
Traditional data centers have undergone a transition from a three-tier architecture to a leaf-spine architecture, primarily to accommodate the growth of east-west traffic within the data center. As the process of data migration to the cloud continues to accelerate, the scale of cloud computing data centers continues to expand. Applications such as virtualization and hyper-converged systems adopted in these data centers have driven a significant increase in east-west traffic—according to previous data from Cisco, in 2021, internal data center traffic accounted for over 70% of data center-related traffic.
Taking the transition from traditional three-tier architecture to leaf-spine architecture as an example, the number of optical modules required in a leaf-spine network architecture can increase by up to tens of times.
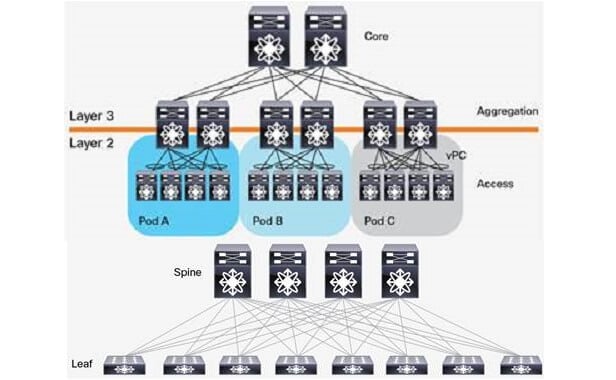
Network Architecture Requirements for Large-Scale AI Clusters
Considering the need to alleviate network bottlenecks, the network architecture for large-scale AI clusters must meet the requirements of high bandwidth, low latency, and lossless transmission. AI computing centers generally adopt a Fat-Tree network architecture, which features a non-blocking network. Additionally, to avoid inter-node interconnect bottlenecks, NVIDIA employs NVLink to enable efficient inter-GPU communication. Compared to PCIe, NVLink offers higher bandwidth advantages, serving as the foundation for NVIDIA’s shared memory architecture and creating a new demand for optical interconnects between GPUs.
A100 Network Structure and Optical Module Requirements
The basic deployment structure for each DGX A100 SuperPOD consists of 140 servers (each server with 8 GPUs) and switches (each switch with 40 ports, each port at 200G). The network topology is an InfiniBand (IB) Fat-Tree structure. Regarding the number of network layers, a three-layer network structure (server-leaf switch-spine switch-core switch) is deployed for 140 servers, with the corresponding number of cables for each layer being 1120-1124-1120, respectively. Assuming copper cables are used between servers and switches, and based on one cable corresponding to two 200G optical modules, the ratio of GPU:switch:optical module is 1:0.15:4. If an all-optical network is used, the ratio becomes GPU:switch:optical module = 1:0.15:6.

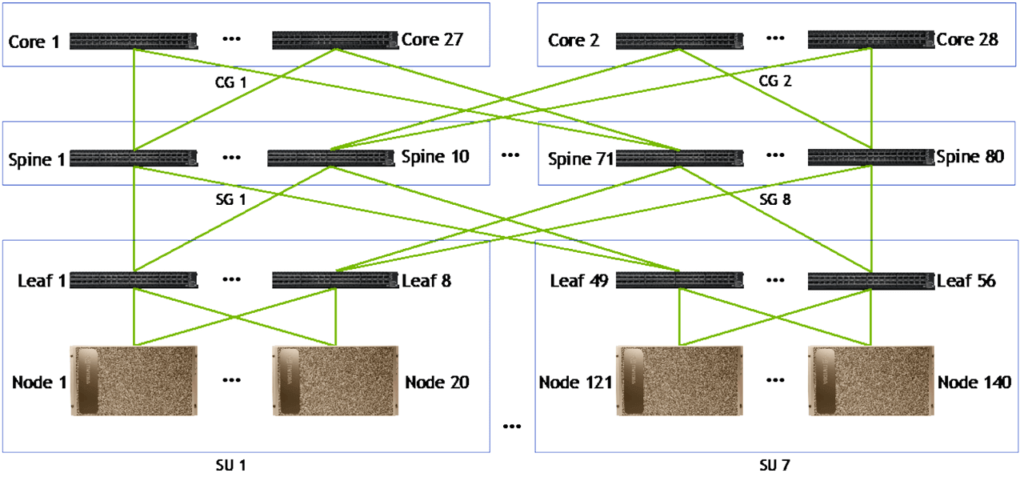
H100 Network Structure and Optical Module Requirements
The basic deployment structure for each DGX H100 SuperPOD consists of 32 servers (each server with 8 GPUs) and 12 switches. The network topology is an IB Fat-Tree structure, with each switch port operating at 400G and capable of being combined into an 800G port. For a 4SU cluster, assuming an all-optical network and a three-layer Fat-Tree architecture, 400G optical modules are used between servers and leaf switches, while 800G optical modules are used between leaf-spine and spine-core switches. The number of 400G optical modules required is 3284=256, and the number of 800G optical modules is 3282.5=640. Therefore, the ratio of GPU:switch:400G optical module:800G optical module is 1:0.08:1:2.5.
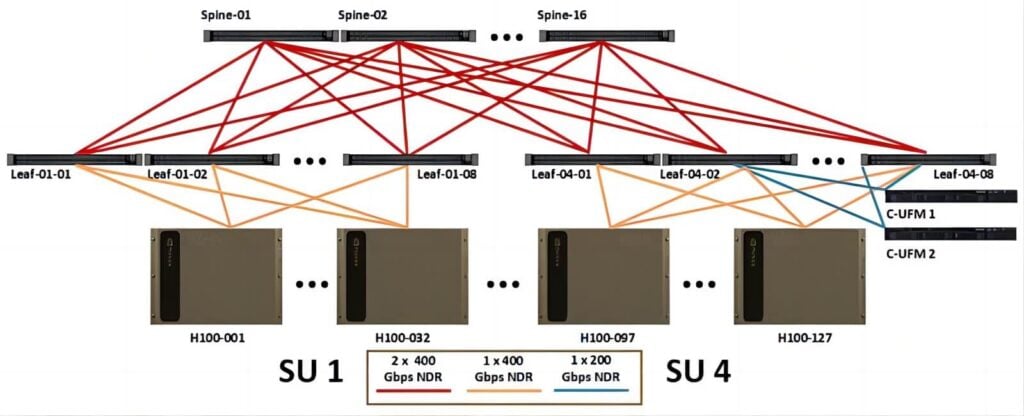
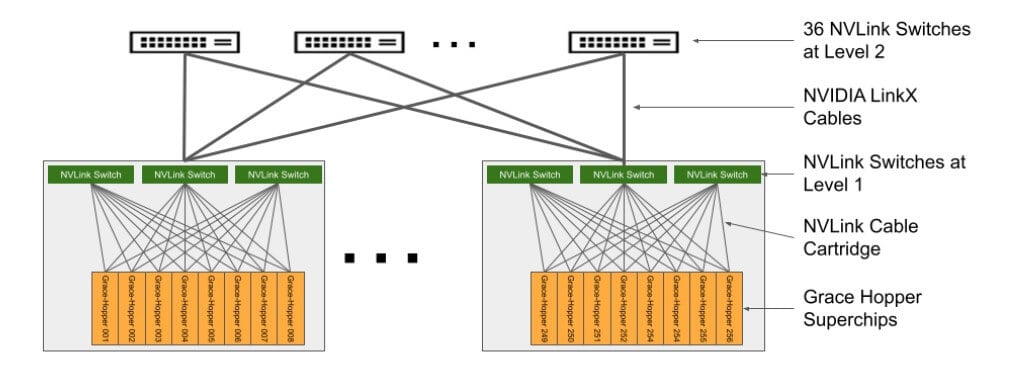
For a single GH200 cluster, which consists of 256 interconnected super-chip GPUs using a two-tier fat-tree network structure, both tiers are built with NVLink switches. The first tier (between servers and Level 1 switches) uses 96 switches, while Level 2 employs 36 switches. Each NVLink switch has 32 ports, with each port having a speed of 800G. Given that the NVLink 4.0’s bidirectional aggregated bandwidth is 900GB/s, and unidirectional is 450GB/s, the total uplink bandwidth for the access layer in a 256-card cluster is 115,200GB/s. Considering the fat-tree architecture and the 800G optical module transmission rate (100GB/s), the total requirement for 800G optical modules is 2,304 units. Therefore, within the GH200 cluster, the ratio of GPUs to optical modules is 1:9. When interconnecting multiple GH200 clusters, referencing the H100 architecture, under a three-tier network structure, the demand for GPUs to 800G optical modules is 1:2.5; under a two-tier network, it is 1:1.5. Thus, when interconnecting multiple GH200s, the upper limit for the GPU to 800G optical module ratio is 1:(9+2.5) = 1:11.5.
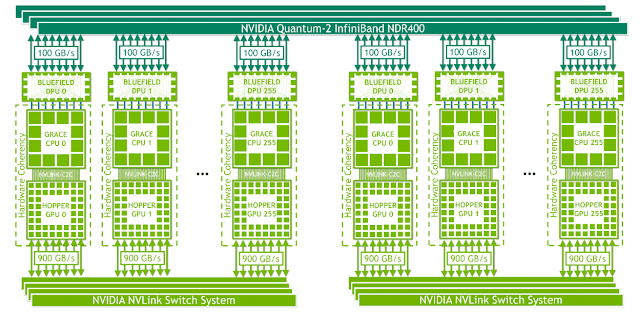
In summary, as computational clusters continue to enhance network performance, the demand for high-speed optical modules becomes more elastic. Taking NVIDIA clusters as an example, the network card interface rate adapted by the accelerator card is closely related to its network protocol bandwidth. The A100 GPU supports PCIe 4.0, with a maximum unidirectional bandwidth of 252Gb/s, hence the PCIe network card rate must be less than 252Gb/s, pairing with Mellanox HDR 200Gb/s Infiniband network cards. The H100 GPU supports PCIe 5.0, with a maximum unidirectional bandwidth of 504Gb/s, thus pairing with Mellanox NDR 400Gb/s Infiniband network cards. Therefore, upgrading from A100 to H100, the corresponding optical module demand increases from 200G to 800G (two 400G ports combined into one 800G); while the GH200 uses NVLink for inter-card connectivity, with unidirectional bandwidth increased to 450GB/s, further increasing the elasticity for the 800G demand. Suppose the H100 cluster upgrades from PCIe 5.0 to PCIe 6.0, with the maximum unidirectional bandwidth increased to 1024Gb/s. In that case, the access layer network card rate can be raised to 800G, meaning the access layer can use 800G optical modules, and the demand elasticity for a single card corresponding to 800G optical modules in the cluster would double.
Meta’s computational cluster architecture and application previously released the “Research SuperCluster” project for training the LLaMA model. In the second phase of the RSC project, Meta deployed a total of 2,000 A100 servers, containing 16,000 A100 GPUs. The cluster includes 2,000 switches and 48,000 links, corresponding to a three-tier CLOS network architecture. If a full optical network is adopted, it corresponds to 96,000 200G optical modules, meaning the ratio of A100 GPUs to optical modules is 1:6, consistent with the previously calculated A100 architecture.
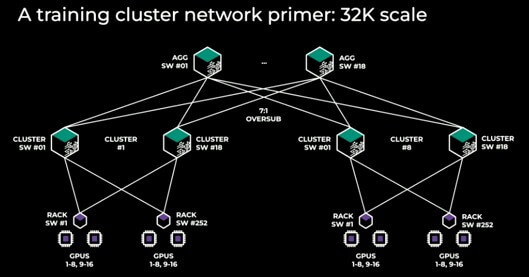
Meta has implemented a training infrastructure for LLaMA3 using H100 GPUs, which includes clusters with both InfiniBand and Ethernet, capable of supporting up to 32,000 GPUs. For the Ethernet solution, according to information disclosed by Meta, the computing cluster still employs a converged leaf-spine network architecture. Each rack contains 2 servers connected to 1 Top-of-Rack (TOR) switch (using Wedge 400), with a total of 252 servers in a cluster. The cluster switches use Minipack2 OCP rack switches, with 18 cluster switches in total, resulting in a convergence ratio of 3.5:1. There are 18 aggregation layer switches (using Arista 7800R3), with a convergence ratio of 7:1. The cluster primarily uses 400G optical modules. From the cluster architecture perspective, the Ethernet solution still requires further breakthroughs at the protocol level to promote the construction of a non-blocking network, with attention to the progress of organizations such as the Ethernet Alliance.
AWS has launched the second generation of EC2 Ultra Clusters, which include the H100 GPU and their proprietary Trainium ASIC solution. The AWS EC2 Ultra Clusters P5 instances (i.e., the H100 solution) provide an aggregate network bandwidth of 3200 Gbps and support GPUDirect RDMA, with a maximum networking capacity of 20,000 GPUs. The Trn1n instances (proprietary Trainium solution) feature a 16-card cluster providing 1600 Gbps of aggregate network bandwidth, supporting up to 30,000 ASICs networked, corresponding to 6 EFlops of computing power.
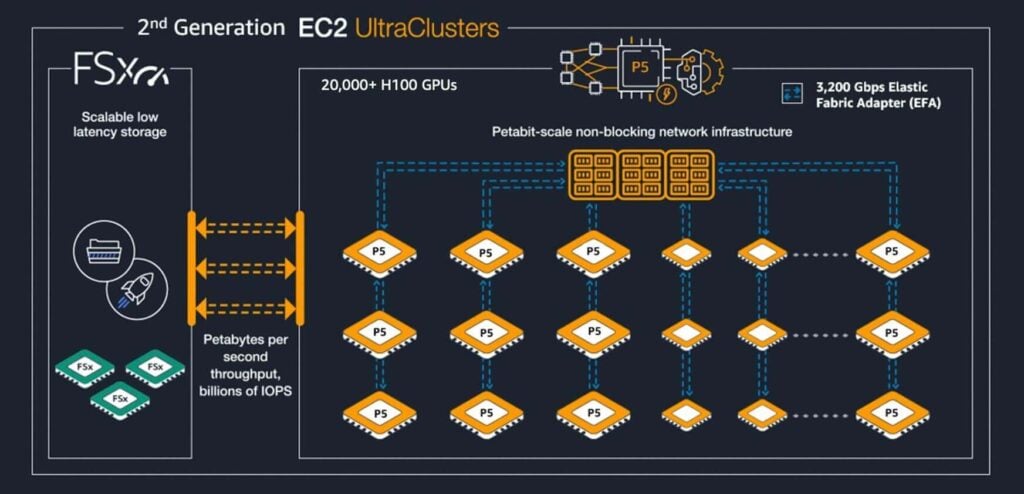
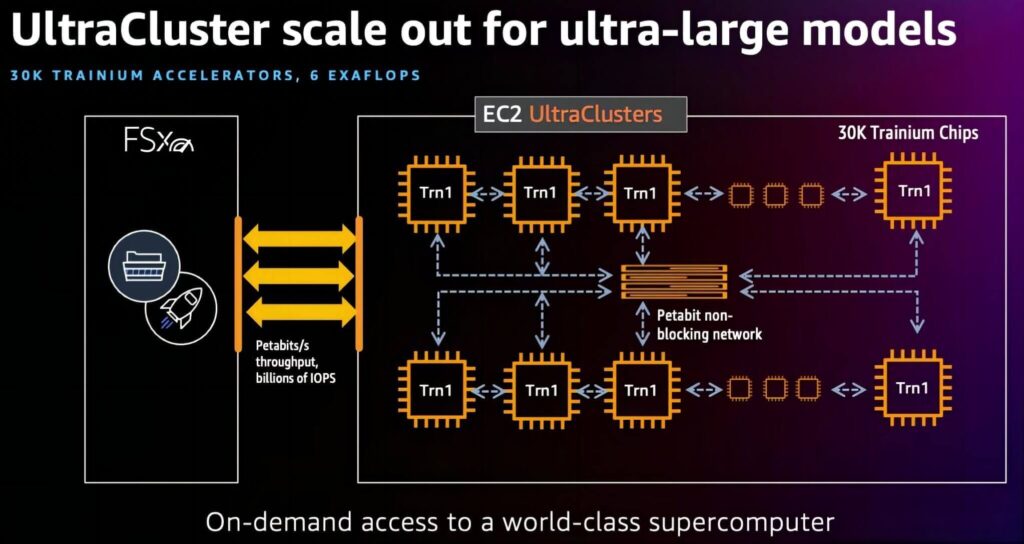
The interconnection between AWS EC2 Ultra Clusters cards uses NVLink (for the H100 solution) and NeuronLink (for the Trainium solution), with cluster interconnection using their proprietary EFA network adapter. Compared to Nvidia’s solution, AWS’s proprietary Trainium ASIC cluster has an estimated uplink bandwidth of 100G per card (1600G aggregate bandwidth / 16 cards = 100G), hence there is currently no demand for 800G optical modules in AWS’s architecture.
Google’s latest computing cluster is composed of TPU arrays configured in a three-dimensional torus. A one-dimensional torus corresponds to each TPU connected to two adjacent TPUs, a two-dimensional torus consists of two orthogonal rings, corresponding to each TPU connected to four adjacent TPUs; Google’s TPUv4 represents a three-dimensional torus, with each TPU connected to six adjacent TPUs.
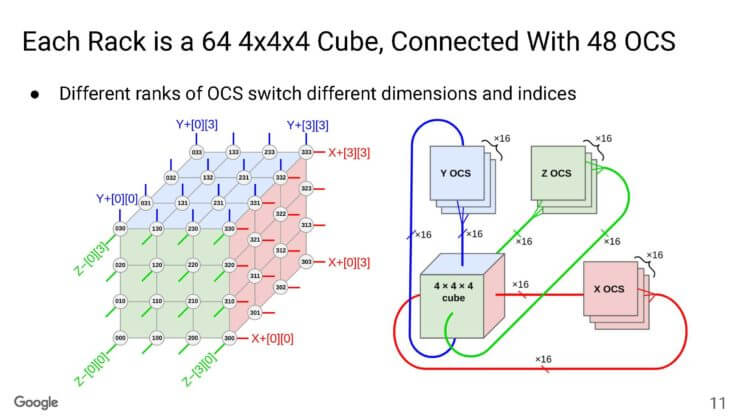
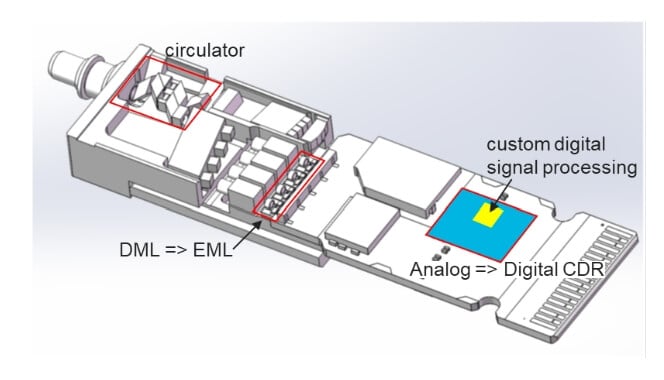
Based on this, a 3D network structure of 444=64 TPUs is constructed within each cabinet. The external part of the 3D structure connects to the OCS, with an interconnection of 4096 TPUs corresponding to 64 cabinets and 48 OCS switches, which equals 48*64=6144 optical modules. Internally, DAC connections are used (18000 cables), resulting in a TPU to optical module ratio of 1:1.5. Under the OCS solution, the optical modules need to adopt a wavelength-division multiplexing solution and add circulators to reduce the number of fibers, with the optical module solution having customized features (800G VFR8).
Related Products:
-
 NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$700.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA MMA1Z00-NS400 Compatible 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$550.00
-
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
OSFP-FLT-800G-PC2M 2m (7ft) 2x400G OSFP to 2x400G OSFP PAM4 InfiniBand NDR Passive Direct Attached Cable, Flat top on one end and Flat top on the other
$300.00
-
OSFP-800G-PC50CM 0.5m (1.6ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Passive Direct Attach Copper Cable
$105.00
-
OSFP-800G-AC3M 3m (10ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Active Copper Cable
$600.00
-
OSFP-FLT-800G-AC3M 3m (10ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Active Copper Cable, Flat top on one end and Flat top on the other
$600.00











