
Five years later, the globally renowned AI computing technology event, the annual NVIDIA GTC conference, made a significant return to in-person format. Today, NVIDIA’s founder and CEO, Jensen Huang, delivered a two-hour keynote speech unveiling the latest groundbreaking AI chip – the Blackwell GPU.

During this conference, NVIDIA showcased an impressive industry influence by bringing together top AI experts and industry leaders. The event witnessed an unprecedented turnout with over ten thousand in-person attendees.

On March 18th at 1:00 PM local time (4:00 AM on March 19th in Beijing), the most anticipated keynote speech of GTC officially commenced. Following an AI-themed short film, Jensen Huang made his entrance onto the main stage wearing his iconic black leather jacket, engaging with the audience.
He began by reflecting on NVIDIA’s 30-year journey in accelerating computing, highlighting milestones such as developing the revolutionary CUDA computing model, delivering the first AI supercomputer DGX to OpenAI, and then naturally shifting focus to generative AI.
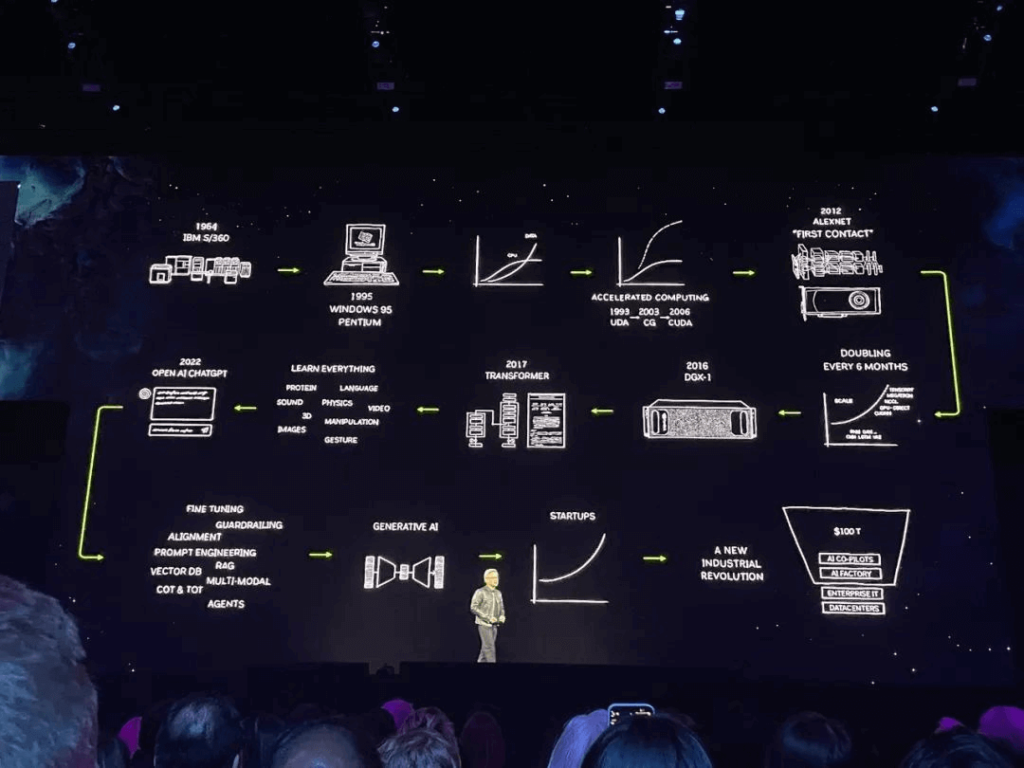
After announcing important partnerships with leading EDA companies, he discussed the rapid evolution of AI models driving a surge in training computational power demand, emphasizing the need for larger GPUs. He stated that “accelerated computing has reached a critical point, and general-purpose computing has lost its momentum,” highlighting significant advancements in accelerated computing across various industries. Subsequently, a series of key components from GPUs and super chips to supercomputers and cluster systems flashed rapidly on the big screen before Jensen Huang made the major announcement: the all-new flagship AI chip – Blackwell GPU has arrived!

This latest innovation in the GPU field surpasses its predecessor Hopper GPU in both configuration and performance. Jensen Huang compared Blackwell and Hopper GPUs, showcasing Blackwell’s significantly larger size. Following this comparison, he humorously reassured Hopper saying, “It’s OK, Hopper. You’re very good, good boy. Good girl.” The performance of Blackwell is indeed exceptional! Whether it’s FP8 or the new FP6 and FP4 precision, along with the model scale and HBM bandwidth that can accommodate – all surpassing the previous Hopper generation.

Over 8 years from Pascal architecture to Blackwell architecture, NVIDIA has increased AI computing performance by 1000 times!
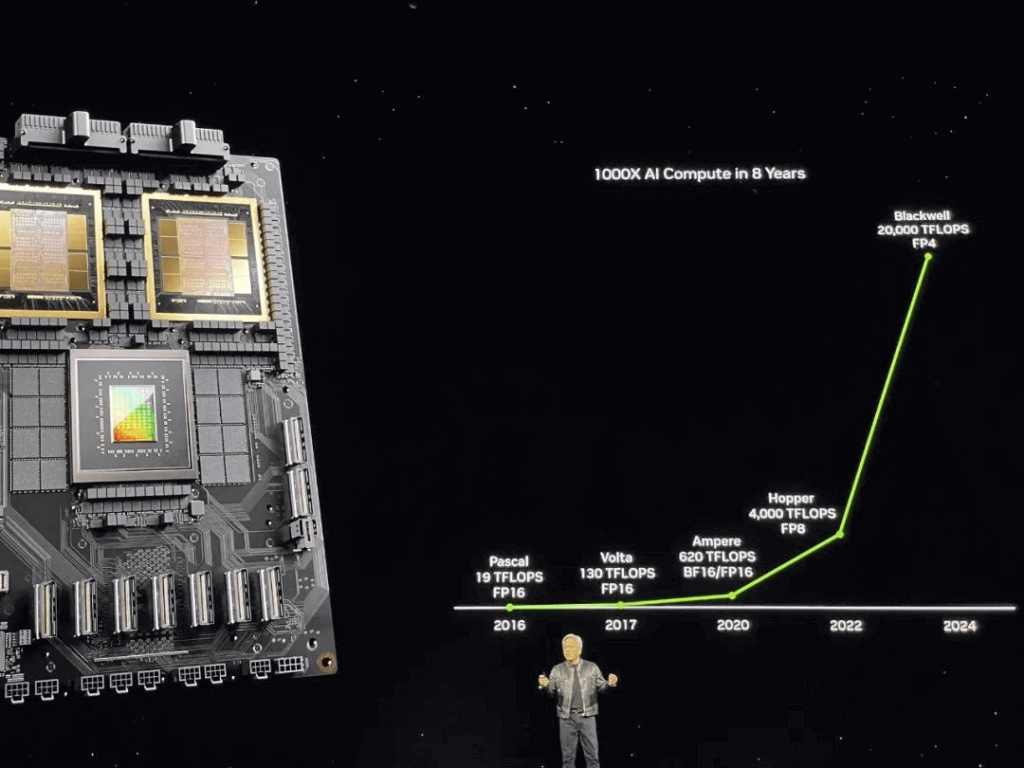
This is just the beginning as Jensen Huang’s true ambition lies in creating the most powerful AI infrastructure capable of optimizing trillion-parameter level GPU computations. Overall, NVIDIA unveiled six major announcements at this year’s GTC conference:
- Introduction of Blackwell GPU: Training performance increased by 2.5 times, FP4 precision inference performance enhanced by 5 times compared to previous FP8; upgraded fifth-generation NVLink with interconnect speed twice that of Hopper’s speed; scalable up to 576 GPUs to address communication bottlenecks in trillion-parameter mixed-expert models.
- Introduction of Blackwell Architecture: Optimized for trillion-parameter level GPU computations; launched new X800 series network switches with throughput up to 800Gb/s; introduced GB200 super chip, GB200 NVL72 system, DGX B200 system, and next-generation DGX SuperPOD AI supercomputer.

- Release of dozens of enterprise generative AI microservices providing a new way to package and deliver software for easy deployment of custom AI models using GPUs.
- Announcement of breakthrough lithography computation platform cuLitho by TSMC and Synopsys: cuLitho accelerates lithography computation by 40-60 times using enhanced generative AI algorithms to provide significant support for developing 2nm and more advanced processes.
- Launch of humanoid robot base model Project GR00T and new humanoid robot computer Jetson Thor; significant upgrades to Isaac robot platform driving embodied intelligence advancements. Jensen Huang also interacted with a pair of small NVIDIA robots from Disney Research.
- Collaboration with Apple to integrate Omniverse platform into Apple Vision Pro and provide Omniverse Cloud API for industrial digital twin software tools.
AI Chip New Emerges: 20.8 Billion Transistors, 2.5x Training Performance, 5x Inference Performance
Entering a new era of generative AI, the explosive growth in AI computing demands has led to the emergence of Blackwell GPU, surpassing its predecessor Hopper GPU as the focal point of AI competition. Each generation of NVIDIA GPU architecture is named after a scientist, and the new architecture, Blackwell, pays tribute to David Blackwell, the first African American member of the National Academy of Sciences and a distinguished statistician and mathematician. Blackwell was known for simplifying complex problems and his independent inventions like “dynamic programming” and “renewal theorem” have had wide applications across various scientific and engineering fields.

Huang stated that generative AI is the defining technology of this era, with Blackwell being the engine driving this new industrial revolution. The Blackwell GPU boasts six core technologies:
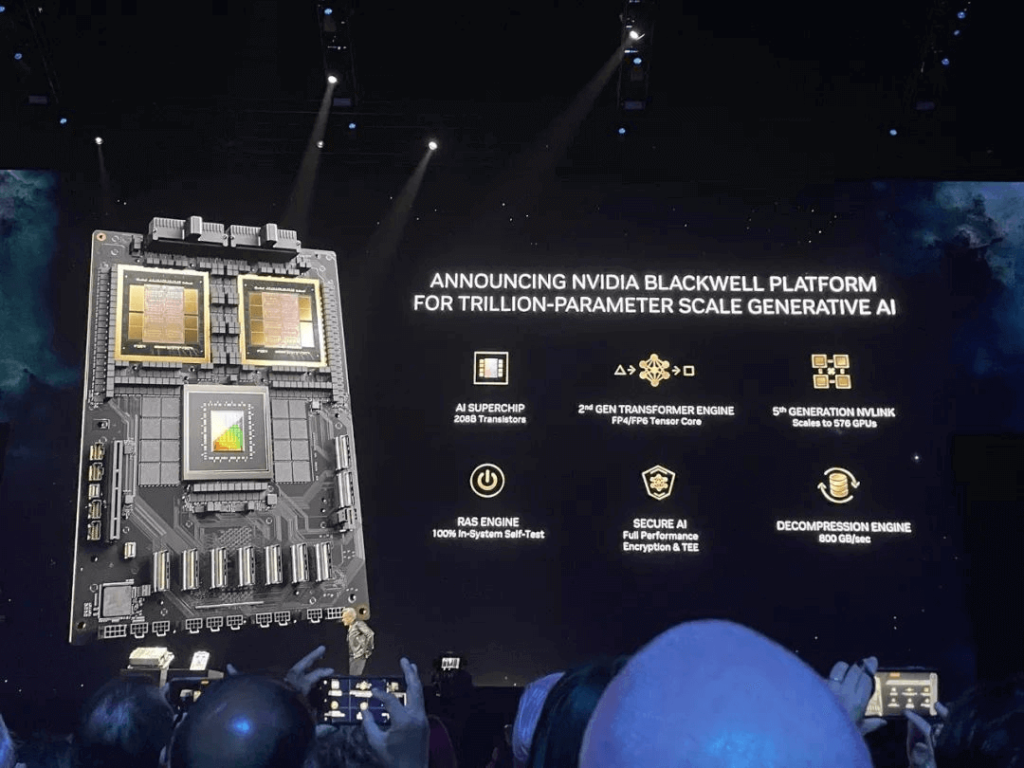
- Dubbed the “World’s Most Powerful Chip”: integrates 20.8 billion transistors using a custom TSMC 4NP process, following the concept of “chiplet” design with unified memory architecture + dual-core configuration, connecting two GPUs dies limited by lithography templates through a 10TB/s inter-chip NVHyperfuse interface to form a unified GPU with 192GB HBM3e memory, 8TB/s memory bandwidth, and single-card AI training power up to 20PFLOPS.

Compared to the previous Hopper generation, Blackwell’s integration of two dies results in a larger size with an additional 12.8 billion transistors compared to the Hopper GPU. In contrast, the previous H100 had only 80GB HBM3 memory and 3.35TB/s bandwidth, while the H200 featured 141GB HBM3e memory and 4.8TB/s bandwidth.
- Second-Generation Transformer Engine: combining new micro-tensor scaling support and advanced dynamic range management algorithms with TensorRT-LLM and NeMo Megatron frameworks to equip Blackwell with AI inference capabilities at FP4 precision, supporting double computation and model scale while maintaining high accuracy for mixed-expert models.

Under the new FP4 precision, Blackwell GPU’s AI performance reaches five times that of Hopper. NVIDIA has not disclosed the performance of its CUDA cores; more details about the architecture are yet to be revealed.

- Fifth-Generation NVLink: To accelerate performance for trillion-parameter and mixed-expert models, the new NVLink provides each GPU with a bidirectional bandwidth of 1.8TB/s, supporting seamless high-speed communication among up to 576 GPUs suitable for complex large language models.

A single NVLink Switch chip comprises 50 billion transistors using the TSMC 4NP process, connecting four NVLinks at 1.8TB/s.

- RAS Engine: Blackwell GPU includes a dedicated engine ensuring reliability, availability, and maintainability while incorporating chip-level features utilizing AI-based predictive maintenance for diagnosing and predicting reliability issues to maximize system uptime, enhance scalability for large-scale AI deployments running continuously for weeks or even months without interruption, reducing operational costs.
- Secure AI: Advanced confidential computing capabilities protect AI models and customer data without compromising performance supporting new local interface encryption protocols.
- Decompression Engine: Supporting the latest formats to accelerate database queries providing top performance for data analysis and data science tasks. AWS, Dell, Google, Meta, Microsoft, OpenAI, Oracle, Tesla, xAI are all set to adopt Blackwell products. Tesla and xAI’s CEO Musk bluntly stated: “Currently in the field of AI, there is nothing better than NVIDIA hardware.”
Notably different from emphasizing single-chip performance in the past releases, the Blackwell series focuses more on overall system performance with a blurred distinction in GPU code names where most are collectively referred to as “Blackwell GPU.” According to market rumors before this release, B100 may be priced around $30,000 while B200 could be around $35,000; considering this pricing strategy where prices have increased by less than 50% compared to previous generations but training performance has improved by 2.5 times indicating significantly higher cost-effectiveness. If pricing remains relatively stable with such modest increases in price but substantial improvements in training performance; the market competitiveness of Blackwell series GPUs will be formidable.
Introduction of New Network Switches and AI Supercomputers Optimized for Trillion-Parameter-Level GPU Computing
The Blackwell platform, in addition to the foundational HGX B100, includes the NVLink Switch, GB200 superchip compute nodes, and X800 series network switches.

Among these, the X800 series is a newly designed network switch tailored for large-scale AI operations, aimed at supporting trillion-parameter-level generative AI tasks. NVIDIA’s Quantum-X800 InfiniBand network and Spectrum-X800 Ethernet are among the world’s first end-to-end platforms with throughput capabilities of up to 800Gb/s, boasting a 5x increase in exchange bandwidth capacity over previous-generation products. The network’s computational power has been enhanced by 9x through NVIDIA’s fourth-generation SHARP technology, resulting in a network computational performance of 14.4TFLOPS. Early adopters include Microsoft Azure, Oracle Cloud Infrastructure, and Coreweave, among others.

The Spectrum-X800 platform is specifically designed for multi-tenant, enabling performance isolation for each tenant’s AI workloads, thereby optimizing network performance for generative AI cloud services and large enterprise users. NVIDIA offers a comprehensive software solution including network acceleration communication libraries, software development kits, and management software. The GB200 Grace Blackwell superchip is designed as a processor for trillion-parameter-scale generative AI tasks. This chip connects two Blackwell GPUs to one NVIDIA Grace CPU using the 900GB/s fifth-generation NVLink-C2C interconnect technology. However, NVIDIA has not specified the exact model of the Blackwell GPU.

Huang showcased the GB200 superchip, highlighting it as the first of its kind to accommodate such high computational density in a compact space, emphasizing its interconnected memory and collaborative application development akin to a “happy family.”

Each GB200 superchip compute node can house two GB200 superchips. A single NVLink switch node can support two NVLink switches, achieving a total bandwidth of 14.4TB/s.

A Blackwell compute node comprises two Grace CPUs and four Blackwell GPUs, delivering AI performance of 80PFLOPS.

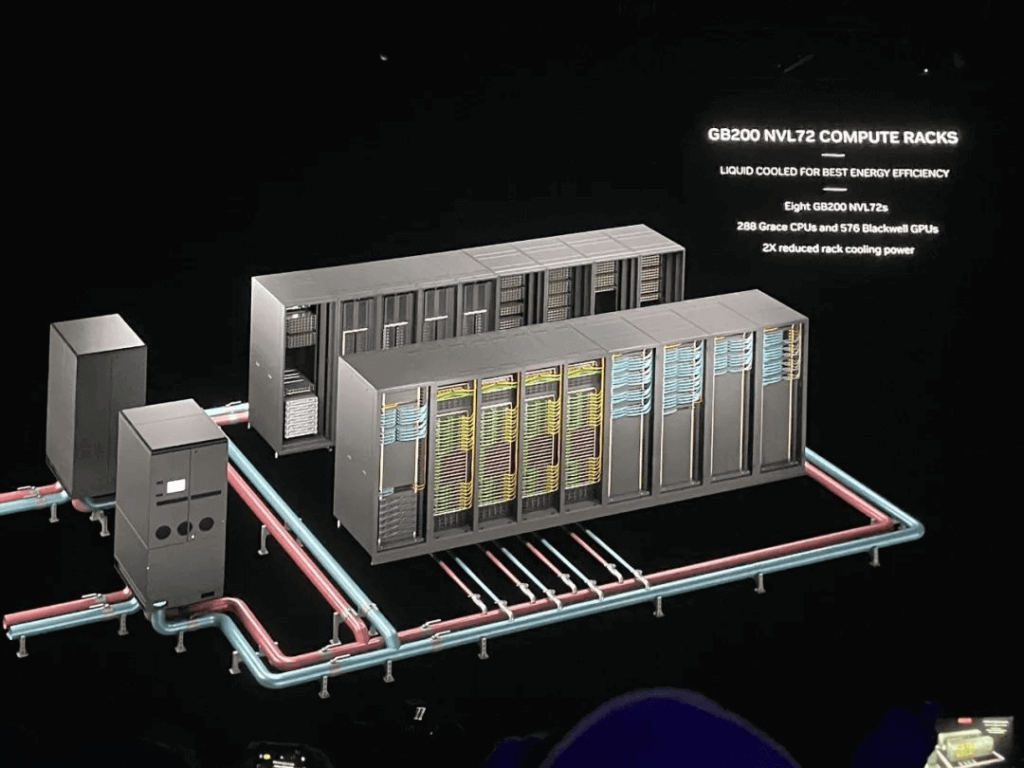
With enhanced GPU and network capabilities, Huang announced the launch of a new computing unit – the NVIDIA GB200 NVL72 – featuring multi-node architecture, liquid cooling, and rack-level systems.

The GB200 NVL72 functions like a “giant GPU,” operating similarly to a single-card GPU but with AI training performance reaching 720PFLOPS and AI inference performance peaking at 1.44EFLOPS. It boasts 30TB of fast memory and can handle large language models with up to 27 trillion parameters, serving as a key component in the latest DGX SuperPOD.

The GB200 NVL72 can be configured with 36*GB200 superchips (comprising 72*B200 GPUs and 36*Grace CPUs), interconnected via fifth-generation NVLink technology and including BlueField-3 DPU.

Jensen Huang noted that globally there are only a few EFLOPS-level machines currently available; this machine consists of 600,000 parts weighing 3000 pounds and represents an “EFLOPS AI system within a single rack.” He shared that previously training GPT-MoE-1.8T models with H100 required 90 days and approximately 8000 GPUs consuming 15MW of power; whereas now using GB200 NVL72 only requires 2000 GPUs and 4MW of power.

For trillion-parameter model runs, the GB200 has undergone multidimensional optimizations resulting in individual GPU token throughput rates up to 30 times that of H200 FP8 precision.
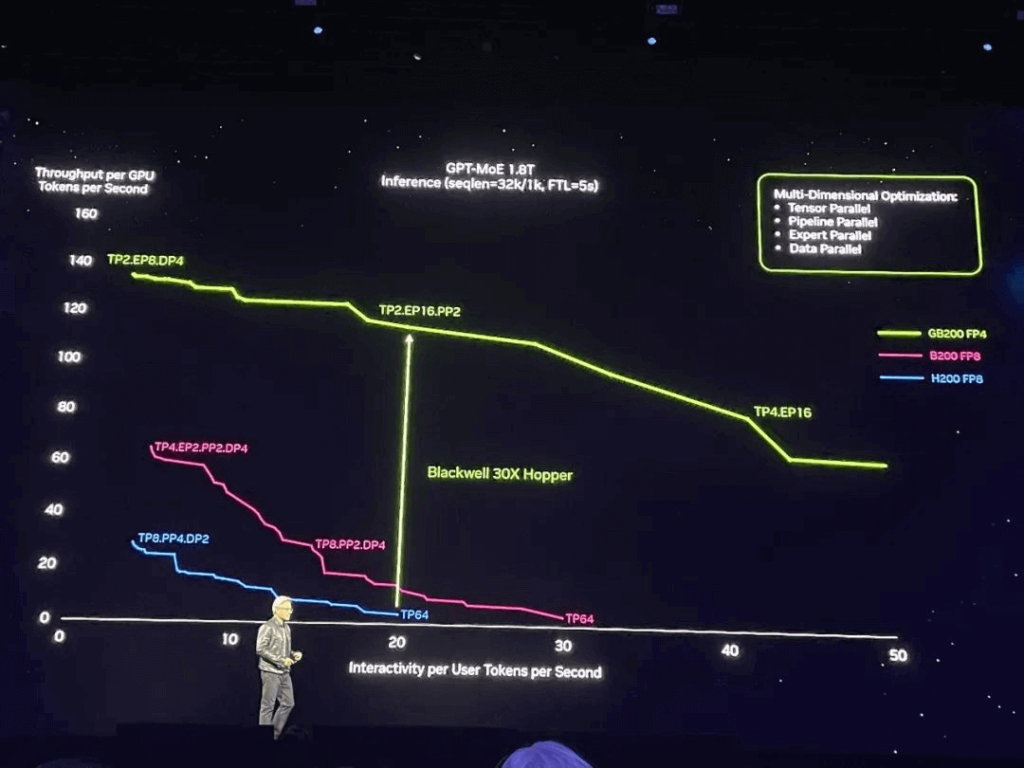
In terms of large language model inference tasks, the GB200 NVL72 delivers a 30x performance boost compared to the same number of H100s, at 1/25 the cost and power consumption of its predecessor.
Major cloud providers such as AWS, Google Cloud, Microsoft Azure, and Oracle Cloud Infrastructure among others support access to the GB200 NVL72. Additionally, NVIDIA has introduced the DGX B200 system – a unified AI supercomputing platform for AI model training, fine-tuning, and inference tasks. The DGX B200 system represents the sixth generation in the DGX series featuring a traditional rack-mounted design with air cooling; it includes eight B200 GPUs and two fifth-generation Intel Xeon processors delivering 144PFLOPS AI performance at FP4 precision along with a massive 1.4TB GPU memory capacity and 64TB/s memory bandwidth enabling real-time inference speeds for trillion-parameter models up to fifteen times faster than its predecessor. The system incorporates advanced networking with eight ConnectX-7 NICs and two BlueField-3 DPUs providing each connection with bandwidth up to 400Gb/s facilitating higher AI performance through Quantum-2 InfiniBand and Spectrum-X Ethernet platforms. NVIDIA has also introduced the next-generation data center-grade AI supercomputer – DGX SuperPOD utilizing DGX GB200 systems capable of handling trillion-parameter models ensuring continuous operation for large-scale generative AI training and inference workloads. Constructed from eight or more DGX GB200 systems, this new generation DGX SuperPOD features an efficient liquid-cooled rack-level expansion architecture delivering an AI computational power of 11.5EFLOPS at FP4 precision along with 240TB fast memory storage which can be further expanded through rack-level enhancements. Each DGX GB200 system houses thirty-six GB200 superchips. Compared to H100 units running large language model inference tasks, the GB200 superchip offers up to a forty-fivefold increase in performance.
Huang envisions data centers as future “AI factories”, with the entire industry gearing up for Blackwell’s advancements.

Launch of Dozens of Enterprise-Level Generative AI Microservices for Customization and Deployment of Copilots
NVIDIA continues to expand its advantages built on CUDA and the generative AI ecosystem by introducing dozens of enterprise-level generative AI microservices. These services enable developers to create and deploy generative AI Copilots on NVIDIA CUDA GPU installations.
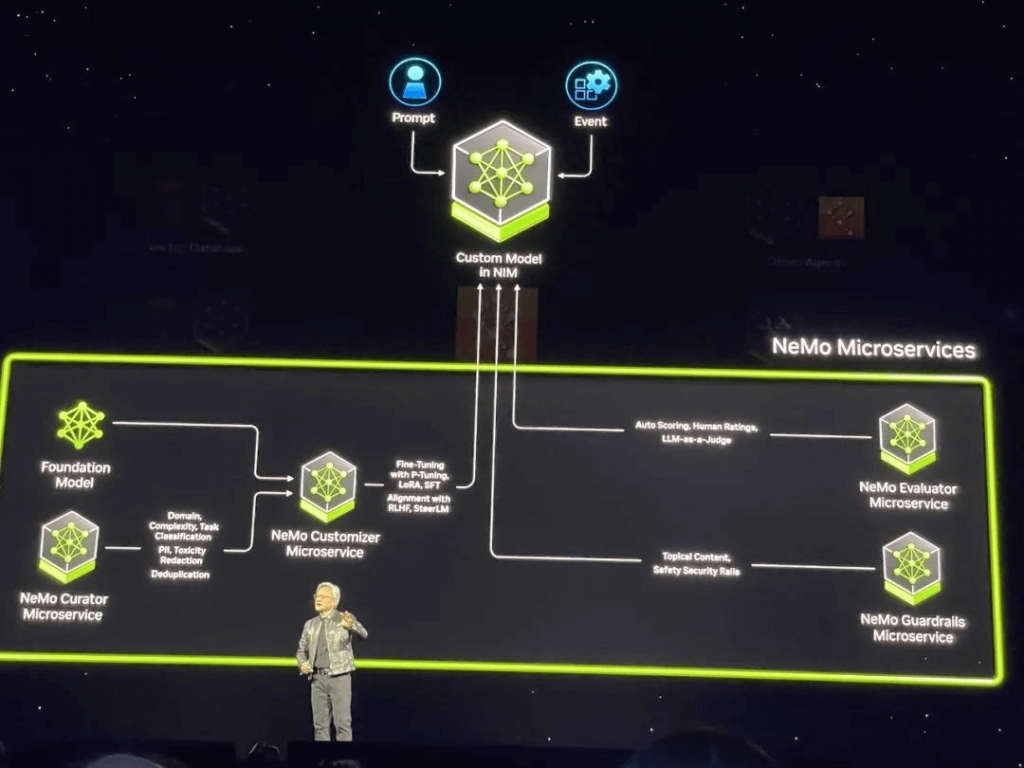
Huang stated that generative AI is transforming the way applications are programmed, shifting from writing software to assembling AI models, specifying tasks, providing work product examples, reviewing plans, and intermediate results. NVIDIA NIM serves as a reference for NVIDIA’s inference microservices, constructed from NVIDIA’s accelerated computing libraries and generative AI models. These microservices support industry-standard APIs, operate on NVIDIA’s large-scale CUDA installations, and are optimized for new GPUs.
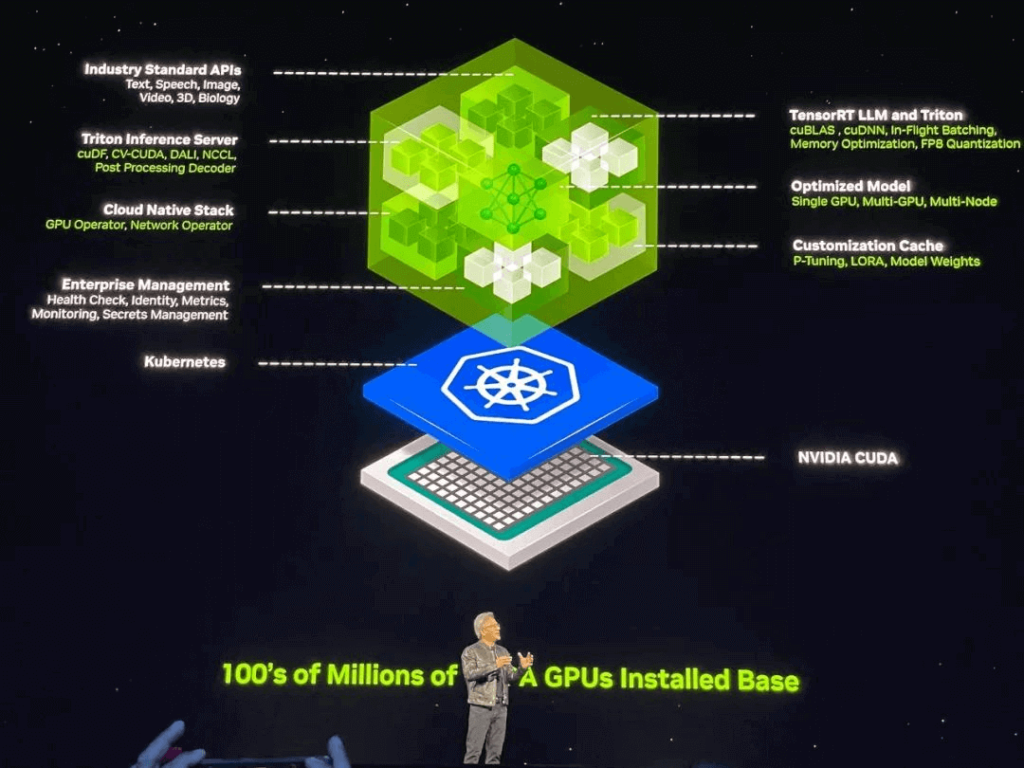
Businesses can utilize these microservices to create and deploy custom applications on their platforms while retaining complete ownership and control over their intellectual property. NIM microservices offer pre-built production AI containers supported by NVIDIA’s inference software, enabling developers to reduce deployment times from weeks to minutes. NIM microservices can deploy models from NVIDIA, AI21, Adept, Cohere, Getty Images, and Shutterstock, as well as open models from Google, Hugging Face, Meta, Microsoft, Mistral AI, and Stability AI.
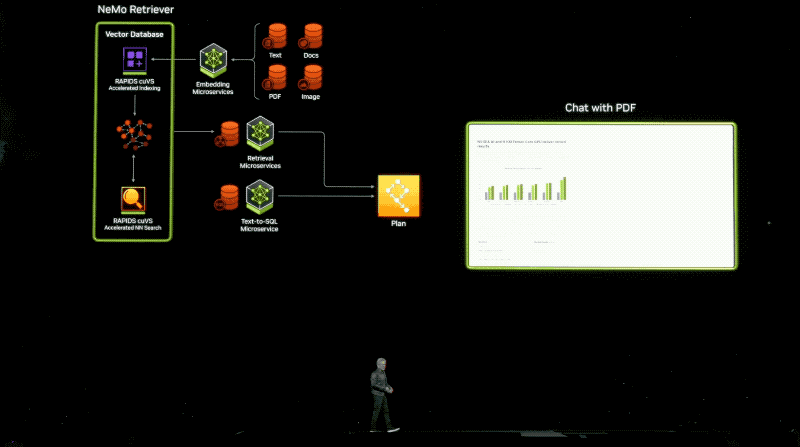
Users will have access to NIM microservices from Amazon SageMaker, Google Kubernetes Engine, and Microsoft Azure AI, integrated with popular AI frameworks like Deepset, LangChain, and LlamaIndex. To accelerate AI applications, businesses can leverage CUDA-X microservices including NVIDIA Riva for custom speech and translation AI, NVIDIA cuOpt for path optimization, NVIDIA Earth-2 for high-resolution climate and weather simulations. A series of NVIDIA NeMo microservices for custom model development is set to be released soon.
Developers can freely trial NVIDIA microservices at ai.nvidia.com. Enterprises can deploy production-grade NIM microservices using NVIDIA’s AI Enterprise 5.0 platform.
Advancing Generative AI Algorithms: Collaborating with Top Players in the Semiconductor Industry to Spark a New Revolution in Photolithography Computing
At last year’s GTC conference, NVIDIA unveiled a groundbreaking development after four years of secret research aimed at the semiconductor manufacturing industry: leveraging the revolutionary photolithography computing library cuLitho to accelerate photolithography computations by 40-60 times, surpassing the physical limits of producing 2nm and more advanced chips. The collaborators on this project are key players in the semiconductor industry – global AI chip giant NVIDIA, leading semiconductor foundry TSMC, and top EDA giant Synopsys.

Computational lithography is fundamental to chip manufacturing. Today, building upon the accelerated processes of cuLitho, the workflow speed has been further doubled through generative AI algorithms. Specifically, many changes in wafer fabrication processes require Optical Proximity Correction (OPC), increasing computational complexity and causing development bottlenecks. cuLitho’s accelerated computing and generative AI can alleviate these issues. Applying generative AI can create nearly perfect mask solutions or approaches to address light diffraction issues before deriving the final mask through traditional physically rigorous methods – thus speeding up the entire OPC process by 2 times. In chip manufacturing processes, computational lithography is the most intensive workload consuming billions of hours annually on CPUs. Compared to CPU-based methods, cuLitho’s GPU-accelerated photolithography computation significantly enhances chip manufacturing processes. By accelerating computations, 350 NVIDIA H100 systems can replace 40,000 CPU systems significantly boosting throughput rates, and speeding up production while reducing costs, space requirements, and power consumption. “We are deploying NVIDIA cuLitho at TSMC,” stated TSMC President Wei Zhejia highlighting the significant performance leap achieved through integrating GPU-accelerated computing into TSMC’s workflow. When testing cuLitho on shared workflows between the two companies they achieved a 45x acceleration in curve processes and nearly 60x improvement in traditional Manhattan processes.
Introduction of New Humanoid Robot Base Model and Computer: Isaac Robot Platform Major Update
In addition to generative AI, NVIDIA is also optimistic about embodied intelligence and has unveiled the humanoid robot universal base model Project GR00T and the new humanoid robot computer Jetson Thor based on the Thor SoC. Jensen Huang stated, “Developing a universal humanoid robot base model is one of the most exciting topics in the field of AI today.” Robots powered by GR00T can understand natural language, mimic rapid learning coordination, flexibility, and other skills by observing human behavior to adapt to and interact with the real world. Huang Renxun demonstrated how multiple such robots can complete various tasks.
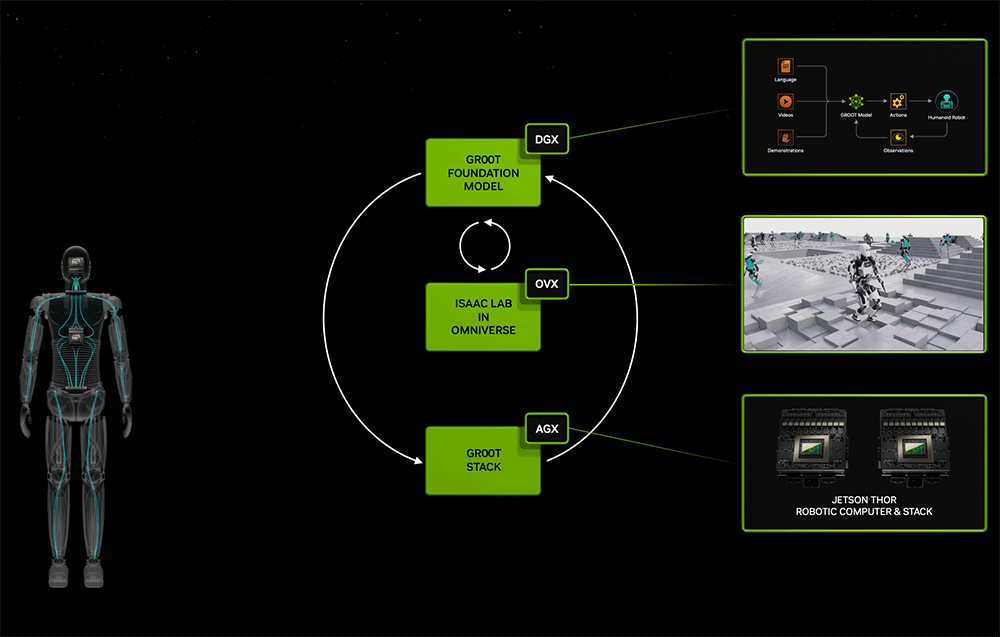
Jetson Thor features a modular architecture optimized for performance, power consumption, and size. This SoC includes a next-generation Blackwell GPU with a Transformer engine to run multimodal generative AI models like GR00T. NVIDIA is developing a comprehensive AI platform for leading humanoid robot companies such as 1X, Agility Robotics, Apptronik, Boston Dynamics, Figure AI, Fourier Intelligence, Sanctuary AI, Unitree Robotics, and XPENG Robotics.
Additionally, NVIDIA has made significant upgrades to the Isaac robot platform, including generative AI base models, simulation tools, and AI workflow infrastructure. These new features will be rolled out in the next quarter. NVIDIA has also released a range of pre-trained robot models, libraries, and reference hardware such as Isaac Manipulator for robotic arms with flexibility and modular AI capabilities, along with a series of base models and GPU-accelerated libraries like Isaac Perceptor offering advanced features like multi-camera setups, 3D reconstruction, and depth perception.
Omniverse Platform Latest Development: Advancing into Apple Vision Pro, Introducing Cloud API
NVIDIA has announced the integration of the Omniverse platform with Apple Vision Pro.

Targeting industrial digital twin applications, NVIDIA will offer Omniverse Cloud in the form of an API. Developers can utilize this API to stream interactive industrial digital twin content to VR headsets.
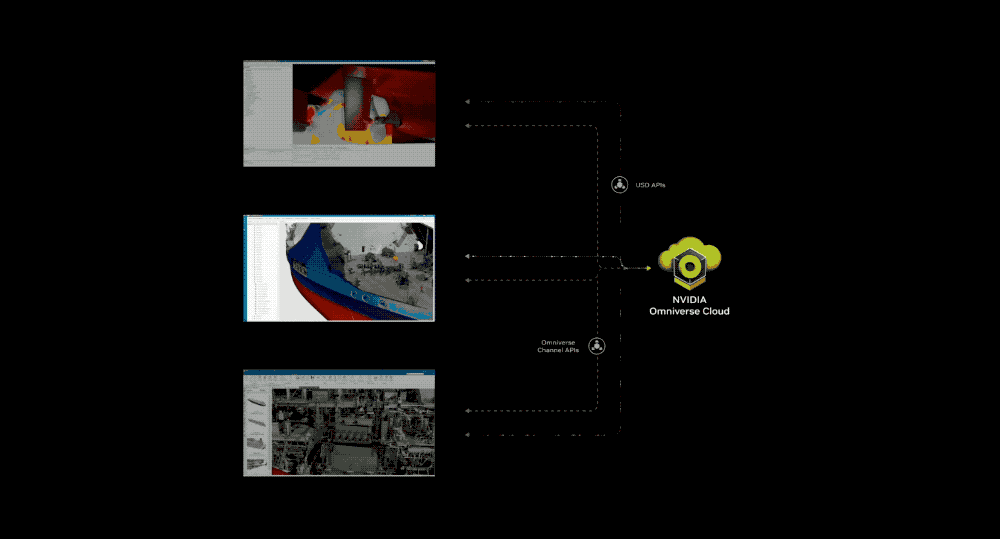
By leveraging the API, developers can easily integrate Omniverse’s core technology directly into existing digital twin design and automation software applications or into simulation workflows for testing and validating autonomous machines such as robots or self-driving cars. Jensen Huang believes that all manufactured products will have digital twins, and that Omniverse is an operating system that can build and operate physically realistic digital twins. He believes, “Omniverse and generative AI are both fundamental technologies needed to digitize a heavy industrial market worth up to $50 trillion.”
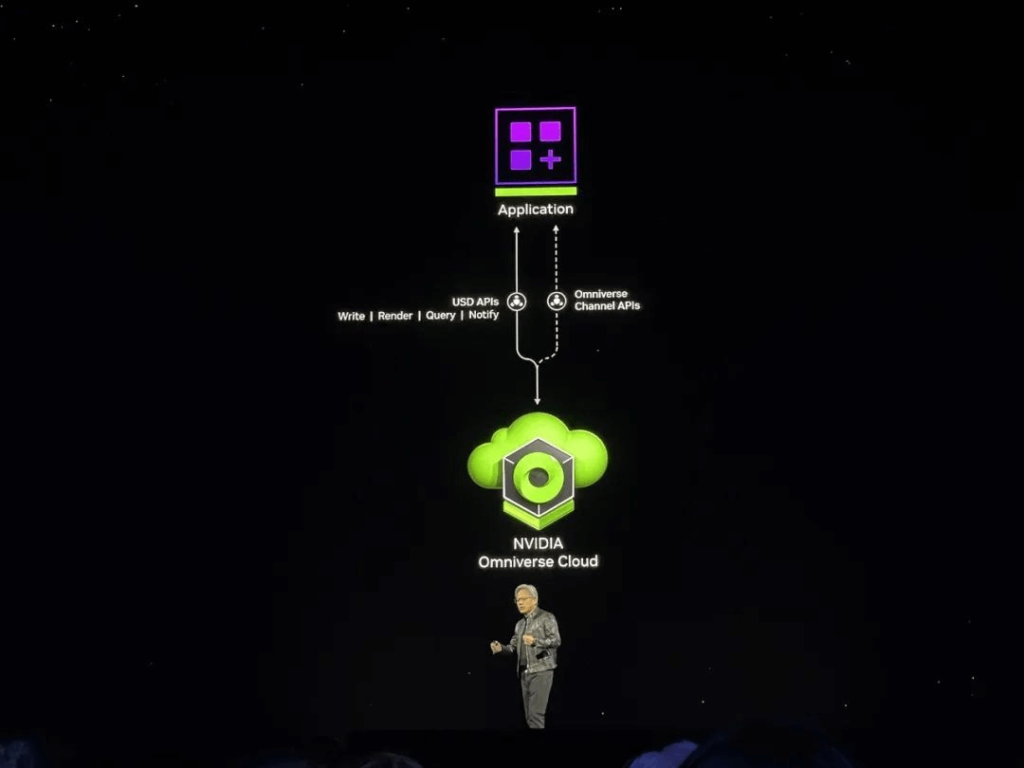
The five new Omniverse Cloud APIs can be used individually or in combination: USD Render (generates fully ray-traced RTX rendering of OpenUSD data), USD Write (enables users to modify and interact with OpenUSD data), USD Query (supports scene queries and interactive scenes), USD Notify (tracking USD changes and providing updates), and Omniverse Channel (connecting users, tools, and the world for cross-scene collaboration).
The Omniverse Cloud API will be available on Microsoft Azure later this year as a self-hosted API on NVIDIA A10 GPUs or as a hosted service deployed on NVIDIA OVX.
Conclusion: The Main Event Concludes but the Show Must Go On
In addition to the significant announcements mentioned above, Huang shared further developments during his speech: NVIDIA has launched a 6G research cloud platform driven by generative AI and Omniverse to advance wireless communication technology development in the telecommunications sector. NVIDIA’s Earth-2 climate digital twin cloud platform is now available for interactive high-resolution simulations to accelerate climate and weather forecasting. He believes that the greatest impact of AI will be in the healthcare. NVIDIA is already collaborating with imaging systems companies, genetic sequencer manufacturers, and leading surgical robotics companies while introducing a new type of biological software.

In the automotive industry, BYD, the world’s largest autonomous driving company, will equip its future electric vehicles with NVIDIA’s next-generation autonomous vehicle (AV) processor DRIVE Thor based on the Blackwell architecture. DRIVE Thor is expected to begin mass production as early as next year with performance reaching up to 1000 TFLOPS.
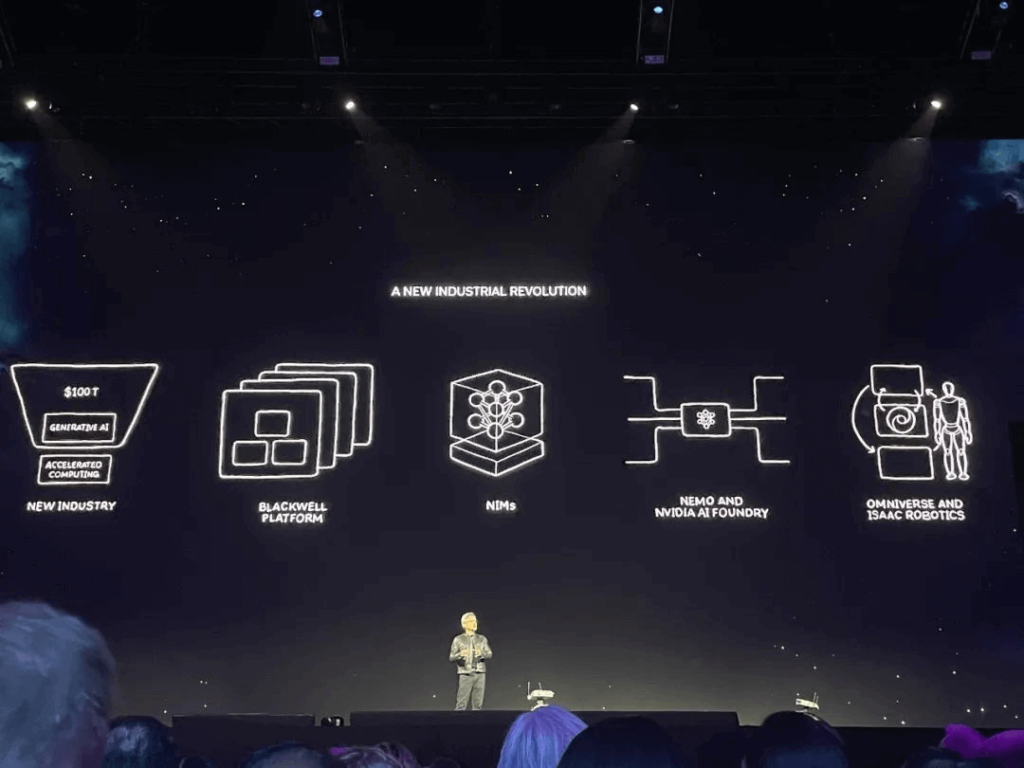
Huang stated: “NVIDIA’s essence lies at the intersection of computer graphics, physics, and artificial intelligence.” As his speech concluded, he outlined five key points: New Industry, Blackwell Platform, NIMs, NEMO and NVIDIA AI Foundry, Omniverse and Isaac Robotics.
Today marks another milestone where NVIDIA pushes the boundaries of AI hardware and software while presenting a feast around cutting-edge technologies such as AI, large models, metaverse, robots, autonomous driving, healthcare, and quantum computing.
Jensen Huang’s keynote was undoubtedly the highlight of the GTC conference, but the excitement was just kicking off for both on-site and remote attendees!
Over 1000 sessions covering NVIDIA’s latest advancements and hot topics in frontier technologies will unfold through speeches, training sessions, and roundtable discussions. Many attendees expressed frustration at not being able to attend all sessions due to time constraints but acknowledged the platform GTC 2024 provides for technical exchange in the AI industry. The release of new products during this period and sharing of technology are expected to have a positive impact on academic research and related industry chains. Further exploration into more technical details of the new Blackwell architecture awaits.
Related Products:
-
 OSFP-800G-FR4 800G OSFP FR4 (200G per line) PAM4 CWDM Duplex LC 2km SMF Optical Transceiver Module
$3500.00
OSFP-800G-FR4 800G OSFP FR4 (200G per line) PAM4 CWDM Duplex LC 2km SMF Optical Transceiver Module
$3500.00
-
OSFP-800G-2FR2L 800G OSFP 2FR2 (200G per line) PAM4 1291/1311nm 2km DOM Duplex LC SMF Optical Transceiver Module
$3000.00
-
OSFP-800G-2FR2 800G OSFP 2FR2 (200G per line) PAM4 1291/1311nm 2km DOM Dual CS SMF Optical Transceiver Module
$3000.00
-
OSFP-800G-DR4 800G OSFP DR4 (200G per line) PAM4 1311nm MPO-12 500m SMF DDM Optical Transceiver Module
$3000.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$700.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA MMS4X50-NM Compatible OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF Optical Transceiver Module
$1200.00
-
OSFP-XD-1.6T-4FR2 1.6T OSFP-XD 4xFR2 PAM4 1291/1311nm 2km SN SMF Optical Transceiver Module
$15000.00
-
OSFP-XD-1.6T-2FR4 1.6T OSFP-XD 2xFR4 PAM4 2x CWDM4 2km Dual Duplex LC SMF Optical Transceiver Module
$20000.00
-
OSFP-XD-1.6T-DR8 1.6T OSFP-XD DR8 PAM4 1311nm 2km MPO-16 SMF Optical Transceiver Module
$12000.00













