
في ظل التطور السريع للبنية التحتية للذكاء الاصطناعي، تبرز AMD كشركة رائدة في مجال تغيير قواعد اللعبة، لا سيما في تقنيات التبريد السائل. ومع سعي مراكز البيانات إلى الارتقاء بمستويات الأداء والكفاءة، تُرسي أحدث تطورات AMD معايير جديدة. تلتزم FiberMall، الشركة المتخصصة في توفير منتجات وحلول الاتصالات الضوئية، بتقديم عروض فعّالة من حيث التكلفة لمراكز البيانات العالمية، وبيئات الحوسبة السحابية، وشبكات المؤسسات، وشبكات الوصول، والأنظمة اللاسلكية. تشتهر FiberMall بريادتها في شبكات الاتصالات المدعومة بالذكاء الاصطناعي، وهي شريك مثالي إذا كنت تبحث عن حلول اتصالات ضوئية عالية الجودة وفعّالة من حيث التكلفة. لمزيد من التفاصيل، يُمكنك زيارة موقعها الإلكتروني الرسمي أو التواصل مباشرةً مع فريق دعم العملاء.
تستكشف هذه المدونة التطورات الرائدة لشركة AMD في مجال تبريد السائل بالذكاء الاصطناعي، بدءًا من مجموعات وحدات معالجة الرسومات الضخمة وصولًا إلى سلسلة MI350 المبتكرة. سواءً كنت من هواة الذكاء الاصطناعي، أو مشغلًا لمراكز البيانات، أو مستثمرًا في التكنولوجيا، فإن هذه الرؤى تُبرز لماذا تُصبح AMD بمثابة دوارة الرياح للعصر القادم من حوسبة الذكاء الاصطناعي.
TensorWave تنشر أكبر مجموعة خوادم AMD المبردة بالسائل في أمريكا الشمالية
أعلنت شركة TensorWave، الرائدة في مجال البنية التحتية للذكاء الاصطناعي، مؤخرًا عن نجاحها في نشر أكبر مجموعة تدريب لوحدات معالجة الرسومات AMD في أمريكا الشمالية. بفضل 8,192 مُسرّعًا لوحدات معالجة الرسومات Instinct MI325X، تُمثل هذه المجموعة أول مجموعة تبريد سائل مباشر (DLC) واسعة النطاق تستخدم هذا الطراز من وحدات معالجة الرسومات.

يُمكّن تركيز TensorWave على أجهزة AMD المتطورة من توفير منصات حوسبة فعّالة للشركات ومؤسسات البحث والمطورين. لا يُحقق هذا التكتّل الضخم رقمًا قياسيًا في الحجم فحسب، بل يُضفي أيضًا زخمًا جديدًا على تطوير الذكاء الاصطناعي. ويشير محللو الصناعة إلى أن التكتلات القائمة على AMD تُقدّم فعالية فائقة من حيث التكلفة، حيث يُمكن أن تُوفّر ما يصل إلى 30% مُقارنةً بـ أنظمة DGX من NVIDIA للحصول على قوة حوسبة مكافئة.
مع تزايد اعتماد المؤسسات لوحدات معالجة الرسومات من AMD، قد تنخفض تكاليف البنية التحتية للذكاء الاصطناعي بشكل أكبر، مما يُسرّع من تبني الذكاء الاصطناعي في مختلف القطاعات. لتلبية احتياجات الاتصالات البصرية في هذه البيئات عالية الأداء، توفر FiberMall حلولاً موثوقة ومُحسّنة للذكاء الاصطناعي لضمان نقل البيانات بسلاسة.

AMD تكشف عن شريحة MI350 المزودة بنظام تبريد سائل كامل، مما أثار حماس السوق
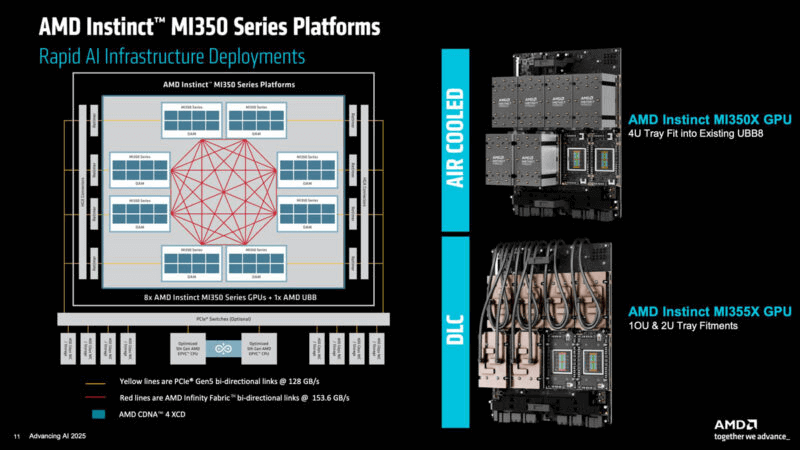
في ١٢ يونيو ٢٠٢٥، استضافت AMD مؤتمر "تطوير الذكاء الاصطناعي ٢٠٢٥" في سان خوسيه، كاليفورنيا، حيث أطلقت رسميًا مُسرّعات وحدات معالجة الرسومات Instinct MI12. تُمكّن هذه المُسرّعات من إنشاء مجموعات حوسبة فائقة الاتساع من خلال التعاون بين بطاقات متعددة، حيث تدعم كل عُقدة ما يصل إلى ثماني بطاقات بالتوازي، مُوفرةً ٢٣٠٤ جيجابايت من ذاكرة HBM2025E. يبلغ الأداء ذروته عند أكثر من ٨٠.٥ بي فلوب في الثانية بدقة FP2025 و١٦١ بي فلوب في الثانية بدقة FP350/FP2,304، مُنافسًا بذلك معالج GB3 من NVIDIA.
يستخدم الاتصال بين البطاقات قنوات Infinity Fabric ثنائية الاتجاه، بينما تستفيد اتصالات وحدة المعالجة المركزية من منفذ PCIe 128 بسرعة 5.0 جيجابايت/ثانية لنقل البيانات بسلاسة. تقدم AMD نسختين مبردتين بالهواء والسائل؛ يدعم التبريد الهوائي ما يصل إلى 64 بطاقة، بينما يصل التبريد السائل إلى 128 بطاقة (رفوف 2U-5U) لتلبية احتياجات الحوسبة الفائقة المتنوعة.



تستهلك وحدة MI350X طاقة قدرها 1,000 واط مع التبريد الهوائي، بينما تصل طاقة وحدة MI355X عالية الأداء إلى 1,400 واط، وتستخدم التبريد السائل بشكل أساسي. وقد طرحت شركات مثل Supermicro وPegatron وGigabyte بالفعل خوادم MI350 المبردة بالسائل.


في سوق رقاقات الذكاء الاصطناعي العالمية المتطورة، تسيطر NVIDIA على أكثر من 80% من الحصة السوقية، إلا أن عودة AMD القوية لمعالج MI350 - الذي يُضاهي أداء معالج GB200 - تُشير إلى تحول كبير. بالنسبة لأنظمة التبريد السائل، يُقدم تقدم AMD بدائل لهيمنة NVIDIA، مما يُعزز المنافسة. سيُدمج مزودو الخدمات السحابية الرائدون، بما في ذلك شركات الحوسبة السحابية الضخمة وNeo Cloud، معالج MI350، على أن تحذو Dell وHPE وSupermicro حذوهم. بدأ الإنتاج الضخم في أوائل هذا الشهر، ومن المقرر أن تبدأ خوادم الشركاء الأولية ومثيلات CSP في الربع الثالث من عام 3 - حيث يُفضل الكثيرون... السائل يبرد المتغيرات.

وتكمل خبرة FiberMall في الشبكات البصرية المدعومة بالذكاء الاصطناعي هذه النشرات، مما يوفر ربطًا فعالًا من حيث التكلفة لمجموعات الذكاء الاصطناعي ذات النطاق الترددي العالي.
تأثير AMD الرائد على سوق التبريد السائل
ربطت شبه احتكار NVIDIA تطورات التبريد السائل بنظامها البيئي، بما في ذلك قوائم بيضاء مقيدة تُثني الشركاء. تُعدّ مجموعات AMD واسعة النطاق المُبرّدة بالسائل، وإطلاق MI350، بمثابة نعمة، مما قد يُشكّل تحديًا لشركة NVIDIA، إلى جانب شركات أخرى مثل هواوي. قد يُنعش هذا موردي التبريد السائل خارج نطاق NVIDIA.
تزعم AMD أن معالج MI350 سيعزز كفاءة استخدام الطاقة لمنصة الذكاء الاصطناعي بنحو 38 مرة خلال خمس سنوات، مع خطط لتحسين آخر بنحو 20 مرة بحلول عام 2030، مما يقلل استخدام الطاقة بنسبة تصل إلى 95%.
نظرة متعمقة: شرائح AMD MI350 Series، وOAM، وUBB، والخوادم المبردة بالسائل، ونشر الحوامل
في مؤتمر Advancing AI 2025، قدمت AMD سلسلة Instinct MI350، بما في ذلك MI350X وMI355X، والتي من المقرر أن تتنافس بشكل مباشر مع Blackwell من NVIDIA.

نظرة عامة على Instinct MI350
يتميز كلا الطرازين بذاكرة HBM288E سعة 3 جيجابايت وعرض نطاق ترددي يبلغ 8 تيرابايت/ثانية. يقدم MI355X أداءً كاملاً: FP64 بسرعة 79 تيرا فلوب، وFP16 بسرعة 5 تيرا فلوب، وFP8 بسرعة 10 تيرا فلوب، وFP6/FP4 بسرعة 20 تيرا فلوب، مع استهلاك طاقة حراري يصل إلى 1,400 واط. تم تخفيض أداء MI350X بنسبة 8%، ليصل إلى ذروة 18.4 تيرا فلوب في FP4 مع استهلاك طاقة حراري يبلغ 1,000 واط.
شرائح AMD Instinct MI350 Series
يتشارك كل من MI350X وMI355X في تصميم الشريحة، والذي تم بناؤه على بنية ربط هجينة ثلاثية الأبعاد باستخدام عمليات 3nm (N3P) و3nm من TSMC.


مقارنة: AMD MI350X مقابل NVIDIA B200/GB200
| معامل | ايه ام دي MI350X | نفيديا بي200 | نفيديا GB200 |
| معمار | CDNA 4 (الترابط الهجين ثلاثي الأبعاد) | بلاكويل (تكامل القالب المزدوج) | وحدة المعالجة المركزية Blackwell + Grace (ثنائي B200 + 1 Grace) |
| عقدة العملية | تغليف هجين TSMC 3nm (N3P) + 6nm (IOD) | TSMC 4 نانومتر (N4P) | TSMC 4 نانومتر (N4P) |
| الترانزستورات | 185 مليار | 208 مليار | 416 مليار (B200 مزدوج) |
| تكوين الذاكرة | 288 جيجابايت HBM3E (12Hi Stack)، عرض النطاق الترددي 8 تيرابايت/ثانية | 192 جيجابايت HBM3E (8Hi Stack)، عرض النطاق الترددي 7.7 تيرابايت/ثانية | 384 جيجابايت HBM3E (مزدوج B200)، عرض النطاق الترددي 15.4 تيرابايت/ثانية |
| حساب FP4 | 18.4 بيلو فلوب (36.8 بيلو فلوب متفرق) | 20 PFLOPS (FP4 كثيف) | 40 PFLOPS (ثنائي B200) |
| حساب FP8 | 9.2 بيلو فلوب (18.4 بيلو فلوب متفرق) | 10 فلوبس | 20 فلوبس |
| حساب FP32 | 144 TFLOPS | 75 TFLOPS | 150 TFLOPS |
| حساب FP64 | 72 تيرا فلوب (2x B200 دقة مزدوجة) | 37 TFLOPS | 74 TFLOPS |
| ربط | 153.6 جيجابايت/ثانية Infinity Fabric (8 بطاقات/عقدة)، Ultra Ethernet إلى 128 بطاقة | 1.8 تيرابايت/ثانية NVLink 5.0 (لكل بطاقة)، 576 بطاقة في NVL72 | 1.8 تيرابايت/ثانية NVLink 5.0 (لكل B200)، 129.6 تيرابايت/ثانية ثنائي الاتجاه في مجموعة مكونة من 72 بطاقة |
| استهلاك الطاقة | 1000 واط (مبرد بالهواء) | 1000 واط (مبرد بالسائل) | 2700 واط (ثنائي B200 + جريس) |
| النظام البيئي للبرمجيات | ROCm 7 مع تحسين PyTorch/TensorFlow، ودعم FP4/FP6 | CUDA 12.5+ مع دقة FP4/FP8 واستدلال TensorRT-LLM | CUDA 12.5+ مع تحسين وحدة المعالجة المركزية Grace للنماذج ذات تريليون معلمة |
| الأداء النموذجي | Llama 3.1 405B استدلال أسرع بنسبة 30% من B200؛ FP8 مكون من 4 بطاقات بسرعة 147 PFLOPS | تدريب GPT-3 4x H100؛ استدلال FP4 ببطاقة واحدة 5x H100 | 72 بطاقة NVL72 FP4 بمعدل 1.4 EFLOPS؛ تكلفة الاستدلال أقل بنسبة 25% من H100 |
| السعر (2025) | 25,000 دولار (زيادة حديثة بنسبة 67%، لا تزال أقل من B17 بنسبة 200%) | $30,000 | 60,000 دولار أمريكي فأكثر (B200 مزدوج + نعمة) |
| الكفاءة | عرض نطاق ترددي HBM أعلى بنسبة 30% لكل واط؛ 40% المزيد من الرموز لكل دولار من B200 | زيادة بنسبة 25% في FP4 لكل ترانزستور؛ وكفاءة أفضل بنسبة 50% في NVLink | 14.8 PFLOPS/W في التبريد السائل لـ FP4 |
| الميزة التنافسية | استدلال ثنائي الدقة فريد من نوعه FP6/FP4؛ 288 جيجابايت لنماذج 520B-Parameter | محرك المحولات من الجيل الثاني لـ FP2؛ نظام RAS على مستوى الشريحة لضمان الموثوقية | ذاكرة وحدة المعالجة المركزية Grace الموحدة؛ محرك فك الضغط لتحميل البيانات |
يتميز MI350X بذاكرة أكبر بنسبة 60% من B200 (192 جيجابايت) مع عرض نطاق ترددي مطابق. يتفوق على FP64/FP32 بحوالي ضعف واحد، وعلى FP1 بما يصل إلى 6 ضعف، وعلى دقة منخفضة بحوالي 1.2%. يتطابق الاستدلال أو يتجاوز بنسبة 10%، والتدريب مماثل أو متقدم بنسبة 30% أو أكثر في الضبط الدقيق لـ FP10 - كل ذلك بتكلفة أقل (8% زيادة في الرموز لكل دولار).
أيه إم دي غريزة MI350 OAM
يعتبر عامل شكل OAM مضغوطًا، مع لوحة دوائر مطبوعة سميكة تشبه MI325X.

AMD Instinct MI350 UBB
هذه هي حزمة MI350 OAM المثبتة في UBB إلى جانب سبع وحدات معالجة رسومية أخرى بإجمالي ثماني وحدات.

AMD Instinct MI350 على وحدة معالجة الرسومات UBB 8 بدون تبريد 2
وهنا زاوية أخرى لذلك.

AMD Instinct MI350 على وحدة معالجة الرسومات UBB 8 بدون تبريد 1
إليكم نظرة على UBB بالكامل مع تثبيت ثماني وحدات معالجة رسومية.

وحدة معالجة الرسومات AMD Instinct MI350 UBB 8 بدون تبريد
إنها تشبه إلى حد كبير لوحة AMD Instinct MI325X من الجيل السابق، وهذه هي النقطة.

AMD Instinct MI350 على وحدة معالجة الرسومات UBB 8 بدون تبريد 3
على أحد الأطراف، لدينا موصلات UBB ومبدد الحرارة لمؤقتات PCIe.

أجهزة إعادة ضبط الوقت AMD Instinct MI350X UBB PCIe
هناك أيضًا SMC للإدارة.

AMD Instinct MI350 SMC
إلى جانب اللوحة نفسها، هناك أيضًا التبريد.
تبريد الهواء AMD Instinct MI350X
هذه وحدة OAM مزودة بمشتت حراري كبير لتبريد الهواء. هذا المبرد هو AMD Instinct MI350X.

مبرد AMD Instinct MI350X
إليكم ثمانية منها على UBB. هذا مشابه لما رأيناه أعلاه، ولكن مع ثمانية عوازل حرارية كبيرة.

وحدة معالجة الرسومات AMD Instinct MI350X UBB 8
وهنا منظر آخر لمبددات الحرارة من جانب SMC والمقبض.

ملف تعريف المشتت الحراري لوحدة معالجة الرسومات AMD Instinct MI350X UBB 8
للحصول على بعض المعلومات، إليك UBB الخاص بـ AMD MI300X:

AMD MI300X 8 GPU OAM UBB 1
وتتوفر لدى AMD أيضًا نسخة MI355X المبردة بالسائل من هذه البطاقة والتي تسمح بمعدل TDP أعلى وأداء أعلى لكل بطاقة.
خوادم الذكاء الاصطناعي من سلسلة AMD MI350
تشمل قائمة الشركاء شركة Supermicro (4U/2U مبردة بالسائل، ما يصل إلى ثمانية MI355X)، وCompal (7U، ما يصل إلى ثمانية)، وASRock (4U، ثمانية MI355X).
نشر رفوف MI350
الحد الأقصى للعقدة الواحدة هو ثماني بطاقات (ذاكرة ٢٣٠٤ جيجابايت، ما يصل إلى ١٦١ بي فلوب في الثانية لمعياري FP2,304/FP161). التبريد الهوائي يتسع لـ ٦٤ بطاقة، والتبريد السائل لـ ١٢٨ بطاقة. يوفر إعداد ١٢٨ بطاقة ذاكرة سعة ٣٦ تيرابايت وما يصل إلى ٢.٥٧ بي فلوب في الثانية لمعياري FP6/FP4.
الاستنتاج: ثورة التبريد السائل من AMD
تُبرز سلسلة معالجات MI350 من AMD ومجموعة معالجات TensorWave تحولاً محورياً في مجال تبريد السوائل بالذكاء الاصطناعي، مما يُمثل تحدياً للاحتكارات ويُعزز الكفاءة. ومع تزايد متطلبات الذكاء الاصطناعي، تُبشر هذه الابتكارات بتوفير التكاليف وقابلية التوسع.
فايبر مول على أتم الاستعداد لدعم بنيتكم التحتية للذكاء الاصطناعي بحلول اتصالات بصرية عالية الجودة. تفضلوا بزيارة موقعنا الإلكتروني أو تواصلوا مع خدمة العملاء للحصول على نصائح مخصصة.
المنتجات ذات الصلة:
-
 أجهزة إرسال واستقبال بصرية OSFP-400GF-MPO1M 400G OSFP SR4 MPO-12 قابس أنثى ضفيرة 1 متر تبريد سائل غاطس
$1950.00
أجهزة إرسال واستقبال بصرية OSFP-400GF-MPO1M 400G OSFP SR4 MPO-12 قابس أنثى ضفيرة 1 متر تبريد سائل غاطس
$1950.00
-
 أجهزة إرسال واستقبال بصرية OSFP-400GM-MPO1M 400G OSFP SR4 MPO-12 قابس ذكر ضفيرة 1 متر تبريد سائل غمر
$1950.00
أجهزة إرسال واستقبال بصرية OSFP-400GM-MPO1M 400G OSFP SR4 MPO-12 قابس ذكر ضفيرة 1 متر تبريد سائل غمر
$1950.00
-
 أجهزة إرسال واستقبال بصرية OSFP-400GF-MPO3M 400G OSFP SR4 MPO-12 قابس أنثى ضفيرة 3 متر تبريد سائل غاطس
$1970.00
أجهزة إرسال واستقبال بصرية OSFP-400GF-MPO3M 400G OSFP SR4 MPO-12 قابس أنثى ضفيرة 3 متر تبريد سائل غاطس
$1970.00
-
 أجهزة إرسال واستقبال بصرية OSFP-400GM-MPO3M 400G OSFP SR4 MPO-12 قابس ذكر ضفيرة 3 متر تبريد سائل غمر
$1970.00
أجهزة إرسال واستقبال بصرية OSFP-400GM-MPO3M 400G OSFP SR4 MPO-12 قابس ذكر ضفيرة 3 متر تبريد سائل غمر
$1970.00
-
 أجهزة إرسال واستقبال بصرية OSFP-400GF-MPO60M 400G OSFP SR4 MPO-12 قابس أنثى ضفيرة 60 متر تبريد سائل غاطس
$2025.00
أجهزة إرسال واستقبال بصرية OSFP-400GF-MPO60M 400G OSFP SR4 MPO-12 قابس أنثى ضفيرة 60 متر تبريد سائل غاطس
$2025.00
-
 أجهزة إرسال واستقبال بصرية OSFP-400GM-MPO60M 400G OSFP SR4 MPO-12 قابس ذكر ضفيرة 60 متر تبريد سائل غمر
$2025.00
أجهزة إرسال واستقبال بصرية OSFP-400GM-MPO60M 400G OSFP SR4 MPO-12 قابس ذكر ضفيرة 60 متر تبريد سائل غمر
$2025.00
-
 أجهزة إرسال واستقبال بصرية OSFP-800G85F-MPO60M 800G OSFP SR8 MPO-12 قابس أنثى ضفيرة 60 متر تبريد سائل غاطس
$2400.00
أجهزة إرسال واستقبال بصرية OSFP-800G85F-MPO60M 800G OSFP SR8 MPO-12 قابس أنثى ضفيرة 60 متر تبريد سائل غاطس
$2400.00
-
 أجهزة إرسال واستقبال بصرية OSFP-800G85M-MPO60M 800G OSFP SR8 MPO-12 قابس ذكر ضفيرة 60 أمتار تبريد سائل غاطس
$2400.00
أجهزة إرسال واستقبال بصرية OSFP-800G85M-MPO60M 800G OSFP SR8 MPO-12 قابس ذكر ضفيرة 60 أمتار تبريد سائل غاطس
$2400.00
-
 أجهزة إرسال واستقبال بصرية OSFP-800G85F-MPO5M 800G OSFP SR8 MPO-12 قابس أنثى ضفيرة 5 متر تبريد سائل غاطس
$2330.00
أجهزة إرسال واستقبال بصرية OSFP-800G85F-MPO5M 800G OSFP SR8 MPO-12 قابس أنثى ضفيرة 5 متر تبريد سائل غاطس
$2330.00
-
 أجهزة إرسال واستقبال بصرية OSFP-800G85M-MPO5M 800G OSFP SR8 MPO-12 قابس ذكر ضفيرة 5 أمتار تبريد سائل غاطس
$2330.00
أجهزة إرسال واستقبال بصرية OSFP-800G85M-MPO5M 800G OSFP SR8 MPO-12 قابس ذكر ضفيرة 5 أمتار تبريد سائل غاطس
$2330.00
-
 أجهزة إرسال واستقبال بصرية OSFP-800G85F-MPO1M 800G OSFP SR8 MPO-12 قابس أنثى ضفيرة 1 متر تبريد سائل غاطس
$2250.00
أجهزة إرسال واستقبال بصرية OSFP-800G85F-MPO1M 800G OSFP SR8 MPO-12 قابس أنثى ضفيرة 1 متر تبريد سائل غاطس
$2250.00
-
 أجهزة إرسال واستقبال بصرية OSFP-800G85M-MPO1M 800G OSFP SR8 MPO-12 قابس ذكر ضفيرة 1 أمتار تبريد سائل غاطس
$2250.00
أجهزة إرسال واستقبال بصرية OSFP-800G85M-MPO1M 800G OSFP SR8 MPO-12 قابس ذكر ضفيرة 1 أمتار تبريد سائل غاطس
$2250.00