
NVIDIA’s Spectrum-X solution is the world’s first end-to-end Ethernet solution designed specifically for generative AI. This comprehensive solution includes several key components: the Spectrum-4 series switches, BlueField-3 SuperNICs, LinkX 800G/400G high-performance cable modules, and an integrated full-stack software solution with hardware acceleration capabilities. The true power of Spectrum-X lies in the tight integration of both hardware and software; using any single part in isolation does not fully showcase its maximum efficiency.

Today, many leading chip manufacturers have launched switch chips designed for AI and machine learning (ML) applications, with single-chip throughput reaching up to 51.2 Tbps. While traditional data center switch chips can be used in AI scenarios, they struggle with efficiency when handling AI traffic focused on training and inference.
Let’s delve into why traditional Ethernet faces limitations with AI-specific traffic models, primarily due to load imbalance, higher latency and jitter, and poor congestion control.
ECMP Load Imbalance Issue
Traditional Ethernet data centers primarily handle applications such as web browsing, music and video streaming, and everyday office tasks. These applications typically involve small, numerous data flows (referred to as “flows”) that are randomly distributed, making them well-suited to multipath load balancing techniques based on hash algorithms (ECMP), which ensure network bandwidth is used evenly.
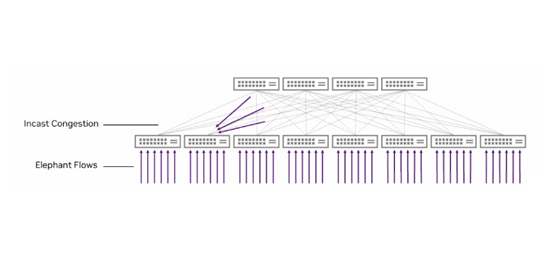
In AI model training, however, the models, parameters, GPUs, CPUs, and NICs are closely coupled. The network traffic mainly consists of high-bandwidth collective operations like all-reduce and all-to-all. Typically, each GPU is paired with a high-bandwidth NIC, and each NIC establishes a relatively small number of flow connections during each training process. These flows are significant enough to quickly consume the entire NIC bandwidth—referred to as “elephant flows.”
Due to the nature of elephant flows, they may concentrate on specific network paths due to hash algorithms, leading to severe overload on these paths while others remain underutilized. This unbalanced traffic distribution makes traditional ECMP-based load balancing methods ineffective, thereby impacting overall training efficiency.
Issues of High Latency and Jitter
Traditional Ethernet applications rely on TCP/IP socket programming, where the CPU must copy user data from user space to kernel space, then from kernel space to the network card driver for processing and transmission to the receiver. This process increases latency and adds to the CPU workload. To address these issues, modern AI computing clusters use lossless networks supporting Remote Direct Memory Access (RDMA) technology, such as InfiniBand or RDMA over Converged Ethernet (RoCE). These technologies reduce application data transmission latency significantly by bypassing the kernel (kernel bypass) and using zero-copy mechanisms.
In AI training scenarios, technologies like GPU Direct RDMA and GPU Direct Storage enable direct data exchange between GPU memory or between GPU memory and storage via RDMA. This reduces GPU memory data transmission latency to a tenth of the original. Additionally, the NVIDIA Collective Communications Library (NCCL) seamlessly supports RDMA interfaces, greatly simplifying the transition from TCP to RDMA frameworks for AI applications.
When training large models with hundreds of millions of parameters, we often disassemble data and models for parallel processing to enhance efficiency. In this process, thousands of GPUs work together in complex, multidimensional parallel and cross-structured configurations, continuously exchanging parameters and summarizing computational results. Ensuring each step of this distributed parallel training process is efficient and stable is critical. Any single GPU failure or increased latency in node-to-node communication can bottleneck the entire training process. This increased latency not only extends the overall training time but also negatively impacts the speed improvement (training acceleration ratio) and final outcomes. Therefore, AI training requires networks with lower latency and better link quality.
Poor Network Congestion Control Issues
In distributed parallel training, “incast” traffic spikes, where multiple sources send data to a single receiver, often cause network congestion. Traditional Ethernet follows a best-effort service model, making it difficult to avoid buffer overflow and packet loss, even with good end-to-end quality of service (QoS). Typically, upper-layer protocols use retransmission mechanisms to mitigate the effects of packet loss. For Ethernet supporting RDMA, achieving zero packet loss is crucial.
To meet this goal, two key technologies are widely adopted: hop-by-hop flow control mechanisms and congestion control mechanisms for “incast” traffic. In RDMA over Converged Ethernet (RoCE) networks, these mechanisms are implemented as Priority Flow Control (PFC) and Data Center Quantized Congestion Control (DCQCN), respectively.
In AI training scenarios, while Priority Flow Control (PFC) and Data Center Quantized Congestion Control (DCQCN) mitigate network congestion, they still present significant shortcomings. PFC prevents data loss by generating hop-by-hop backpressure, but this can lead to congestion trees, head-of-line blocking, and deadlock loops, ultimately affecting overall network performance. DCQCN relies on ECN marking and CNP messages to adjust rates, but its congestion indication is not precise, and rate adjustments are slow, unable to promptly respond to dynamic network conditions, thus limiting throughput. Both require manual adjustments and monitoring, increasing operational costs and maintenance complexity, failing to meet the stringent demands for high-performance, low-latency networks in AI training.
How NVIDIA Spectrum-X Overcomes These Issues
NVIDIA’s Spectrum-X solution stands out among various network manufacturers by addressing these traditional Ethernet limitations in AI training. According to the recent technical white paper, Spectrum-X’s core advantage lies in its adaptive routing technology, considered its “killer” feature. This technology directly tackles the uneven bandwidth allocation caused by static hash distribution mechanisms in traditional Ethernet.
By deeply integrating the capabilities of network-side switches and terminal-side DPUs (Data Processing Units), Spectrum-X achieves real-time, dynamic monitoring of each link’s physical bandwidth and port egress congestion status. Based on this monitoring, Spectrum-X can implement finely-tuned, dynamic load distribution strategies for each network packet, significantly enhancing link balance and effective bandwidth utilization from the traditional 50%-60% to over 97%. This improvement directly eliminates long-tail latency issues caused by “elephant flows” (large-scale data transmission flows) in AI applications.
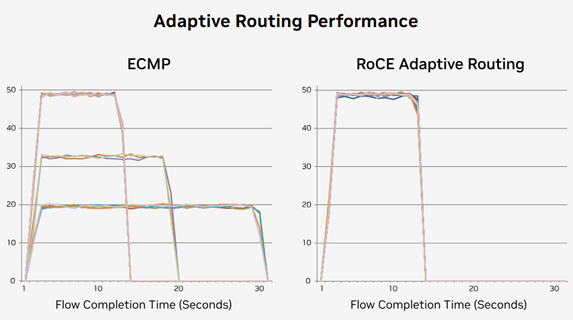
As illustrated, traditional ECMP can lead to significantly prolonged completion times for specific data flows due to uneven bandwidth utilization. In contrast, adaptive routing ensures that all data flows are evenly distributed across multiple links, significantly shortening and balancing the transmission times of each data flow, thereby reducing the overall training task completion cycle. Notably, in collective communication patterns common in AI training scenarios such as all-reduce and all-to-all, Spectrum-X showcases significant performance advantages over traditional Ethernet due to its superior link bandwidth utilization capabilities.
Direct Data Placement (DDP): Revolutionary Solution for Out-of-Order Reassembly Challenges
While per-packet load balancing strategies significantly improve bandwidth utilization efficiency and have become a highly sought-after solution, the main challenge they bring is the reassembly of out-of-order packets at the receiving end. This problem has been difficult for the industry to overcome. Traditional methods rely either on network-side processing or terminal-side solutions, but both are limited by software and hardware performance bottlenecks, leading to suboptimal results.
Spectrum-X, with its innovative deep integration of Spectrum-4 switch network-side and BlueField-3 terminal-side hardware, elegantly addresses this challenge. Here is a detailed explanation of the DDP processing flow in an RoCE (RDMA over Converged Ethernet) scenario:
.png)
On the left side, training traffic originating from different GPU memories is first specially marked by their respective sending BlueField-3 NICs. These marked packets are then sent to the directly connected Top of Rack (TOR) Spectrum-4 switches. The TOR switches, utilizing their powerful hardware capabilities, quickly identify the BlueField-3 marked packets and, based on the real-time bandwidth status and buffer conditions of the uplink, intelligently distribute the packets of each data flow across four uplink paths to four spine switches, using dynamic routing algorithms per packet.
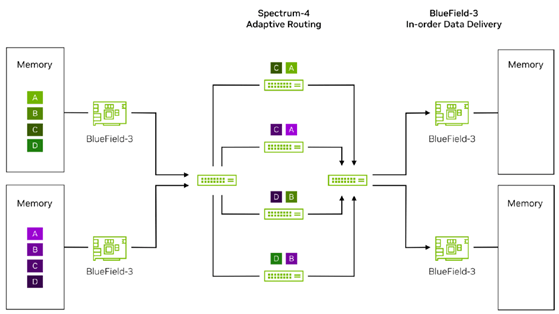
As these packets traverse their respective spine switches, they eventually reach the destination TOR switch and are further transmitted to the target server’s BlueField-3 NIC. Due to the different transmission paths and equipment performance variations, the packets may arrive at the destination BlueField-3 NIC out of order. The destination BlueField-3 NIC, utilizing its built-in DDP technology, quickly identifies the BlueField-3 marked packets and directly reads the packet memory addresses, precisely placing the packets in the target GPU’s memory. Subsequently, DDP technology further integrates these out-of-order packets, ensuring they are combined into a complete data flow in the correct order, completely eliminating out-of-order issues caused by network path differences and equipment performance disparities.
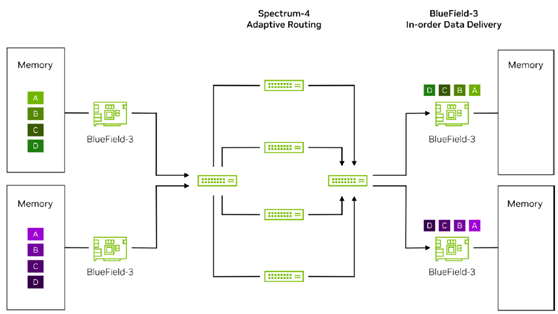
Through the seamless integration of dynamic routing and DDP hardware acceleration technologies, Spectrum-X not only effectively resolves the uneven bandwidth allocation issues of traditional Ethernet ECMP (Equal-Cost Multi-Path) mechanisms but also fundamentally eliminates the long-tail latency phenomena caused by out-of-order packets. This provides a more stable and efficient data transmission solution for high-performance computing applications like AI training.
Performance Isolation for AI Multi-Tenancy
In a highly concurrent AI cloud ecosystem, application performance fluctuations and runtime uncertainties are often closely related to network-level congestion. This phenomenon not only arises from the application’s own network traffic fluctuations but may also be induced by background traffic from other concurrent applications. Specifically, “many-to-one” congestion (multiple data sources sending data to a single receiver) becomes a significant performance bottleneck, dramatically increasing the processing pressure on the receiver.
In a multi-tenant or multi-task coexisting RoCE network environment, while technologies such as VXLAN can achieve a certain degree of host isolation, tenant traffic congestion and performance isolation issues remain challenging. A common scenario is where some applications perform excellently in a physical bare-metal environment but see a significant drop in performance once migrated to the cloud.
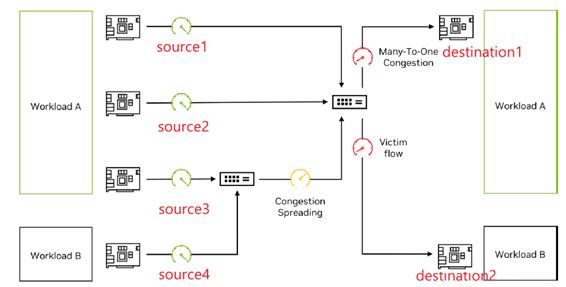
For instance, suppose workload A and workload B are running simultaneously in the system. When network congestion occurs and triggers congestion control mechanisms, due to the limited information carried by ECN, the sender cannot determine at which switch level the congestion occurred or the extent of it. Thus, it cannot decide how quickly to increase or decrease the sending rate, often relying on heuristic methods to converge gradually. This convergence time is long and can easily cause inter-job interference. Additionally, congestion control parameters are numerous, and switches and NICs require very detailed and complex parameter settings. Triggering congestion control mechanisms too quickly or too slowly can significantly impact customer business performance.
To address these challenges, Spectrum-X, with its powerful programmable congestion control function on the BlueField-3 hardware platform, presents an advanced solution beyond the traditional DCQCN algorithm. Spectrum-X achieves precise evaluation of congestion conditions on the traffic path through the close collaboration of BlueField-3 hardware at both the sender and receiver ends, utilizing RTT (Round Trip Time) probe packets and inband telemetry information from intermediate switches. This information includes, but is not limited to, timestamps of packets passing through switches and egress buffer utilization rates, providing a solid foundation for congestion control.
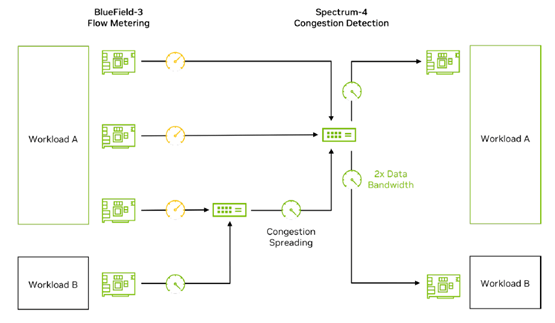
Critically, the high-performance processing capabilities of BlueField-3 hardware enable it to handle millions of Congestion Control (CC) packets per second, achieving refined congestion control based on different workloads. This effectively achieves performance isolation goals. Under this mechanism, workload A and workload B can each achieve their optimal expected performance without being adversely affected by other tenants’ congestion.
In summary, with its innovative hardware technology and intelligent congestion control algorithms, Spectrum-X provides an efficient and precise performance isolation solution for AI multi-tenant cloud environments, helping each tenant achieve performance comparable to that in a physical environment.
Spectrum-X Product Composition
SN5600 Switch: The SN5600 switch is an advanced 2U box switch that integrates the Spectrum-4 51.2 Tbps single chip, made with TSMC’s cutting-edge 4nm process and incorporating an astounding 100 billion transistors.

The switch is equipped with 64 800G OSFP ports and can flexibly support expansion to 128 400G ports or 256 200G ports, meeting diverse network needs. Its packet forwarding rate reaches 33.3Bpps, with 512K forwarding table entries and 160MB of global shared cache, ensuring line-rate forwarding even for 172-byte packets. Furthermore, the SN5600 is fully compatible with mainstream operating systems like Cumulus and Sonic, and its functionality has continuously evolved through the Spectrum series from generation 1 to 4, providing users with enhanced network performance and flexibility.
BlueField-3 SuperNIC: The BlueField-3 SuperNIC is a new network accelerator based on the BlueField-3 platform, designed to power large-scale AI workloads. Specifically developed for network-intensive large-scale parallel computing, it provides up to 400Gb/s RDMA connectivity between GPU servers over converged Ethernet, optimizing peak AI workload efficiency. The BlueField-3 SuperNIC marks a new era in AI cloud computing, delivering secure multi-tenant data center environments and ensuring performance consistency and isolation between jobs and tenants.

Notably, its powerful DOCA 2.0 software development framework offers highly customizable software solutions, further enhancing overall system efficiency.
LinkX Cables: The LinkX cable series focuses on 800G and 400G end-to-end high-speed connectivity, utilizing 100G PAM4 technology. Fully supporting OSFP and QSFP112 MSA standards, it covers various optical module forms from DAC and ACC to multi-mode and single-mode, meeting diverse wiring needs. These cables can seamlessly interface with the SN5600 switch’s 800G OSFP ports, enabling 1-to-2 expansions of 400G OSFP ports, improving network connection flexibility and efficiency.
Summary and Case Study
Spectrum-X, NVIDIA’s pioneering global leading AI Ethernet solution, integrates industry-leading hardware and software technologies, aiming to reshape the AI computing power ecosystem. Its core highlights include the self-developed Spectrum-4 ASIC high-performance switch, BlueField series DPU intelligent NICs, and LinkX optical module cables using Direct Drive technology. These hardware components together build a robust infrastructure.
Technologically, Spectrum-X incorporates multiple innovative features, such as dynamic routing mechanisms, end-side out-of-order correction technology, new-generation programmable congestion control algorithms, and the full-stack AI software acceleration platform DOCA 2.0. These features not only optimize network performance and efficiency but also significantly enhance AI application responsiveness and processing capabilities, creating an efficient and reliable computing foundation for users in the generative AI field.
This highly integrated solution aims to bridge the gap between traditional Ethernet and InfiniBand, focusing on providing customized, high-performance network support for the AI Cloud market. It meets AI applications’ stringent demands for high bandwidth, low latency, and flexible expansion, leading Ethernet technology trends towards AI-specific scenario optimization and aiming to develop and expand this emerging and promising market.
The technical advantages of Spectrum-X are exemplified in its application case with the French cloud service provider Scaleway. Scaleway, founded in 1999, offers high-performance infrastructure and over 80 cloud products and services to more than 25,000 global customers, including Mistral AI, Aternos, Hugging Face, and Golem.ai. Scaleway provides one-stop cloud services to develop innovative solutions and help users build and scale AI projects from scratch.
Currently, Scaleway is building a regional AI cloud offering GPU infrastructure for large-scale AI model training, inference, and deployment. Adopting NVIDIA’s Hopper GPUs and Spectrum-X network platform has significantly enhanced AI computing power, shortened AI training time, and accelerated AI solution development, deployment, and time to market, effectively improving ROI. Scaleway’s customers can scale from a few GPUs to thousands to meet any AI use case. Spectrum-X not only provides the performance and security needed for multi-tenant, multi-task AI environments but also achieves performance isolation through mechanisms like dynamic routing, congestion control, and global shared buffers. Additionally, NetQ provides deep visibility into AI network health with features like RoCE traffic counters, events, and WJH (What Just Happened) alerts, enabling AI network visualization, troubleshooting, and validation. With support from NVIDIA Air and Cumulus Linux, Scaleway can integrate API-native network environments into the DevOps toolchain, ensuring seamless transitions from deployment to operations.
Related Products:
-
 NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA(Mellanox) MMA1T00-HS Compatible 200G Infiniband HDR QSFP56 SR4 850nm 100m MPO-12 APC OM3/OM4 FEC PAM4 Optical Transceiver Module
$139.00
-
NVIDIA MFP7E10-N010 Compatible 10m (33ft) 8 Fibers Low Insertion Loss Female to Female MPO Trunk Cable Polarity B APC to APC LSZH Multimode OM3 50/125
$47.00
-
NVIDIA MCP7Y00-N003-FLT Compatible 3m (10ft) 800G Twin-port OSFP to 2x400G Flat Top OSFP InfiniBand NDR Breakout DAC
$260.00
-
NVIDIA MCP7Y70-H002 Compatible 2m (7ft) 400G Twin-port 2x200G OSFP to 4x100G QSFP56 Passive Breakout Direct Attach Copper Cable
$155.00
-
NVIDIA MCA4J80-N003-FTF Compatible 3m (10ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Active Copper Cable, Flat top on one end and Finned top on other
$600.00
-
NVIDIA MCP7Y10-N002 Compatible 2m (7ft) 800G InfiniBand NDR Twin-port OSFP to 2x400G QSFP112 Breakout DAC
$190.00











