
Evolution and Challenges of AI Network Architecture
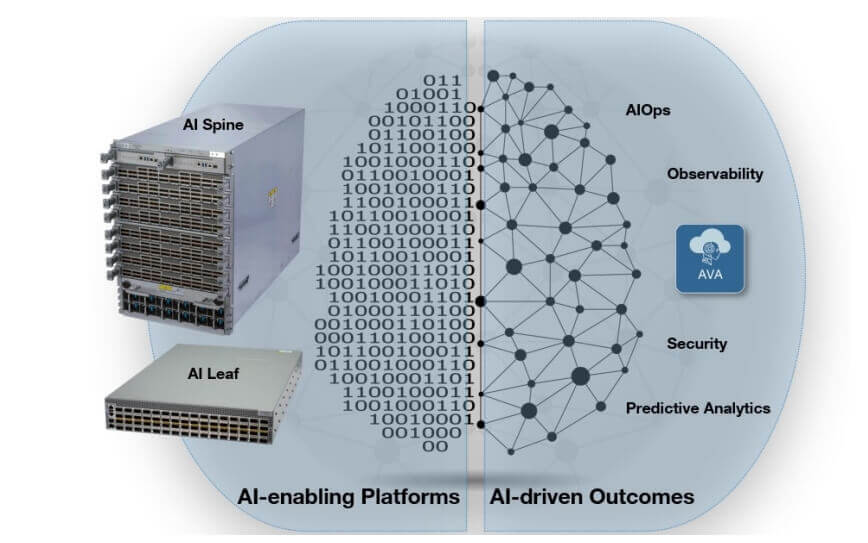
When discussing AI networks, two key dimensions can be analyzed. The first dimension is the foundational network architecture provided for AI. The second dimension is the application of AI technology in network operations and maintenance. We have integrated various features and solutions to enhance our internal systems, including AI operations (AIOps) and observability. Our switches are equipped with multiple sensors and security features such as Smart System Upgrade (SSU), which are core capabilities of AI networks. The SSU feature allows seamless security patch updates and system upgrades while maintaining critical network services operational, and it supports predictive analytics.
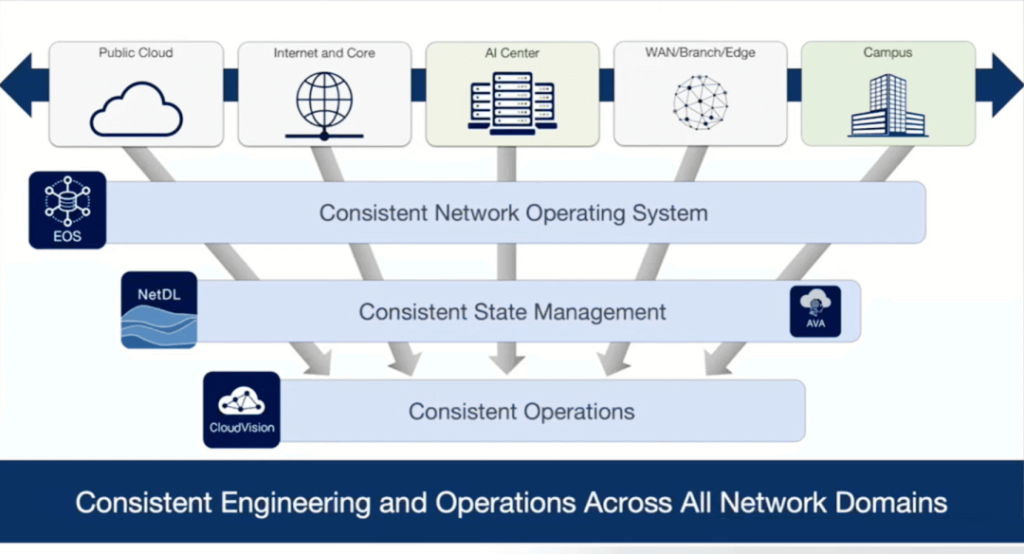
All Arista products, whether they are campus switches, WAN routers, or large 400G data center switches with 576 ports, operate on the same Extensible Operating System (EOS). Additionally, all products are managed through the unified software platform CloudVision, providing customers with end-to-end high-quality solutions that ensure consistent performance across various environments. This uniformity has been highly appreciated by customers.
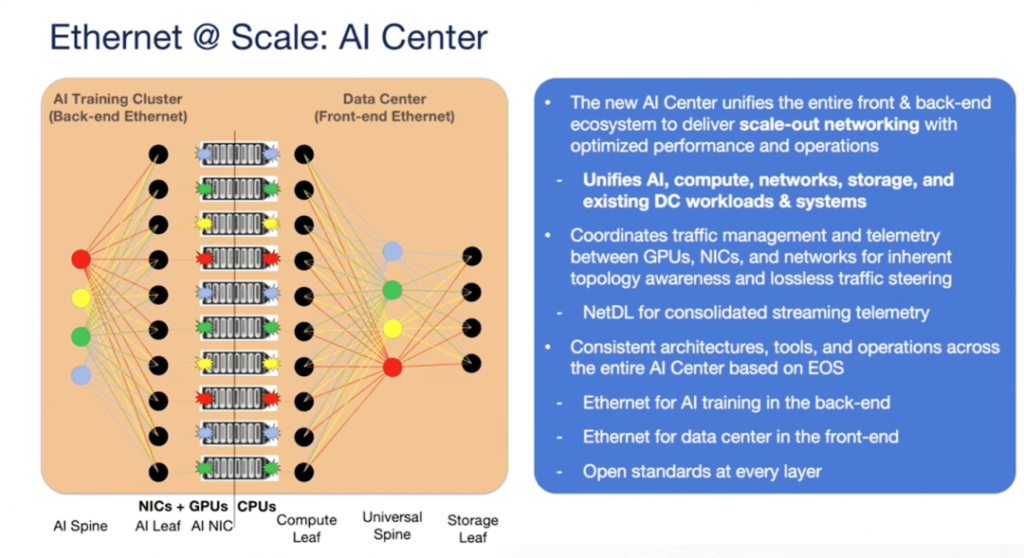
Traditionally, networks have operated in isolated silos. For instance, we have had the frontend network and the backend network in data centers, with the backend network primarily composed of HPC dominated by InfiniBand. With the advancement of AI technology, we are witnessing a shift from traditional data centers to AI-centric centers. In AI centers, the backend network connects GPUs, while the frontend network connects traditional data center networks, storage systems, and WANs, essentially covering all the network components needed to build a unified AI center.
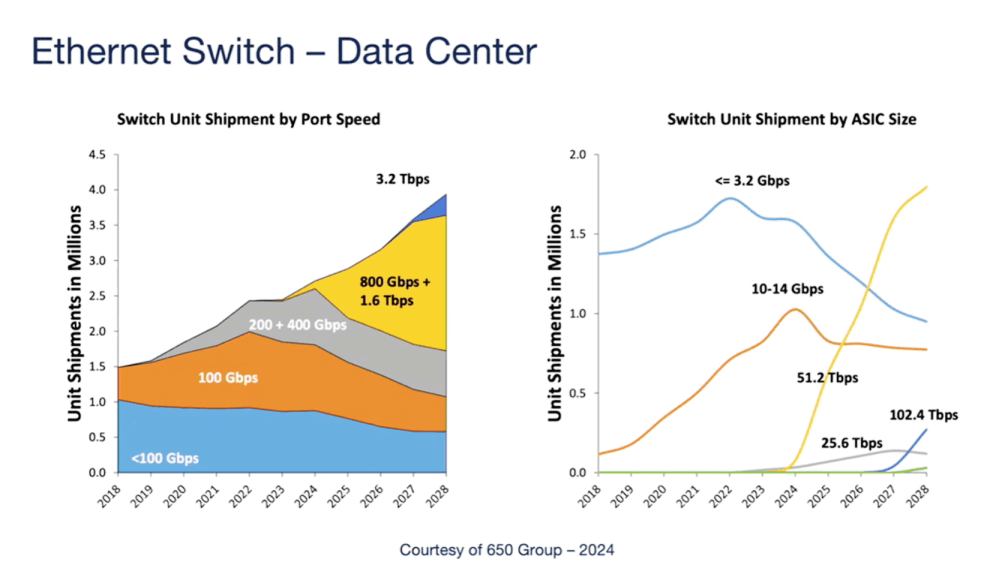
A slide from the 650 Group illustrates the historical evolution and future projection of data center port speeds. As depicted, high-speed ports are on a significant growth trajectory. The graph consolidates 800G and 1.6T speeds, which makes sense—800G relies on 8x100G SERDES, while 1.6T uses 16x100G or 8x200G SERDES. This growth is driven by approximately 30% to 40% AI network demand, reflecting the expansion of AI clusters, particularly training clusters. Looking ahead, inference operations will also drive this growth. Therefore, I/O capabilities must keep pace with GPU performance improvements. On the right side of the graph, the 51.2T ASIC shows the fastest adoption rate in history, marking a swift transition from 25.6T to 51.2T, with 100T chips potentially following at an even faster pace. Traditionally, speed upgrades took several years, but driven by AI demand, technological transitions are now occurring every 1.5 to 2 years to meet the bandwidth needs of GPUs and other accelerators.
From Traditional Data Centers to AI Centers: Arista’s Transformation Journey
Architectural Transformation: Traditional data center networks typically employ a tiered architecture, with the frontend network connecting user devices and external networks, and the backend network primarily utilizing InfiniBand technology to meet the demands of high-performance computing (HPC). However, with the rapid advancement of AI technology, data center design philosophies are shifting towards AI-centric models.
Component Reorganization: In AI data center architectures, the backend network connects GPUs, while the frontend network continues to link traditional data center networks, storage systems, and WANs. This results in a comprehensive network environment centered around AI workloads.

Regarding modular systems, Arista’s flagship AI backbone products feature the largest chassis designs, supporting up to 576 800G ports. This configuration allows smaller networks to connect to a large chassis, achieving over 1100 400G ports in scale—delivering nearly half a petabyte of bandwidth from a single chassis. For larger clusters, such as those with tens or hundreds of thousands of GPUs, the optimal design employs a dual-layer leaf-spine network architecture for the backend. Maintaining this dual-layer structure is crucial in AI scenarios, as load balancing is a primary concern. Ensuring proper traffic distribution helps prevent congestion, avoids individual GPUs from slowing down the entire workload, reduces interruptions, and lowers the power consumption of high-power networks.
Challenges of AI Workloads on Networks
Bandwidth Demand: The scale and computational requirements of AI models are growing exponentially, driving a sharp increase in network bandwidth demand.
Burst Traffic: Each data stream from AI training servers generates burst traffic at line rates, typically involving only 4-8 data streams, but this pattern can cause severe network congestion.
Latency Bottlenecks: Distributed computing makes the slowest traffic path a bottleneck, with any network latency potentially having a significant impact on overall performance.
Traffic Monitoring: Monitoring and troubleshooting AI traffic is highly challenging due to its high speed and bursty nature, making traditional monitoring tools insufficient.
Arista’s AI Network Solutions
Arista offers a comprehensive suite of AI network solutions, covering high-performance switch platforms, innovative network architectures, advanced software features, and efficient optical technologies to address the various challenges posed by AI workloads.
High-Performance Ethernet Switches:
Product Line: Arista provides a full range of 800G Ethernet switches, including fixed configurations and modular systems.
Etherlink AI Series:
Fixed Configuration Systems: Featuring the Broadcom 512T chip, equipped with 64 800G ports (equivalent to 128 400G ports), suitable for small to medium-sized AI workloads.
Modular Systems: Flagship AI backbone products supporting up to 576 800G ports per chassis, ideal for ultra-large-scale data centers.
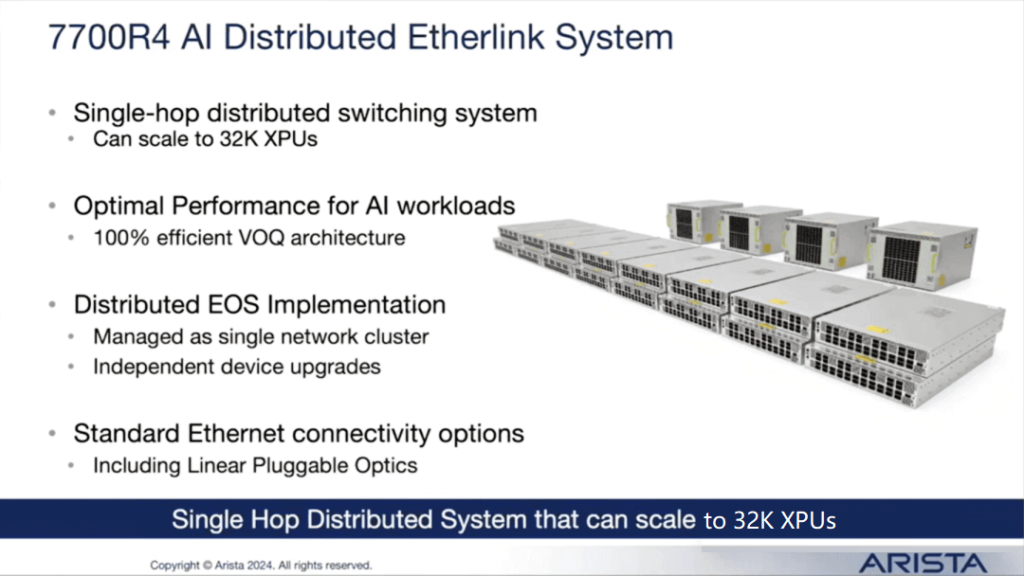
7700 Series: Distributed Etherlink systems employ a single-hop design, supporting expansion to 32,000 GPUs, catering to larger-scale computing needs.
Operating System: All switches run on Arista EOS (Extensible Operating System), managed uniformly through the CloudVision platform, enhancing management efficiency.

Arista’s 51.2 Tbps chassis, built on a 5-nanometer process and equipped with 64 800G ports, stands as the most energy-efficient choice currently available. In AI clusters, load balancing and energy consumption are the two primary challenges, with energy efficiency being a major concern for customers. The industry is moving towards linear pluggable optics (LPO) to enhance both optical module and network energy efficiency. Energy savings on the network side can be reallocated to more GPUs or xPUs.
This represents a smart hardware innovation. Based on feedback from major customers, removing all cables, dismantling the chassis, and performing repairs when a component fails inside the chassis is a cumbersome task. Typically, the components with the shortest mean time between failures (MTBF) are memory (RAM), solid-state drives (SSD), or central processing units (CPU). To address this issue, our system design allows for the entire CPU module to be removed after taking out the two fans on the right side.
Another advantage of this design is its ability to meet the security needs of some customers regarding proprietary data on SSDs. Since the CPU module can be independently removed, customers can securely handle this data during maintenance. This design brings significant convenience and marks a major hardware innovation.

The 7700R4, latest generation product, is equipped with 800G line cards. In its largest configuration, the chassis can support up to 1,152 400G ports, capable of delivering nearly half a petabyte of data throughput. This chassis employs a fully cell-based virtual output queuing (VOQ) architecture, ensuring perfect load balancing. This design is particularly suitable for customers building small clusters, where a single chassis suffices; it also serves as an ideal AI backbone network device for customers constructing large clusters.
Innovative Load Balancing Technologies
- Challenge: Traditional equal-cost multi-path (ECMP) algorithms are inefficient in handling AI traffic, prompting Arista to develop various targeted load balancing solutions:
- Congestion-aware Layout: Distributes traffic intelligently to different uplinks based on real-time network load, reducing congestion risk.
- RDMA-based Load Balancing: Uses software algorithms to achieve precise load balancing based on RDMA traffic characteristics.
- Distributed Etherlink Switch (DES): Resolves load balancing issues through hardware-level packet forwarding, employing a single-hop interconnection scheme to reduce latency.
- Architecture Design: Features a dual-layer network architecture requiring only one hop in practice, with the main chip located in the leaf switch and the spine acting as a high-speed switching device.
- Packet Spray Transmission Protocol: A future RDMA protocol alternative, designed to handle out-of-order packets and enhance data transmission stability effectively.
Difference Between Virtual Output Queuing (VOQ) and RDMA-supported Load Balancing: VOQ refers to the architecture within the chassis, using virtual output queues to allocate packets between input and output ports, which is a fully scheduled process. In contrast, RDMA-supported load balancing involves dynamic load balancing with a specific focus on RDMA traffic characteristics, allowing for load balancing or hashing based on that traffic.
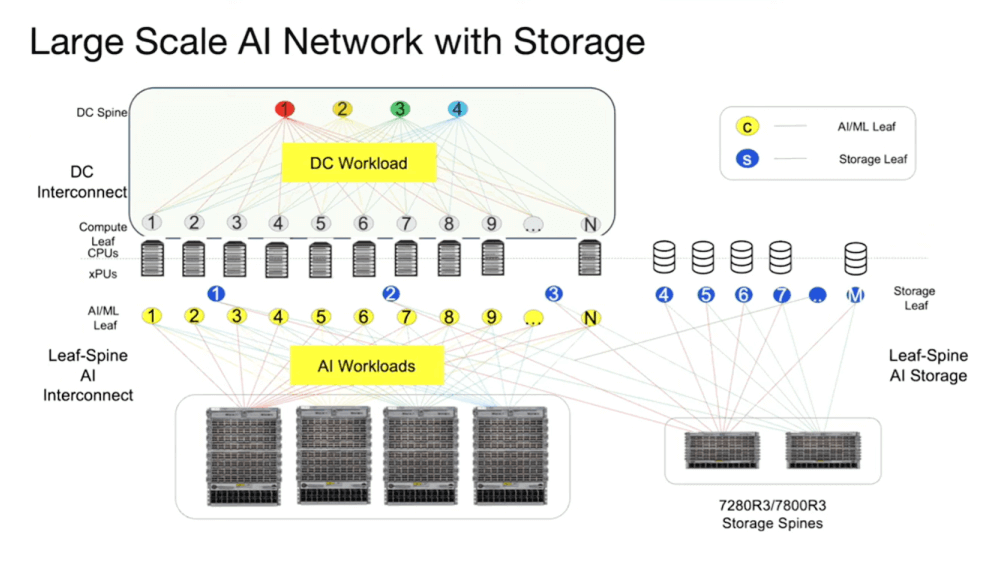
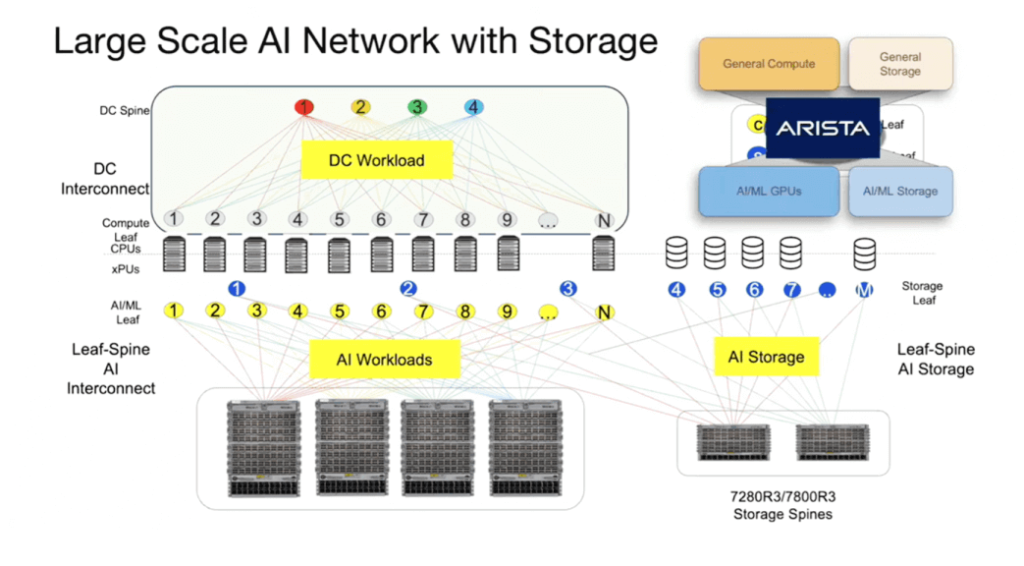
The diagram provides a comprehensive overview of the network architecture, encompassing both traditional front-end networks and dedicated back-end AI networks. Depending on the cluster size, configurations can include smaller fixed chassis, racks, or a hybrid of both. For extremely large-scale clusters, a three-tier architecture may even be considered.
Both the AI back-end and the front-end require dedicated storage systems. Additionally, WAN connections are necessary. This overview presents the overall architecture of a large AI network.
Enhanced Visualization Capabilities
- Network Monitoring Tools: Traditional network monitoring methods struggle to capture microsecond-level fluctuations in AI traffic. Arista offers various innovative monitoring tools:
- AI Analyzer: Captures traffic statistics at 100-microsecond intervals, providing granular insights into network behavior, enabling quick identification of congestion and load balancing issues.
- AI Agent: Extends EOS to NIC servers, achieving centralized management and monitoring of ToR and NIC connections.
- Automated Discovery: The AI Agent can automatically discover and synchronize configurations between switches and NICs, supporting various NIC plugin extensions.
- Data Collection: Gathers NIC counter data, offering a more comprehensive network view and enhanced analysis capabilities.
Comprehensive Congestion Control Mechanisms
- Congestion Management Techniques: Arista employs multiple techniques to effectively manage network congestion, including:
- Priority Flow Control (PFC): Prevents packet loss caused by last-hop traffic aggregation through priority flow control.
- Explicit Congestion Notification (ECN): Reduces data transmission speed during PCI bus congestion, avoiding network crashes.
- In-network Telemetry: Provides granular information on network congestion queue depth, facilitating real-time monitoring and optimization.
High-Reliability Assurance:
- High Availability Technologies: Arista offers various features to ensure high availability of AI networks:
- Non-Disruptive Upgrades (SSU): Supports EOS version upgrades with zero downtime.
- Data Plane Optimization: Optimizes chip performance to ensure stable network operation.
- Comprehensive L1 Link Monitoring: Monitors the status of 400,000 optical modules in real-time, promptly identifying and addressing faults to ensure network reliability.
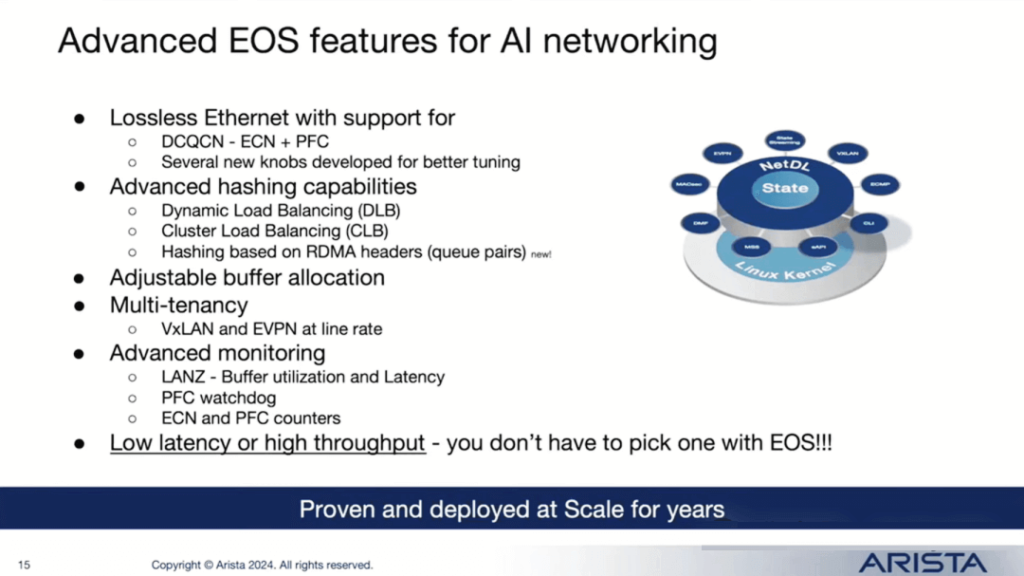
Arista’s Crown Jewel: EOS (Extensible Operating System) and its Features:
In an AI environment, load balancing is crucial. We provide various features, including Dynamic Load Balancing (DLB), Congestion Load Balancing (CLB), RDMA header-based hashing, Data Center Quantized Congestion Notification (DCQCN), Explicit Congestion Notification (ECN), and Priority Flow Control (PFC) congestion control methods. Additionally, we offer enhanced features such as PFC watchdog and multi-tenant options.
If you are building GPU or xPU clusters and plan to offer them as a service, segmentation and multi-tenancy capabilities will be required. This is where Virtual Extensible LAN (VXLAN) and Ethernet Virtual Private Network (EVPN) come into play. Once deployed, monitoring and visualization are essential to access telemetry data, identify congestion points and faulty links, ensuring the network’s reliability and robustness.
Optical Technology and Future Trends
Linear Pluggable Optics (LPO):
- Design Features: The 800G LPO uses a linear design, significantly reducing cost and power consumption.
- Future Outlook: The 1.6T LPO can further reduce power consumption and is expected to achieve large-scale production by 2025, becoming a key technology for reducing power consumption in AI clusters.

In networks, it is equally important. When examining 400G optical technology, a mismatch between electrical signals and optical signals is observed. Electrical signals are 8X 50G, while optical signals are 4X 100G, necessitating a gearbox to convert the 50G electrical signal to a 100G optical signal. Besides signal conversion, the gearbox also has signal amplification capabilities. What is the role of the gearbox? It provides power gain for the optical signal but also adds cost. At 800G speeds, the situation is linear, which is a favorable characteristic. Electrical signals are 8X 100G PAM-4, and optical signals are also 8X 100G PAM-4, resulting in perfect matching of optical signal speeds, leading to the lowest cost and simpler optical design.
Rack-Level Integration:
- Integration Solution: Integrating more GPUs and network technology into the same rack, using copper cable optical interconnects to improve overall performance.
- Case Analysis: Nvidia’s NVL72 rack integrates 72 GPUs with a power consumption of up to 120 kilowatts. While rack-level integration offers cost and power advantages, it also faces challenges in thermal management.
In AI clusters, if you are curious about the most commonly used optical connection schemes, most AI clusters adopt an end-of-rack design. Here, 800G VSR4 is used, providing a transmission distance of 50 meters, sufficient to connect any GPU from the end of the rack. Between the leaf and spine, XDR4 or FR4 can be used; one supports transmission up to 500 meters, the other up to 2 kilometers.

Ultra Ethernet Consortium (UEC):
- Organizational Background: Arista is one of the founding members of UEC, actively promoting the development of Ethernet technology.
- Technical Goals: UEC aims to address network challenges posed by AI and HPC workloads, including transmission protocols, congestion control, and packet spray technology.
- Specification Release: UEC is expected to release multi-layer network specifications later in 2024, driving industry standardization.
Scaling AI Networks:
- Architectural Support: Arista offers various network architectures to support AI clusters of different sizes, including:
- Dual-Layer Leaf-Spine Architecture: Suitable for small to medium-sized clusters, offering efficient bandwidth utilization.
- Three-Tier Network Architecture: Suitable for ultra-large-scale clusters, enhancing network scalability.
- Multi-Plane Network Architecture: Expands network scale through multiple independent planes, supporting higher concurrency.
- Distributed Scheduling Architecture: Achieves single-hop logical connections, supporting expansion needs for up to 32,000 GPUs.
- Market Demand: Building ultra-large-scale AI clusters is costly, but the market’s growing demand for high-performance computing and big data processing continues to drive innovation and development in related technologies.
Related Products:
-
 Arista Networks QDD-400G-SR8 Compatible 400G QSFP-DD SR8 PAM4 850nm 100m MTP/MPO OM3 FEC Optical Transceiver Module
$180.00
Arista Networks QDD-400G-SR8 Compatible 400G QSFP-DD SR8 PAM4 850nm 100m MTP/MPO OM3 FEC Optical Transceiver Module
$180.00
-
 Arista Networks QDD-400G-DR4 Compatible 400G QSFP-DD DR4 PAM4 1310nm 500m MTP/MPO SMF FEC Optical Transceiver Module
$450.00
Arista Networks QDD-400G-DR4 Compatible 400G QSFP-DD DR4 PAM4 1310nm 500m MTP/MPO SMF FEC Optical Transceiver Module
$450.00
-
 Arista QDD-400G-VSR4 Compatible QSFP-DD 400G SR4 PAM4 850nm 100m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$600.00
Arista QDD-400G-VSR4 Compatible QSFP-DD 400G SR4 PAM4 850nm 100m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$600.00
-
 Arista Networks QDD-400G-FR4 Compatible 400G QSFP-DD FR4 PAM4 CWDM4 2km LC SMF FEC Optical Transceiver Module
$600.00
Arista Networks QDD-400G-FR4 Compatible 400G QSFP-DD FR4 PAM4 CWDM4 2km LC SMF FEC Optical Transceiver Module
$600.00
-
 Arista Networks QDD-400G-XDR4 Compatible 400G QSFP-DD XDR4 PAM4 1310nm 2km MTP/MPO-12 SMF FEC Optical Transceiver Module
$650.00
Arista Networks QDD-400G-XDR4 Compatible 400G QSFP-DD XDR4 PAM4 1310nm 2km MTP/MPO-12 SMF FEC Optical Transceiver Module
$650.00
-
 Arista Networks QDD-400G-LR4 Compatible 400G QSFP-DD LR4 PAM4 CWDM4 10km LC SMF FEC Optical Transceiver Module
$650.00
Arista Networks QDD-400G-LR4 Compatible 400G QSFP-DD LR4 PAM4 CWDM4 10km LC SMF FEC Optical Transceiver Module
$650.00
-
 Arista QDD-400G-SRBD Compatible 400G QSFP-DD SR4 BiDi PAM4 850nm/910nm 100m/150m OM4/OM5 MMF MPO-12 FEC Optical Transceiver Module
$1000.00
Arista QDD-400G-SRBD Compatible 400G QSFP-DD SR4 BiDi PAM4 850nm/910nm 100m/150m OM4/OM5 MMF MPO-12 FEC Optical Transceiver Module
$1000.00
-
 Arista Networks QDD-400G-PLR4 Compatible 400G QSFP-DD PLR4 PAM4 1310nm 10km MTP/MPO-12 SMF FEC Optical Transceiver Module
$1000.00
Arista Networks QDD-400G-PLR4 Compatible 400G QSFP-DD PLR4 PAM4 1310nm 10km MTP/MPO-12 SMF FEC Optical Transceiver Module
$1000.00
-
 Arista Q112-400G-DR4 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$800.00
Arista Q112-400G-DR4 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$800.00
-
 Arista Q112-400G-SR4 Compatible 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC Optical Transceiver Module
$650.00
Arista Q112-400G-SR4 Compatible 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC Optical Transceiver Module
$650.00
-
 Arista OSFP-400G-LR4 Compatible 400G LR4 OSFP PAM4 CWDM4 LC 10km SMF Optical Transceiver Module
$1199.00
Arista OSFP-400G-LR4 Compatible 400G LR4 OSFP PAM4 CWDM4 LC 10km SMF Optical Transceiver Module
$1199.00
-
 Arista OSFP-400G-XDR4 Compatible 400G OSFP DR4+ 1310nm MPO-12 2km SMF Optical Transceiver Module
$879.00
Arista OSFP-400G-XDR4 Compatible 400G OSFP DR4+ 1310nm MPO-12 2km SMF Optical Transceiver Module
$879.00
-
 Arista Networks OSFP-400G-2FR4 Compatible 2x 200G OSFP FR4 PAM4 2x CWDM4 CS 2km SMF FEC Optical Transceiver Module
$3000.00
Arista Networks OSFP-400G-2FR4 Compatible 2x 200G OSFP FR4 PAM4 2x CWDM4 CS 2km SMF FEC Optical Transceiver Module
$3000.00
-
 Arista Networks OSFP-400G-FR4 Compatible 400G OSFP FR4 PAM4 CWDM4 2km LC SMF FEC Optical Transceiver Module
$900.00
Arista Networks OSFP-400G-FR4 Compatible 400G OSFP FR4 PAM4 CWDM4 2km LC SMF FEC Optical Transceiver Module
$900.00
-
 Arista Networks OSFP-400G-DR4 Compatible 400G OSFP DR4 PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$900.00
Arista Networks OSFP-400G-DR4 Compatible 400G OSFP DR4 PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$900.00
-
 Arista Networks OSFP-400G-SR8 Compatible 400G OSFP SR8 PAM4 850nm MTP/MPO-16 100m OM3 MMF FEC Optical Transceiver Module
$480.00
Arista Networks OSFP-400G-SR8 Compatible 400G OSFP SR8 PAM4 850nm MTP/MPO-16 100m OM3 MMF FEC Optical Transceiver Module
$480.00
-
 Arista OSFP-800G-2SR4 Compatible OSFP 2x400G SR4 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$750.00
Arista OSFP-800G-2SR4 Compatible OSFP 2x400G SR4 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$750.00
-
 Arista OSFP-800G-2PLR4 Compatible OSFP 8x100G LR PAM4 1310nm Dual MPO-12 10km SMF Optical Transceiver Module
$2200.00
Arista OSFP-800G-2PLR4 Compatible OSFP 8x100G LR PAM4 1310nm Dual MPO-12 10km SMF Optical Transceiver Module
$2200.00
-
 Arista OSFP-800G-2XDR4 Compatible OSFP 8x100G FR PAM4 1310nm Dual MPO-12 2km SMF Optical Transceiver Module
$1300.00
Arista OSFP-800G-2XDR4 Compatible OSFP 8x100G FR PAM4 1310nm Dual MPO-12 2km SMF Optical Transceiver Module
$1300.00
-
 Arista OSFP-800G-2LR4 Compatible OSFP 2x400G LR4 PAM4 CWDM4 Dual duplex LC 10km SMF Optical Transceiver Module
$3700.00
Arista OSFP-800G-2LR4 Compatible OSFP 2x400G LR4 PAM4 CWDM4 Dual duplex LC 10km SMF Optical Transceiver Module
$3700.00