
After entering the era of large models, the development of large models has become the core of artificial intelligence, but training large models is actually a complicated task because it requires a large amount of GPU resources and a long training time.
In addition, a single GPU worker thread has limited memory and the size of many large models exceeds the scope of a single GPU. Therefore, it is necessary to implement model training across multiple GPUs. This training method involves distributed communication and NVLink.
When talking about distributed communications and NVLink, we are in a fascinating and evolving technical field. Next we will briefly introduce the principles of distributed communication and the evolution of NVLink, the technology which helps achieving efficient distributed communication.
Distributed communication refers to connecting multiple nodes in a computer system so that they can communicate and collaborate with each other to complete common tasks. NVLink is a high-speed, low-latency communication technology that is typically used to connect GPUs or GPUs to other devices to achieve high-performance computing and data transmission.
Distributed Parallelism
Currently, deep learning has entered the era of large models, namely Foundation Models. The big model, as the name suggests, focuses on “big”. It mainly includes the following aspects:
- Large data size
Large models usually use self-supervised learning methods, which reduces data annotation and training and R&D costs, while large amounts of data can improve the generalization ability and performance of the model.
- Large parameter scale
As the scale of model parameters continues to increase, the model can better capture the complex relationships and patterns in the data, and is expected to further break through the accuracy limitations of the existing model structure.
- High computing power requirements
Large-scale data and parameters make it impossible for the model to run and calculate on a single machine. On the one hand, this requires continuous advancement of computing hardware, and on the other hand, it also requires the AI framework to have distributed parallel training capabilities.
Therefore, in order to solve the above problems, we need to introduce a distributed parallel strategy.
Data Parallelism
Data Parallel (DP) is a commonly used deep learning training strategy that achieves parallel processing by distributing data across multiple GPUs. In a data-parallel framework, each GPU (or working unit) stores a complete copy of the model so that each GPU can independently perform forward and backward propagation calculations on its assigned subset of data.
Data parallel workflow:
- Parameter synchronization: Before starting training, all working units synchronize model parameters to ensure that the model copies on each GPU are identical.
- Data distribution: The training data is divided into batches, each batch is further split into subsets, and each GPU is responsible for processing one subset of the data.
- Independent gradient computation: Each GPU independently performs forward and backward propagation on its subset of data and computes the corresponding gradients.
- Gradient aggregation: After the calculation is completed, the gradients of all work units need to be aggregated. This is usually achieved via network communication, for example using an All-Reduce algorithm, which allows gradients to be efficiently averaged across different GPUs.
- Parameters update: Once the gradients are averaged, each GPU uses this averaged gradient to update the parameters of its copy of the model.
- Process repetition: This process is repeated on each batch of data until the model is trained on the entire dataset.
Advantages and challenges of data parallelism:
Data parallelism can allow the training process to scale horizontally to more GPUs, thereby speeding up training. Its advantages lie in simple implementation and the ability to flexibly adjust the number of work units to adapt to available hardware resources. Currently, many deep learning frameworks provide built-in support.
However, as the number of parallel GPUs increases, more parameter copies need to be stored, which results in significant memory overhead. In addition, the gradient aggregation step requires synchronizing a large amount of data between GPUs, which may become a bottleneck of the system, especially when the number of working units increases.
Application of asynchronous synchronization scheme in data parallelism:
In order to solve the communication bottleneck problem in data parallelism, researchers have proposed various asynchronous synchronization schemes. In these schemes, each GPU worker thread can process data independently of other threads, without waiting for other worker threads to complete their gradient calculations and synchronization. This approach can significantly reduce the dead time caused by communication, thereby improving the system throughput.
The implementation principle is that in the gradient calculation stage, after each GPU completes its own forward and backward propagation, it immediately updates the gradient without waiting for other GPUs. In addition, each GPU reads the latest available global weights when needed without having to wait for all GPUs to reach a synchronization point.
However, this approach also has its disadvantages. Since the model weights on different GPUs may not be synchronized, the worker threads may use outdated weights for gradient calculations, which may lead to a decrease in statistical efficiency, that is, the accuracy cannot be strictly guaranteed.
Model Parallelism
Model Parallel (MP) generally refers to training a large deep learning model in a distributed manner across multiple computing nodes, where each node is responsible for a part of the model. This method is mainly used to solve the situation where a single computing node cannot accommodate the entire model. Model parallelism can be further subdivided into several strategies, including but not limited to pipeline parallelism (PP) and tensor parallelism (TP).
Model parallelism is a method to solve the problem that a single computing node cannot accommodate all the parameters of the model. Unlike data parallelism, where each node processes a different subset of the data for the full model, model parallelism distributes different parts of the model across multiple nodes, with each node responsible for only a portion of the model’s parameters. This can effectively reduce the memory requirements and computational load of a single node.
In model parallelism, multiple layers of a deep neural network can be split and assigned to different nodes. For example, we can group several consecutive layers together and assign the group of layers to a node. This hierarchical strategy enables each node to process only a portion of the model parameters assigned to it, reducing the use of memory and computing resources.
However, simple model-parallel implementations may result in significant waiting time and inefficient utilization of computational resources, as layers with sequential dependencies need to wait for the computation of the previous layer to complete.
In order to reduce this efficiency loss, Pipeline Parallel (PP) was proposed. In pipeline parallelism, a large batch of data is split into multiple small micro-batches. Each micro-batch should be processed proportionally faster, and each worker starts processing the next micro-batch as soon as it is available, thereby speeding up the execution of the pipeline. If there are enough microbatches, the workers (GPU cards) can be fully utilized and the idle time “bubbles” at the beginning and end of the steps can be minimized.
In pipeline parallelism, each node processes a different model layer sequentially, and micro-batches flow between nodes like in a pipeline. The gradients are averaged over all mini-batches and then used to update the model parameters.
Pipeline parallelism partitions the model “vertically” by layers. We can also split certain operations within a layer “horizontally”, which is often called Tensor Parallel (TP) training to further improve efficiency.
In tensor parallelism, large matrix multiplication operations in a model are split into smaller parts that can be executed in parallel on multiple compute nodes. For example, in the Transformer model, matrix multiplication is a major computational bottleneck. With tensor parallelism, we can split the weight matrix into smaller blocks, each of which is processed in parallel on different nodes.
In practice, model parallelism can include a combination of pipeline parallelism and tensor parallelism. A node can be responsible for part of the model (model parallelism) and process different micro-batches simultaneously (pipeline parallelism), and within this node, large matrix operations can be further split across multiple processors (tensor parallelism). Such a combination can make full use of distributed computing resources and improve the efficiency of large-scale model training.
AI Framework Distribution
For model training, no matter which parallel strategy is used, its essence includes splitting the model “vertically” or “horizontally”, and then placing the separate splits on different machines for calculation to make full use of computing resources.
In current AI frameworks, a mixed parallel approach of multiple strategies is usually adopted to accelerate model training. To support the training model of multiple parallel strategies, it is necessary to involve how the different “split” model parts communicate.
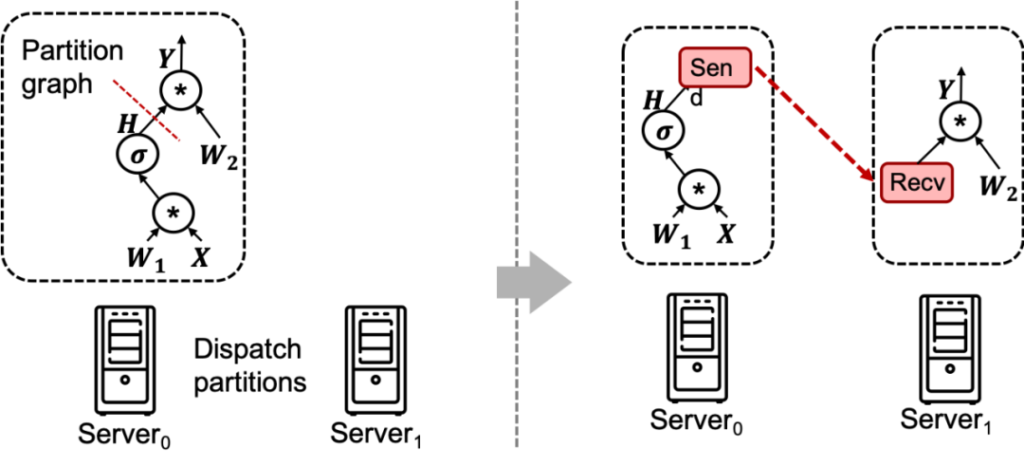
AI training graph segmentation
As shown in the figure above, in the AI computing framework, we need to split the original network model and distribute it on different machines for computing. Here, communication is carried out by inserting Send and Recv nodes in the model.
In addition, in distributed model training, due to the segmentation of the model, we also need to place the model parameters on the machines where the different model parts are located. During the training process, we will involve the interaction and synchronization of parameters of different model nodes, which also requires cross-node synchronization of data and parameters. This is distributed training.
What we have introduced above are distributed strategies and algorithms at the software level. Next, let’s take a look at how communication is implemented on the hardware.
Communication Hardware
Distributed communication is critical in AI training, especially when dealing with large models and massive amounts of data. Distributed communication involves data transmission and coordination between different devices or nodes to achieve parallel computing and model parameter synchronization, as shown in the following figure.
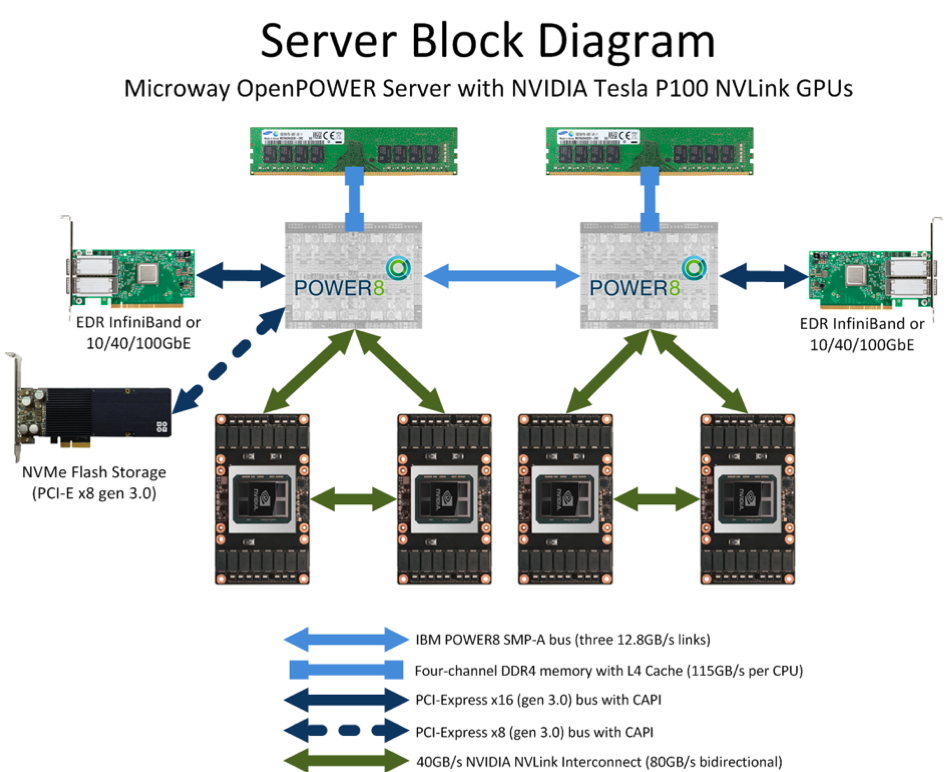
GPU Service Structure
When it comes to intra-machine communication, there are several common hardware:
- Shared memory: Multiple processors or threads can access the same physical memory so that they can communicate by reading and writing data in memory. Shared memory is suitable for parallel computing on the same machine.
- PCIe (Peripheral Component Interconnect Express): The PCIe bus is a standard interface for connecting computing devices, typically used to connect GPUs, accelerator cards, or other external devices. Through the PCIe bus, data can be transferred between different computing devices to achieve distributed computing.
- NVLink: NVLink is a high-speed interconnect technology developed by NVIDIA that enables direct communication between GPUs. NVLink can provide higher bandwidth and lower latency than PCIe, which is suitable for tasks that require higher communication performance.
In terms of machine-to-machine communication, common hardware includes:
- TCP/IP Network: TCP/IP protocol is the basis of Internet communication, which allows data transmission between different machines over the network. In distributed computing, TCP/IP networks can be used for communication and data transfer between machines.
- RDMA (Remote Direct Memory Access) Network: RDMA is a high-performance network communication technology that allows data to be transferred directly from one memory area to another without involving the CPU. RDMA networks are often used to build high-performance computing clusters to provide low-latency and high-throughput data transmission.
After understanding the hardware, the library that provides collective communication functions is indispensable for realizing communication. Among them, one of the most commonly used collective communication libraries is MPI (Message Passing Interface), which is widely used on CPU. On NVIDIA GPUs, the most commonly used collective communications library is NCCL (NVIDIA Collective Communications Library).
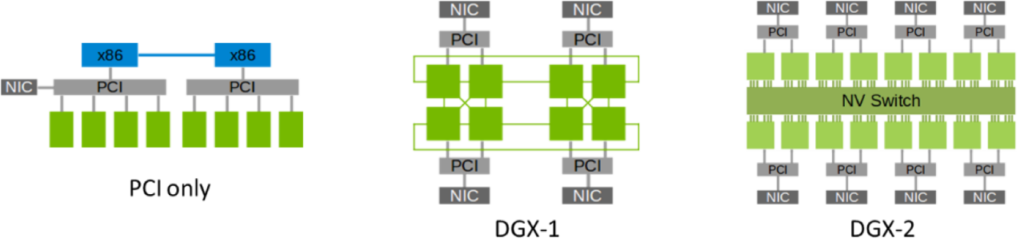
NVLink & NVSwitch
As shown in the figure above, through the NCCL library, we can use NVLink or NVSwitch to connect different GPUs to each other. NCCL provides external APIs at the algorithm level, through which we can easily perform collective communication operations across multiple GPUs. NCCL’s API covers common collective communication operations, such as broadcast, reduction, global reduction, global synchronization, etc., providing developers with rich and efficient parallel computing tools.
Collective Communication
Collective Communications is a global communication operation involving all processes in a process group. It includes a series of basic operations, such as sending, receiving, copying, intra-group process barrier synchronization (Barrier), and inter-node process synchronization (signal + wait). These basic operations can be combined to form a set of communication templates, also called communication primitives. For example, one-to-many broadcast, many-to-one gather, many-to-many gather (all-gather), one-to-many scatter (scatter), many-to-one reduce, many-to-many reduce (all-reduce), combined reduce and scatter (reduce-scatter), many-to-many (all-to-all), etc. Let us briefly introduce a few of them below.
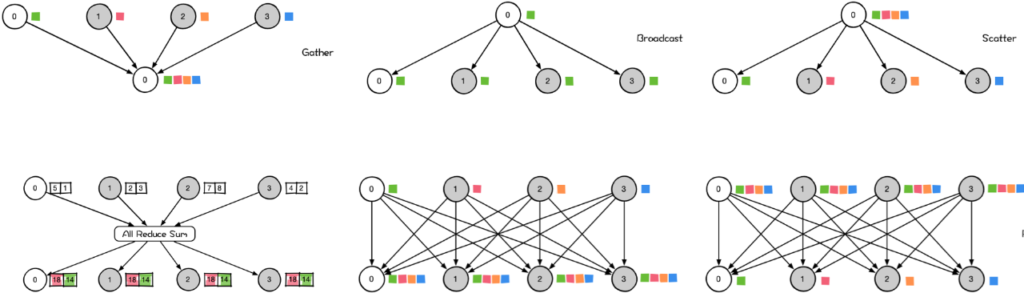
Collective Communication
The Gather operation is a many-to-one communication primitive with multiple data senders and one data receiver. It can collect data from multiple nodes to one node in the cluster. Its reverse operation corresponds to Scatter.
Broadcast is a one-to-many communication primitive, with one data sender and multiple data receivers. It can broadcast a node’s own data to other nodes in the cluster. As shown in the figure above, when master node 0 executes Broadcast, data is broadcast from master node 0 to other nodes.
Scatter is a one-to-many distribution of data. It divides the data on a GPU card into shards and distributes them to all other GPU cards.
AllReduce is a many-to-many communication primitive with multiple data senders and multiple data receivers. It performs the same Reduce operation on all nodes in the cluster and can send the results of data reduction operations on all nodes in the cluster to all nodes. Simply put, AllReduce is a many-to-many reduction operation of data, which reduces the data on all GPU cards (such as SUM) to each GPU card in the cluster.
AllGather is a many-to-many communication primitive with multiple data senders and multiple data receivers. It can collect data from multiple nodes in the cluster to a master node (Gather), and then distribute the collected data to other nodes.
The AllToAll operation scatters the data of each node to all nodes in the cluster, and each node also gathers the data of all nodes in the cluster. AllToAll is an extension of AllGather. The difference is that in the AllGather operation, the data collected from a certain node by different nodes is the same, while in AllToAll, the data collected from a certain node by different nodes is different.
NVLlink and NVSwitch Development
NVLink and NVSwitch are two revolutionary technologies introduced by NVIDIA that are redefining the way CPUs and GPUs, as well as GPUs and GPUs, work together and communicate efficiently.
NVLink is an advanced bus and communication protocol. NVLink uses a point-to-point structure and serial transmission to connect the central processing unit (CPU) and the graphics processing unit (GPU). It can also be used to connect multiple graphics processing units (GPUs).
NVSwitch: a high-speed interconnect technology. As an independent NVLink chip, it provides up to 18 NVLink interfaces, which can achieve high-speed data transmission between multiple GPUs.
The introduction of these two technologies brings higher communication bandwidth and lower latency to application scenarios such as GPU clusters and deep learning systems, thereby improving the overall performance and efficiency of the system.
NVLink Development
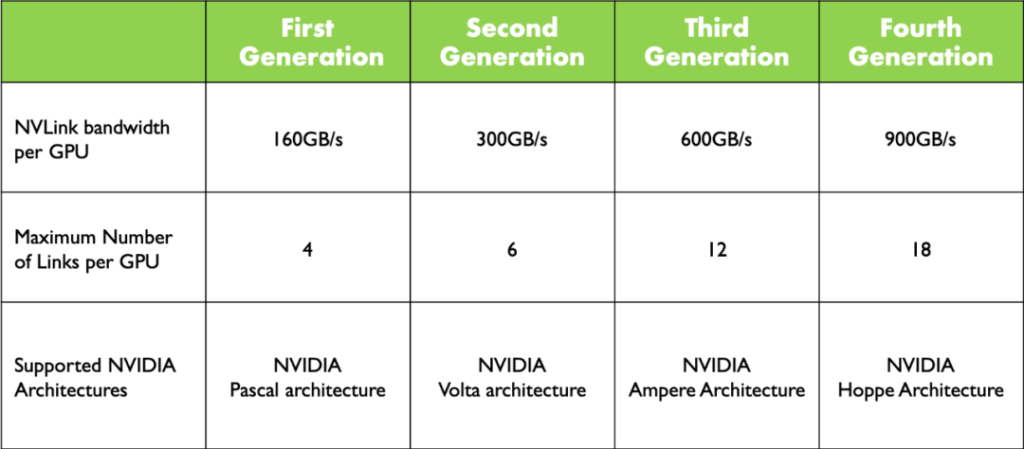
NVLink Development
As shown in the figure above, NVLink has gone through four generations of development and evolution from the Pascal architecture to the Hoppe architecture. At the GTC conference in 2024, NVIDIA released the Blackwell architecture, in which NVLink was updated again and the fifth-generation NVLink was released, with an interconnection bandwidth of 1800GB/s.
With each update of NVLink, the interconnection bandwidth of each GPU is continuously improved. The number of GPUs that can be interconnected between NVLinks has also increased from 4 in the first generation to 18 in the fourth generation. The latest Blackwell architecture has not increased the maximum number of interconnected GPUs.
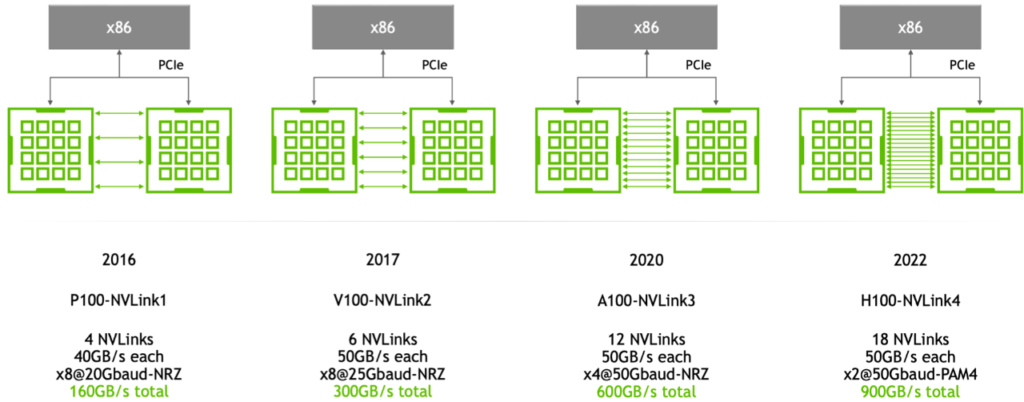
NVLink Development
As can be seen from the above figure, each NVLink in P100 has only 40GB/s, while from the second-generation V100 to H100, each NVLink link has 50GB/s. The overall bandwidth is increased by increasing the number of links.
NVSwitch Development
NVSwitch technology has undergone three generations of evolution and development from the Volta architecture to the Hopper architecture. The number of chiplets interconnected per GPU has remained constant at eight in each generation, meaning the basic structure of the interconnection remains stable and consistent. With the upgrade of the NVLink architecture, the bandwidth between GPUs has achieved a significant increase, because NVSwitch is the chip module that NVLink specifically carries, from 300GB/s in the Volta architecture to 900GB/s in the Hopper architecture.
Next, let’s take a look at the relationship between NVLink and NVSwitch in the server.
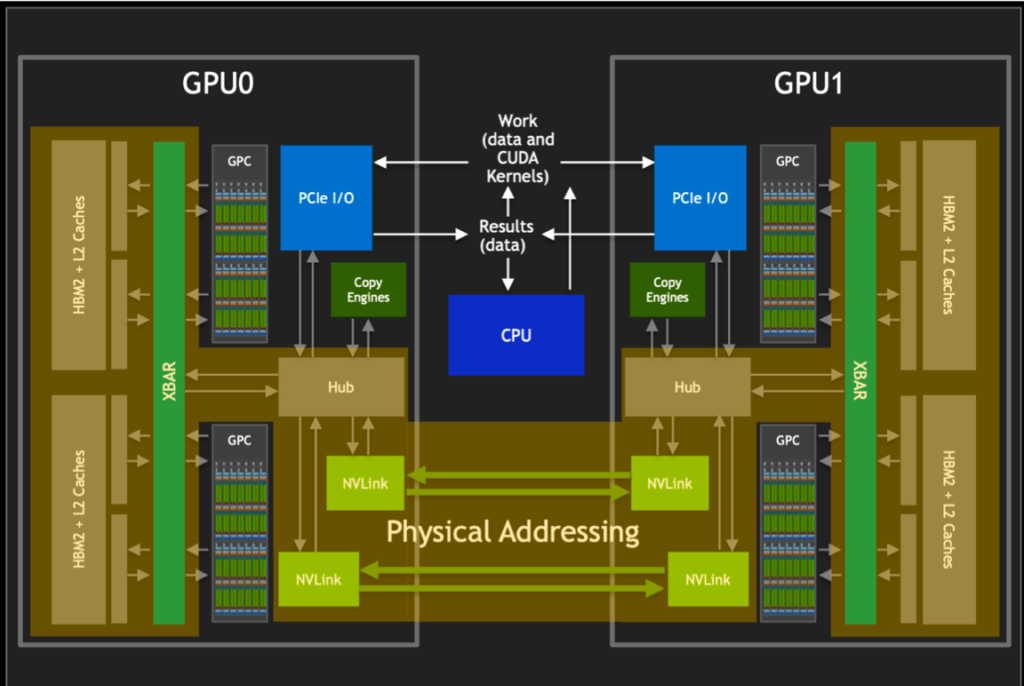
NVSwitch Development
As shown in the figure above, there is only NVLink in P100, and GPUs are interconnected through CubeMesh. In P100, each GPU has 4 interconnections, and every 4 form a CubeMesh.
While in V100, each GPU can be interconnected with another GPU through NVSwitch. In A100, NVSwitch was upgraded again, saving a lot of links. Each GPU can be interconnected with any other GPU through NVSwitch.
In H100, there has been a new technological breakthrough. There are 8 H100 GPU cards in a single machine, and there is a 900 GB/s bidirectional interconnection bandwidth between any two H100 cards. It is worth noting that in the DGX H100 system, four NVSwitches reserve 72 NVLink4 connections for connecting to other DGX H100 systems through NVLink-Network Switch, thereby facilitating the formation of a DGX H100 SuperPod system. The total bidirectional bandwidth of the 72 NVLink4 connections is ~3.6TB/s.
Summary
In the era of big models, the development of artificial intelligence increasingly relies on powerful computing resources, especially GPU resources. In order to train these large models, we need to adopt a distributed parallel strategy to spread the model training tasks across multiple GPUs or computing nodes. This not only involves strategies such as data parallelism and model parallelism, but also requires efficient distributed communication technologies, such as NVLink and NVSwitch, to ensure fast transmission and synchronization of data between different computing units.
AI frameworks in the era of large models not only need to support different distributed parallel strategies, but also need to involve and take into account distributed communication technologies such as NVLink and NVSwitch to support efficient cross-node communication.
As the size of the model continues to grow in the future, the demand for computing resources will continue to rise. We need to continuously optimize distributed parallel strategies and develop more efficient distributed communication technologies. This is not just a strategy optimization update on the software, but also involves optimization updates at the hardware level.
NVLink and NVSwitch are constantly updated to further improve the speed and efficiency of deep learning model training. Understanding these communication technology innovations and advances can help us better train larger models and push artificial intelligence to a deeper level.
Related Products:
-
 NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA(Mellanox) MMA1T00-HS Compatible 200G Infiniband HDR QSFP56 SR4 850nm 100m MPO-12 APC OM3/OM4 FEC PAM4 Optical Transceiver Module
$139.00
-
NVIDIA MFP7E10-N010 Compatible 10m (33ft) 8 Fibers Low Insertion Loss Female to Female MPO Trunk Cable Polarity B APC to APC LSZH Multimode OM3 50/125
$47.00
-
NVIDIA MCP7Y00-N003-FLT Compatible 3m (10ft) 800G Twin-port OSFP to 2x400G Flat Top OSFP InfiniBand NDR Breakout DAC
$260.00
-
NVIDIA MCP7Y70-H002 Compatible 2m (7ft) 400G Twin-port 2x200G OSFP to 4x100G QSFP56 Passive Breakout Direct Attach Copper Cable
$155.00
-
NVIDIA MCA4J80-N003-FTF Compatible 3m (10ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Active Copper Cable, Flat top on one end and Finned top on other
$600.00
-
NVIDIA MCP7Y10-N002 Compatible 2m (7ft) 800G InfiniBand NDR Twin-port OSFP to 2x400G QSFP112 Breakout DAC
$190.00











