
During the Chinese Spring Festival, DeepSeek quickly became popular with its ultra-low price, setting off a global AI big model storm. This directly changed the “traditional” concept that the development of AI requires continuous accumulation of computing power and GPUs.
But many people may wonder: How many GPUs are needed to train DeepSeek?
There are different opinions on this issue on the Internet. Even “American Iron Man” Musk questioned DeepSeek: I don’t believe that only a very small number of chips were used.
So how many GPUs does DeepSeek use? Recently, the website SemiAnalysis analyzed this topic. I personally think it is relatively true. Let’s discuss it together today.
DeepSeek and High-Flyer
For those who have been following the field of big AI models closely, DeepSeek is not strictly a new company.
DeepSeek founder Liang Wenfeng was born in Zhanjiang City, Guangdong Province in 1985. In 2015, Liang Wenfeng and his friends founded High-Flyer, one of the earliest institutions to use artificial intelligence in trading algorithms.
They realized early on the potential of AI beyond finance and the importance of expansion. As a result, they continued to expand their GPU supply. Before the export restrictions in 2021, High-Flyer invested in 10,000 A100 GPUs, a move that paid off handsomely.
As High-Flyer continued to progress, they realized in May 2023 that it was time to spin off “DeepSeek” to more focusedly pursue further AI capabilities. Since external investors had little interest in AI at the time and were concerned about the lack of a business model, High-Flyer invested in the company on its own, which now seems to be a wise investment.
Thanks to this, High-Flyer and DeepSeek now often share human and computing resources. DeepSeek has now developed into a serious and organized effort, not a “sideline” as many media claim. SemiAnalysis believes that even taking into account export controls, their investment in GPUs has exceeded $500 million.
GPU Resource Distribution of DeepSeek
SemiAnalysis estimates that DeepSeek uses about 50,000 Hopper GPUs for training, which is of course not equivalent to 50,000 H100s as some people claim. Nvidia manufactures different versions of the H100 (H800, H20) according to different regulations, and currently only the H20 is available to model suppliers in China.
It is important to note that the H800 has the same computing power as the H100, but with lower network bandwidth.
SemiAnalysis believes that DeepSeek uses about 10,000 H800s and about 10,000 H100s. In addition, they have ordered more H20s, and Nvidia has produced more than 1 million GPUs designed specifically for China in the past 9 months. These GPUs are shared between High-Flyer and DeepSeek and deployed in a certain degree of geographical dispersion for trading, reasoning, training, and research.
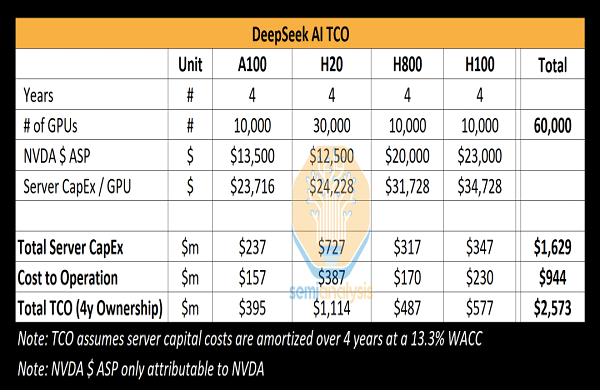
Deepseek TCO
The analysis shows that DeepSeek’s total server capital expenditures were approximately $1.6 billion, of which the costs associated with operating these clusters were considerable, reaching $944 million.
Similarly, all AI labs and hyperscale cloud service providers have more GPUs for a variety of tasks, including research and training, rather than just for a single training run. How to effectively concentrate resources for training for a specific task is also one of DeepSeek’s challenges.
In terms of talent, DeepSeek focuses on recruiting talent from China, regardless of previous qualifications, focusing on their ability and curiosity. It is understood that DeepSeek regularly holds job fairs at top universities such as Peking University and Zhejiang University, where many employees graduate from. Positions are not necessarily predefined, and recruiters are given flexibility. DeepSeek even boasted in recruitment ads that they can use tens of thousands of GPUs without restrictions.
DeepSeek is extremely competitive, reportedly offering salaries of more than $1.3 million to promising candidates, far higher than Chinese rivals such as Moonshot. DeepSeek currently has about 150 employees but is growing rapidly.
As history has proven, a small, well-funded and focused startup is often able to push the boundaries of what’s possible. DeepSeek doesn’t have the same bureaucracy as Google, and being self-funded, they can move ideas forward quickly. However, like Google, DeepSeek (in most cases) operates its own data centers and doesn’t rely on external parties or providers. This opens up more room for experimentation, allowing them to innovate across the entire stack.
SemiAnalysis believes that DeepSeek is the best “open and flexible” laboratory today, surpassing Meta’s Llama project, Mistral, etc.
Training Cost and Performance of DeepSeek
Recently, a headline about DeepSeek’s price and efficiency caused a global frenzy, saying that DeepSeek V3 only cost “$6 million” to train, which is wrong. It’s like considering a specific part in a product’s bill of materials as the entire cost. The pre-training cost is only a very small part of the total cost.
Let’s take a look at the overall training cost of DeepSeek:
We believe that the cost of pre-training is far from the actual amount spent on the model. SemiAnalysis believes that DeepSeek’s spending on hardware in the company’s history is far more than $500 million. During the model development process, in order to develop new architectural innovations, it is necessary to spend a considerable amount of money on testing new ideas, new architectural ideas, and ablation studies.
For example, Multi-Head Latent Attention is a key innovation of DeepSeek. Its development took the team several months and involved a lot of manpower and GPU resources. The $6 million cost mentioned in the article is attributed only to the GPU costs for the pre-training runs, which is only part of the total cost of the model. Other important parts left out include R&D and the total cost of ownership (TCO) of the hardware itself.
For reference, the training cost of Claude 3.5 Sonnet was tens of millions of dollars, and if that was all it took for Anthropic, they wouldn’t have raised billions from Google and tens of billions from Amazon. This is because they need to run experiments, come up with new architectures, collect and clean data, pay employees, etc.
So how did DeepSeek have such a large cluster? The lag in export control is the key, and they also ordered a large number of H20 model GPUs, which are specially produced to meet the needs of the Chinese market.
Let’s take a look at the performance of V3:
V3 is undoubtedly an impressive model, but it is worth noting what it is impressive relative to. Many people compare V3 to GPT-4o and emphasize that V3 outperforms 4o. This is true, but GPT-4o was released in May 2024. In the field of AI, this period of time has brought significant algorithmic progress.
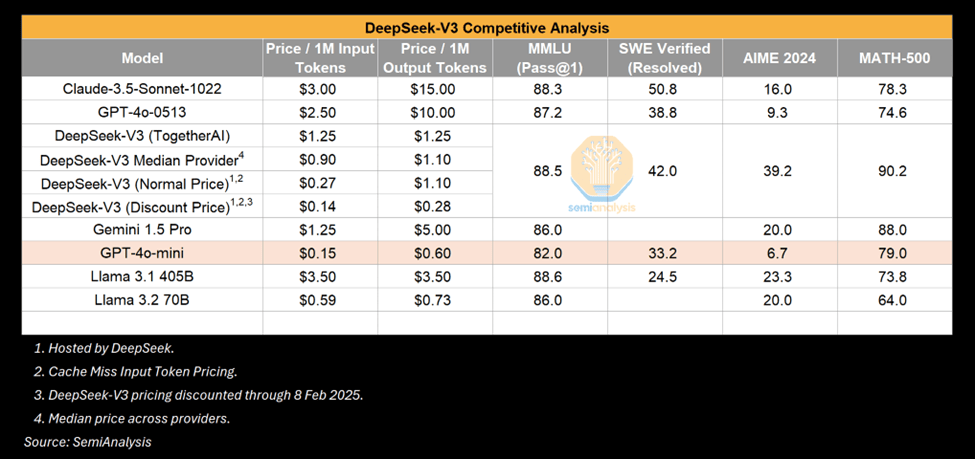
Deepseek-V3 Competitive Analysis
Over time, it is normal to achieve the same or greater capabilities with fewer computing resources. For example, a small model that can now run on a laptop has performance comparable to GPT-3, which requires a supercomputer for training and multiple GPUs for inference.
In other words, algorithmic improvements have resulted in less compute required to train and infer models of the same capability, a pattern that has emerged time and again. This time, the world took notice because it came from a lab in China. But performance gains for small models are nothing new.
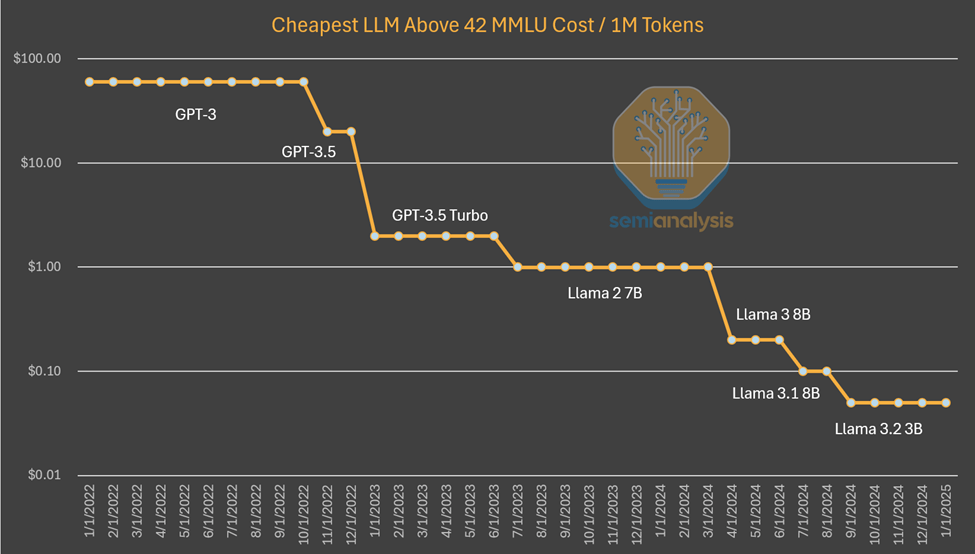
Cheapest LLM Above 42 MMLU Cost/1M Tokens
The pattern we have witnessed so far suggests that AI labs are spending more in absolute dollar terms in exchange for better performance for their work. The rate of algorithmic progress is estimated to be 4x per year, meaning that with each passing year, the amount of compute required to achieve the same capability is reduced by 3/4.
Anthropic CEO Dario believes that algorithmic progress is even faster, bringing a 10x improvement. In terms of GPT-3-level inference pricing, costs have dropped 1,200x.
When looking at the cost of GPT-4, we see a similar downward trend in cost, albeit earlier in the curve. While the reduction in cost differentials over time could be explained by not holding power constant, in this case we see a 10x reduction in cost and a 10x increase in power due to algorithmic improvements and optimizations.
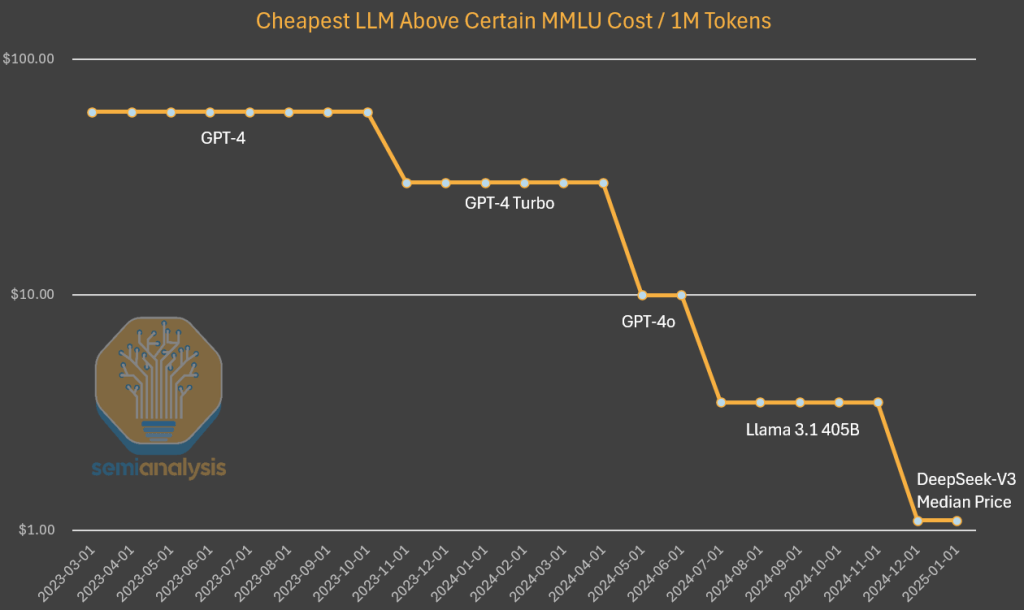
Cheapest LLM Above Certain MMLU Cost/1M Tokens
To be clear, DeepSeek is unique in that they are the first to achieve this level of cost and capability. They are also unique in releasing open source weights, but previous Mistral and Llama models have done so. DeepSeek has achieved this level of cost, but don’t be surprised to see costs drop another 5x by the end of the year.
- Is the Performance of R1 Comparable to o1?
On the other hand, R1 is able to achieve comparable results to O1, which was only announced in September. How did DeepSeek catch up so quickly?
The answer is that inference is a new paradigm that has faster iterations and lower barriers to entry, and can achieve meaningful gains with less compute, which is more advantageous than the previous paradigm. As outlined in the Scaling Law report, the previous paradigm relied on pre-training, which is becoming increasingly expensive and difficult to achieve robust gains.
This new paradigm focuses on enabling inference capabilities through synthetic data generation and reinforcement learning (RL) post-trained on existing models, which allows people to make progress faster and at a lower price. The low barrier to entry combined with the ease of optimization allows DeepSeek to replicate o1’s approach faster than ever before. As participants gradually learn to achieve greater scale in this new paradigm, the time gap to matching capabilities is expected to increase.
It’s important to note that the R1 paper doesn’t mention the amount of compute used. This is no accident — generating synthetic data for post-training R1 requires a lot of compute, not to mention reinforcement learning. R1 is a very good model, we don’t deny that, and reaching the forefront of reasoning capabilities so quickly is admirable. DeepSeek is even more impressive as a Chinese company that has caught up with even fewer resources.
But some of the benchmarks mentioned by R1 are also misleading. Comparing R1 to o1 is tricky because R1 intentionally does not mention the benchmarks they do not lead. And while R1 is comparable to o1 in inference performance, in many cases it is not the clear winner in every metric, and in many cases it is worse than o1.
We haven’t even mentioned O3 yet. O3 is vastly superior to both R1 and O1. In fact, OpenAI recently shared results for O3, and the improvement on benchmarks was vertical. “Deep learning has hit a wall,” but this is a different kind of wall.
- Is Google’s Inference Model Comparable to R1?
While R1 generated a lot of hype, a $2.5 trillion company released a cheaper inference model a month earlier: Google’s Gemini Flash 2.0 Thinking. This model is already available and is much cheaper than R1, although its model context length is much larger through the API.
In the reported benchmarks, Flash 2.0 Thinking beats the R1, though benchmarks don’t tell the whole story. Google has only released 3 benchmarks, so this is an incomplete picture. Still, we think Google’s model is solid and holds its own against the R1 in many ways, even though it didn’t have any of the hype. This could be because of Google’s poor go-to-market strategy and poor user experience, but also because the R1 was a surprise from China.
To be clear, none of this diminishes DeepSeek’s outstanding achievement. DeepSeek deserves credit for being a fast-moving, well-funded, smart, and focused startup that was able to beat a giant like Meta to release an inference model.
DeepSeek Technology Innovation
DeepSeek has cracked the AI big model code, unlocking innovations that leading labs have yet to achieve. SemiAnalysis expects that any improvements released by DeepSeek will be replicated almost immediately by Western labs.
What are these improvements? Most of the architectural achievements are related to V3, which is the base model of R1. Let’s explain these innovations in detail.
- Training (pre-training and fine-tuning)
DeepSeek V3 uses multi-label prediction (MTP) at an unprecedented scale and adds attention modules that predict the next few labels instead of a single label. This improves model performance during training and can be discarded at inference time. This is an example of algorithmic innovation that achieves improved performance with lower computational effort.
There are other consideration, like using FP8 precision in training, but leading US labs have been doing FP8 training for a long time. DeepSeek V3 is also a mixture of expert model, a large model composed of many other smaller experts that are good at different things, which is an emergent behavior. One challenge with mixture of experts models is how to determine which label should be assigned to which sub-model or “expert”.
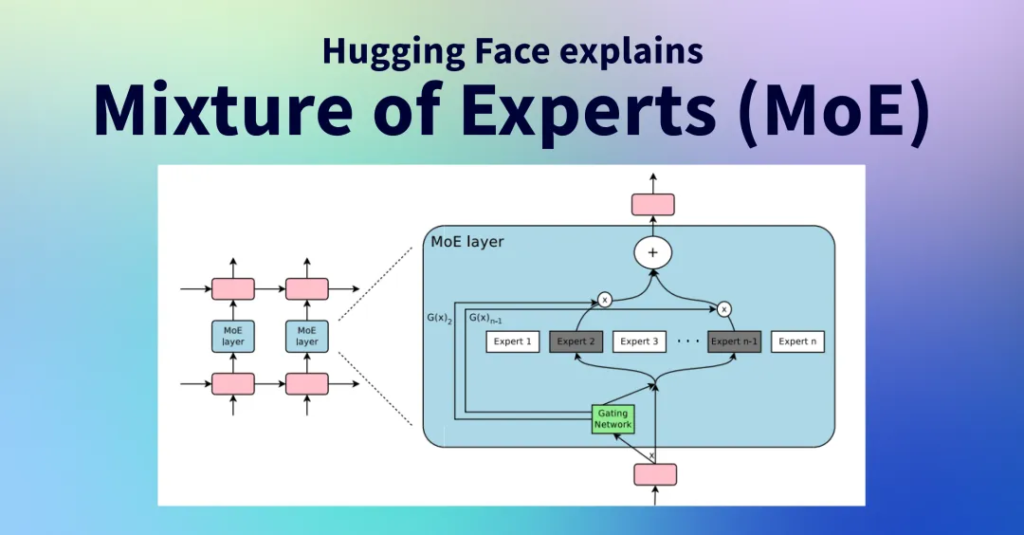
Mixture of Experts
DeepSeek implements a “gating network” to dispatch labels to the correct experts in a balanced way without degrading model performance. This means that the dispatch is very efficient and during training, only a small number of parameters are changed for each label relative to the overall size of the model. This increases training efficiency and reduces the cost of inference.
While some worry that MoE efficiency gains could reduce investment, Dario notes that the economic benefits of more powerful AI models are so large that any cost savings are quickly reinvested in building larger models. Rather than reducing overall investment, MoE efficiency gains will accelerate AI scaling efforts. Companies focus on scaling models to more computing resources and making them more efficient algorithmically.
In the case of R1, it benefited greatly from having a strong base model (V3). This is partly because of reinforcement learning (RL). RL has two focuses: formatting (to ensure it provides coherent output) and usefulness vs. harmlessness (to ensure the model is useful). Reasoning capabilities emerge when the model is fine-tuned on a synthetic dataset.
It’s important to note that there is no mention of compute in the R1 paper, this is because mentioning the amount of compute used would suggest they have more GPUs than they claim. Reinforcement learning at this scale requires a lot of compute, especially for generating synthetic data.
In addition, a portion of the data used by DeepSeek appears to come from OpenAI’s model, which SemiAnalysis believes will have an impact on the policy of extracting information from the output. This is already illegal in the terms of service, but looking forward, a new trend may be some form of KYC (know your customer) to prevent the extraction of information.
Speaking of extracting information, perhaps the most interesting part of the R1 paper is the ability to turn smaller non-inference models into inference models by fine-tuning them with the output of the inference model. The dataset curation includes a total of 800,000 samples, and now anyone can use R1’s CoT output to create their own datasets and use these outputs to make inference models. We may see more smaller models demonstrating inference capabilities, thereby improving the performance of small models.
- Multi-Latent Attention (MLA)
MLA is one of the key innovations of DeepSeek that significantly reduces the cost of inference. The reason is that MLA reduces the KV cache required for each query by about 93.3% compared to standard attention. KV cache is a memory mechanism in the Transformer model that is used to store data representing the context of the conversation and reduce unnecessary calculations.
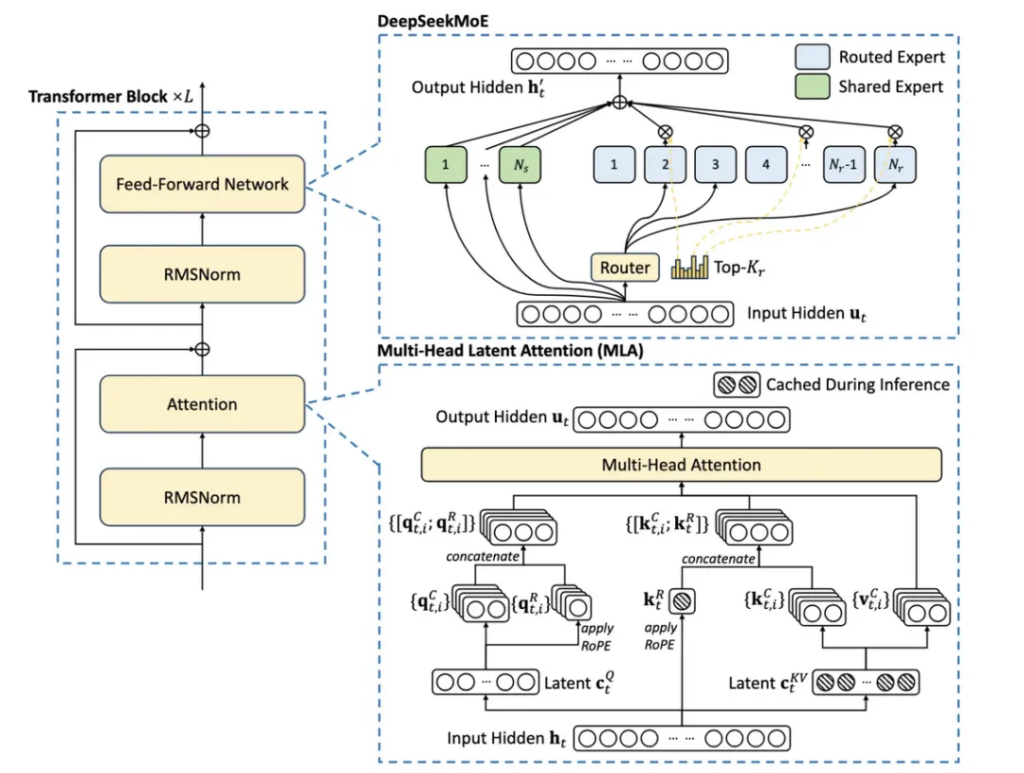
MLA
As the conversation context grows, the KV cache also grows and can introduce significant memory constraints. Drastically reducing the KV cache required for each query can reduce the amount of hardware required for each query, thereby reducing costs.
However, SemiAnalysis believes that DeepSeek is offering inference services at cost price to gain market share rather than actually making money. Google’s Gemini Flash 2.0 Thinking is still cheaper, and it is unlikely that Google will offer the service at cost price. MLA has particularly attracted the attention of many leading US laboratories. MLA was introduced in DeepSeek V2, which was released in May 2024. Due to the higher memory bandwidth and capacity of H20 than H100, DeepSeek also enjoys more efficiency in inference workloads.
At present, DeepSeek’s GPU requirements highlight the necessity of effective AI infrastructure planning. By using intelligent workload distribution, quantization, and dynamic GPU allocation, businesses can significantly reduce computing costs while maintaining high performance. This is also an important reason why DeepSeek is called a “national-level” product.