
After ChatGPT exploded in the technology field, people have been discussing what the “next step” of AI will be, and many scholars have mentioned multimodality. Recently, OpenAI released the multimodal pre-trained big model GPT-4. GPT-4 achieves leaps and bounds in the following aspects: powerful graph recognition, text input limit raised to 25,000 words, significant improvement in answer accuracy, ability to generate lyrics, creative text, and realize style changes.
Such efficient iterations are inseparable from AI large-scale model training, which requires large computational resources and high-speed data transmission networks. Among them, the end-to-end IB (InfiniBand) network is a high-performance computing network that is particularly suitable for high-performance computing and AI model training. In this paper, we will introduce what is AIGC model training, why end-to-end IB network is needed and how to use ChatGPT model for AIGC training.
What is AIGC?
AIGC, AI Generated Content, refers to artificial intelligence automatically generated content, which can be used for painting, writing, video and many other types of content creation. 2022 AIGC is developing at a high speed, which the deep learning model continues to improve, the promotion of open source model, and the possibility of commercialization of large model exploration, which becomes the development of AIGC ” acceleration”. Take ChatGPT, a chatbot, for example, which can write essays, create novels and code, and has been online for only 2 months, with 100 million monthly users. Because of its unexpected ” intelligent “, AIGC is considered ” the next disruptor of the technology industry “, ” a major revolution in content productivity “.
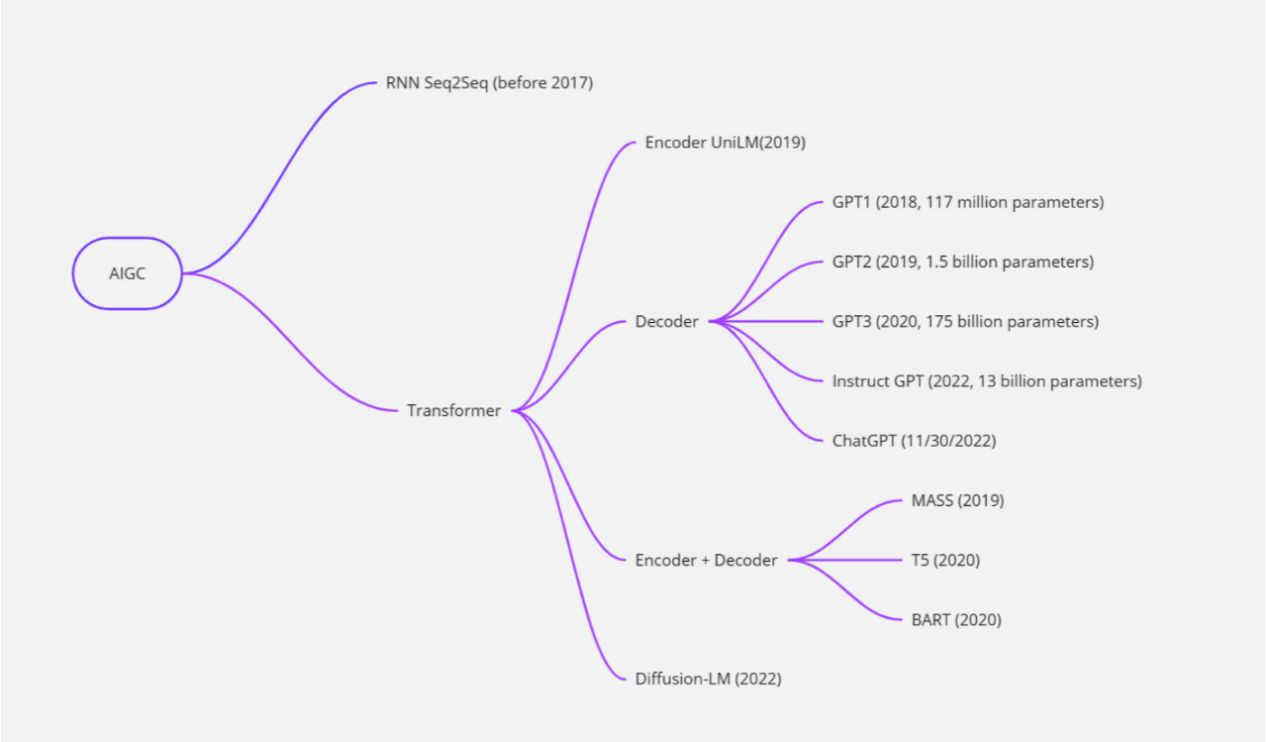
Large Language Model (LLM) and ChatGPT
Large Language Model is an artificial intelligence technology that can acquire and understand natural language. It is usually based on deep learning algorithms that learn large amounts of text data to acquire linguistic knowledge and can generate natural language text, such as conversations, articles, etc. ChatGPT is a large language model-based chatbot that uses the GPT (Generative Pre-trained Transformer) developed by OpenAI to generate linguistically expressive natural language text and interact with users by pre-training and fine-tuning large amounts of text data. Thus, it can be said that ChatGPT is a chatbot based on large language modeling technology. It leverages the powerful language understanding and generation capabilities of large language models, thus enabling the generation and understanding of natural language text in conversations. With the development of deep learning techniques, the capabilities and scale of large language models continue to increase. While the original language models (e.g. N-gram models) could only consider limited contextual information, modern large language models (e.g. BERT, GPT-3, etc.) are able to consider much longer contextual information and have stronger generalization and generation capabilities. Large language models are usually trained using deep neural networks, such as recurrent neural networks (RNN), long and short-term memory (LSTM), gated recurrent units (GRU), and transformer. In training, the models are trained in an unsupervised or semi-supervised manner using a large-scale text dataset. For example, BERT models are trained by tasks such as prediction masks, next sentences, etc., while GPT-3 uses a large-scale self-supervised learning approach. Large-scale language models have a wide range of applications in the field of natural language processing, such as machine translation, natural language generation, question and answer systems, text classification, sentiment analysis, etc.
What are the Current Bottlenecks in Training LLM?
When training large language models, high-speed, reliable networks are needed to transfer large amounts of data. For example, OpenAI released the first version of the GPT model (GPT-1), which had a model size of 117 million parameters. After that, OpenAI successively released larger models such as GPT-2 and GPT-3 with 150 million and 1.75 trillion parameters, respectively. Such large parameters are completely impossible to train on a single machine and require a high reliance on GPU computing clusters. The current bottleneck lies in how to solve the problem of efficient communication among the nodes in the training cluster.
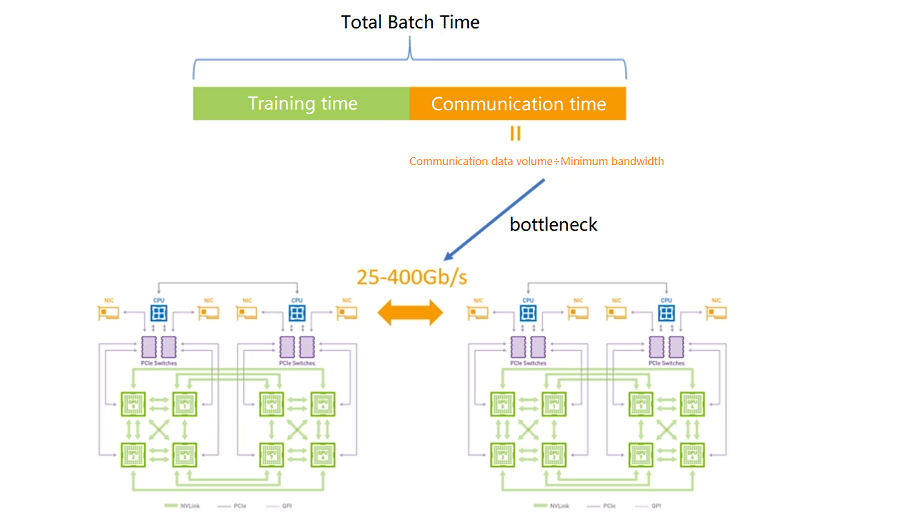
One of the more commonly used GPU communication algorithms is Ring-Allreduce, whose basic idea is to have the GPUs form a ring and let the data flow within the ring. The GPUs in the ring are arranged in a logic where each GPU has one left and one right neighbor, and it will only send data to its right neighbor and receive data from its left neighbor. The algorithm proceeds in two steps: first scatter-reduce and then allgather. In the scatter-reduce step, the GPUs will exchange data so that each GPU can get a block of the final result. In the allgather step, the GPUs will swap these blocks so that all GPUs get the complete final result.
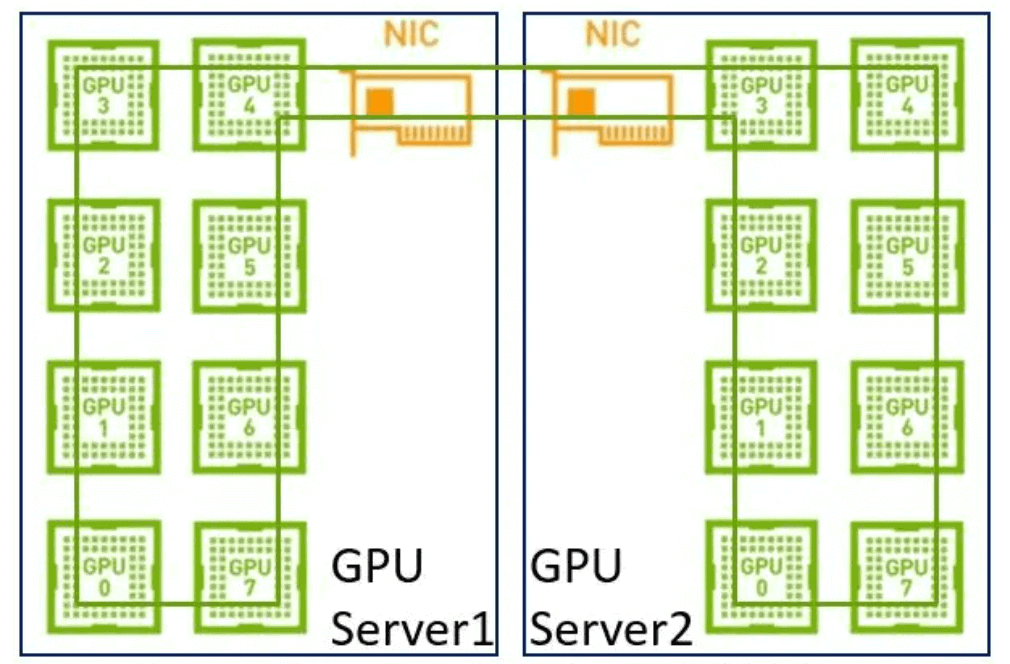
In the early days, there was no NVLink inside the single machine, no RDMA on the network, and the bandwidth was relatively low. There was not much difference in bandwidth between single-machine distribution and multi-machine distribution, so it was enough to build a big ring. But now that we have NVLink inside the single machine, it is not appropriate to use the same method. Because the bandwidth of the network is much lower than that of NVLink, if we use a large ring again, it will lead to the high bandwidth of NVLink being seriously pulled down to the level of the network. Second, it is now a multi-NIC environment. It is also impossible to take full advantage of multiple NICs if only one ring is used. Therefore, a two-stage ring is recommended in such a scenario. First, data synchronization is done between GPUs within a single machine using NVLink’s high bandwidth advantage. Then the GPUs between multiple machines use multiple NICs to establish multiple rings to synchronize data from different segments. Finally, the GPUs inside the single machine are synchronized once more, finally completing the data synchronization of all GPUs, and here we have to mention NCCL.
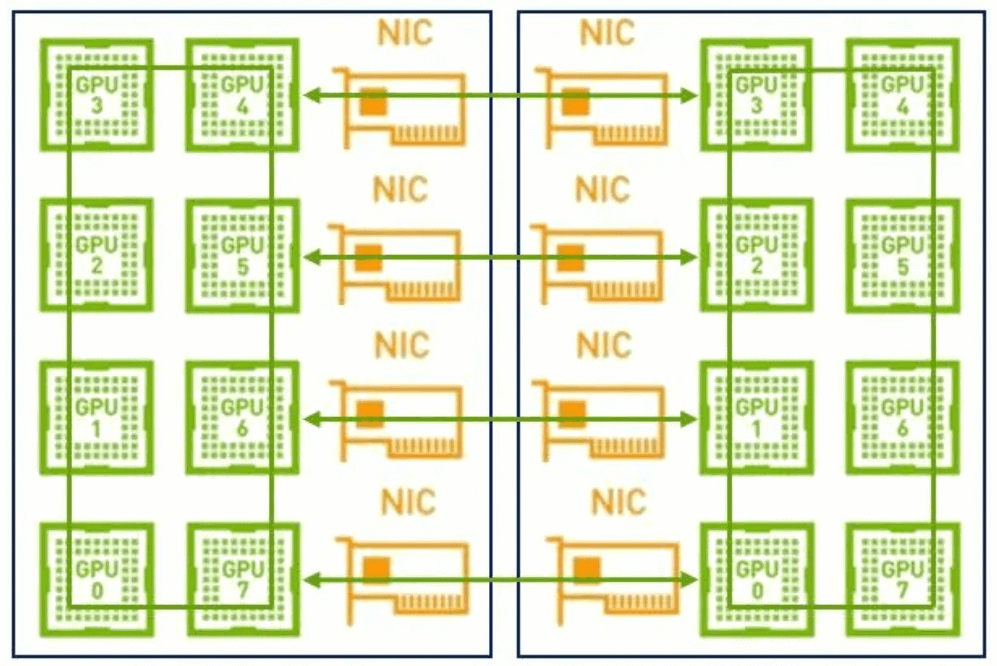
The NVIDIA Collective Communication Library (NCCL) implements multi-GPU and multi-node communication primitives optimized for NVIDIA GPUs and networks.
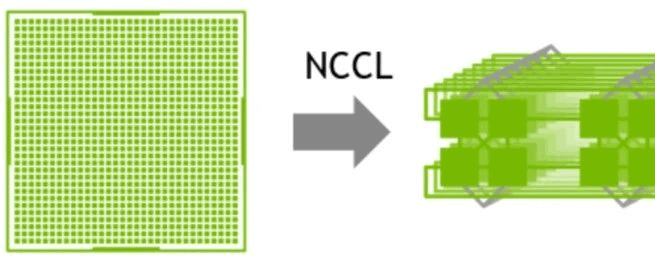
1 GPU->multi-GPU multi node
NCCL provides routines for all-collection, all-decrease, broadcast, reduce, reduce scatter, and point-to-point send and receive. These routines are optimized for high bandwidth and low latency through in-node and NVIDIA Mellanox networks over PCIe and NVLink high-speed interconnects.
Why Use an End-to-end InfiniBand Network?
Ethernet is a widely used network protocol, but its transmission rate and latency do not meet the demands of large model training. In contrast, the end-to-end InfiniBand network is a high-performance computing network capable of delivering transmission rates up to 400 Gbps and microsecond latency, well above the performance of Ethernet. This makes InfiniBand networks the network technology of choice for large-scale model training. In addition, the end-to-end InfiniBand network supports data redundancy and error correction mechanisms that ensure reliable data transmission. This is especially important in large scale model training, because when dealing with so much data, data transmission errors or data loss can cause the training process to interrupt or even fail. With the dramatic increase in the number of network nodes and rising computational power, it is more important than ever for high-performance computing to eliminate performance bottlenecks and improve system management. InfiniBand is considered a highly promising I/O technology that can enhance the performance bottleneck of current I/O architectures, as shown in the figure. infiniBand is a pervasive, low-latency, high-bandwidth interconnect communication protocol with low processing overhead, ideal for carrying multiple traffic types (clustering, communication, storage, and management) on a single connection. In 1999, IBTA (InfiniBand Trade Association) developed the InfiniBand-related standards, which define the input/output architecture for interconnected servers, communication infrastructure devices, storage and embedded systems in the InfiniBand™ specification. InfiniBand is a mature, proven technology that is widely used in high-performance computing clusters.
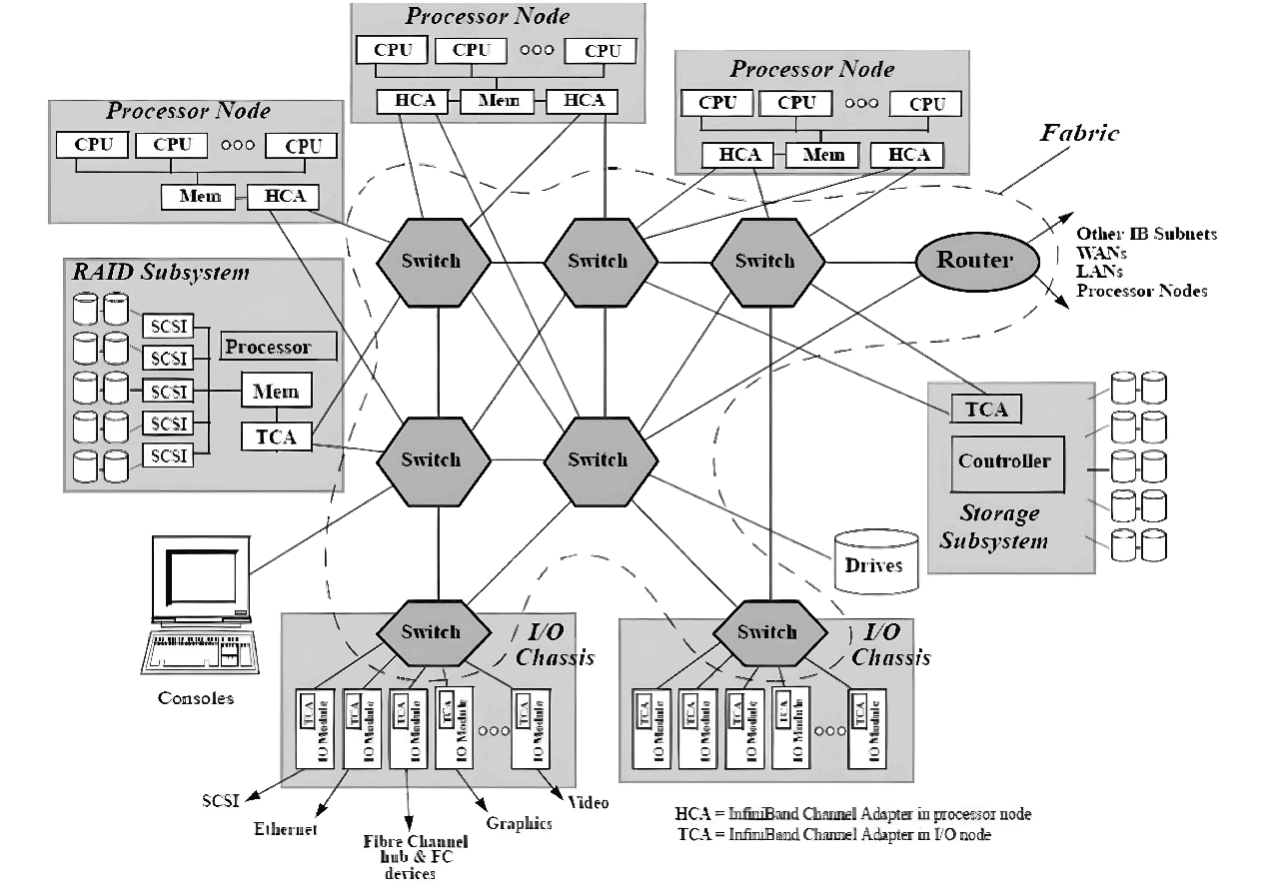
Architecture diagram of InfiniBand interconnection
According to InfiniBand interconnection protocol, each node must have a host channel adapter (HCA) to set and maintain links with host devices. Switches contain multiple ports and forward data packets from one port to another, completing data transmission within subnets.
The Subnet Manager (SM) is used to configure its local subnet and ensure its continuous operation, with the help of the Subnet Manager Packet (SMP) and the Subnet Manager Agent (SMA) on each InfiniBand device. The Subnet Manager discovers and initializes the network, assigns unique identifiers to all devices, determines the MTU (Minimum Transmission Unit), and generates switch routing tables based on selected routing algorithms.The SM also performs periodic optical scans of the subnet to detect any topology changes and configures the network accordingly. InfiniBand networks offer higher bandwidth, lower latency, and greater scalability than other network communication protocols. In addition, because InfiniBand provides credit-based flow control (where the sender node sends no more data than the number of credits posted in the receive buffer at the other end of the link), the transport layer does not require a packet loss mechanism like the TCP window algorithm to determine the optimal number of packets being transmitted. This allows InfiniBand networks to deliver extremely high data transfer rates to applications with very low latency and very low CPU usage. InfiniBand transfers data from one end of the channel to the other using RDMA technology (Remote Direct Memory Access), a protocol that transfers data directly between applications over the network without the involvement of the operating system, while consuming very low CPU resources on both sides (zero-copy transfer). The application at one end simply reads the message directly from memory and the message has been successfully transferred. The reduced CPU overhead increases the network’s ability to transfer data quickly and allows applications to receive data faster.
FiberMall End-to-End InfiniBand Networking Solutions
FiberMall offers an end-to-end solution based on NVIDIA Quantum-2 switches, ConnectX InfiniBand smart cards and flexible 400Gb/s InfiniBand, based on our understanding of high speed networking trends and extensive experience in HPC and AI project implementations, to reduce costs and complexity while delivering superior performance in High performance computing (HPC), AI and hyperscale cloud infrastructure while reducing cost and complexity.
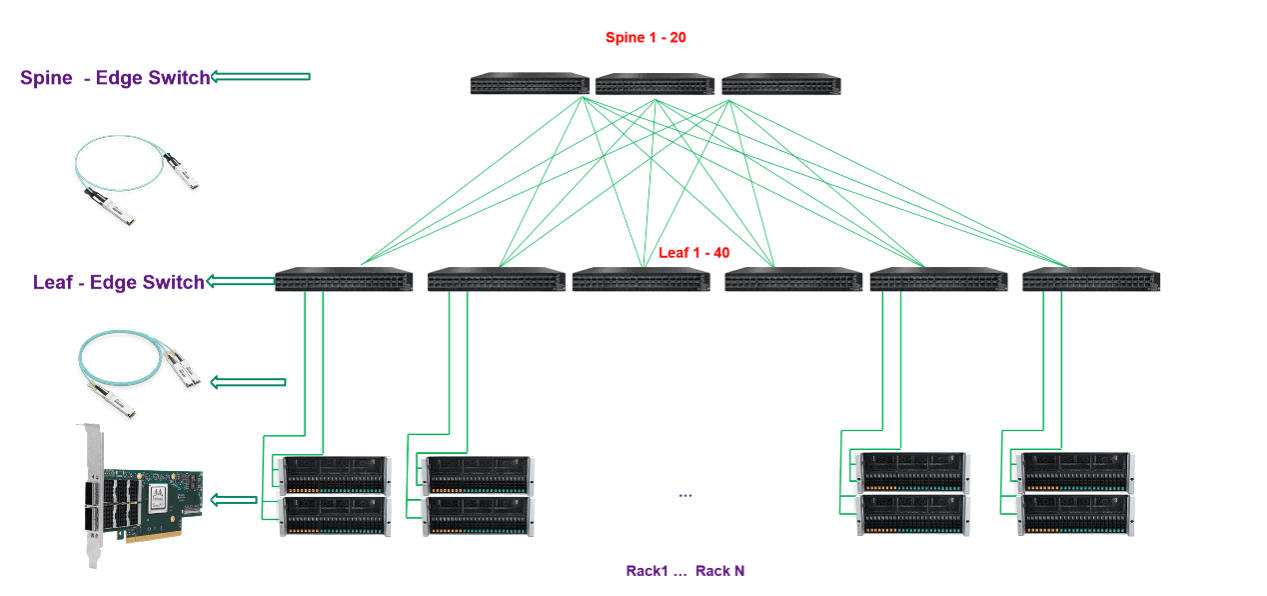
FiberMall Data Center InfiniBand Network Solutions
Related Products:
-
 Mellanox QMMA1U00-WS Compatible 400G QSFP-DD SR8 PAM4 850nm 100m MTP/MPO OM3 FEC Optical Transceiver Module
$180.00
Mellanox QMMA1U00-WS Compatible 400G QSFP-DD SR8 PAM4 850nm 100m MTP/MPO OM3 FEC Optical Transceiver Module
$180.00
-
 Mellanox MMS1V00-WM Compatible 400G QSFP-DD DR4 PAM4 1310nm 500m MTP/MPO SMF FEC Optical Transceiver Module
$450.00
Mellanox MMS1V00-WM Compatible 400G QSFP-DD DR4 PAM4 1310nm 500m MTP/MPO SMF FEC Optical Transceiver Module
$450.00
-
 Mellanox MMA1T00-HS Compatible 200G Infiniband HDR QSFP56 SR4 850nm 100m MPO-12 APC OM3/OM4 FEC PAM4 Optical Transceiver Module
$200.00
Mellanox MMA1T00-HS Compatible 200G Infiniband HDR QSFP56 SR4 850nm 100m MPO-12 APC OM3/OM4 FEC PAM4 Optical Transceiver Module
$200.00
-
 Mellanox MMS1W50-HM Compatible 200G InfiniBand HDR QSFP56 FR4 PAM4 CWDM4 2km LC SMF FEC Optical Transceiver Module
$650.00
Mellanox MMS1W50-HM Compatible 200G InfiniBand HDR QSFP56 FR4 PAM4 CWDM4 2km LC SMF FEC Optical Transceiver Module
$650.00
-
 Mellanox MFS1S00-H005E Compatible 5m (16ft) 200G HDR QSFP56 to QSFP56 Active Optical Cable
$405.00
Mellanox MFS1S00-H005E Compatible 5m (16ft) 200G HDR QSFP56 to QSFP56 Active Optical Cable
$405.00
-
 Mellanox MFS1S00-H010E Compatible 10m (33ft) 200G HDR QSFP56 to QSFP56 Active Optical Cable
$465.00
Mellanox MFS1S00-H010E Compatible 10m (33ft) 200G HDR QSFP56 to QSFP56 Active Optical Cable
$465.00
-
 Mellanox MFS1S50-V020E Compatible 20m (66ft) 200G QSFP56 to 2x100G QSFP56 PAM4 Breakout Active Optical Cable
$640.00
Mellanox MFS1S50-V020E Compatible 20m (66ft) 200G QSFP56 to 2x100G QSFP56 PAM4 Breakout Active Optical Cable
$640.00
-
 Mellanox MFS1S50-V030E Compatible 30m (98ft) 200G QSFP56 to 2x100G QSFP56 PAM4 Breakout Active Optical Cable
$660.00
Mellanox MFS1S50-V030E Compatible 30m (98ft) 200G QSFP56 to 2x100G QSFP56 PAM4 Breakout Active Optical Cable
$660.00
-
 HPE (Mellanox) P06149-B22 Compatible 1m (3ft) Infiniband HDR 200G QSFP56 to QSFP56 PAM4 Passive Direct Attach Copper Twinax Cable
$70.00
HPE (Mellanox) P06149-B22 Compatible 1m (3ft) Infiniband HDR 200G QSFP56 to QSFP56 PAM4 Passive Direct Attach Copper Twinax Cable
$70.00
-
 HPE (Mellanox) P06149-B21 Compatible 0.5m (1.6ft) Infiniband HDR 200G QSFP56 to QSFP56 PAM4 Passive Direct Attach Copper Twinax Cable
$65.00
HPE (Mellanox) P06149-B21 Compatible 0.5m (1.6ft) Infiniband HDR 200G QSFP56 to QSFP56 PAM4 Passive Direct Attach Copper Twinax Cable
$65.00
-
 Mellanox MCP1650-H002E26 Compatible 2m (7ft) Infiniband HDR 200G QSFP56 to QSFP56 PAM4 Passive Direct Attach Copper Twinax Cable
$70.00
Mellanox MCP1650-H002E26 Compatible 2m (7ft) Infiniband HDR 200G QSFP56 to QSFP56 PAM4 Passive Direct Attach Copper Twinax Cable
$70.00
-
 Mellanox MCP7H50-H002R26 Compatible 2m (7ft) Infiniband HDR 200G QSFP56 to 2x100G QSFP56 PAM4 Passive Breakout Direct Attach Copper Cable
$68.00
Mellanox MCP7H50-H002R26 Compatible 2m (7ft) Infiniband HDR 200G QSFP56 to 2x100G QSFP56 PAM4 Passive Breakout Direct Attach Copper Cable
$68.00
-
 Mellanox MCP7H50-H01AR30 Compatible 1.5m (5ft) Infiniband HDR 200G QSFP56 to 2x100G QSFP56 PAM4 Passive Breakout Direct Attach Copper Cable
$65.00
Mellanox MCP7H50-H01AR30 Compatible 1.5m (5ft) Infiniband HDR 200G QSFP56 to 2x100G QSFP56 PAM4 Passive Breakout Direct Attach Copper Cable
$65.00
-
 Mellanox MCP7H50-H001R30 Compatible 1m (3ft) Infiniband HDR 200G QSFP56 to 2x100G QSFP56 PAM4 Passive Breakout Direct Attach Copper Cable
$55.00
Mellanox MCP7H50-H001R30 Compatible 1m (3ft) Infiniband HDR 200G QSFP56 to 2x100G QSFP56 PAM4 Passive Breakout Direct Attach Copper Cable
$55.00
-
 HPE (Mellanox) P06248-B21 Compatible 1m (3ft) Infiniband HDR 200G QSFP56 to 2x100G QSFP56 PAM4 Passive Breakout Direct Attach Copper Cable
$75.00
HPE (Mellanox) P06248-B21 Compatible 1m (3ft) Infiniband HDR 200G QSFP56 to 2x100G QSFP56 PAM4 Passive Breakout Direct Attach Copper Cable
$75.00
-
 HPE (Mellanox) P06248-B22 Compatible 1.5m (5ft) Infiniband HDR 200G QSFP56 to 2x100G QSFP56 PAM4 Passive Breakout Direct Attach Copper Cable
$80.00
HPE (Mellanox) P06248-B22 Compatible 1.5m (5ft) Infiniband HDR 200G QSFP56 to 2x100G QSFP56 PAM4 Passive Breakout Direct Attach Copper Cable
$80.00
-
 Mellanox MCP1600-E01AE30 Compatible 1.5m InfiniBand EDR 100G QSFP28 to QSFP28 Copper Direct Attach Cable
$35.00
Mellanox MCP1600-E01AE30 Compatible 1.5m InfiniBand EDR 100G QSFP28 to QSFP28 Copper Direct Attach Cable
$35.00
-
 Mellanox MCP1600-E003E26 Compatible 3m InfiniBand EDR 100G QSFP28 to QSFP28 Copper Direct Attach Cable
$43.00
Mellanox MCP1600-E003E26 Compatible 3m InfiniBand EDR 100G QSFP28 to QSFP28 Copper Direct Attach Cable
$43.00
-
 Mellanox MCP1600-E002E30 Compatible 2m InfiniBand EDR 100G QSFP28 to QSFP28 Copper Direct Attach Cable
$35.00
Mellanox MCP1600-E002E30 Compatible 2m InfiniBand EDR 100G QSFP28 to QSFP28 Copper Direct Attach Cable
$35.00
-
 Mellanox MCP1600-E001E30 Compatible 1m InfiniBand EDR 100G QSFP28 to QSFP28 Copper Direct Attach Cable
$25.00
Mellanox MCP1600-E001E30 Compatible 1m InfiniBand EDR 100G QSFP28 to QSFP28 Copper Direct Attach Cable
$25.00