
To achieve good training performance, GPU networks need to meet the following conditions:
1. End-to-end delay: Since GPU communication is frequent, reducing the overall latency of data transfer between nodes helps to shorten the overall training time.
2. Lossless transmission: This is critical for AI training because any loss of gradients or intermediate results will cause the training to fall back to the previous checkpoint stored in memory and restart, severely affecting the training performance.
3. Effective end-to-end congestion control mechanism: In a tree topology, transient congestion is inevitable when multiple nodes transmit data to a single node. Persistent congestion will increase the system tail latency. Due to the sequential dependency between GPUs, even if one GPU’s gradient update is affected by network latency, it may cause multiple GPUs to stop working. A slow link is enough to reduce the training performance.
In addition to the above factors, the system’s total cost, power consumption, and cooling costs also need to be considered comprehensively. Based on these premises, we will explore the different GPU architecture design choices and their pros and cons.
I. NVLink Switching System
The NVLink switch that connects 8 GPUs in a GPU server can also be used to build a switching network that connects GPU servers. Nvidia demonstrated a topology that uses the NVSwitch architecture to connect 32 nodes (or 256 GPUs) at the Hot Chips conference in 2022. Since NVLink is designed specifically for connecting GPUs with high-speed point-to-point links, it has higher performance and lower overhead than traditional networks.
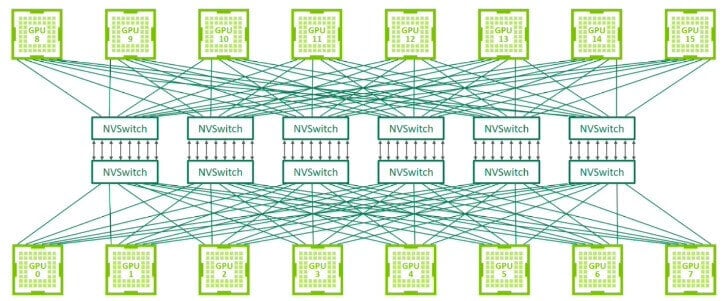
The third-generation NVswitch is equipped with 64 NVLink ports, providing up to 12.8Tbps of switching capacity, while supporting multicast and network aggregation functions. Network aggregation can gather all the gradients generated by the working GPUs within the NVswitches, and feed back the updated gradients to the GPUs for the next iteration. This feature helps to reduce the amount of data transfer between GPUs during the training iteration process.
According to Nvidia, the NVswitch architecture is twice as fast as the InfiniBand switching network when training the GPT-3 model, showing impressive performance. However, it is worth noting that the bandwidth of this switch is four times less than the 51.2Tbps switch provided by high-end switch suppliers.
If one tries to use NVswitches to build a large-scale system that contains more than 1000 GPUs, it is not only cost-ineffective but also may be limited by the protocol itself, making it unable to support large-scale systems. In addition, Nvidia does not sell NVswitches separately, which means that if data centers want to expand their existing clusters by mixing and matching GPUs from different suppliers, they will not be able to use NVswitches, because other suppliers’ GPUs do not support these interfaces.

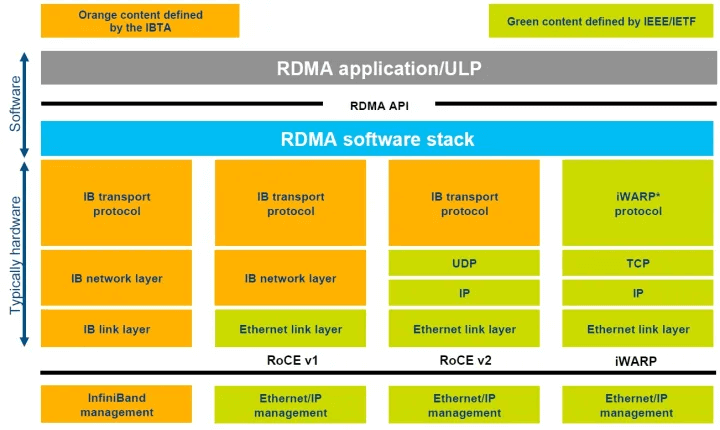
II. InfiniBand Network
InfiniBand (IB) is a technology that has been serving as a high-speed alternative since its launch in 1999, effectively replacing PCI and PCI-X bus technologies, and widely used for connecting servers, storage, and network. Although its initial grand vision was scaled down due to economic factors, InfiniBand still has been widely applied in fields such as high-performance computing, artificial intelligence/machine learning clusters, and data centers. This is mainly attributed to its excellent speed, low latency, lossless transmission, and remote direct memory access (RDMA) capabilities.
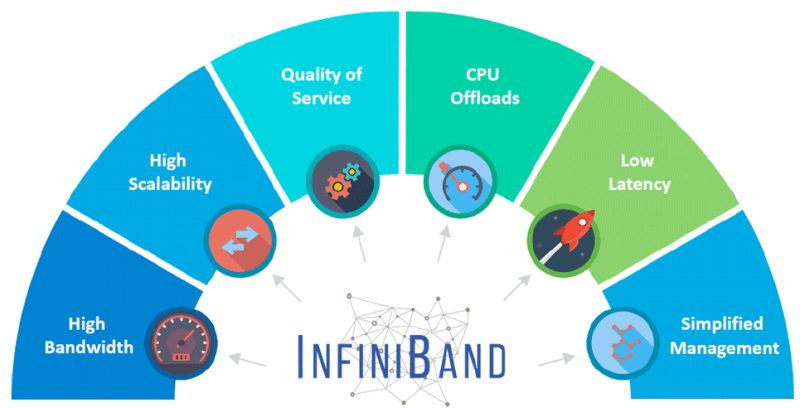
The InfiniBand (IB) protocol aims to achieve an efficient and lightweight design, effectively avoiding the common overheads in Ethernet protocols. It supports both channel-based and memory-based communication, and can efficiently handle various data transfer scenarios.
By using credit-based flow control between send/receive devices, IB achieves lossless transmission (queue or virtual channel level). This hop-by-hop flow control ensures that no data loss will occur due to buffer overflow. In addition, it also supports congestion notification between endpoints (similar to ECN in the TCP/IP protocol stack). IB provides excellent quality of service, allowing prioritizing certain types of traffic to reduce latency and prevent packet loss.
It is worth mentioning that all IB switches support the RDMA protocol, which enables data to be transferred directly from the memory of one GPU to the memory of another GPU, without the intervention of the CPU operating system. This direct transfer mode improves the throughput and significantly reduces the end-to-end latency.
However, despite its many advantages, the InfiniBand switching system is not as popular as the Ethernet switching system. This is because the InfiniBand switching system is relatively difficult to configure, maintain, and scale. The InfiniBand control plane is usually centrally controlled by a single subnet manager. Although it can run well in small clusters, its scalability may become a challenge for networks with 32K or more GPUs. Moreover, the IB network also requires specialized hardware, such as host channel adapters and InfiniBand cables, which makes its expansion cost higher than the Ethernet network.
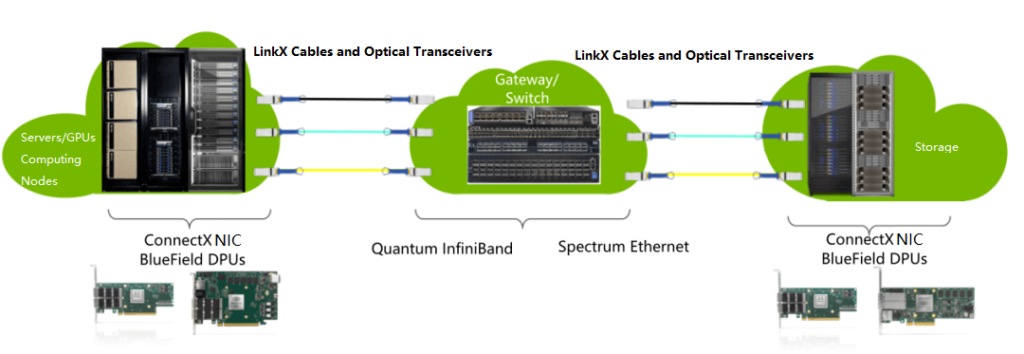
Currently, Nvidia is the only supplier that provides high-end IB switches for HPC and AI GPU clusters. For example, OpenAI used 10,000 Nvidia A100 GPUs and IB switching network to train their GPT-3 model on Microsoft Azure cloud. Meta recently built a cluster with 16K GPUs, which uses Nvidia A100 GPU servers and Quantum-2 IB switches (Nvidia launched a new InfiniBand network platform at the GTC 2021 conference, with 25.6Tbps of switching capacity and 400Gbps ports). This cluster is used to train their generative artificial intelligence models, including LLaMA. It is worth noting that when connecting more than 10,000 GPUs, the switching between GPUs inside the server is done by the NVswitches inside the server, while the IB/Ethernet network is responsible for connecting the servers.
To cope with the training demand for larger parameters, ultra-large-scale cloud service providers are looking to build GPU clusters with 32K or even 64K GPUs. At this scale, it may make more economic sense to use Ethernet networks. This is because Ethernet has formed a strong ecosystem among many silicon/system and optical module suppliers, and aims for open standards, achieving interoperability among suppliers.
RoCE Lossless Ethernet
Ethernet is widely used in various applications, from data centers to backbone networks, with speeds ranging from 1Gbps to 800Gbps, and even expected to reach 1.6Tbps in the future. Compared with Infiniband, Ethernet has an edge in interconnect port speed and total switch capacity. Moreover, Ethernet switches are relatively cheaper, with lower cost per bandwidth unit, thanks to the fierce competition among high-end network chip suppliers, which drives them to integrate more bandwidth into ASICs, thus reducing the cost per gigabit.
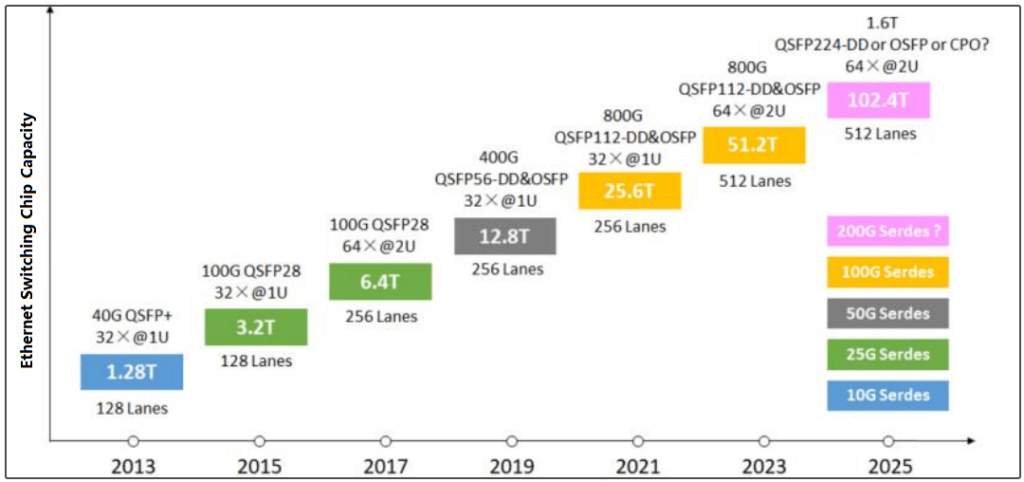
The main suppliers of high-end Ethernet switch ASICs can provide up to 51.2Tbps of switch capacity, equipped with 800Gbps ports, which is twice the performance of Quantum-2 (a new InfiniBand network platform released at NVIDIA GTC 2021, with 25.6Tbps of switch capacity and 400Gbps ports). This means that if the switch throughput is doubled, the number of switches required to build a GPU network can be halved.
Ethernet can also provide lossless transmission service, through priority flow control (PFC). PFC supports eight service classes, each of which can be flow-controlled, and some can be designated as lossless classes. When processing and passing through switches, lossless traffic has higher priority than lossy traffic. In case of network congestion, switches or NICs can manage upstream devices through flow control, instead of simply dropping packets.
In addition, Ethernet also supports RDMA (remote direct memory access) through RoCEv2 (RDMA over Converged Ethernet), where RDMA frames are encapsulated in IP/UDP. When RoCEv2 packets arrive at the network adapter (NIC) in the GPU server, the NIC can directly transfer the RDMA data to the GPU’s memory, without CPU intervention. Meanwhile, powerful end-to-end congestion control schemes such as DCQCN can be deployed to reduce the end-to-end congestion and packet loss of RDMA. In terms of load balancing, routing protocols such as BGP use equal-cost multipath routing (ECMP) to distribute packets over multiple paths with equal “cost” to the destination. When packets arrive at a switch that has multiple equal-cost paths to the target, the switch uses a hash function to decide the path of the packets. However, the hash is not always perfect and may cause some links to be unevenly loaded, resulting in network congestion.
In terms of load balancing, routing protocols such as BGP use Equal-Cost Multi-Path Routing (ECMP) to distribute packets across multiple paths with equal “cost”. When a packet arrives at a switch that has multiple equal-cost paths to the destination, the switch uses a hash function to decide which path to send the packet. However, the hash is not always perfect, and it may cause some links to be unevenly loaded, resulting in network congestion.
To solve this problem, some strategies can be adopted, such as reserving a slight excess of bandwidth or implementing adaptive load balancing, which allows the switch to route new flow packets to other ports when a path is congested. Many switches already support this feature. Moreover, RoCEv2’s packet-level load balancing can evenly disperse packets across all available links, to maintain link balance. But this may cause packets to arrive at the destination out of order, and it requires the network card to support processing these unordered data on the RoCE transport layer, to ensure that the GPU receives the data in order. This requires additional hardware support from the network card and the Ethernet switch.
Additionally, some vendors’ ROCE Ethernet switches can also aggregate the gradients from the GPUs inside the switch, which helps reduce the inter-GPU traffic during the training process, such as NVIDIA’s high-end Ethernet switches.
In summary, high-end Ethernet switches and network cards have powerful congestion control, load balancing, and RDMA support, and they can scale to larger designs than IB switches. Some cloud service providers and large-scale cluster companies have started to use Ethernet-based GPU networks, to connect more than 32K GPUs.
DDC Fully Scheduled Network
Recently, several switch/router chip vendors announced the launch of chips that support fully scheduled Fabric or AI Fabric. This fully scheduled network has been applied to many modular chassis designs for more than a decade, including Juniper’s PTX series routers, which use a Virtual Output Queue (VOQ) network.
In the VOQ architecture, packets are buffered only once at the ingress leaf switch, and stored in queues corresponding to the final egress leaf switch/WAN port/output queue. These queues are called Virtual Output Queues (VOQs) at the ingress switch. Therefore, each ingress leaf switch provides buffer space for every output queue in the entire system. The size of this buffer is usually enough to accommodate the packets of each VOQ when they encounter congestion in 40-70 microseconds. When the amount of data in a VOQ is small, it is kept in the on-chip buffer; when the queue starts to grow, the data is transferred to the deep buffer in the external memory.
When a VOQ on an ingress leaf switch accumulates multiple packets, it sends a request to the egress switch, asking to transmit these packets in the network. These requests are sent through the network to the egress leaf switch.
The scheduler in the egress leaf switch approves these requests based on a strict scheduling hierarchy and the available space in its shallow output buffer. The rate of these approvals is limited to avoid oversubscribing the switch links (beyond the queue buffer acceptance range).
Once the approval arrives at the ingress leaf switch, it sends the approved set of packets to the egress and transmits them through all available uplinks.
The packets sent to a specific VOQ can be evenly dispersed across all available output links, to achieve perfect load balancing. This may cause the packets to be reordered. However, the egress switch has a logical function that can reorder these packets in sequence, and then transmit them to the GPU nodes.
Since the egress scheduler controls the approved data before it enters the switch, avoiding the overuse of link bandwidth, it eliminates 99% of the congestion problems caused by incast in the Ethernet data plane (when multiple ports try to send traffic to a single output port) and eliminates head-of-line blocking (HOL blocking). It should be noted that in this architecture, the data (including requests and approvals) is still transmitted through Ethernet.
HOL blocking refers to the phenomenon in network transmission, where the first packet in a series of packets encounters an obstacle, causing all the following packets to be blocked and unable to continue transmission, even if the output port of the following packets is idle. This phenomenon severely affects the network’s transmission efficiency and performance.
Some architectures, such as Juniper’s Express and Broadcom’s Jericho series, implement virtual output queues (VOQs) through their proprietary cellified data plane.
In this method, the leaf switch splits the packets into fixed-size segments and evenly distributes them across all available output links. Compared to evenly distributing at the packet level, this can improve link utilization, because it is difficult to fully utilize all links with a mix of large and small packets. By segment forwarding, we also avoid another store/forward delay on the output link (egress Ethernet interface). In the segment data plane, the spine switches used to forward segments are replaced by custom switches, which can efficiently perform segment forwarding. These segment data plane switches are superior to Ethernet switches in terms of power consumption and latency because they do not need to support the overhead of L2 switching. Therefore, the segment-based data plane can not only improve link utilization but also reduce the overall delay of the VOQ data plane.
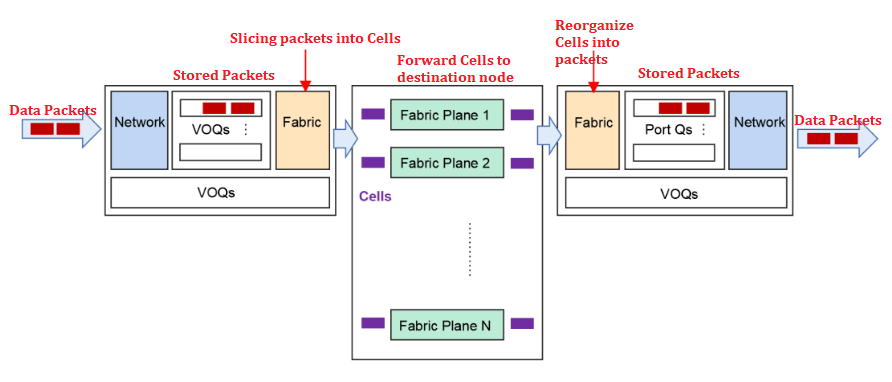
There are some limitations of the VOQ architecture:
Each leaf switch’s ingress port should have a reasonable buffer to store packets for all VOQs in the system during congestion. The buffer size is proportional to the number of GPUs and the number of priority queues per GPU. A larger GPU scale directly leads to a larger ingress buffer demand.
The egress queue buffer should have enough space to cover the round-trip delay through the data plane, to prevent these buffers from being exhausted during the request-approval handshake. In larger GPU clusters, using a 3-level data plane, this round-trip delay may increase due to the cable latency and the presence of additional switches. Suppose the egress queue buffer is not properly adjusted to accommodate the increased round-trip delay. In that case, the output link will not be able to achieve 100% utilization, thus reducing the system performance.
Although the VOQ system reduces the tail latency caused by head-of-line blocking through egress scheduling, the minimum latency of a packet is increased by an extra round-trip delay, because the ingress leaf switch has to perform a request-approval handshake before transmitting the packet.
Despite these limitations, the fully scheduled VOQ (fabric) has a significantly better performance in reducing tail latency than the typical Ethernet traffic. If the link utilization is increased to more than 90% by increasing the buffer, the extra overhead brought by the GPU scale expansion may be worth investing in.
In addition, vendor lock-in is a problem faced by VOQ (fabric). Because each vendor uses its proprietary protocol, mixing and matching switches in the same fabric is very difficult.
Summary: Application of mainstream GPU cluster networking technologies
NVLink switching system provides an effective solution for GPU intercommunication, but its supported GPU scale is relatively limited, mainly applied to GPU communication within the server and small-scale data transmission across server nodes. InfiniBand network, as a native RDMA network, performs excellently in congestion-free and low-latency environments. However, due to its relatively closed architecture and high cost, it is more suitable for small and medium-sized customers who demand wired connections.
ROCE lossless Ethernet, relying on the mature Ethernet ecosystem, the lowest networking cost, and the fastest bandwidth iteration speed, shows higher applicability in the scenario of medium and large-scale training GPU clusters.
As for the DDC fully scheduled network, it combines the cell switching and virtual output queue (VOQ) technologies, thus having a significant advantage in solving the Ethernet congestion problem. As an emerging technology, the industry is still in the research stage to evaluate its long-term potential and application prospects.
Related Products:
-
 NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$650.00
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$650.00
-
 NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$850.00
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$850.00
-
 NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$750.00
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$750.00
-
 NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1100.00
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1100.00
-
 NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1200.00
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1200.00
-
 NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$800.00
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$800.00
-
 Mellanox MMA1T00-HS Compatible 200G Infiniband HDR QSFP56 SR4 850nm 100m MPO-12 APC OM3/OM4 FEC PAM4 Optical Transceiver Module
$200.00
Mellanox MMA1T00-HS Compatible 200G Infiniband HDR QSFP56 SR4 850nm 100m MPO-12 APC OM3/OM4 FEC PAM4 Optical Transceiver Module
$200.00
-
 NVIDIA MFP7E10-N010 Compatible 10m (33ft) 8 Fibers Low Insertion Loss Female to Female MPO Trunk Cable Polarity B APC to APC LSZH Multimode OM3 50/125
$47.00
NVIDIA MFP7E10-N010 Compatible 10m (33ft) 8 Fibers Low Insertion Loss Female to Female MPO Trunk Cable Polarity B APC to APC LSZH Multimode OM3 50/125
$47.00
-
 NVIDIA MCP7Y00-N003-FLT Compatible 3m (10ft) 800G Twin-port OSFP to 2x400G Flat Top OSFP InfiniBand NDR Breakout DAC
$275.00
NVIDIA MCP7Y00-N003-FLT Compatible 3m (10ft) 800G Twin-port OSFP to 2x400G Flat Top OSFP InfiniBand NDR Breakout DAC
$275.00
-
 NVIDIA MCP7Y70-H002 Compatible 2m (7ft) 400G Twin-port 2x200G OSFP to 4x100G QSFP56 Passive Breakout Direct Attach Copper Cable
$155.00
NVIDIA MCP7Y70-H002 Compatible 2m (7ft) 400G Twin-port 2x200G OSFP to 4x100G QSFP56 Passive Breakout Direct Attach Copper Cable
$155.00
-
 NVIDIA MCA4J80-N003-FTF Compatible 3m (10ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Active Copper Cable, Flat top on one end and Finned top on other
$600.00
NVIDIA MCA4J80-N003-FTF Compatible 3m (10ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Active Copper Cable, Flat top on one end and Finned top on other
$600.00
-
 NVIDIA MCP7Y10-N002 Compatible 2m (7ft) 800G InfiniBand NDR Twin-port OSFP to 2x400G QSFP112 Breakout DAC
$200.00
NVIDIA MCP7Y10-N002 Compatible 2m (7ft) 800G InfiniBand NDR Twin-port OSFP to 2x400G QSFP112 Breakout DAC
$200.00