
A network protocol is a collection of rules, standards, or conventions established for data exchange in a computer network. On a legal level, the OSI seven-layer protocol is an international protocol.
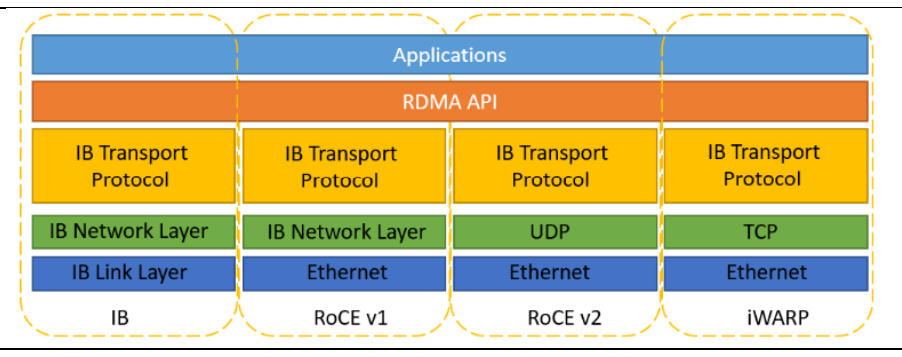
Due to the requirements of HPC/AI for high network throughput and low latency, TCP/IP is gradually transitioning to RDMA in data centers. RDMA contains different branches. Among them, Infiniband is designed specifically for RDMA, which guarantees reliable transmission from the hardware level. It has advanced technology but is pricy. RoCE and iWARP are both based on Ethernet RDMA technology.
This article focuses on the following aspects to discuss the relationship between switches and AI.
Q: What is a protocol?
Q: What is the role of switches in data center architecture?
Q: NVIDIA switch = IB switch?
Q: How to understand NVIDIA SuperPOD?
Q: What is the status quo of the switch market?
What is a Protocol?
A network protocol is a collection of rules, standards, or conventions established for data exchange in a computer network. On a legal level, the OSI seven-layer protocol is an international protocol. In the 1980s, in order to standardize the communication methods between computers and meet the needs of open networks, the OSI (Open System Interconnection) protocol was proposed, which adopted a seven-layer network.
- Physical layer: It solves how hardware communicates with each other. Its main function is to define physical device standards (such as interface type, transmission rate, etc.) to achieve the transmission of bit streams (a data stream represented by 0 and 1).
- Data link layer: The main functions are frame coding and error correction control. The specific work is to receive data from the physical layer, encapsulate it into frames, and then transmit it to the upper layer. Similarly, the data from the network layer can be split into bit streams and transmitted to the physical layer. The error correction function can be achieved because each frame includes verification information in addition to the data to be transmitted.
- Network layer: creates logical circuits between nodes and finds addresses through IP (each node in the network has an IP). The data transmitted at this layer is in packets.
- Transport layer: responsible for monitoring the quality of data transmission. If packet loss occurs, it should be resent.
- Session layer: The main function is to manage session connections of network devices.
- Presentation layer: mainly responsible for data format conversion, encryption, etc.
- Application layer: provides application interfaces, which can directly provide users with various network services and complete various network tasks.
TCP/IP is protocol stack includes various protocols. These protocols can be roughly divided into four layers, namely application layer, transport layer, network layer, and data link layer. In fact, the TCP/IP protocol can be understood as an optimized version of the OSI seven-layer protocol.
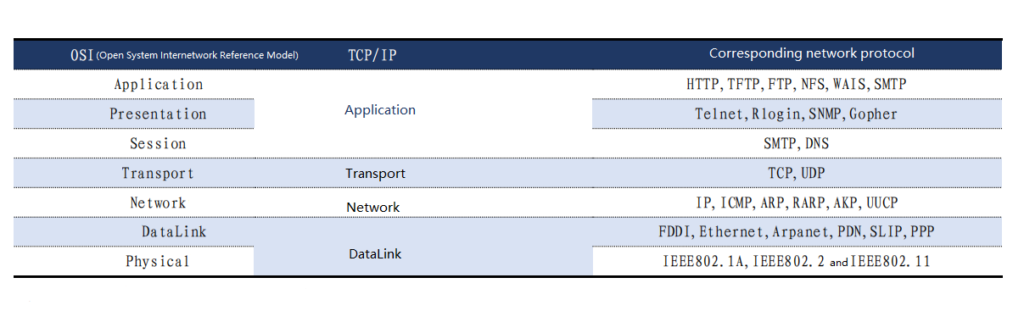
Comparison between OSI seven-layer network model and TCP/IP four-layer model
Due to HPC’s requirements for high network throughput and low latency, TCP/IP is gradually transitioning to RDMA. There are several major disadvantages of TCP/IP:
First, there is latency of tens of microseconds. Since the TCP/IP protocol stack requires multiple context switches during transmission and relies on the CPU for encapsulation, latency is relatively long.
Second, the CPU is heavily loaded. The TCP/IP network requires the host CPU to participate in protocol stack memory copying multiple times, and the correlation coefficient between CPU load and network bandwidth is too large.
RDMA (Remote Direct Memory Access): can access memory data directly through the network interface without the intervention of the operating system kernel. This allows high-throughput, low-latency network communication, which is particularly suitable for use in massively parallel computer clusters.
Three modes of RDMA
RDMA does not specify the entire protocol stack, but it places high demands on specific transmissions: for example, no loss, high throughput, and low latency, etc. RDMA includes different branches, among which Infiniband is designed specifically for RDMA and guarantees reliable transmission at the hardware level. It is technologically advanced but costly. RoCE and iWARP are both based on Ethernet RDMA technology.
What is the Role of Switches in Data Center Architecture?
Switches and routers work at different levels. The switch works at the data link layer and can encapsulate and forward data packets based on MAC (hardware address of the network card) identification, allowing different devices to communicate with each other. A router, also known as a path selector, works at the network layer to achieve interconnection, implements addressing based on IP, and connects different subnetworks.
Traditional data centers often use a three-layer architecture, namely the access layer, aggregation layer, and core layer. However, in small data centers, the existence of the aggregation layer can be ignored. Among them, the access layer is usually directly connected to the server, with the TOR (Top of Rack) switch being the commonly used one. The aggregation layer is the “intermediary (middle layer)” between the network access layer and the core layer. Core switches provide forwarding for packets entering and leaving the data center and provide connectivity for the aggregation layer.
With the development of cloud computing, the disadvantages of traditional three-layer networks have become more prominent:
- Bandwidth waste: Each group of aggregation switches manages a POD (Point Of Delivery), and each POD has an independent VLAN network. Spanning Tree Protocol (STP) is usually used between aggregation switches and access switches. STP makes only one aggregation layer switch available for a VLAN network, with other aggregation layers being blocked. This also makes it impossible to expand the aggregation layer horizontally.
- Large fault domain: Due to the STP algorithm, re-convergence is required when the network topology changes, which is prone to failure.
- Long latency: With the development of data centers, east-west traffic has increased significantly, and the communication between servers in the three-tier architecture needs to pass through switches layer by layer, resulting in a large latency. In addition, the working pressure of core switches and aggregation switches continues to increase, and performance upgrades also cause rising costs.
The leaf-spine architecture has obvious advantages, including flat design, low latency, and high bandwidth. The leaf-spine network flattens the network, where the leaf switches are equivalent to traditional access layer switches and the spine switches are similar to core switches.
Multiple paths are dynamically selected between leaf and spine switches through ECMP (Equal Cost Multi Path). When there are no bottlenecks in the access ports and uplinks of the Leaf layer, this architecture achieves non-blocking. Because each Leaf in the Fabric is connected to each Spine, if a Spine fails, the data center’s throughput performance will only slightly degrade.
NVIDIA switch = IB switch?
No. NVIDIA Spectrum and Quantum platforms are equipped with both Ethernet and IB switches.
IB switches are mainly operated by the manufacturer mellanox, which NVIDIA successfully acquired in 2020. In addition, the switches of NVIDIA’s Spectrum platform are mainly based on Ethernet, and its products are constantly iterating. The Spectrum-4 released in 2022 is a 400G switch product.

NVIDIA Spectrum and Quantum Platforms
Spectrum-X is designed for generative AI and optimizes the limitations of traditional Ethernet switches. Two key elements of the NVIDIA Spectrum X platform are the NVIDIA Spectrum-4 Ethernet switch and the NVIDIA BlueField-3 DPU.
Key benefits of Spectrum-X include: Extending RoCE for AI and Adaptive Routing (AR) to achieve maximum performance of the NVIDIA Collective Communications Library (NCCL). NVIDIA Spectrum-X can achieve up to 95% effective bandwidth at the load and scale of hyperscale systems.
- Leverage performance isolation to ensure that in a multi-tenant and multi-job environment, one job does not affect another job.
- Ensure that the network infrastructure continues to deliver peak performance in the event of a network component failure.
- Synchronize with BlueField-3 DPU for optimal NCCL and AI performance.
- Maintain consistent and stable performance across a variety of AI workloads, which is critical to achieving SLAs.
In networking mode, IB or Ethernet is an important question. In the current market, Ethernet occupies the vast majority of the market share, but in some large-scale computing scenarios, IB stands out. At the ISC 2021 Supercomputing Conference, IB accounted for 70% of the TOP10 systems and 65% of the TOP100 systems. As the scope of consideration grows, IB’s market share decreases.
The Spectrum and Quantum platforms target different application scenarios. In Nvidia’s vision, AI application scenarios can be roughly divided into AI cloud and AI factory. Traditional Ethernet switches and Spectrum-X Ethernet can be used in AI cloud, while NVLink+InfiniBand solutions are required in AI factory.
How to Understand NVIDIA SuperPOD?
SuperPOD is a server cluster that connects multiple computing nodes to provide greater throughput performance.
Taking NVIDIA DGX A100 SuperPOD as an example, the switch used in the configuration officially recommended by NVIDIA is QM9700, which can provide 40 200G ports. In the first layer, the DGX A100 server has a total of 8 interfaces, which are connected to 8 leaf switches respectively for it adopts a fat tree (non-convergent) architecture. 20 servers form an SU, so a total of 8*SU servers are required. In the second-layer architecture, since the network does not converge and port speed is consistent, the uplink port provided by the spine switch must be greater than or equal to the downlink port of the leaf switch. Therefore, 1 SU corresponds to 8 leaf switches and 5 spine switches, 2 SUs correspond to 16 leaf switches and 10 spine switches, and so on. In addition, when the number of SUs increases to more than 6, the official recommendation is to add a core layer switch.
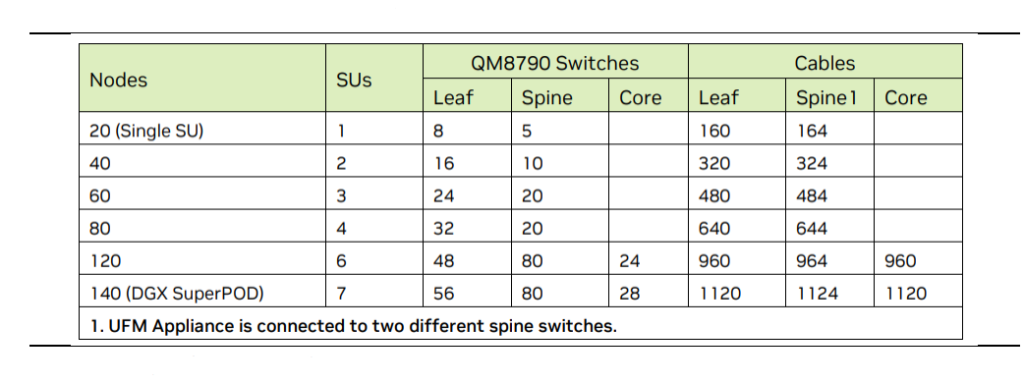
NVIDIA DGX A100 SuperPOD Architecture Reference
In the DGX A100 SuperPOD, server: switch ratio in the computing network is 1:1.17 (taking 7 SUs as an example); But in the DGX A100 SuperPOD, the ratio is 1:0.38. Taking into account the requirements for storage and network management, the server:switch ratios for the DGX A100 SuperPOD and DGX H100 SuperPOD are 1:1.34 and 1:0.50, respectively.
In terms of ports, in the recommended configuration for DGX H100, each SU consists of 31 servers. On the one hand, the DGX H100 has only 4 interfaces for computing, on the other hand, the switch is a QM9700, providing 64 400G ports in the DGX H100 SuperPOD .
In terms of switch performance, the QM9700 performance has been greatly improved in the recommended configuration of DGX H100 SuperPOD. Infiniband switches introduce Sharp technology. By constructing a streaming aggregation tree (SAT) in the physical topology through the aggregation manager, and then having multiple switches in the tree perform parallel operations, latency can be greatly reduced and network performance can be improved. QM8700/8790+CX6 only supports up to 2 SATs, but QM9700/9790+CX7 supports up to 64. The number of stacking ports increases, so the number of switches used decreases.
Judging from the switch prices, the price of QM9700 is about twice that of QM8700/8790. According to the SHI official website, the unit price of Quantum-2 QM9700 is 38,000 US dollars, and the unit price of Quantum QM8700/8790 is 23,000/17,000 US dollars respectively.
What is the Status Quo of the Switch Market?
The switch market is booming in the short term. With the development of AI, market demand is expected to further expand and show a trend towards high-end iteration.
From a structural perspective, the switch market is still a blue ocean, with Cisco taking a large share, and Arista growing rapidly.
In terms of market size: In Q1 2023, global Ethernet switch revenue was US$10.021 billion, a year-on-year increase of 31.5%. 200G/400G switch revenue increased by 41.3% year-on-year, and 100G switch revenue increased by 18.0% year-on-year.
In terms of port shipment quantity: 229 million units were shipped in the first quarter of 2023, a year-on-year increase of 14.8%. 200G/400G and 100G ports increased by 224.2% and 17.0% respectively.
The competitive landscape of the switch is better than in the server market. According to theNextPlatform, Cisco accounted for 46% of the market share in Q1 2023, approximately US$4.61 billion, a year-on-year increase of 33.7%. Arista achieved revenue of US$1.15 billion in the first quarter of 2023, a year-on-year increase of 61.6%, thanks to its outstanding performance in the data center.
In terms of profitability, Cisco and Arista both have gross margins close to 60%. The relatively favorable landscape has created good profitability for manufacturers in the industry chain. Although the gross profit margins of Cisco and Arista have shown a slightly downward trend, they still maintain a gross profit margin of around 60% overall. Looking ahead, we believe that the switch market is expected to continue to benefit from the development of AI.
Related Products:
-
 NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$650.00
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$650.00
-
 NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$850.00
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$850.00
-
 NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$750.00
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$750.00
-
 NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1100.00
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1100.00
-
 NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1200.00
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1200.00
-
 NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$800.00
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$800.00
-
 Mellanox MMA1T00-HS Compatible 200G Infiniband HDR QSFP56 SR4 850nm 100m MPO-12 APC OM3/OM4 FEC PAM4 Optical Transceiver Module
$200.00
Mellanox MMA1T00-HS Compatible 200G Infiniband HDR QSFP56 SR4 850nm 100m MPO-12 APC OM3/OM4 FEC PAM4 Optical Transceiver Module
$200.00
-
 NVIDIA MFP7E10-N010 Compatible 10m (33ft) 8 Fibers Low Insertion Loss Female to Female MPO Trunk Cable Polarity B APC to APC LSZH Multimode OM3 50/125
$47.00
NVIDIA MFP7E10-N010 Compatible 10m (33ft) 8 Fibers Low Insertion Loss Female to Female MPO Trunk Cable Polarity B APC to APC LSZH Multimode OM3 50/125
$47.00
-
 NVIDIA MCP7Y00-N003-FLT Compatible 3m (10ft) 800G Twin-port OSFP to 2x400G Flat Top OSFP InfiniBand NDR Breakout DAC
$275.00
NVIDIA MCP7Y00-N003-FLT Compatible 3m (10ft) 800G Twin-port OSFP to 2x400G Flat Top OSFP InfiniBand NDR Breakout DAC
$275.00
-
 NVIDIA MCP7Y70-H002 Compatible 2m (7ft) 400G Twin-port 2x200G OSFP to 4x100G QSFP56 Passive Breakout Direct Attach Copper Cable
$155.00
NVIDIA MCP7Y70-H002 Compatible 2m (7ft) 400G Twin-port 2x200G OSFP to 4x100G QSFP56 Passive Breakout Direct Attach Copper Cable
$155.00
-
 NVIDIA MCA4J80-N003-FTF Compatible 3m (10ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Active Copper Cable, Flat top on one end and Finned top on other
$600.00
NVIDIA MCA4J80-N003-FTF Compatible 3m (10ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Active Copper Cable, Flat top on one end and Finned top on other
$600.00
-
 NVIDIA MCP7Y10-N002 Compatible 2m (7ft) 800G InfiniBand NDR Twin-port OSFP to 2x400G QSFP112 Breakout DAC
$200.00
NVIDIA MCP7Y10-N002 Compatible 2m (7ft) 800G InfiniBand NDR Twin-port OSFP to 2x400G QSFP112 Breakout DAC
$200.00