requires a specialized set of high-bandwidth and low-latency interconnection technologies. Processor interconnection technologies such as NVlink, PCIe, CXL and UPI enable all these elements to operate as a whole, supporting fast data transmission between devices.
- NVLink
NVLink is a high-speed interconnection technology designed specifically to connect NVIDIA GPUs. It allows GPUs to communicate with each other in a point-to-point manner, bypassing the traditional PCIe bus, achieving higher bandwidth and lower latency. NVLINK can be used to connect two or more GPUs to achieve high-speed data transmission and sharing, providing higher performance and efficiency for multi-GPU systems.
- PCIe (Peripheral Component Interconnect Express)
It is a universal computer bus standard used to connect hardware devices inside the computer, such as graphics cards, solid-state drives, etc. PCIe technology is widely used for its high-speed serial data transmission capabilities, supporting a variety of devices and a wide range of application scenarios, including data centers, artificial intelligence, and processor interconnection. The PCIe interface allows devices to initiate DMA operations to access memory, just knowing on condition that the target physical address is known. It is currently available up to version 6.0, version 7.0 is planned to be released in 2025.
- CXL (Compute Express Link)
It is a new type of high-speed interconnection technology jointly launched by Intel, AMD and other companies. It aims to provide higher data throughput and lower latency to meet the needs of modern computing and storage systems. CXL technology allows memory to be shared between the CPU and devices, and between devices, enabling faster and more flexible data exchange and processing. CXL contains three sub-protocols: CXL.io, CXL.cache, and CXL.memory, which are used for different data transmission and memory sharing tasks respectively. It is currently available up to version 3.1.
A notable feature of CXL is its support for memory consistency, which means that data can be shared between different devices without complex data copying. This consistency is particularly important for multiprocessor systems and large-scale computing tasks because it can improve data access efficiency, reduce latency, and thus speed up computing. Additionally, CXL offers the flexibility to be used in a wide variety of devices and applications, making it a universal interconnect solution.
- UPI (Ultra Path Interconnect)
It is a point-to-point connection protocol developed by Intel for high-speed communication between multi-core processors and/or multiple processors. It is designed to replace the previous QPI (QuickPath Interconnect) technology and provides higher bandwidth, lower latency and better energy efficiency.
- Infinity Fabric
It is a high-speed interconnect technology developed by AMD, used to connect the various cores, caches, and other components inside AMD processors to achieve efficient data transmission and communication. Infinity Fabric uses a distributed architecture that contains multiple independent channels, each of which can carry out bidirectional data transmission. This design allows fast and low-latency communication between different cores, thereby improving overall performance. In addition, Infinity Fabric is scalable and flexible. It allows connections between different chips and supports combining multiple processors into more powerful systems.
Data Center Interconnection
Hyperscale data centers can occupy an area equivalent to several football fields, creating unprecedented demands for architectural speed and intelligent processing capabilities. High-speed, long-distance interconnect technologies can significantly increase performance while performing computations with low latency. Data center-level interconnection technology is the foundation for supporting modern Internet services and cloud computing. From high-speed data transmission at the rack layer to data center network connections, these technologies together ensure the efficiency, stability and scalability of data centers.
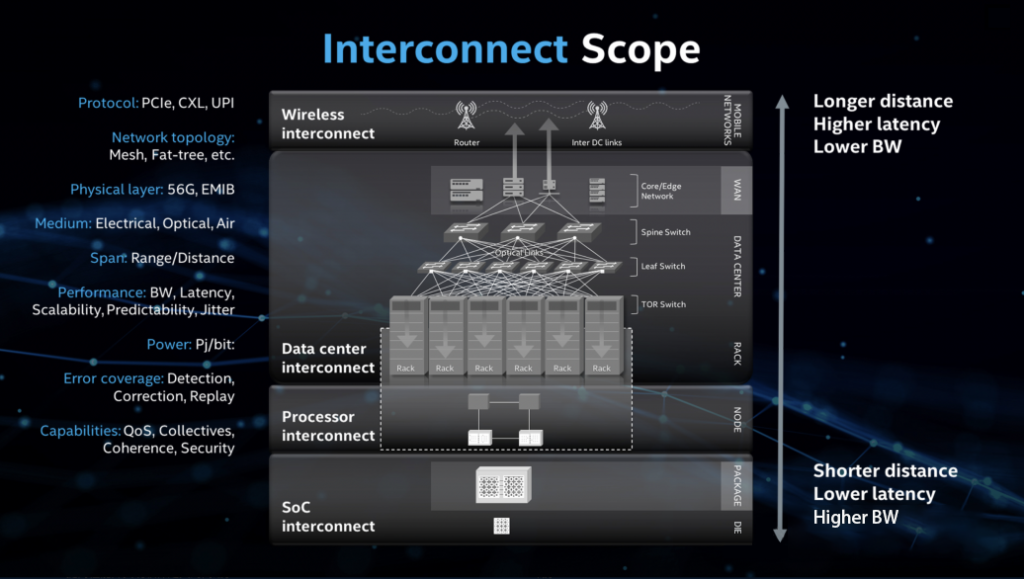
Interconnection technique
- Software Defined Networking (SDN)
Software-Defined Networking (SDN) is a network architecture concept that separates the control plane from the data plane of the network, allowing network administrators to centrally manage and configure network behavior through software programs. The core idea of SDN is to abstract the intelligent control function of the network from the network devices to realize the dynamic management and optimization of network traffic.
- Ethernet and RoCE
Ethernet is the most widely used and mature network technology, originated from Xerox PARC. It can transmit large amounts of data between servers in data centers, which is critical for many accelerated computing tasks. Under the RoCE protocol, Ethernet integrates the RDMA function, which greatly improves the communication performance in high-performance computing scenarios. To meet the new challenges posed by AI and HPC workloads, network giants have jointly established Ultra Ethernet Consortium (UEC). The Ultra Ethernet solution stack will leverage the ubiquity and flexibility of Ethernet to handle a variety of workloads while being scalable and cost-effective, injecting new vitality into Ethernet.
RoCE (RDMA over Converged Ethernet): RoCE technology allows remote direct memory access on a standard Ethernet network. It supports RDMA by optimizing Ethernet switches, providing high-performance network connections while maintaining compatibility with traditional Ethernet.
- Infiniband
InfiniBand: A network technology designed specifically for high-performance computing (HPC) that provides high-bandwidth, low-latency network connections, supports point-to-point connections and remote direct memory access (RDMA), which is suitable for large-scale computing and data center environments.
- Network topology
Common topologies include star network topology, Fat-tree topology, Leaf-Spine topology, hierarchical topology, etc. Here we mainly introduce Fat-tree and leaf-spine, both of which are data center network architectures based on the CLOS network model.
- Leaf-Spine topology
It is a flat network design consisting of the Spine layer (backbone layer) and the Leaf layer (access layer). Each Leaf switch is connected to all Spine switches to form a full mesh topology. This design provides high-bandwidth, low-latency, and non-blocking server-to-server connections, which is easy to scale horizontally, and has high reliability and ease of management. The advantages of the Leaf-Spine architecture include flat design to reduce latency, easy scalability, low convergence ratio, simplified management, and multi-cloud management.
- Fat-Tree topology
It is a tree-structured network design, usually consisting of three layers: core layer, aggregation layer and access layer. The main feature of the Fat-Tree topology lies in that there is no bandwidth convergence, that is, the network bandwidth does not converge from the leaves to the root, which provides a basis for building a large-scale non-blocking network. Each of its nodes (except the root node) needs to ensure equal upstream and downstream bandwidths, and all switches can be the same, thereby reducing costs. However, the Fat-Tree topology also has its limitations, such as limited scalability, poor fault tolerance, unfavorable deployment of certain high-performance distributed applications, and high costs.
- Core/Edge Network
The core network is a high-speed, high-reliability network backbone that is responsible for transmitting large amounts of data between major nodes in the network and providing routing services. The edge network is the access layer of the network, directly connecting end users and devices, providing diversified services and optimizing user experience.